Hive(一)
Hive
- Hive的基本概念
-
- 什么是Hive
- Hive的优缺点
-
- 优点
- 缺点
- Hive的架构原理
- Hive和数据库比较
-
- 查询语言
- 数据存储位置
- 数据更新
- 执行
- 执行延迟
- 可扩展性
- 数据规模
- Hive安装
-
- Hive安装部署
- Hadoop集群配置
- Hive的基本操作
- 将本地文件导入Hive案例
-
- 数据准备
- 实际操作
- MySQL安装
- 配置只要是root用户+密码,在任何主机上都能登录MySQL数据库。
- Hive元数据配置到Mysql
-
- 拷贝驱动
- 配置Metastore到MySql
- 多窗口Hive测试
- 元数据服务访问hive
- JDBC连接Hive
- Hive启动方式
- Hive其他交互模式
- 参数配置
-
- 参数配置含有优先级
- 基本数据类型
- 复杂数据类型:
-
- 数据类型转换
- DDL数据定义
-
- 创建数据库
- 查询数据库
- 修改数据库
- 删除数据库
- 创建表
-
- 创建语法
- 管理表(内部表)
- 外部表
- 内部表于外部表的相互转化
- 创建表时指定字段分割符
- 修改/删除表
-
- 重命名表
- 增加/修改/替换列信息(列名和列数据类型)
-
- 更新列(数据类型必须加上,哪怕修改前后一样)
- 增加或替换列
-
- 演示
- 删除表
- DML数据操作
-
- 数据导入
-
- 向表中加载数据(Load)
-
- 实操
- 通过查询语句向表中插入数据(Insert)
- 创建表时加载数据(As Select)
- 创建表时通过Location来指定加载数据路径
- Import数据到指定的Hive中
- 数据导出
-
- Insert导出数据
- Hive Shell导出
- Export导出数据
- 清空表中数据
- DML查询
-
- 列别名
- 算术运算符
- 常用函数(MR很慢)
- Limit语句
- Where语句
-
- 比较运算符与逻辑运算符
- Like和RLike
- 逻辑运算符(And/Or/Not)
- Group by
- Hiving
- Join
-
- 内连接(两个表中交集)
- 左外连接(AB表中A表的部分)
- 右外连接
- 满外连接
- 左连接(左表独有的数据)
- 右连接
- 两张表都没有出现交集的数据集
- 多表连接
- 笛卡尔积
- 排序
-
- 全局排序(Order by)
- 每个Reduce内部排序(Sort by)
- 分区排序(distribute by)
- Cluster By
- 分区表
-
- 分区表创建
-
- 分区表的增删查
- 二级分区
- 分区和HDFS
-
- 上传数据后修复
- 上传数据后添加分区
- 上传文件后load数据到分区
- 动态分区
- 分桶表(数据集极大的地方能用到)
-
- 分桶抽样查询
- 函数
-
- 系统内置函数
- 常用查询函数
-
- 空字段函数(nvl)
- CASE WHEN THEN ELSE END
- 行转列
-
- 相关函数说明
- 列转行
- 窗口函数
-
- Rank函数
- 函数
-
- 自定义函数
- 压缩
-
-
- 开启Map输出阶段压缩
- 开启Reduce输出阶段压缩
- 文件存储格式
-
- 主流文件存储格式对比
- 总结
-
Hive的基本概念
什么是Hive
Hive:由Facebook开源用于解决海量结构化日志的数据统计
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类sql查询功能
本质就是将HQL转化为MapReduce程序

Hive处理的数据存储在HDFS
Hive分析数据底层实现是MapReduce
执行程序运行在Yarn上
Hive相当于Hadoop的一个客户端,通过提交SQL,让Hive自行解析封装成MapReduce任务去HDFS读数据提交给Yarn执行
Hive的优缺点
优点
- 操作接口采用类SQL语法,提供快速开发的能力
- 避免了去写MapReduce,减少开发人员学习成本
- Hive的执行延迟较高,因此常用于数据分析,对实时性要求不高的场合
- Hive的优势在于处理大数据,对于效数据没有优势,因为Hice的执行延迟比较高
- Hive支持用户自定义函数
缺点
- Hive的HQL表达能力有限
迭代式算法无法表达
数据挖掘方柏霓不擅长,由于MapReduce数据处理流程的限制,小路更高的算法无法实现
- Hive的效率比较低
Hive自动生成的MapReduce作业通常情况下不够智能
Hive调优比较困难
Hive的架构原理
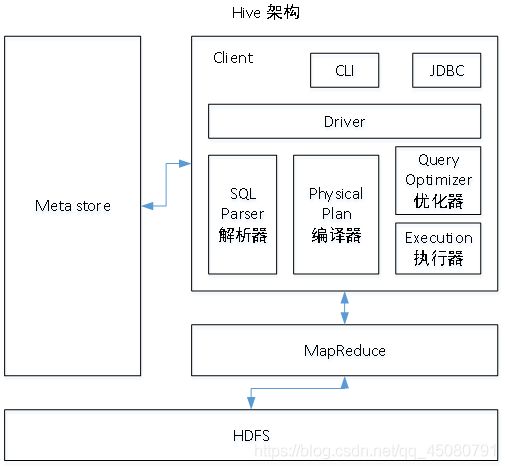
1.用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)
2.元数据:Metastore
元数据包括:表名、表所属的数据库(默认default)、表拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,我们改为使用MySQL存储Metastore
3.Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
4.驱动器:Driver(很重要)
- 解析器:将SQL字符串转换成抽象语法树AST,这一步一般用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
- 编译器:将AST编译生成逻辑执行计划
- 优化器:对逻辑执行计划进行优化
- 执行器:把逻辑执行计划转换成可以运行的物理嘉华。对于Hive来说就是MR/Spark

Hive通过给用户提供一系列交互接口,接收到用户的指令(SQL),使用自己的Driver结合元数据(MetaStore)将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将只写返回的结果输出到用户交互接口
Hive和数据库比较
Hive采用了类似SQL的查询语言HQL,所以很容易将Hive理解为数据库。其实从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之处。Hive是为了数据仓库而设计的
查询语言
由于SQL被广泛应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
数据存储位置
Hive是建立在Hadoop之上的,所有Hive的数据都是存储在HDFS中。而数据库则可以将数据保存在设备或本地文件系统中
数据更新
由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少,因此Hive中不建议对数据进行改写,所有的数据都是在加载的时候确定好的。 而数据库中的数据通常是需要进行修改的,因此可以使用INSERT INTO…Values添加数据,是用UPDATE…SET修改数据
执行
Hive中大多数查询的执行是通Hadoop提供的MapReduce来实现的。而数据库有自己的执行引擎。
执行延迟
Hive在查询数据时,由于没有索引,需要扫描整个表,因此延迟比较高。另外一个导致Hive执行延迟高的因素时MapReduce框架。由于MaoReduce本身具有较高的延迟,因此再利用MapReduce执行Hive查询时,也会有较高的延迟。相对的,数据库的执行延迟比较低,(数据规模小,当数据规模超过数据可得处理能力时,Hive的并行计算显然能体现出优势)
可扩展性
由于Hive时建立在Hadoop上的,因此Hive的可扩展性是和Hadoop的可扩展性一致的。而数据库由于ACID语义的严格限制,扩展行非常有限。
数据规模
由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的规模就比较小
Hive安装
Hive安装部署
把安装包上传到linux的/opt/software目录下
解压到/opt/module/下并改名为hive
/opt/module/hive/conf目录下的hive-env.sh.template名称为hive-env.sh
[yyx@hadoop01 conf]$ mv hive-env.sh.template hive-env.sh
配置hive-env.sh文件

Hadoop集群配置
首先启动hdfs和yarn
[yyx@hadoop01 hadoop-2.7.2]$ sbin/start-dfs.sh
[yyx@hadoop02 hadoop-2.7.2]$ sbin/start-yarn.sh
在HDFS上创建/tmp和/user/hive/warehouse两个目录并修改他们的同组权限可写
[yyx@hadoop01 hadoop-2.7.2]$ bin/hadoop fs -mkdir /tmp
[yyx@hadoop01 hadoop-2.7.2]$ bin/hadoop fs -mkdir -p /user/hive/warehouse
[yyx@hadoop01 hadoop-2.7.2]$ bin/hadoop fs -chmod g+w /tmp
[yyx@hadoop01 hadoop-2.7.2]$ bin/hadoop fs -chmod g+w /usr/hive/warehouse
chmod: `/usr/hive/warehouse': No such file or directory
[yyx@hadoop01 hadoop-2.7.2]$ bin/hadoop fs -chmod g+w /user/hive/warehouse
Hive的基本操作
日志查看位置:/tmp/yyx/hive.log
查看方法:tail -f hive.log 空格,之后启动报错程序
启动Hive
[yyx@hadoop01 hive]$ bin/hive
查看数据库
hive> show databases;
OK
default
Time taken: 0.231 seconds, Fetched: 1 row(s)
打开默认数据库
hive> use default;
OK
Time taken: 0.08 seconds
创建一张表(默认路径/user/hive/warehouse/表名)
hive> create table student (id int,name string);
OK
Time taken: 0.288 seconds
显示数据库中有多少张表
hive> show tables;
OK
student
Time taken: 0.039 seconds, Fetched: 1 row(s)
查看表结构
hive> desc student;
OK
id int
name string
Time taken: 0.181 seconds, Fetched: 2 row(s)
向表中插入数据
hive> insert into student values(1000,"ss");
Query ID = yyx_20210204152702_1a4a37f4-bb2d-4dfa-925a-42a79b482413
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1612423146019_0001, Tracking URL = http://hadoop02:8088/proxy/application_1612423146019_0001/
Kill Command = /opt/module/hadoop-2.7.2/bin/hadoop job -kill job_1612423146019_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2021-02-04 15:27:19,209 Stage-1 map = 0%, reduce = 0%
2021-02-04 15:27:27,811 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.69 sec
MapReduce Total cumulative CPU time: 1 seconds 690 msec
Ended Job = job_1612423146019_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://hadoop01:9000/user/hive/warehouse/student/.hive-staging_hive_2021-02-04_15-27-02_235_3653949154542618460-1/-ext-10000
Loading data to table default.student
Table default.student stats: [numFiles=1, numRows=1, totalSize=8, rawDataSize=7]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.69 sec HDFS Read: 3548 HDFS Write: 79 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 690 msec
OK
Time taken: 27.043 seconds
查询表中数据
hive> select * from student;
OK
1000 ss
Time taken: 0.282 seconds, Fetched: 1 row(s)
退出hive
hive> quit;
[yyx@hadoop01 hive]$
说明:(查看hive在hdfs中的结构)
数据库:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
表:在hdfs中表现所属db目录下一个文件夹,文件夹中存放该表中的具体数据
将本地文件导入Hive案例
需求:将本地/opt/module/datas/student.txt这个目录下的数据导入到hive的student(id int, name string)表中。
数据准备
[yyx@hadoop01 hive]$ cd /opt/module/
[yyx@hadoop01 module]$ mkdir datas
[yyx@hadoop01 module]$ cd datas/
[yyx@hadoop01 datas]$ touch student.txt
[yyx@hadoop01 datas]$ vi student.txt
1001 zhangsan
1002 lisi
1003 wangwu
注意,用tab键间隔
实际操作
删除原有的表,新增了一个以/t分割的表,并导入
[yyx@hadoop01 hive]$ bin/hive
Logging initialized using configuration in jar:file:/opt/module/hive/lib/hive-common-1.2.1.jar!/hive-log4j.properties
hive> show databases;
OK
default
Time taken: 0.762 seconds, Fetched: 1 row(s)
hive> use default;
OK
Time taken: 0.011 seconds
hive> show tables;
OK
student
Time taken: 0.03 seconds, Fetched: 1 row(s)
hive> drop table student;
OK
Time taken: 1.466 seconds
hive> create table student(id int,name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
OK
Time taken: 0.256 seconds
hive> load data local inpath '/opt/module/datas/student.txt' into table student;
Loading data to table default.student
Table default.student stats: [numFiles=1, totalSize=36]
OK
Time taken: 0.45 seconds
hive> select * from student;
OK
1001 zhangsan
1002 lisi
1003 wangwu
Time taken: 0.218 seconds, Fetched: 3 row(s)
遇到的问题:再打开一个窗口操作,会产生异常:
[yyx@hadoop01 hive]$ bin/hive
Logging initialized using configuration in jar:file:/opt/module/hive/lib/hive-common-1.2.1.jar!/hive-log4j.properties
Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:522)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:677)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:621)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient...
原因是:Metastore默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
MySQL安装
首先:检查是否安装过,如果是,卸载
rpm -qa | grep mysql
rpm -qa | grep mariadb
将压缩包放到/opt/software/
之后在将其解压到当前目录
unzip mysql-libs.zip
进入mysql-lip
安装客户端和服务端
rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm
rpm -ivh MySQL-client-5.6.24-1.el6.x86_64.rpm
再获取密码
cat /root/.mysql_secret
获取状态
启动mysql
service mysql status
service mysql start
连接mysql
mysql -uroot -pOEXaQuS8IWkG19Xs
修改密码:
SET PASSWORD=PASSWORD('000000');
配置只要是root用户+密码,在任何主机上都能登录MySQL数据库。
进入Mysql
mysql -uroot -p000000
显示数据库
show databases;
使用数据库
use mysql;
展示mysql中所有表
show tables;
展示user表结构
desc user;
查询user表
select User, Host, Password from user;
修改user表,将Host表内容修改为%
update user set host='%' where host='localhost';
删除root其他Host
mysql>delete from user where Host='hadoop102';
mysql>delete from user where Host='127.0.0.1';
mysql>delete from user where Host='::1';
刷新:
并推出
mysql>flush privileges;
quit
Hive元数据配置到Mysql
拷贝驱动
在/opt/software/mysql-libs目录下解压mysql-connector-java-5.1.27.tar.gz驱动
tar -zxvf mysql-connector-java-5.1.27.tar.gz
拷贝/opt/software/mysql-libs/mysql-connector-java-5.1.27目录下的mysql-connector-java-5.1.27-bin.jar到/opt/module/hive/lib/
cp mysql-connector-java-5.1.27-bin.jar
/opt/module/hive/lib/
配置Metastore到MySql
在/opt/module/hive/conf目录下创建一个hive-site.xml
touch hive-site.xml
vi hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
<description>password to use against metastore database</description>
</property>
</configuration>
配置完毕后,如果启动hive异常,可以重新启动虚拟机。(重启后,别忘了启动hadoop集群)
多窗口Hive测试
先启动mysql
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.01 sec)
启动多窗口启动HIve可行
此时Mysql:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| metastore |
| mysql |
| performance_schema |
| test |
+--------------------+
5 rows in set (0.01 sec)
元数据服务访问hive
目前只能再bin/hive使用hive,如果想在第三方框架中使用,没有东西可连(没有开启服务)
首先,在hive-site.xml中添加配置信息
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop01:9083</value>
</property>
启动metastore(此时bin/hive已经启动不了)
[yyx@hadoop01 hive]$ bin/hive --service metastore
Starting Hive Metastore Server
这是一个前台进程,启动了就不释放
这时另外启动一个窗口,bin/hive
如果想用第三方链接,就可以用9083这个端口
JDBC连接Hive
配置hive-site.xml信息
<property>
<name>hive.server2.thrift.bind.hostname>
<value>hadoop01value>
property>
<property>
<name>hive.server2.thrift.portname>
<value>10000value>
property>
想要连接hiveserver2,我们也要将元数据服务启动
hiveserver2连接元数据服务,与那数据服务通过JDBC连接MySQL(这个JDBC是MySQL的JDBC,并不是JDBC连接Hive)
JDBC连接HIve是使用一个客户端,使用JDBC来连接hiveserver2(这个JDBC才是Hive驱动)
首先启动元数据服务
[yyx@hadoop01 hive]$ bin/hive --service metastore
Starting Hive Metastore Server
之后开启hiveserver2
[yyx@hadoop01 hive]$ bin/hive --service hiveserver2
在开启beeline(另一个窗口)
[yyx@hadoop01 hive]$ bin/beeline -u jdbc:hive2://hadoop01:10000 -n yyx
Connecting to jdbc:hive2://hadoop01:10000
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.2.1 by Apache Hive
0: jdbc:hive2://hadoop01:10000> show tables;
+-----------+--+
| tab_name |
+-----------+--+
| student |
+-----------+--+
1 row selected (1.809 seconds)
退出
!quit
Hive启动方式
前台启动的方式需要启动多个shell窗口,可以用脚本的方式后台启动
nohup:放在命令开头,表示不挂起,也就是关闭终端进程也继续保持运行状态
/dev/null:是linux的一个文件,被称为黑洞,所有写入该文件的内容都会自动被丢弃
2>&1:表示将错误重定向到标准输出上
&:放在命令结尾,表示后台运行
那么启动hive可以用以下命令
[yyx@hadoop01 hive]$ nohup bin/hive --service metastore 2>&1 &
[1] 11009
[yyx@hadoop01 hive]$ nohup: 忽略输入并把输出追加到"nohup.out"
[yyx@hadoop01 hive]$ nohup bin/hive --service hiveserver2 2>&1 &
[2] 11095
[yyx@hadoop01 hive]$ nohup: 忽略输入并把输出追加到"nohup.out"
[yyx@hadoop01 hive]$ bin/beeline -u jdbc:hive2://hadoop01:10000 -n yyx
Connecting to jdbc:hive2://hadoop01:10000
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.2.1 by Apache Hive
0: jdbc:hive2://hadoop01:10000>
Hive其他交互模式
1.“-e”不进入hive的交互窗口执行sql语句
[yyx@hadoop01 hive]$ bin/hive -e "select id from student;"
2.“-f”执行脚本中sql语句
(1)在/opt/module/datas目录下创建hivef.sql文件
[yyx@hadoop01 datas]$ touch hivef.sql
文件中写入正确的sql语句
select *from student;
(2)执行文件中的sql语句
[yyx@hadoop01 hive]$ bin/hive -f /opt/module/datas/hivef.sql
(3)执行文件中的sql语句并将结果写入文件中
[yyx@hadoop01 hive]$ bin/hive -f /opt/module/datas/hivef.sql > /opt/module/datas/hive_result.txt
参数配置
打印当前库和表头
在hive-site.xml中添加
<property>
<name>hive.cli.print.headername>
<value>truevalue>
property>
<property>
<name>hive.cli.print.current.dbname>
<value>truevalue>
property>
所有的默认信息可以查看
cat hive-default.xml.template
参数配置含有优先级
hive-default.xml.template 为默认的,优先级最低
在hive-site.xml中添加,优先级高于默认,且永久有效
通过命令行kv启动(如下):高于hive-site,且仅本次hive有效
bin/hive -hiveconf hive.cl.print.current.db=false;
在hive中设置参数优先级最高,但是也是临时生效
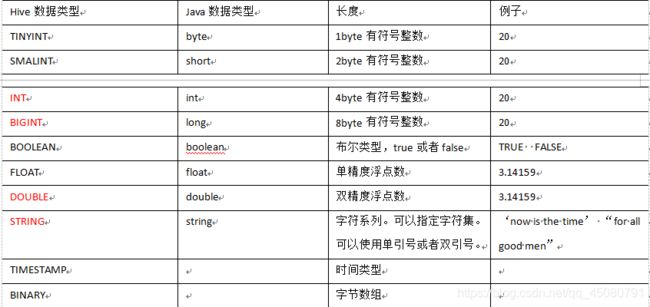
基本数据类型
复杂数据类型:
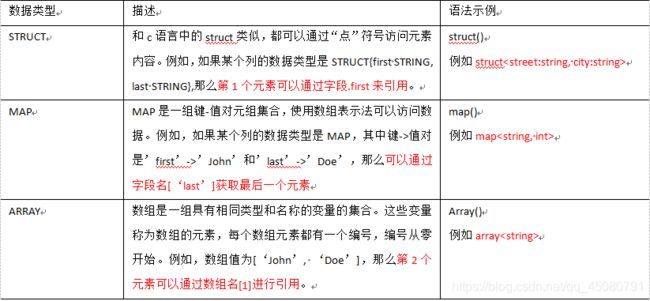
复杂数据类型允许任意层次嵌套
如果在一张表中既用到了数组,又用到了Map,要将元素于元素之间数据统一。
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //列表Array,
"children": {
//键值Map,
"xiao song": 18 ,
"xiaoxiao song": 19
}
"address": {
//结构Struct,
"street": "hui long guan" ,
"city": "beijing"
}
}
需求:基于上述数据结构,我们在Hive里创建对应的表,并导入数据。
数据准备:
[yyx@hadoop01 datas]$ vim text.txt
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
~
创建表:
0: jdbc:hive2://hadoop01:10000> create table test(
0: jdbc:hive2://hadoop01:10000> name string,
0: jdbc:hive2://hadoop01:10000> friends array<string>,
0: jdbc:hive2://hadoop01:10000> children map<string, int>,
0: jdbc:hive2://hadoop01:10000> address struct<street:string, city:string>
0: jdbc:hive2://hadoop01:10000> )
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by ','
0: jdbc:hive2://hadoop01:10000> collection items terminated by '_'
0: jdbc:hive2://hadoop01:10000> map keys terminated by ':'
0: jdbc:hive2://hadoop01:10000> lines terminated by '\n';
No rows affected (1.848 seconds)
row format delimited fields terminated by ‘,’ – 列分隔符
collection items terminated by ‘_’ --MAP STRUCT 和 ARRAY 的分隔符(数据分割符号)
map keys terminated by ‘:’ – MAP中的key与value的分隔符
lines terminated by ‘\n’; – 行分隔符
导入:
将其上传到hadoop
[yyx@hadoop01 datas]$ hadoop fs -put text.txt /user/hive/warehouse/test
查询:
0: jdbc:hive2://hadoop01:10000> select * from test;
+------------+----------------------+--------------------------------------+----------------------------------------------+--+
| test.name | test.friends | test.children | test.address |
+------------+----------------------+--------------------------------------+----------------------------------------------+--+
| songsong | ["bingbing","lili"] | {
"xiao song":18,"xiaoxiao song":19} | {
"street":"hui long guan","city":"beijing"} |
| yangyang | ["caicai","susu"] | {
"xiao yang":18,"xiaoxiao yang":19} | {
"street":"chao yang","city":"beijing"} |
+------------+----------------------+--------------------------------------+----------------------------------------------+--+
查询方式:数组和Java数组相同
Map:
children[‘xiao song’]
STRUCT则直接.
0: jdbc:hive2://hadoop01:10000> select friends[1],children['xiao song'],address.city from test
0: jdbc:hive2://hadoop01:10000> where name="songsong";
+-------+------+----------+--+
| _c0 | _c1 | city |
+-------+------+----------+--+
| lili | 18 | beijing |
+-------+------+----------+--+
1 row selected (0.269 seconds)
数据类型转换
Hive的数据类型是可以进行隐式转换的,类似于Java的类型转换,例如某表达式使用INT类型,TINYINT回自动转换为INT类型,但是Hive不会进行反向转化
1.隐式类型转换规则如下
(1)任何整数类型都可以隐式地转换为一个范围更广的类型,如TINYINT可以转换成INT,INT可以转换成BIGINT。
(2)所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE。
(3)TINYINT、SMALLINT、INT都可以转换为FLOAT。
(4)BOOLEAN类型不可以转换为任何其它的类型。
2.可以使用CAST操作显示进行数据类型转换
例如CAST(‘1’ AS INT)将把字符串’1’ 转换成整数1;如果强制类型转换失败,如执行CAST(‘X’ AS INT),表达式返回空值 NULL。
select '1'+2, cast('1'as int) + 2;
+------+------+--+
| _c0 | _c1 |
+------+------+--+
| 3.0 | 3 |
+------+------+--+
DDL数据定义
创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name //是否已经存在
[COMMENT database_comment] //备注
[LOCATION hdfs_path] //在HDFS存储位置
[WITH DBPROPERTIES (property_name=property_value, ...)];// 按KV值添加属性
查询数据库
1、 显示数据库
hive> show databases;
2、过滤显示查询数据库
hive> show databases like 'db_hive*';
OK
db_hive
db_hive_1
3、查看数据库信息
hive> desc database db_hive;
OK
db_hive hdfs://hadoop01:9000/user/hive/warehouse/db_hive.db yyxUSER
4、显示数据库详细信息(会显示KV值)
hive> desc database extended db_hive;
OK
db_hive hdfs://hadoop01:9000/user/hive/warehouse/db_hive.db yyxUSER
5、切换数据库
hive (default)> use db_hive;
修改数据库
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属性值,来描述这个数据库的属性信息。数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。
hive (default)> alter database db_hive set dbproperties('createtime'='20170830');
查看数据库详细信息:
hive> desc database extended db_hive;
db_name comment location owner_name owner_type parameters
db_hive hdfs://hadoop01:8020/user/hive/warehouse/db_hive.db yyx USER {
createtime=20170830}
删除数据库
1、删除数据库
hive>drop database db_hive2;
2、如果删除的数据库不确定是否存在,采用if exists判断数据库是否存在。
hive> drop database db_hive;
FAILED: SemanticException [Error 10072]: Database does not exist: db_hive
hive> drop database if exists db_hive2;
3、如果数据库不为空,可以采用cascade命令,强制删除
hive> drop database db_hive;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database db_hive is not empty. One or more tables exist.)
hive> drop database db_hive cascade;
创建表
创建语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
CREATE TABLE是床架一个指定名字的表,如果相同名字的表已经存在,则抛出异常,用户可以通过IF NOT EXISTS选项来忽略这个异常
EXTERNAL关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实际数据的路径(LOVATION),在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据
COMMENT:为表和列添加注释
PARTITIONED BY:创建分区表
CLUSTERED BY:创建分桶表
SORTED BY:对桶中的一个或多个列另外排序
[ROW FORMAT row_format] :定义行格式
[STORED AS file_format] :指定文件存储类型,常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件),如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
LOCATION:指定表在HDFS上的存储位置
AS:后面跟查询语句,根据查询结果创建表
管理表(内部表)
默认船舰的表都是内部表,因为这种表完全由Hive控制生命周期,当我们删除一个内部表是,Hive也会删除这个表中的数据,因此,内部表不适合和其他工具共享数据。
外部表
表是外部表,所以Hive并非完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除
内部表于外部表的相互转化
查询表类型:
可以通过MySQL元数据进行查询

或者用代码查询
hive (default)> desc formatted student;
Table Type: MANAGED_TABLE// 内部表
修改为外部表
alter table student2 set tblproperties('EXTERNAL'='TRUE');
注意:(‘EXTERNAL’=‘TRUE’)和(‘EXTERNAL’=‘FALSE’)为固定写法,区分大小写!
创建表时指定字段分割符
首先,创建一个表(用,分割)
0: jdbc:hive2://hadoop01:10000> create table stu1(id int,name string)
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by ',';
在创建一个表,不指定字段分割符
0: jdbc:hive2://hadoop01:10000> create table stu2(id int,name string);
No rows affected (0.079 seconds)
分别向两张表插入数据:
0: jdbc:hive2://hadoop01:10000> insert into stu1 values(1001,'zhangsan');
0: jdbc:hive2://hadoop01:10000> insert into stu2 values(1001,'zhangsan');
之后在hdfs上查看数据,stu1的数据显示为
1001,zhangsan
stu2的数据显示为:
1001zhangsan
这表示,如果不指定分隔符,那么hive将使用默认的分割符
同理。如果将不符合分隔符的数据传到HDFS上某个分隔符不同的表,那么,会对查询结果带来影响
修改/删除表
重命名表
ALTER TABLE table_name RENAME TO new_table_name
HDFS上的文件名也会修改
0: jdbc:hive2://hadoop01:10000> ALTER table stu1 rename to student1;
No rows affected (2.16 seconds)
0: jdbc:hive2://hadoop01:10000> show tables;
+------------------------+--+
| tab_name |
+------------------------+--+
| stu2 |
| student1 |
| values__tmp__table__1 |
| values__tmp__table__2 |
+------------------------+--+
4 rows selected (1.33 seconds)
不可以修改为已存在的表名
增加/修改/替换列信息(列名和列数据类型)
更新列(数据类型必须加上,哪怕修改前后一样)
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
如果不方便查询Mysql元数据,想查询表的数据类型等,可以通过
`0: jdbc:hive2://hadoop01:10000> desc formatted student1;
+-------------------------------+----------------------------------------------------------------+-----------------------+--+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------------------+-----------------------+--+
| # col_name | data_type | comment |
| | NULL | NULL |
| id | int | |
| name | string | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | yyx_hive | NULL |
| Owner: | yyx | NULL |
| CreateTime: | Mon Feb 22 16:34:00 CST 2021 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Protect Mode: | None | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://hadoop01:9000/user/hive/warehouse/yyx_hive.db/student1 | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | COLUMN_STATS_ACCURATE | true |
| | last_modified_by | yyx |
| | last_modified_time | 1613999491 |
| | numFiles | 1 |
| | numRows | 1 |
| | rawDataSize | 13 |
| | totalSize | 14 |
| | transient_lastDdlTime | 1613999491 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | field.delim | , |
| | serialization.format | , |
+-------------------------------+----------------------------------------------------------------+-----------------------+--+
`
可以发现id的数据类型时int,将其修改为string(并没有修改列名)
0: jdbc:hive2://hadoop01:10000> alter table student1 change id id string;
No rows affected (3.78 seconds)
0: jdbc:hive2://hadoop01:10000> desc formatted student1;
+-------------------------------+----------------------------------------------------------------+-----------------------+--+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------------------+-----------------------+--+
| # col_name | data_type | comment |
| | NULL | NULL |
| id | string | |
| name | string | |
| | NULL | NULL |
之后将其改回
0: jdbc:hive2://hadoop01:10000> alter table student1 change id id int;
增加或替换列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
ADD表示增加
REPLACE表示全部替换
演示
当前表
0: jdbc:hive2://hadoop01:10000> select * from stu2;
+----------+------------+--+
| stu2.id | stu2.name |
+----------+------------+--+
| 1001 | zhangsan |
+----------+------------+--+
减少一个列
0: jdbc:hive2://hadoop01:10000> alter table stu2 replace columns (id int);
No rows affected (4.018 seconds)
0: jdbc:hive2://hadoop01:10000> select * from stu2;
+----------+--+
| stu2.id |
+----------+--+
| 1001 |
+----------+--+
增加一个列
0: jdbc:hive2://hadoop01:10000> alter table stu2 replace columns (id int,name string,birthday timestamp);
No rows affected (0.145 seconds)
0: jdbc:hive2://hadoop01:10000> select * from stu2;
+----------+------------+----------------+--+
| stu2.id | stu2.name | stu2.birthday |
+----------+------------+----------------+--+
| 1001 | zhangsan | NULL |
+----------+------------+----------------+--+
1 row selected (0.141 seconds)
增加或者删除列只会修改元数据,并不会对hdfs中数据产生改变
删除表
0: jdbc:hive2://hadoop01:10000> drop table stu2;
No rows affected (1.418 seconds)
0: jdbc:hive2://hadoop01:10000> show tables;
+-----------+--+
| tab_name |
+-----------+--+
| student1 |
+-----------+--+
1 row selected (0.044 seconds)
注意内部表删除和外部表删除的区别
DML数据操作
数据导入
向表中加载数据(Load)
load data [local] inpath '/opt/module/datas/data.txt' [overwrite] into table table_name [partition (partcol1=val1,…)];
local:表示从本地加载到Hive表,否则懂HDFS加载
inpath:表示路径
overwrite:表示覆盖表中已有数据,否则表示追加
into table table_name:表示加载到哪张表
partiton:表示上传到指定分区
实操
创建一张表
0: jdbc:hive2://hadoop01:10000> create table student (id int, name String) row format delimited fields terminated by '\t';
No rows affected (0.314 seconds)
数据准备
[yyx@hadoop01 hive]$ vim student.txt
1001 yyx
1002 dlq
1003 nuomi
1004 lucky
加载本地文件到hive
0: jdbc:hive2://hadoop01:10000> load data local inpath './student.txt' into table yyx_hive.student;
INFO : Loading data to table yyx_hive.student from file:/opt/module/hive/student.txt
INFO : Table yyx_hive.student stats: [numFiles=1, totalSize=40]
No rows affected (2.823 seconds)
0: jdbc:hive2://hadoop01:10000> select * from student;
+-------------+---------------+--+
| student.id | student.name |
+-------------+---------------+--+
| 1001 | yyx |
| 1002 | dlq |
| 1003 | nuomi |
| 1004 | lucky |
+-------------+---------------+--+
4 rows selected (0.135 seconds)
对数据进行修改
[yyx@hadoop01 hive]$ vim student.txt
1001 yyx
1002 dlq
1003 nuomi
1004 lucky
1032 yl
2003 lhm
追加(允许重复数据存在)
0: jdbc:hive2://hadoop01:10000> load data local inpath './student.txt' into table yyx_hive.student;
INFO : Loading data to table yyx_hive.student from file:/opt/module/hive/student.txt
INFO : Table yyx_hive.student stats: [numFiles=2, totalSize=98]
No rows affected (0.351 seconds)
0: jdbc:hive2://hadoop01:10000> select * from student;
+-------------+---------------+--+
| student.id | student.name |
+-------------+---------------+--+
| 1001 | yyx |
| 1002 | dlq |
| 1003 | nuomi |
| 1004 | lucky |
| 1001 | yyx |
| 1002 | dlq |
| 1003 | nuomi |
| 1004 | lucky |
| 1032 | yl |
| 2003 | lhm |
| NULL | NULL |
+-------------+---------------+--+
11 rows selected (0.085 seconds)
将数据文件上传到HDFS
(yyx为文件名)
[yyx@hadoop01 hive]$ hdfs dfs -put student.txt /user/yyx
将文件覆盖到hive中student表
0: jdbc:hive2://hadoop01:10000> load data inpath '/user/yyx' overwrite into table student;
INFO : Loading data to table yyx_hive.student from hdfs://hadoop01:9000/user/yyx
INFO : Table yyx_hive.student stats: [numFiles=1, numRows=0, totalSize=58, rawDataSize=0]
No rows affected (0.448 seconds)
0: jdbc:hive2://hadoop01:10000> select * from student;
+-------------+---------------+--+
| student.id | student.name |
+-------------+---------------+--+
| 1001 | yyx |
| 1002 | dlq |
| 1003 | nuomi |
| 1004 | lucky |
| 1032 | yl |
| 2003 | lhm |
| NULL | NULL |
+-------------+---------------+--+
7 rows selected (0.122 seconds)
文件放到一张表中,用load
通过查询语句向表中插入数据(Insert)
单条数据插入
insert into table student partition(month='201709') values(1,'wangwu'),(2,’zhaoliu’);
基本插入数据
0: jdbc:hive2://hadoop01:10000> create table student2 (id int,name string ) row format delimited fields terminated by '/t';
No rows affected (0.229 seconds)
0: jdbc:hive2://hadoop01:10000> show tables;
+-----------+--+
| tab_name |
+-----------+--+
| student |
| student1 |
| student2 |
+-----------+--+
3 rows selected (0.047 seconds)
0: jdbc:hive2://hadoop01:10000> insert into table student2 values(1,'SS'),(2,'yangguang');
0: jdbc:hive2://hadoop01:10000> select * from student2;
+--------------+----------------+--+
| student2.id | student2.name |
+--------------+----------------+--+
| 1 | SS |
| 2 | yangguang |
+--------------+----------------+--+
2 rows selected (0.134 seconds)
0: jdbc:hive2://hadoop01:10000>
基本模式插入(根据单张表查询结果)
0: jdbc:hive2://hadoop01:10000> insert into(也可以是overwrite) table student2
0: jdbc:hive2://hadoop01:10000> select * from student;
0: jdbc:hive2://hadoop01:10000> select * from student2;
+--------------+----------------+--+
| student2.id | student2.name |
+--------------+----------------+--+
| 1 | SS |
| 2 | yangguang |
| 1001 | yyx |
| 1002 | dlq |
| 1003 | nuomi |
| 1004 | lucky |
| 1032 | yl |
| 2003 | lhm |
| NULL | NULL |
+--------------+----------------+--+
9 rows selected (0.076 seconds)
创建表时加载数据(As Select)
查询结果会直接添加到表中
0: jdbc:hive2://hadoop01:10000> create table student3
0: jdbc:hive2://hadoop01:10000> as select * from student;
创建表时通过Location来指定加载数据路径
首先,在HDFS上非Hive表默认位置创建一个文件夹
[yyx@hadoop01 hive]$ hdfs dfs -mkdir /student
之后,向该位置上传数据
[yyx@hadoop01 hive]$ hdfs dfs -put /opt/module/hive/student.txt /student
创建表,并指定在hdfs上的位置为刚刚创建的文件夹的位置
0: jdbc:hive2://hadoop01:10000> create table student5(id int,name string) row format delimited fields terminated by '\t' location '/student';
No rows affected (0.167 seconds)
0: jdbc:hive2://hadoop01:10000> select * from student5;
+--------------+----------------+--+
| student5.id | student5.name |
+--------------+----------------+--+
| 1001 | yyx |
| 1002 | dlq |
| 1003 | nuomi |
| 1004 | lucky |
| 1032 | yl |
| 2003 | lhm |
| NULL | NULL |
+--------------+----------------+--+
7 rows selected (0.097 seconds)
Import数据到指定的Hive中
import table table_name from '/user/hive/warehouse/export/'
只能导入export导出的数据
主要用于两个Hadoop集群之间数据的迁移
创建一个空表(或者直接导入,创建的话必须保证所有格式,包括字段分隔符相同)
0: jdbc:hive2://hadoop01:10000> create table student6(id int ,name string )
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by '\t';
导入
0: jdbc:hive2://hadoop01:10000> import table student6
0: jdbc:hive2://hadoop01:10000> from '/student';
INFO : Copying data from hdfs://hadoop01:9000/student/data to hdfs://hadoop01:9000/student/.hive-staging_hive_2021-02-24_11-42-34_761_1090775357266628372-1/-ext-10000
INFO : Copying file: hdfs://hadoop01:9000/student/data/000000_0
INFO : Copying file: hdfs://hadoop01:9000/student/data/yyx
INFO : Loading data to table yyx_hive.student6 from hdfs://hadoop01:9000/student/.hive-staging_hive_2021-02-24_11-42-34_761_1090775357266628372-1/-ext-10000
No rows affected (0.251 seconds)
0: jdbc:hive2://hadoop01:10000> select * from student6;
+--------------+----------------+--+
| student6.id | student6.name |
+--------------+----------------+--+
| 1007 | dali |
| 1080 | sanjin |
| 1001 | yyx |
| 1002 | dlq |
| 1003 | nuomi |
| 1004 | lucky |
| 1032 | yl |
| 2003 | lhm |
| NULL | NULL |
+--------------+----------------+--+
9 rows selected (0.083 seconds)
数据导出
Insert导出数据
将查询结果导出到本地
这样的数据不好看
0: jdbc:hive2://hadoop01:10000> insert overwrite local directory '/opt/module/hive/datas'
0: jdbc:hive2://hadoop01:10000> select * from student;
[yyx@hadoop01 datas]$ cat 000000_0
1001yyx
1002dlq
1003nuomi
1004lucky
1032yl
2003lhm
\N\N
将查询结果格式化导出到本地
0: jdbc:hive2://hadoop01:10000> insert overwrite local directory '/opt/module/hive/datas'
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by '\t'0: jdbc:hive2://hadoop01:10000> select * from student;
[yyx@hadoop01 datas]$ cat 000000_0
1001 yyx
1002 dlq
1003 nuomi
1004 lucky
1032 yl
2003 lhm
\N \N
将查询结果导出到HDFS上
0: jdbc:hive2://hadoop01:10000> insert overwrite directory '/datas' row format delimited fields terminated by '\t'
0: jdbc:hive2://hadoop01:10000> select * from student;
结果:
1001 yyx
1002 dlq
1003 nuomi
1004 lucky
1032 yl
2003 lhm
\N \N
Hive Shell导出
[yyx@hadoop01 hive]$ bin/hive -e 'select * from yyx_hive.student' > /opt/module/hive/datas/databyshell.txt
Logging initialized using configuration in jar:file:/opt/module/hive/lib/hive-common-1.2.1.jar!/hive-log4j.properties
OK
Time taken: 1.667 seconds, Fetched: 7 row(s)
[yyx@hadoop01 hive]$ cd datas/
[yyx@hadoop01 datas]$ ll
总用量 8
-rw-r--r--. 1 yyx yyx 63 2月 23 19:41 000000_0
-rw-rw-r--. 1 yyx yyx 91 2月 24 10:54 databyshell.txt
[yyx@hadoop01 datas]$ vim databyshell.txt
student.id student.name
1001 yyx
1002 dlq
1003 nuomi
1004 lucky
1032 yl
2003 lhm
NULL NULL
Export导出数据
export table table_name to 'HDFS路径'
用在两个Hadoop集群之间传输数据
导出到/student
export table student
0: jdbc:hive2://hadoop01:10000> to '/student';
INFO : Copying data from file:/tmp/yyx/a8a46f21-ab2c-476a-ba9a-24719b007281/hive_2021-02-24_11-41-42_275_703533597325481387-1/-local-10000/_metadata to hdfs://hadoop01:9000/student
INFO : Copying file: file:/tmp/yyx/a8a46f21-ab2c-476a-ba9a-24719b007281/hive_2021-02-24_11-41-42_275_703533597325481387-1/-local-10000/_metadata
INFO : Copying data from hdfs://hadoop01:9000/user/hive/warehouse/yyx_hive.db/student to hdfs://hadoop01:9000/student/data
INFO : Copying file: hdfs://hadoop01:9000/user/hive/warehouse/yyx_hive.db/student/000000_0
INFO : Copying file: hdfs://hadoop01:9000/user/hive/warehouse/yyx_hive.db/student/yyx
No rows affected (0.198 seconds)
连同元数据也会一起导出
清空表中数据
只能清空内部表,不能清空外部表
并不删除原数据,也就是说,show tables还有这个表
0: jdbc:hive2://hadoop01:10000> truncate table student1;
No rows affected (0.177 seconds)
0: jdbc:hive2://hadoop01:10000> select * from student1;
+--------------+----------------+--------------------+--+
| student1.id | student1.name | student1.birthday |
+--------------+----------------+--------------------+--+
+--------------+----------------+--------------------+--+
No rows selected (0.042 seconds)
DML查询
Apache官方网址
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Select
语法
[WITH CommonTableExpression (, CommonTableExpression)*] (Note: Only available
starting with Hive 0.13.0)
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]
数据准备:
创建部门表:
0: jdbc:hive2://hadoop01:10000> create table dept(deptno int,dname string,loc int)
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by '\t';
创建员工表
0: jdbc:hive2://hadoop01:10000> create table emp(
0: jdbc:hive2://hadoop01:10000> empno int,
0: jdbc:hive2://hadoop01:10000> ename string,
0: jdbc:hive2://hadoop01:10000> job string,
0: jdbc:hive2://hadoop01:10000> mgr int,
0: jdbc:hive2://hadoop01:10000> hiredate string,
0: jdbc:hive2://hadoop01:10000> sal double,
0: jdbc:hive2://hadoop01:10000> comm double,
0: jdbc:hive2://hadoop01:10000> deptno int)
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by '\t';
No rows affected (0.085 seconds)
导入数据:
0: jdbc:hive2://hadoop01:10000> load data local inpath '/opt/module/hive/datas/dept.txt' into table dept;
INFO : Loading data to table yyx_hive.dept from file:/opt/module/hive/datas/dept.txt
INFO : Table yyx_hive.dept stats: [numFiles=1, totalSize=71]
No rows affected (0.425 seconds)
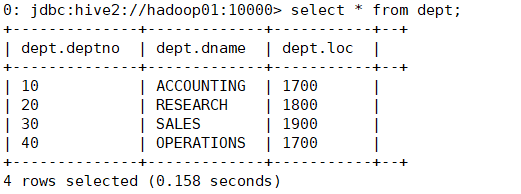
0: jdbc:hive2://hadoop01:10000> select * from dept;
+--------------+-------------+-----------+--+
| dept.deptno | dept.dname | dept.loc |
+--------------+-------------+-----------+--+
| 10 | ACCOUNTING | 1700 |
| 20 | RESEARCH | 1800 |
| 30 | SALES | 1900 |
| 40 | OPERATIONS | 1700 |
+--------------+-------------+-----------+--+
4 rows selected (0.082 seconds)
0: jdbc:hive2://hadoop01:10000> load data local inpath '/opt/module/hive/datas/emp.txt' into table emp;
INFO : Loading data to table yyx_hive.emp from file:/opt/module/hive/datas/emp.txt
INFO : Table yyx_hive.emp stats: [numFiles=1, totalSize=656]
No rows affected (0.321 seconds)
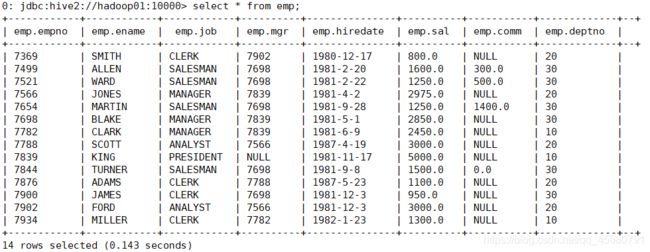
0: jdbc:hive2://hadoop01:10000> select * from emp;
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
14 rows selected (0.199 seconds)
全表查询(也可以将列全列出来,尽量不要用select * ,效果一样)
0: jdbc:hive2://hadoop01:10000> select deptno,dname,loc from dept;
+---------+-------------+-------+--+
| deptno | dname | loc |
+---------+-------------+-------+--+
| 10 | ACCOUNTING | 1700 |
| 20 | RESEARCH | 1800 |
| 30 | SALES | 1900 |
| 40 | OPERATIONS | 1700 |
+---------+-------------+-------+--+
4 rows selected (0.161 seconds)
查询注意事项
SQL语言大小写不敏感
SQL可以写在一行或者多行
关键字不能被缩写也不能分行
使用缩进提高可读性
列别名
重命名一个列,使它便于计算,通过AS关键字(AS可省)
0: jdbc:hive2://hadoop01:10000> select ename as name from emp;
+---------+--+
| name |
+---------+--+
| SMITH |
| ALLEN |
| WARD |
| JONES |
| MARTIN |
| BLAKE |
| CLARK |
| SCOTT |
| KING |
| TURNER |
| ADAMS |
| JAMES |
| FORD |
| MILLER |
+---------+--+
14 rows selected (0.16 seconds)
算术运算符

实操:
0: jdbc:hive2://hadoop01:10000> select ename,sal + 100 from emp;
+---------+---------+--+
| ename | _c1 |
+---------+---------+--+
| SMITH | 900.0 |
| ALLEN | 1700.0 |
| WARD | 1350.0 |
| JONES | 3075.0 |
| MARTIN | 1350.0 |
| BLAKE | 2950.0 |
| CLARK | 2550.0 |
| SCOTT | 3100.0 |
| KING | 5100.0 |
| TURNER | 1600.0 |
| ADAMS | 1200.0 |
| JAMES | 1050.0 |
| FORD | 3100.0 |
| MILLER | 1400.0 |
+---------+---------+--+
14 rows selected (0.159 seconds)
常用函数(MR很慢)
1.求总行数
0: jdbc:hive2://hadoop01:10000> select count(*) from emp;
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1614134996439_0002
INFO : The url to track the job: http://hadoop02:8088/proxy/application_1614134996439_0002/
INFO : Starting Job = job_1614134996439_0002, Tracking URL = http://hadoop02:8088/proxy/application_1614134996439_0002/
INFO : Kill Command = /opt/module/hadoop-2.7.2/bin/hadoop job -kill job_1614134996439_0002
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2021-02-24 15:14:14,310 Stage-1 map = 0%, reduce = 0%
INFO : 2021-02-24 15:14:26,780 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.23 sec
INFO : 2021-02-24 15:14:34,061 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.27 sec
INFO : MapReduce Total cumulative CPU time: 2 seconds 270 msec
INFO : Ended Job = job_1614134996439_0002
+------+--+
| _c0 |
+------+--+
| 14 |
+------+--+
1 row selected (33.455 seconds)
2.求工资最大值
0: jdbc:hive2://hadoop01:10000> select max(sal) max_sal from emp;
+----------+--+
| max_sal |
+----------+--+
| 5000.0 |
+----------+--+
3.求最小工资数
0: jdbc:hive2://hadoop01:10000> select min(sal) as min_sal from emp;
4.求总工资数
0: jdbc:hive2://hadoop01:10000> select sum(sal) from emp;
+----------+--+
| _c0 |
+----------+--+
| 29025.0 |
+----------+--+
5.求平均值
0: jdbc:hive2://hadoop01:10000> select avg(sal) avg_sal from emp;
+--------------------+--+
| avg_sal |
+--------------------+--+
| 2073.214285714286 |
+--------------------+--+
Limit语句
查询返回行数过多时,可以使用Limit限制行数
0: jdbc:hive2://hadoop01:10000> select * from emp limit 4;
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
4 rows selected (0.096 seconds)
Where语句
使用Where子句是为了过滤不满足条件的数据
where子句紧随From子句
找出薪资小于1000的员工
0: jdbc:hive2://hadoop01:10000> select * from emp as e where sal < 1000;
+----------+----------+--------+--------+-------------+--------+---------+-----------+--+
| e.empno | e.ename | e.job | e.mgr | e.hiredate | e.sal | e.comm | e.deptno |
+----------+----------+--------+--------+-------------+--------+---------+-----------+--+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
+----------+----------+--------+--------+-------------+--------+---------+-----------+--+
2 rows selected (0.072 seconds)
where子句中不能使用字段别名
SQL的执行顺序时先from,之后where,最后select,所以where无法使用别名
比较运算符与逻辑运算符
比较运算符(Between/In/ Is Null)
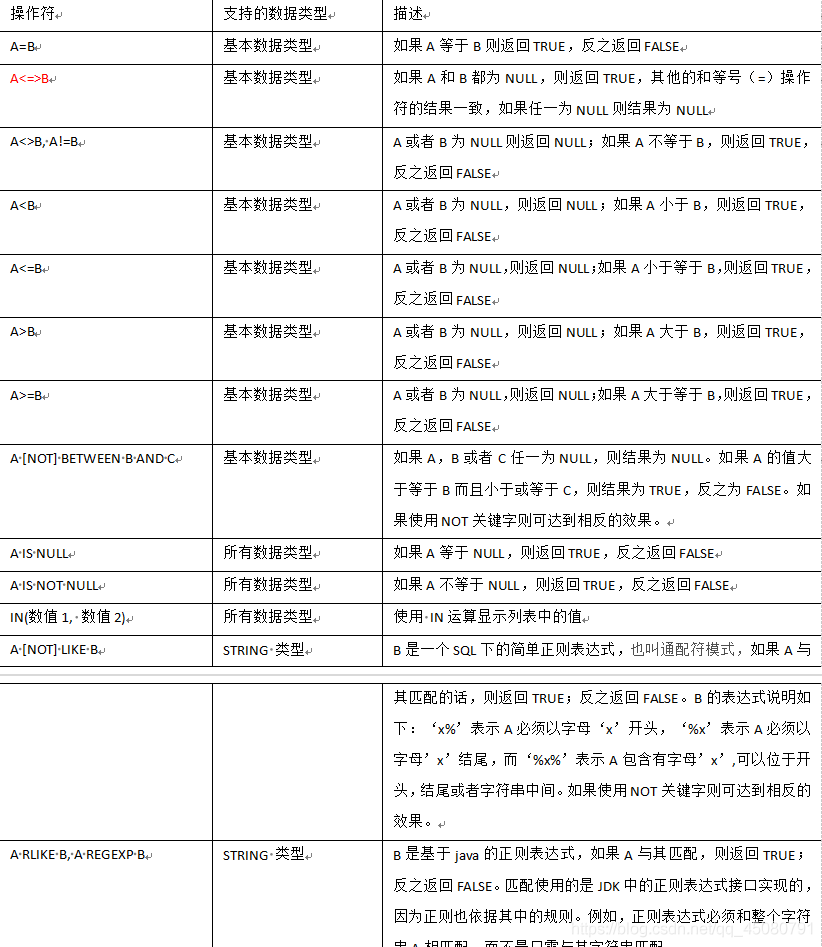
这些操作同样可用于Join on和Having中
实操:
查询薪水等于5000的所有员工
0: jdbc:hive2://hadoop01:10000> select * from emp where sal=5000;
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
1 row selected (0.392 seconds)
查询工资在800到1200之间的员工信息
0: jdbc:hive2://hadoop01:10000> select * from emp where sal between 800 and 1200;
+------------+------------+----------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+----------+----------+---------------+----------+-----------+-------------+--+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
+------------+------------+----------+----------+---------------+----------+-----------+-------------+--+
3 rows selected (0.076 seconds)
查询所有comm不是null的员工
0: jdbc:hive2://hadoop01:10000> select * from emp where comm is not null;
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
4 rows selected (0.051 seconds)
查询工资为1500或者5000的员工
0: jdbc:hive2://hadoop01:10000> select * from emp where sal in (5000,1500);
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
2 rows selected (0.065 seconds)
Like和RLike
使用Like选择类似的值
% 代表零个或多个字符(任意个字符)。
_ 代表一个字符。
RLIKE子句是Hive中这个功能的一个扩展,其可以通过Java的正则表达式这个更强大的语言来指定匹配条件。
实操:
查询以2开头薪水的员工
0: jdbc:hive2://hadoop01:10000> select * from emp where sal like '2%';
+------------+------------+----------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+----------+----------+---------------+----------+-----------+-------------+--+
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
+------------+------------+----------+----------+---------------+----------+-----------+-------------+--+
3 rows selected (0.076 seconds)
查询第二位为2的薪水的员工信息
0: jdbc:hive2://hadoop01:10000> select * from emp where sal like '_2%';
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
2 rows selected (0.038 seconds)
查询薪水中含有2的员工信息
0: jdbc:hive2://hadoop01:10000> select * from emp where sal like '%2%';
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
5 rows selected (0.114 seconds)
0: jdbc:hive2://hadoop01:10000> select * from emp where sal rlike '[2]';
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
5 rows selected (0.144 seconds)
逻辑运算符(And/Or/Not)
并或否
实操:
查询薪水大于1000并且部门为30的员工
0: jdbc:hive2://hadoop01:10000> select * from emp where sal >1000 and deptno = 30;
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
5 rows selected (0.088 seconds)
查询薪水大于1000或者部门是30的员工
0: jdbc:hive2://hadoop01:10000> select * from emp where sal >1000 or deptno = 30;
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
13 rows selected (0.066 seconds)
查询comm非空的员工信息
0: jdbc:hive2://hadoop01:10000> select * from emp where comm is not null;
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+--+
4 rows selected (0.063 seconds)
Group by
Group by 语句通常会和聚合函数一起使用,按照一个或多个列对结果进行分组,然后对每个组进行聚合操作
实操:
计算emp表每个部门的平均工资
每个部门,即,根据部门分组
0: jdbc:hive2://hadoop01:10000> select deptno,avg(sal) avf_sal from emp group by deptno;
+---------+---------------------+--+
| deptno | avf_sal |
+---------+---------------------+--+
| 10 | 2916.6666666666665 |
| 20 | 2175.0 |
| 30 | 1566.6666666666667 |
+---------+---------------------+--+
3 rows selected (32.097 seconds)
计算emp每个部门中每个岗位的最高薪水
0: jdbc:hive2://hadoop01:10000> select deptno,job, max(sal) from emp group by deptno,job;
+---------+------------+---------+--+
| deptno | job | _c2 |
+---------+------------+---------+--+
| 10 | CLERK | 1300.0 |
| 10 | MANAGER | 2450.0 |
| 10 | PRESIDENT | 5000.0 |
| 20 | ANALYST | 3000.0 |
| 20 | CLERK | 1100.0 |
| 20 | MANAGER | 2975.0 |
| 30 | CLERK | 950.0 |
| 30 | MANAGER | 2850.0 |
| 30 | SALESMAN | 1600.0 |
+---------+------------+---------+--+
Hiving
Hiving子句允许用户通过一个简单的语法完成原本需要子查询才能对Group by语句产生的分组进行过滤的任务
求出每个部门平均薪资大于两千的
0: jdbc:hive2://hadoop01:10000> select avg_sal,deptno from (select deptno,avg(sal) avg_sal from emp group by deptno)t where avg_sal > 2000;
+---------------------+---------+--+
| avg_sal | deptno |
+---------------------+---------+--+
| 2916.6666666666665 | 10 |
| 2175.0 | 20 |
+---------------------+---------+--+
t表示内部的表
或者
0: jdbc:hive2://hadoop01:10000> select deptno,avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;
+---------+---------------------+--+
| deptno | avg_sal |
+---------+---------------------+--+
| 10 | 2916.6666666666665 |
| 20 | 2175.0 |
+---------+---------------------+--+
Join
Hive支持SQL Join语句,但是只支持等值连接,不支持非等值连接
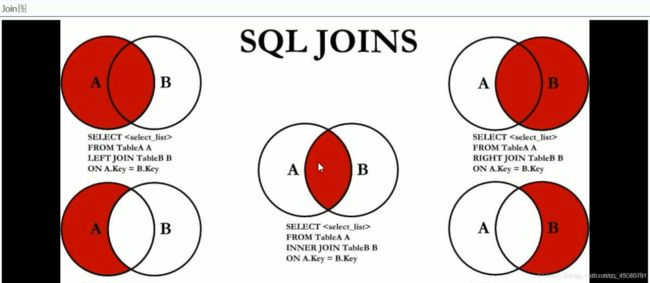
内连接(两个表中交集)
只有进行连接两个表中都存在与连接条件相匹配的的数据才会被保留下来
0: jdbc:hive2://hadoop01:10000> select e.empno,e.ename,d.deptno
0: jdbc:hive2://hadoop01:10000> from emp e
0: jdbc:hive2://hadoop01:10000> join dept d
0: jdbc:hive2://hadoop01:10000> on e.deptno=d.deptno;
+----------+----------+-----------+--+
| e.empno | e.ename | d.deptno |
+----------+----------+-----------+--+
| 7369 | SMITH | 20 |
| 7499 | ALLEN | 30 |
| 7521 | WARD | 30 |
| 7566 | JONES | 20 |
| 7654 | MARTIN | 30 |
| 7698 | BLAKE | 30 |
| 7782 | CLARK | 10 |
| 7788 | SCOTT | 20 |
| 7839 | KING | 10 |
| 7844 | TURNER | 30 |
| 7876 | ADAMS | 20 |
| 7900 | JAMES | 30 |
| 7902 | FORD | 20 |
| 7934 | MILLER | 10 |
+----------+----------+-----------+--+
14 rows selected (24.677 seconds)
左外连接(AB表中A表的部分)
Join操作符左边表中符合Where的子句所有记录都会被返回,右表中如果没有符合哦那后面的连接条件的,那么游标指定选择的列值将会是null
0: jdbc:hive2://hadoop01:10000> select e.empno,e.ename,d.deptno
0: jdbc:hive2://hadoop01:10000> from dept d
0: jdbc:hive2://hadoop01:10000> left outer join emp e
0: jdbc:hive2://hadoop01:10000> on e.deptno = d.deptno;
+----------+----------+-----------+--+
| e.empno | e.ename | d.deptno |
+----------+----------+-----------+--+
| 7782 | CLARK | 10 |
| 7839 | KING | 10 |
| 7934 | MILLER | 10 |
| 7369 | SMITH | 20 |
| 7566 | JONES | 20 |
| 7788 | SCOTT | 20 |
| 7876 | ADAMS | 20 |
| 7902 | FORD | 20 |
| 7499 | ALLEN | 30 |
| 7521 | WARD | 30 |
| 7654 | MARTIN | 30 |
| 7698 | BLAKE | 30 |
| 7844 | TURNER | 30 |
| 7900 | JAMES | 30 |
| NULL | NULL | 40 |
+----------+----------+-----------+--+
e表中没有deptno为40的
本次查询左外连接是以dept为主表(左表)
右外连接
0: jdbc:hive2://hadoop01:10000> select e.empno,e.ename,d.deptno
0: jdbc:hive2://hadoop01:10000> from dept d
0: jdbc:hive2://hadoop01:10000> right outer join emp e
0: jdbc:hive2://hadoop01:10000> on e.deptno=d.deptno;
+----------+----------+-----------+--+
| e.empno | e.ename | d.deptno |
+----------+----------+-----------+--+
| 7369 | SMITH | 20 |
| 7499 | ALLEN | 30 |
| 7521 | WARD | 30 |
| 7566 | JONES | 20 |
| 7654 | MARTIN | 30 |
| 7698 | BLAKE | 30 |
| 7782 | CLARK | 10 |
| 7788 | SCOTT | 20 |
| 7839 | KING | 10 |
| 7844 | TURNER | 30 |
| 7876 | ADAMS | 20 |
| 7900 | JAMES | 30 |
| 7902 | FORD | 20 |
| 7934 | MILLER | 10 |
+----------+----------+-----------+--+
14 rows selected (18.63 seconds)
以emp为右表(主表)查询
满外连接
nvl(a,b):如果a为null就为b
0: jdbc:hive2://hadoop01:10000> select e.empno,e.ename,nvl(d.deptno,e.deptno)
0: jdbc:hive2://hadoop01:10000> from emp e
0: jdbc:hive2://hadoop01:10000> full outer join dept d
0: jdbc:hive2://hadoop01:10000> on e.deptno=d.deptno;
+----------+----------+------+--+
| e.empno | e.ename | _c2 |
+----------+----------+------+--+
| 7934 | MILLER | 10 |
| 7839 | KING | 10 |
| 7782 | CLARK | 10 |
| 7876 | ADAMS | 20 |
| 7788 | SCOTT | 20 |
| 7369 | SMITH | 20 |
| 7566 | JONES | 20 |
| 7902 | FORD | 20 |
| 7844 | TURNER | 30 |
| 7499 | ALLEN | 30 |
| 7698 | BLAKE | 30 |
| 7654 | MARTIN | 30 |
| 7521 | WARD | 30 |
| 7900 | JAMES | 30 |
| NULL | NULL | 40 |
+----------+----------+------+--+
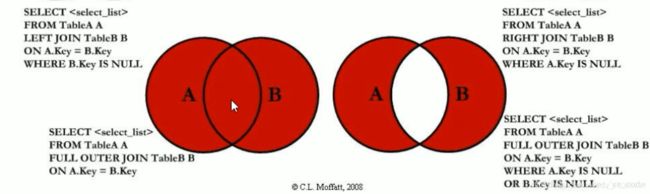
左连接(左表独有的数据)
即右表没有的数据
查询部门号,且部门员工信息为null
where后不能加字段别名,可以加表别名
0: jdbc:hive2://hadoop01:10000> select e.empno,e.ename,d.deptno
0: jdbc:hive2://hadoop01:10000> from dept d
0: jdbc:hive2://hadoop01:10000> left outer join emp e
0: jdbc:hive2://hadoop01:10000> on e.deptno = d.deptno
0: jdbc:hive2://hadoop01:10000> where e.empno is null;
+----------+----------+-----------+--+
| e.empno | e.ename | d.deptno |
+----------+----------+-----------+--+
| NULL | NULL | 40 |
+----------+----------+-----------+--+
写法二:
这样写不推荐
0: jdbc:hive2://hadoop01:10000> select d.deptno
0: jdbc:hive2://hadoop01:10000> from dept d
0: jdbc:hive2://hadoop01:10000> where d.deptno not in (select deptno from emp);
+-----------+--+
| d.deptno |
+-----------+--+
| 40 |
+-----------+--+
右连接
0: jdbc:hive2://hadoop01:10000> select e.empno,e.ename
0: jdbc:hive2://hadoop01:10000> from dept d
0: jdbc:hive2://hadoop01:10000> right join emp e
0: jdbc:hive2://hadoop01:10000> on e.deptno = d.deptno
0: jdbc:hive2://hadoop01:10000> where d.deptno is null;
+----------+----------+--+
| e.empno | e.ename |
+----------+----------+--+
+----------+----------+--+
两张表都没有出现交集的数据集
即左连接和右连接拼接
union(去重)
union all(不去重)
select * from
0: jdbc:hive2://hadoop01:10000> (select e.empno,e.ename,d.deptno from dept d left outer join emp e on e.deptno = d.deptno where e.empno is null union select e.empno,e.ename,d.deptno from dept d right join emp e on e.deptno = d.deptno where d.deptno is null)tmp;
+------------+------------+-------------+--+
| tmp.empno | tmp.ename | tmp.deptno |
+------------+------------+-------------+--+
| NULL | NULL | 40 |
+------------+------------+-------------+--+
或从全连接中筛选
0: jdbc:hive2://hadoop01:10000> select e.empno,e.ename,nvl(d.deptno,e.deptno)
0: jdbc:hive2://hadoop01:10000> from emp e
0: jdbc:hive2://hadoop01:10000> full outer join dept d
0: jdbc:hive2://hadoop01:10000> on e.deptno=d.deptno
0: jdbc:hive2://hadoop01:10000> where e.empno is null or d.deptno is null;
+----------+----------+------+--+
| e.empno | e.ename | _c2 |
+----------+----------+------+--+
| NULL | NULL | 40 |
+----------+----------+------+--+
多表连接
创建数据
[yyx@hadoop01 datas]$ vim location.txt
1700 Beijing
1800 London
1900 Tokyo
创建表并导入
0: jdbc:hive2://hadoop01:10000> create table location(loc int,loc_name string)
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by '\t';
No rows affected (3.285 seconds)
0: jdbc:hive2://hadoop01:10000> load data local inpath '/opt/module/hive/datas/location.txt' into table location;
INFO : Loading data to table yyx_hive.location from file:/opt/module/hive/datas/location.txt
INFO : Table yyx_hive.location stats: [numFiles=1, totalSize=36]
No rows affected (1.071 seconds)
0: jdbc:hive2://hadoop01:10000> select * from location;
+---------------+--------------------+--+
| location.loc | location.loc_name |
+---------------+--------------------+--+
| 1700 | Beijing |
| 1800 | London |
| 1900 | Tokyo |
+---------------+--------------------+--+
3 rows selected (0.124 seconds)
查询员工姓名,部门名称以及部门所在城市名称
0: jdbc:hive2://hadoop01:10000> select e.ename,d.dname,l.loc_name
0: jdbc:hive2://hadoop01:10000> from emp e
0: jdbc:hive2://hadoop01:10000> join dept d
0: jdbc:hive2://hadoop01:10000> on d.deptno=e.deptno
0: jdbc:hive2://hadoop01:10000> join location l
0: jdbc:hive2://hadoop01:10000> on l.loc=d.loc;
+----------+-------------+-------------+--+
| e.ename | d.dname | l.loc_name |
+----------+-------------+-------------+--+
| SMITH | RESEARCH | London |
| ALLEN | SALES | Tokyo |
| WARD | SALES | Tokyo |
| JONES | RESEARCH | London |
| MARTIN | SALES | Tokyo |
| BLAKE | SALES | Tokyo |
| CLARK | ACCOUNTING | Beijing |
| SCOTT | RESEARCH | London |
| KING | ACCOUNTING | Beijing |
| TURNER | SALES | Tokyo |
| ADAMS | RESEARCH | London |
| JAMES | SALES | Tokyo |
| FORD | RESEARCH | London |
| MILLER | ACCOUNTING | Beijing |
+----------+-------------+-------------+--+
14 rows selected (22.208 seconds)
笛卡尔积
产生条件
省略连接条件
连接条件无效
所有表中所有行互相连接
笛卡尔积是要避免的,因为数据没有意义
排序
全局排序(Order by)
Order by只有一个Reducer
DESC表降序
ASC表升序
查询员工信息(升序)
0: jdbc:hive2://hadoop01:10000> select * from emp order by sal;
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
14 rows selected (29.88 seconds)
多个列排列:
按照员工薪水以及员工编号排序(降序)
以员工编号为主
0: jdbc:hive2://hadoop01:10000> select * from emp order by empno,sal desc;
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
14 rows selected (21.997 seconds)
在大规模数据集的时候,并不经常使用Order by,因为只有一个MapReduce,会很慢
每个Reduce内部排序(Sort by)
Sort by为每个reducer产生一个排序文件。每个Reducer内部进行排序,对全局结果集来说不是排序。
设置reduce个数
set mapreduce.job.reduces=3;
查询reduce个数
0: jdbc:hive2://hadoop01:10000> set mapreduce.job.reduces;
+--------------------------+--+
| set |
+--------------------------+--+
| mapreduce.job.reduces=3 |
+--------------------------+--+
1 row selected (0.01 seconds)
根据部门编号降序查看员工信息
0: jdbc:hive2://hadoop01:10000> select * from emp sort by deptno desc;
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 |
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
14 rows selected (27.73 seconds)
多个reduce,因此部门编号在每个reduce中都是降序的
分区排序(distribute by)
在有些情况下,我们需要控制某个特定行应该到哪个reducer,通常是为了进行后续的聚集操作。distribute by 子句可以做这件事。distribute by类似MR中partition(自定义分区),进行分区,结合sort by使用。
对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。
按照部门编号分区再按照员工编号排序
0: jdbc:hive2://hadoop01:10000> select * from emp distribute by deptno sort by empno;
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
| 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 |
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
distribute by的分区规则是根据分区字段的hash码与reduce的个数进行模除后,余数相同的分到一个区。
Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。
Cluster By
当分区字段和排序字段都相同且都用升序排列时,可以用Clister by来减少代码量
0: jdbc:hive2://hadoop01:10000> select * from emp cluster by deptno;
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 |
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
按照部门编号分区,不一定就是固定死的数值,可以是20号和30号部门分到一个分区里面去。
分区表
即通过将表内部分区来是表分割,并且通过扫描一个分区来提高效率
分区表创建
数据准备
[yyx@hadoop01 datas]$ cat dept1.txt
10 ACCOUNTING 1700
20 RESEARCH 1800
[yyx@hadoop01 datas]$ cat dept2.txt
30 SALES 1900
40 OPERATIONS 1700
[yyx@hadoop01 datas]$ cat dept3.txt
50 TEST 2000
60 DEV 1900
创建表
0: jdbc:hive2://hadoop01:10000> create table dept_par2(deptno int,dname string,loc string)
0: jdbc:hive2://hadoop01:10000> partitioned by (day string)
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by '\t';
数据导入
0: jdbc:hive2://hadoop01:10000> load data local inpath '/opt/module/hive/datas/dept1.txt' into table dept_par
0: jdbc:hive2://hadoop01:10000> partition (day = '2021-02-07)
…
0: jdbc:hive2://hadoop01:10000> select * from dept_par;
+------------------+-----------------+---------------+---------------+--+
| dept_par.deptno | dept_par.dname | dept_par.loc | dept_par.day |
+------------------+-----------------+---------------+---------------+--+
| 10 | ACCOUNTING | 1700 | 2021-02-27 |
| 20 | RESEARCH | 1800 | 2021-02-27 |
| 30 | SALES | 1900 | 2021-02-28 |
| 40 | OPERATIONS | 1700 | 2021-02-28 |
| 50 | TEST | 2000 | 2021-03-01 |
| 60 | DEV | 1900 | 2021-03-01 |
+------------------+-----------------+---------------+---------------+--+
6 rows selected (0.367 seconds)
查询可以通过where子句来扫描特定分区
0: jdbc:hive2://hadoop01:10000> select * from dept_par where day = '2021-02-27';
+------------------+-----------------+---------------+---------------+--+
| dept_par.deptno | dept_par.dname | dept_par.loc | dept_par.day |
+------------------+-----------------+---------------+---------------+--+
| 10 | ACCOUNTING | 1700 | 2021-02-27 |
| 20 | RESEARCH | 1800 | 2021-02-27 |
+------------------+-----------------+---------------+---------------+--+
2 rows selected (0.559 seconds)
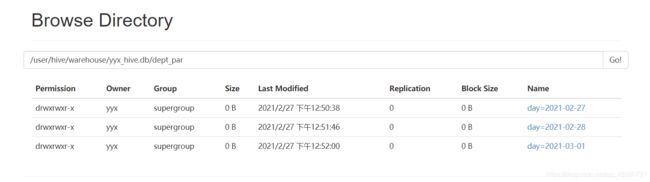
分区表的增删查
增加一个分区:
0: jdbc:hive2://hadoop01:10000> alter table dept_par add partition(day='2020-01-01');
增加多个分区
(中间是空格)
0: jdbc:hive2://hadoop01:10000> alter table dept_par add partition(day='2020-01-02') partition(day='2020-01-03');
删除分区:
中间是逗号
0: jdbc:hive2://hadoop01:10000> alter table dept_par drop partition(day='2020-01-02'),partition(day='2020-01-01'),partition(day='2020-01-03');
查看分区:
0: jdbc:hive2://hadoop01:10000> show partitions dept_par;
+-----------------+--+
| partition |
+-----------------+--+
| day=2021-02-27 |
| day=2021-02-28 |
| day=2021-03-01 |
+-----------------+--+
3 rows selected (0.15 seconds)
查看分区描述字段
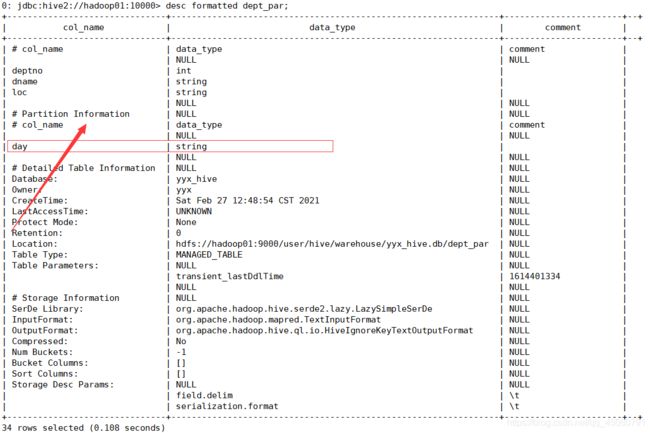
二级分区
创建
create table dept_part2(
deptno int, dname string, loc string
)
partitioned by (month string, day string)
row format delimited fields terminated by '\t';
数据导入
load data local inpath '/opt/module/datas/dept1.txt' into table
default.dept_partition2 partition(day='2021-03-01 ', hour='11');
…
0: jdbc:hive2://hadoop01:10000> select * from dept_par2;
+-------------------+------------------+----------------+----------------+-----------------+--+
| dept_par2.deptno | dept_par2.dname | dept_par2.loc | dept_par2.day | dept_par2.hour |
+-------------------+------------------+----------------+----------------+-----------------+--+
| 10 | ACCOUNTING | 1700 | 2021-03-01 | 11 |
| 20 | RESEARCH | 1800 | 2021-03-01 | 11 |
| 30 | SALES | 1900 | 2021-03-01 | 12 |
| 40 | OPERATIONS | 1700 | 2021-03-01 | 12 |
| 50 | TEST | 2000 | 2021-03-02 | 11 |
| 60 | DEV | 1900 | 2021-03-02 | 11 |
+-------------------+------------------+----------------+----------------+-----------------+--+
6 rows selected (0.152 seconds)
查询:
0: jdbc:hive2://hadoop01:10000> select deptno,dname from dept_par2 where day = '2021-03-01' and hour = '12';
+---------+-------------+--+
| deptno | dname |
+---------+-------------+--+
| 30 | SALES |
| 40 | OPERATIONS |
+---------+-------------+--+
2 rows selected (0.161 seconds)
分区和HDFS
正常情况下,将表创建好,并将数据文件通过HDFS命令上传到该目录,在Hive中也可以显示,但是分区表不可以。
分区表向通过HDFS上传后在Hive显示只有三种方式
上传数据后修复
即将数据上传到指定目录后,再修复
例如:
[yyx@hadoop01 datas]$ hdfs dfs -mkdir '/user/hive/warehouse/yyx_hive.db/dept_par/day=2021-03-02';
现在的HDFS文件
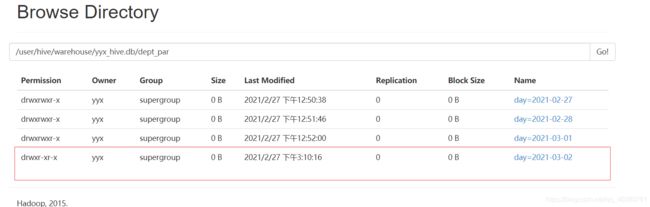
将数据上传到该目录
[yyx@hadoop01 datas]$ hdfs dfs -put dept1.txt /user/hive/warehouse/yyx_hive.db/dept_par/day=2021-03-02

但是我们查询不到
0: jdbc:hive2://hadoop01:10000> select * from dept_par where day = '2021-03-02';
+------------------+-----------------+---------------+---------------+--+
| dept_par.deptno | dept_par.dname | dept_par.loc | dept_par.day |
+------------------+-----------------+---------------+---------------+--+
+------------------+-----------------+---------------+---------------+--+
No rows selected (0.237 seconds)
修复命令
0: jdbc:hive2://hadoop01:10000> msck repair table dept_par;
No rows affected (0.267 seconds)
0: jdbc:hive2://hadoop01:10000> select * from dept_par where day = '2021-03-02';
+------------------+-----------------+---------------+---------------+--+
| dept_par.deptno | dept_par.dname | dept_par.loc | dept_par.day |
+------------------+-----------------+---------------+---------------+--+
| 10 | ACCOUNTING | 1700 | 2021-03-02 |
| 20 | RESEARCH | 1800 | 2021-03-02 |
+------------------+-----------------+---------------+---------------+--+
2 rows selected (0.112 seconds)
上传数据后添加分区
上传数据
[yyx@hadoop01 datas]$ hdfs dfs -mkdir '/user/hive/warehouse/yyx_hive.db/dept_par/day=2021-03-03'
[yyx@hadoop01 datas]$ hdfs dfs -put dept2.txt /user/hive/warehouse/yyx_hive.db/dept_par/day=2021-03-03/
添加分区
0: jdbc:hive2://hadoop01:10000> alter table dept_par add partition(day='2021-03-03');
查询
0: jdbc:hive2://hadoop01:10000> select * from dept_par where day = '2021-03-03';
+------------------+-----------------+---------------+---------------+--+
| dept_par.deptno | dept_par.dname | dept_par.loc | dept_par.day |
+------------------+-----------------+---------------+---------------+--+
| 30 | SALES | 1900 | 2021-03-03 |
| 40 | OPERATIONS | 1700 | 2021-03-03 |
+------------------+-----------------+---------------+---------------+--+
2 rows selected (0.137 seconds)
上传文件后load数据到分区
…
动态分区
首先,开启动态分区功能(默认打开的true)
hive.exec.dynamic.partition=true
设置为非严格模式(默认为严格模式):
hive.exec.dynamic.partition.mode=nostrict
在所有执行的MR节点上,最大可以创建1000个动态分区(默认的)
hive.exec.max.dynamic.partition.pernode=100
创建动态分区表
0: jdbc:hive2://hadoop01:10000> create table dept_no_par(dname string,loc int)
0: jdbc:hive2://hadoop01:10000> partitioned by(deptno int)
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by '\t';
注意,此处我们在正常字段中并没有设置deptno字段
数据导入
注意,并不是因为字段名相同,而是因为默认查询的最后一个字段做为分区字段
0: jdbc:hive2://hadoop01:10000> insert into table dept_no_par partition(deptno)
0: jdbc:hive2://hadoop01:10000> select dname,loc,deptno from dept;
0: jdbc:hive2://hadoop01:10000> select * from dept_no_par;
+--------------------+------------------+---------------------+--+
| dept_no_par.dname | dept_no_par.loc | dept_no_par.deptno |
+--------------------+------------------+---------------------+--+
| ACCOUNTING | 1700 | 10 |
| RESEARCH | 1800 | 20 |
| SALES | 1900 | 30 |
| OPERATIONS | 1700 | 40 |
+--------------------+------------------+---------------------+--+
4 rows selected (0.308 seconds)
分桶表(数据集极大的地方能用到)
分区表是针对数据的存储路径,分桶表则是针对数据文件
数据准备:
[yyx@hadoop01 datas]$ vim dupt_datas.txt
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
创建分桶表
0: jdbc:hive2://hadoop01:10000> create table stu_buck(id int,name string)
0: jdbc:hive2://hadoop01:10000> clustered by(id)
0: jdbc:hive2://hadoop01:10000> into 4 buckets
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by '\t';
设置属性:
set hive.enforce.bucketing=true;
set mapreduce.job.reduces=-1;
数据导入
创建分桶表时,数据通过子查询的方式导入
先创建一个普通的stu表
在向其中导入数据
0: jdbc:hive2://hadoop01:10000> create table stu(id int, name string)
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by '\t';
0: jdbc:hive2://hadoop01:10000> load data local inpath '/opt/module/hive/datas/dupt_datas.txt' into table stu;
通过子查询导入:
0: jdbc:hive2://hadoop01:10000> insert into table stu_buck
0: jdbc:hive2://hadoop01:10000> select id, name from stu;
0: jdbc:hive2://hadoop01:10000> select * from stu_buck;
+--------------+----------------+--+
| stu_buck.id | stu_buck.name |
+--------------+----------------+--+
| 1016 | ss16 |
| 1012 | ss12 |
| 1008 | ss8 |
| 1004 | ss4 |
| 1009 | ss9 |
| 1005 | ss5 |
| 1001 | ss1 |
| 1013 | ss13 |
| 1010 | ss10 |
| 1002 | ss2 |
| 1006 | ss6 |
| 1014 | ss14 |
| 1003 | ss3 |
| 1011 | ss11 |
| 1007 | ss7 |
| 1015 | ss15 |
+--------------+----------------+--+
16 rows selected (0.145 seconds)
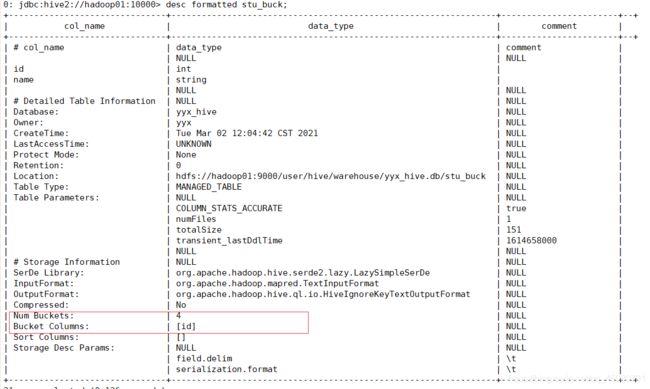
分桶抽样查询
对于非常大量的数据集,又是用户需要使用的一个具代表性的查询结果而不是全部查询结果,Hive可以通过对表进行抽样来满足这个需求。
0: jdbc:hive2://hadoop01:10000> select * from stu_buck tablesample(bucket 1 out
+--------------+----------------+--+
| stu_buck.id | stu_buck.name |
+--------------+----------------+--+
| 1016 | ss16 |
| 1012 | ss12 |
| 1008 | ss8 |
| 1004 | ss4 |
+--------------+----------------+--+
tablesample是抽样语句,语法:TABLESAMPLE(BUCKET x OUT OF y) 。
y是表的bucket数的倍数或因子。hive根据y的大小决定抽样比例,比如,table共分了4份,当y=2时,抽取4/2=2个bucket的数据,当y=8时,抽取4/8个bucket的数据x表示从哪个bucket开始抽取,如果需要多个分区,以后的分区好为当前分区号加上y,例如,table总bucket数为4,tablesample(bucket 1 out of 2),表示总共抽取(4/2)个bucket的数据,抽取第1(x)个和第三(x+y)个bucket的数据
x的值必须小于等于y的值
函数
系统内置函数
查看内置函数:
show functions;
216 rows selected (0.081 seconds)
显示内置函数用法
0: jdbc:hive2://hadoop01:10000> desc function +;
+----------------------+--+
| tab_name |
+----------------------+--+
| a + b - Returns a+b |
+----------------------+--+
1 row selected (0.057 seconds)
显示用法:
0: jdbc:hive2://hadoop01:10000> desc function extended =;
+---------------------------------------------------------+--+
| tab_name |
+---------------------------------------------------------+--+
| a = b - Returns TRUE if a equals b and false otherwise |
| Synonyms: == |
+---------------------------------------------------------+--+
2 rows selected (0.043 seconds)
常用查询函数
空字段函数(nvl)
函数说明:给值为NULL的数据复制,它的格式为NVL(value,default_value),它的功能时如果value为NULL,则NVL函数返回default_value的值,否则返回value的值,如果两个参数都为null,那么返回null
如果员工comm为null,那么用-1代替
0: jdbc:hive2://hadoop01:10000> select ename,empno ,nvl(comm,-1) from emp;
+---------+--------+---------+--+
| ename | empno | _c2 |
+---------+--------+---------+--+
| SMITH | 7369 | -1.0 |
| ALLEN | 7499 | 300.0 |
| WARD | 7521 | 500.0 |
| JONES | 7566 | -1.0 |
| MARTIN | 7654 | 1400.0 |
| BLAKE | 7698 | -1.0 |
| CLARK | 7782 | -1.0 |
| SCOTT | 7788 | -1.0 |
| KING | 7839 | -1.0 |
| TURNER | 7844 | 0.0 |
| ADAMS | 7876 | -1.0 |
| JAMES | 7900 | -1.0 |
| FORD | 7902 | -1.0 |
| MILLER | 7934 | -1.0 |
+---------+--------+---------+--+
14 rows selected (0.104 seconds)
CASE WHEN THEN ELSE END
数据准备:
[yyx@hadoop01 datas]$ vim emp_sex.txt;
悟空 A 男
大海 A 男
宋宋 B 男
凤姐 A 女
婷姐 B 女
婷婷 B 女
创建表并导入数据
0: jdbc:hive2://hadoop01:10000> create table emp_sex(
0: jdbc:hive2://hadoop01:10000> name string,
0: jdbc:hive2://hadoop01:10000> dept_id string,
0: jdbc:hive2://hadoop01:10000> sex string)
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by "\t";
0: jdbc:hive2://hadoop01:10000> load data local inpath '/opt/module/hive/datas/emp_sex.txt' into table emp_sex;
需求:求出不同部门的男女各多少人?
A 2 1
B 1 2
0: jdbc:hive2://hadoop01:10000> select
0: jdbc:hive2://hadoop01:10000> dept_id,
0: jdbc:hive2://hadoop01:10000> sum(case sex when '男' then 1 else 0 end) male_count,
0: jdbc:hive2://hadoop01:10000> sum(case sex when '女' then 1 else 0 end) female_count
0: jdbc:hive2://hadoop01:10000> from
0: jdbc:hive2://hadoop01:10000> emp_sex
0: jdbc:hive2://hadoop01:10000> group by
0: jdbc:hive2://hadoop01:10000> dept_id;
+----------+-------------+---------------+--+
| dept_id | male_count | female_count |
+----------+-------------+---------------+--+
| A | 2 | 1 |
| B | 1 | 2 |
+----------+-------------+---------------+--+
2 rows selected (33.743 seconds)
也可以用if函数
0: jdbc:hive2://hadoop01:10000> select dept_id,
0: jdbc:hive2://hadoop01:10000> sum(if(sex='男',1,0)) male_count,
0: jdbc:hive2://hadoop01:10000> sum(if(sex='女',1,0)) female_count
0: jdbc:hive2://hadoop01:10000> from emp_sex
0: jdbc:hive2://hadoop01:10000> group by dept_id;
+----------+-------------+---------------+--+
| dept_id | male_count | female_count |
+----------+-------------+---------------+--+
| A | 2 | 1 |
| B | 1 | 2 |
+----------+-------------+---------------+--+
2 rows selected (30.622 seconds)
行转列
相关函数说明
CONCAT(A,B,C…):返回输入字符串连接后的结果,支持任意个输入字符串
0: jdbc:hive2://hadoop01:10000> select concat(ename,'-',job) from emp;
+------------------+--+
| _c0 |
+------------------+--+
| SMITH-CLERK |
| ALLEN-SALESMAN |
| WARD-SALESMAN |
| JONES-MANAGER |
| MARTIN-SALESMAN |
| BLAKE-MANAGER |
| CLARK-MANAGER |
| SCOTT-ANALYST |
| KING-PRESIDENT |
| TURNER-SALESMAN |
| ADAMS-CLERK |
| JAMES-CLERK |
| FORD-ANALYST |
| MILLER-CLERK |
+------------------+--+
14 rows selected (0.126 seconds)
CONCAT_WS(separator,A,B…):以第一个参数为分隔符,将后面的参数连接
0: jdbc:hive2://hadoop01:10000> select concat_WS('_',ename,job) from emp;
+------------------+--+
| _c0 |
+------------------+--+
| SMITH_CLERK |
| ALLEN_SALESMAN |
| WARD_SALESMAN |
| JONES_MANAGER |
| MARTIN_SALESMAN |
| BLAKE_MANAGER |
| CLARK_MANAGER |
| SCOTT_ANALYST |
| KING_PRESIDENT |
| TURNER_SALESMAN |
| ADAMS_CLERK |
| JAMES_CLERK |
| FORD_ANALYST |
| MILLER_CLERK |
+------------------+--+
14 rows selected (0.117 seconds)
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。(聚合函数多行数据返回一行)
0: jdbc:hive2://hadoop01:10000> select collect_set(job) from emp;
+-------------------------------------------------------+--+
| _c0 |
+-------------------------------------------------------+--+
| ["CLERK","SALESMAN","MANAGER","ANALYST","PRESIDENT"] |
+-------------------------------------------------------+--+
1 row selected (31.733 seconds)
如果不去重,可以用COLLECT_LIST(col)
0: jdbc:hive2://hadoop01:10000> select collect_list(job) from emp;
+----------------------------------------------------------------------------------------------------------------------------------------------+--+
| _c0 |
+----------------------------------------------------------------------------------------------------------------------------------------------+--+
| ["CLERK","SALESMAN","SALESMAN","MANAGER","SALESMAN","MANAGER","MANAGER","ANALYST","PRESIDENT","SALESMAN","CLERK","CLERK","ANALYST","CLERK"] |
+----------------------------------------------------------------------------------------------------------------------------------------------+--+
1 row selected (35.298 seconds)
数据准备:
[yyx@hadoop01 datas]$ vim constellation.txt
孙悟空 白羊座 A
大海 射手座 A
宋宋 白羊座 B
猪八戒 白羊座 A
凤姐 射手座 A
需求:把星座和血型一样的人归类到一起
射手座,A 大海|凤姐
白羊座,A 孙悟空|猪八戒
白羊座,B 宋宋
创建表并导入数据
0: jdbc:hive2://hadoop01:10000> create table person_info(
0: jdbc:hive2://hadoop01:10000> name string,
0: jdbc:hive2://hadoop01:10000> constellation string,
0: jdbc:hive2://hadoop01:10000> blood_type string)
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by '\t';
No rows affected (5.717 seconds)
0: jdbc:hive2://hadoop01:10000> load data local inpath '/opt/module/hive/datas/constellation.txt' into table person_info;
首先,我们先将星座和血型相拼接
0: jdbc:hive2://hadoop01:10000> select concat(constellation,',',blood_type) con_blood,name from person_info;
+------------+-------+--+
| con_blood | name |
+------------+-------+--+
| 白羊座,A | 孙悟空 |
| 射手座,A | 大海 |
| 白羊座,B | 宋宋 |
| 白羊座,A | 猪八戒 |
| 射手座,A | 凤姐 |
+------------+-------+--+
5 rows selected (0.154 seconds)
之后我们需要将相同的血型星座的人再拼接
0: jdbc:hive2://hadoop01:10000> select
0: jdbc:hive2://hadoop01:10000> t1.base,
0: jdbc:hive2://hadoop01:10000> concat_ws('|', collect_set(t1.name)) name
0: jdbc:hive2://hadoop01:10000> from
0: jdbc:hive2://hadoop01:10000> (select
0: jdbc:hive2://hadoop01:10000> name,
0: jdbc:hive2://hadoop01:10000> concat(constellation, ",", blood_type) base
0: jdbc:hive2://hadoop01:10000> from
0: jdbc:hive2://hadoop01:10000> person_info) t1
0: jdbc:hive2://hadoop01:10000> group by
0: jdbc:hive2://hadoop01:10000> t1.base;
+----------+----------+--+
| t1.base | name |
+----------+----------+--+
| 射手座,A | 大海|凤姐 |
| 白羊座,A | 孙悟空|猪八戒 |
| 白羊座,B | 宋宋 |
+----------+----------+--+
列转行
函数:EXPLODE(clo):将hive中一系列复杂的array或者map拆分成多行(炸列函数)
数据准备:
[yyx@hadoop01 datas]$ vim movie.txt
《疑犯追踪》 悬疑,动作,科幻,剧情
《Lie to me》 悬疑,警匪,动作,心理,剧情
《战狼2》 战争,动作,灾难
0: jdbc:hive2://hadoop01:10000> create table movie_info(
0: jdbc:hive2://hadoop01:10000> movie string,
0: jdbc:hive2://hadoop01:10000> category string)
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by '\t';
No rows affected (1.728 seconds)
0: jdbc:hive2://hadoop01:10000> load data local inpath '/opt/module/hive/datas/movie.txt' into table movie_info;
No rows affected (1.81 seconds)
因为我们的category列的类型是字符串,所以可以用split函数修改为数组
0: jdbc:hive2://hadoop01:10000> select split(category,',') from movie_info;
+-----------------------------+--+
| _c0 |
+-----------------------------+--+
| ["悬疑","动作","科幻","剧情"] |
| ["悬疑","警匪","动作","心理","剧情"] |
| ["战争","动作","灾难"] |
+-----------------------------+--+
3 rows selected (0.215 seconds)
我们可以通过炸列函数搜索,可是因为电影名与炸列后的行数不匹配,我们要用到炸列函数的一个扩展(侧写表)
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解释:用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
0: jdbc:hive2://hadoop01:10000> select movie,movie_con
0: jdbc:hive2://hadoop01:10000> from movie_info
0: jdbc:hive2://hadoop01:10000> lateral view explode(split(category,',')) movie_ce as movie_con;
+--------------+------------+--+
| movie | movie_con |
+--------------+------------+--+
| 《疑犯追踪》 | 悬疑 |
| 《疑犯追踪》 | 动作 |
| 《疑犯追踪》 | 科幻 |
| 《疑犯追踪》 | 剧情 |
| 《Lie to me》 | 悬疑 |
| 《Lie to me》 | 警匪 |
| 《Lie to me》 | 动作 |
| 《Lie to me》 | 心理 |
| 《Lie to me》 | 剧情 |
| 《战狼2》 | 战争 |
| 《战狼2》 | 动作 |
| 《战狼2》 | 灾难 |
+--------------+------------+--+
12 rows selected (0.176 seconds)
窗口函数
OVER():指定分析函数工作的数据窗口大小,这个窗口大小可能随着行的变化而变化
数据准备:
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
导入到表
0: jdbc:hive2://hadoop01:10000> create table business(name string,orderdate string,cost int)
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by ',';
No rows affected (0.127 seconds)
0: jdbc:hive2://hadoop01:10000> load data local inpath '/opt/module/hive/datas/business.txt' into table business;
No rows affected (0.576 seconds)
(1)查询在2017年4月份购买过的顾客及总人数
0: jdbc:hive2://hadoop01:10000> select name ,count(*)
0: jdbc:hive2://hadoop01:10000> from business
0: jdbc:hive2://hadoop01:10000> where substring(orderdate,1,7)='2017-04'
0: jdbc:hive2://hadoop01:10000> group by name;
+-------+------+--+
| name | _c1 |
+-------+------+--+
| jack | 1 |
| mart | 4 |
+-------+------+--+
但是我们希望不是1、4而是2、2
这里就要用到over()
0: jdbc:hive2://hadoop01:10000> select name ,count(*) over()
0: jdbc:hive2://hadoop01:10000> from business
0: jdbc:hive2://hadoop01:10000> where substring(orderdate,0,7)='2017-04'
0: jdbc:hive2://hadoop01:10000> group by name;
+-------+-----------------+--+
| name | count_window_0 |
+-------+-----------------+--+
| mart | 2 |
| jack | 2 |
+-------+-----------------+--+
2 rows selected (58.113 seconds)
Over在group by之后生效
Over是开窗,count()是窗口里的数据集的内容,而窗口里没有写东西,所以将所有行都写入窗口,而count()查询的也就是mark 和jacks(group by之后)两条数据
验证
0: jdbc:hive2://hadoop01:10000> select name,count(*) over()
0: jdbc:hive2://hadoop01:10000> from business
0: jdbc:hive2://hadoop01:10000> group by name;
+-------+-----------------+--+
| name | count_window_0 |
+-------+-----------------+--+
| tony | 4 |
| neil | 4 |
| mart | 4 |
| jack | 4 |
+-------+-----------------+--+
over和group by的区别:
group by是将多条数据聚合成一条
over也是将多条数据聚合成一条,但是over给每一条数据都开了一个窗口
(2)查询顾客的购买明细及月购买总额(partition by表示按什么分区)
0: jdbc:hive2://hadoop01:10000> select name,orderdate,cost,sum(cost) over (partition by name,month(orderdate))
0: jdbc:hive2://hadoop01:10000> from business;
+-------+-------------+-------+---------------+--+
| name | orderdate | cost | sum_window_0 |
+-------+-------------+-------+---------------+--+
| jack | 2017-01-05 | 46 | 111 |
| jack | 2017-01-08 | 55 | 111 |
| jack | 2017-01-01 | 10 | 111 |
| jack | 2017-02-03 | 23 | 23 |
| jack | 2017-04-06 | 42 | 42 |
| mart | 2017-04-13 | 94 | 299 |
| mart | 2017-04-11 | 75 | 299 |
| mart | 2017-04-09 | 68 | 299 |
| mart | 2017-04-08 | 62 | 299 |
| neil | 2017-05-10 | 12 | 12 |
| neil | 2017-06-12 | 80 | 80 |
| tony | 2017-01-04 | 29 | 94 |
| tony | 2017-01-02 | 15 | 94 |
| tony | 2017-01-07 | 50 | 94 |
+-------+-------------+-------+---------------+--+
14 rows selected (22.641 seconds)
如果不看顾客,而直接查看月购买总额
0: jdbc:hive2://hadoop01:10000> select name,orderdate,cost,sum(cost) over (partition by month(orderdate))
0: jdbc:hive2://hadoop01:10000> from business;
+-------+-------------+-------+---------------+--+
| name | orderdate | cost | sum_window_0 |
+-------+-------------+-------+---------------+--+
| jack | 2017-01-01 | 10 | 205 |
| jack | 2017-01-08 | 55 | 205 |
| tony | 2017-01-07 | 50 | 205 |
| jack | 2017-01-05 | 46 | 205 |
| tony | 2017-01-04 | 29 | 205 |
| tony | 2017-01-02 | 15 | 205 |
| jack | 2017-02-03 | 23 | 23 |
| mart | 2017-04-13 | 94 | 341 |
| jack | 2017-04-06 | 42 | 341 |
| mart | 2017-04-11 | 75 | 341 |
| mart | 2017-04-09 | 68 | 341 |
| mart | 2017-04-08 | 62 | 341 |
| neil | 2017-05-10 | 12 | 12 |
| neil | 2017-06-12 | 80 | 80 |
+-------+-------------+-------+---------------+--+
14 rows selected (21.781 seconds)
(3)上述的场景, 将每个顾客的cost按照日期进行累加
0: jdbc:hive2://hadoop01:10000> select
0: jdbc:hive2://hadoop01:10000> name,
0: jdbc:hive2://hadoop01:10000> orderdate,
0: jdbc:hive2://hadoop01:10000> sum(cost) over(partition by name order by orderdate)
0: jdbc:hive2://hadoop01:10000> from business;
+-------+-------------+-------+---------------+--+
| name | orderdate | cost | sum_window_0 |
+-------+-------------+-------+---------------+--+
| jack | 2017-01-01 | 10 | 10 |
| jack | 2017-01-05 | 46 | 56 |
| jack | 2017-01-08 | 55 | 111 |
| jack | 2017-02-03 | 23 | 134 |
| jack | 2017-04-06 | 42 | 176 |
| mart | 2017-04-08 | 62 | 62 |
| mart | 2017-04-09 | 68 | 130 |
| mart | 2017-04-11 | 75 | 205 |
| mart | 2017-04-13 | 94 | 299 |
| neil | 2017-05-10 | 12 | 12 |
| neil | 2017-06-12 | 80 | 92 |
| tony | 2017-01-02 | 15 | 15 |
| tony | 2017-01-04 | 29 | 44 |
| tony | 2017-01-07 | 50 | 94 |
+-------+-------------+-------+---------------+--+
14 rows selected (22.711 seconds)
sum(按名字分组,并且组内数据按orderdate排序。)
When ORDER BY is specified with missing WINDOW clause, the WINDOW specification defaults to RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
当指定ORDER BY缺少WINDOW子句时,WINDOW规范默认为 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
即:
0: jdbc:hive2://hadoop01:10000> select name,orderdate,cost,sum(cost) over(partition by name order by orderdate RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
0: jdbc:hive2://hadoop01:10000> from business;
结果一样
+-------+-------------+-------+---------------+--+
| name | orderdate | cost | sum_window_0 |
+-------+-------------+-------+---------------+--+
| jack | 2017-01-01 | 10 | 10 |
| jack | 2017-01-05 | 46 | 56 |
| jack | 2017-01-08 | 55 | 111 |
| jack | 2017-02-03 | 23 | 134 |
| jack | 2017-04-06 | 42 | 176 |
| mart | 2017-04-08 | 62 | 62 |
| mart | 2017-04-09 | 68 | 130 |
| mart | 2017-04-11 | 75 | 205 |
| mart | 2017-04-13 | 94 | 299 |
| neil | 2017-05-10 | 12 | 12 |
| neil | 2017-06-12 | 80 | 92 |
| tony | 2017-01-02 | 15 | 15 |
| tony | 2017-01-04 | 29 | 44 |
| tony | 2017-01-07 | 50 | 94 |
+-------+-------------+-------+---------------+--+
14 rows selected (26.943 seconds)
WINDOW子句
CURRENT ROW:当前行
n PRECEDING:往前n行数据
n FOLLOWING:往后n行数据
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点
注意:order by当有一个相同的数据时,会将两条数据开同样的窗口
所以,如果有一个字段有两条相同的数据,最好按照两个字段排序(减少数据的相等)
(4)查询每个顾客上次的购买时间
要用到函数(默认值表示如果为空,可以填入)
LAG(col,n,default_val):往前第n行数据
LEAD(col,n, default_val):往后第n行数据
这两个函数后面必须跟上over开窗函数
0: jdbc:hive2://hadoop01:10000> select
0: jdbc:hive2://hadoop01:10000> name,
0: jdbc:hive2://hadoop01:10000> lag(orderdate,1) over(partition by name order by orderdate)
0: jdbc:hive2://hadoop01:10000> from business;
+-------+---------------+--+
| name | lag_window_0 |
+-------+---------------+--+
| jack | NULL |
| jack | 2017-01-01 |
| jack | 2017-01-05 |
| jack | 2017-01-08 |
| jack | 2017-02-03 |
| mart | NULL |
| mart | 2017-04-08 |
| mart | 2017-04-09 |
| mart | 2017-04-11 |
| neil | NULL |
| neil | 2017-05-10 |
| tony | NULL |
| tony | 2017-01-02 |
| tony | 2017-01-04 |
+-------+---------------+--+
(5)查询前20%时间的订单信息
所需函数:
NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。(后面必须跟over开窗函数)
分成五组(百分之二十只要一组)
0: jdbc:hive2://hadoop01:10000> select name,
0: jdbc:hive2://hadoop01:10000> orderdate,
0: jdbc:hive2://hadoop01:10000> cost,
0: jdbc:hive2://hadoop01:10000> ntile(5) over(order by orderdate)
0: jdbc:hive2://hadoop01:10000> from business;
+-------+-------------+-------+-----------------+--+
| name | orderdate | cost | ntile_window_0 |
+-------+-------------+-------+-----------------+--+
| jack | 2017-01-01 | 10 | 1 |
| tony | 2017-01-02 | 15 | 1 |
| tony | 2017-01-04 | 29 | 1 |
| jack | 2017-01-05 | 46 | 2 |
| tony | 2017-01-07 | 50 | 2 |
| jack | 2017-01-08 | 55 | 2 |
| jack | 2017-02-03 | 23 | 3 |
| jack | 2017-04-06 | 42 | 3 |
| mart | 2017-04-08 | 62 | 3 |
| mart | 2017-04-09 | 68 | 4 |
| mart | 2017-04-11 | 75 | 4 |
| mart | 2017-04-13 | 94 | 4 |
| neil | 2017-05-10 | 12 | 5 |
| neil | 2017-06-12 | 80 | 5 |
+-------+-------------+-------+-----------------+--+
14 rows selected (20.101 seconds)
通过嵌套来取出第一组
0: jdbc:hive2://hadoop01:10000> select * from
0: jdbc:hive2://hadoop01:10000> (select name,orderdate,cost,ntile(5) over(order by orderdate) id from business) t
0: jdbc:hive2://hadoop01:10000> where t.id=1;
+---------+--------------+---------+-------+--+
| t.name | t.orderdate | t.cost | t.id |
+---------+--------------+---------+-------+--+
| jack | 2017-01-01 | 10 | 1 |
| tony | 2017-01-02 | 15 | 1 |
| tony | 2017-01-04 | 29 | 1 |
+---------+--------------+---------+-------+--+
3 rows selected (25.038 seconds)
Rank函数
Rank():排序相同时会重复,总数不会变(1224)
DENSE_RANK():排序相同时会重复,总数减少(1223)
ROW_NUMBER():顺延(123)
数据准备:
[yyx@hadoop01 datas]$ vim score.txt
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78
创建表并导入
0: jdbc:hive2://hadoop01:10000> create table score(
0: jdbc:hive2://hadoop01:10000> name string,
0: jdbc:hive2://hadoop01:10000> subject string,
0: jdbc:hive2://hadoop01:10000> score int)
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by '\t';
No rows affected (1.199 seconds)
0: jdbc:hive2://hadoop01:10000> load data local inpath '/opt/module/hive/datas/score.txt' into table score;
求出排序(按照不同科目的名次)
select *,rank() over(partition by subject order by score desc) id from score;
+-------------+----------------+--------------+-----+--+
| score.name | score.subject | score.score | id |
+-------------+----------------+--------------+-----+--+
| 孙悟空 | 数学 | 95 | 1 |
| 宋宋 | 数学 | 86 | 2 |
| 婷婷 | 数学 | 85 | 3 |
| 大海 | 数学 | 56 | 4 |
| 宋宋 | 英语 | 84 | 1 |
| 大海 | 英语 | 84 | 1 |
| 婷婷 | 英语 | 78 | 3 |
| 孙悟空 | 英语 | 68 | 4 |
| 大海 | 语文 | 94 | 1 |
| 孙悟空 | 语文 | 87 | 2 |
| 婷婷 | 语文 | 65 | 3 |
| 宋宋 | 语文 | 64 | 4 |
+-------------+----------------+--------------+-----+--+
12 rows selected (20.427 seconds)
查询每科前三名
0: jdbc:hive2://hadoop01:10000> select * from(select *,rank() over(partition by subject order by score desc) id from score) t where id <=3;
+---------+------------+----------+-------+--+
| t.name | t.subject | t.score | t.id |
+---------+------------+----------+-------+--+
| 孙悟空 | 数学 | 95 | 1 |
| 宋宋 | 数学 | 86 | 2 |
| 婷婷 | 数学 | 85 | 3 |
| 宋宋 | 英语 | 84 | 1 |
| 大海 | 英语 | 84 | 1 |
| 婷婷 | 英语 | 78 | 3 |
| 大海 | 语文 | 94 | 1 |
| 孙悟空 | 语文 | 87 | 2 |
| 婷婷 | 语文 | 65 | 3 |
+---------+------------+----------+-------+--+
9 rows selected (22.617 seconds)
函数
系统内置函数
0: jdbc:hive2://hadoop01:10000> show functions;
展示函数用法
0: jdbc:hive2://hadoop01:10000> desc function trim;
+--------------------------------------------------------------------------+--+
| tab_name |
+--------------------------------------------------------------------------+--+
| trim(str) - Removes the leading and trailing space characters from str |
+--------------------------------------------------------------------------+--+
1 row selected (0.058 seconds)
详细展示
0: jdbc:hive2://hadoop01:10000> desc function extended trim;
+--------------------------------------------------------------------------+--+
| tab_name |
+--------------------------------------------------------------------------+--+
| trim(str) - Removes the leading and trailing space characters from str |
| Example: |
| > SELECT trim(' facebook ') FROM src LIMIT 1; |
| 'facebook' |
+--------------------------------------------------------------------------+--+
4 rows selected (0.027 seconds)
自定义函数
当hive系统内置的函数不够时,可以通过创建自定义函数来满足需求
创建一个maven工程
导入依赖
<dependencies>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>1.2.1version>
dependency>
dependencies>
写代码方法名一定要evaluate
import org.apache.hadoop.hive.ql.exec.UDF;
public class Lower extends UDF {
public String evaluate(String capital){
if (capital == null){
return null;
}
return capital.toLowerCase();
}
}
打包
再将压缩包上传到/opt/module/hive/lib
改一下名
[yyx@hadoop01 lib]$ mv HiveFunction-1.0-SNAPSHOT.jar h.jar
将jar包添加到hive的classpath
0: jdbc:hive2://hadoop01:10000> add jar /opt/module/hive/lib/h.jar;
INFO : Added [/opt/module/hive/lib/h.jar] to class path
INFO : Added resources: [/opt/module/hive/lib/h.jar]
No rows affected (0.154 seconds)
创建临时函数与开发好的class相关联
0: jdbc:hive2://hadoop01:10000> create temporary function mylower as "org.yyx.hive.Lower";
No rows affected (0.033 seconds)
查询:
0: jdbc:hive2://hadoop01:10000> select ename,mylower(ename) from emp;
+---------+---------+--+
| ename | _c1 |
+---------+---------+--+
| SMITH | smith |
| ALLEN | allen |
| WARD | ward |
| JONES | jones |
| MARTIN | martin |
| BLAKE | blake |
| CLARK | clark |
| SCOTT | scott |
| KING | king |
| TURNER | turner |
| ADAMS | adams |
| JAMES | james |
| FORD | ford |
| MILLER | miller |
+---------+---------+--+
14 rows selected (0.185 seconds)
压缩
首先,将支持编译的HDFS集群上传到linux解压
[yyx@hadoop01 software]$ tar -zxv hadoop-2.7.2-src.tar.gz
解压好后进入lib中native,并将其中的内容复制到本地的Hadoop集群lib下native
[yyx@hadoop01 native]$ cp * /opt/module/hadoop-2.7.2/lib/native/
之后进入我们本地的native,运行
[yyx@hadoop01 native]$ cd /opt/module/hadoop-2.7.2/lib/native/
[yyx@hadoop01 native]$ ll
总用量 5636
-rw-r--r--. 1 yyx yyx 1210260 3月 4 16:41 libhadoop.a
-rw-r--r--. 1 yyx yyx 1487268 3月 4 16:41 libhadooppipes.a
lrwxrwxrwx. 1 yyx yyx 18 5月 22 2017 libhadoop.so -> libhadoop.so.1.0.0
-rwxr-xr-x. 1 yyx yyx 716316 3月 4 16:41 libhadoop.so.1.0.0
-rw-r--r--. 1 yyx yyx 582048 3月 4 16:41 libhadooputils.a
-rw-r--r--. 1 yyx yyx 364860 3月 4 16:41 libhdfs.a
lrwxrwxrwx. 1 yyx yyx 16 5月 22 2017 libhdfs.so -> libhdfs.so.0.0.0
-rwxr-xr-x. 1 yyx yyx 229113 3月 4 16:41 libhdfs.so.0.0.0
-rw-r--r--. 1 yyx yyx 472950 3月 4 16:41 libsnappy.a
-rwxr-xr-x. 1 yyx yyx 955 3月 4 16:41 libsnappy.la
-rwxr-xr-x. 1 yyx yyx 228177 3月 4 16:41 libsnappy.so
-rwxr-xr-x. 1 yyx yyx 228177 3月 4 16:41 libsnappy.so.1
-rwxr-xr-x. 1 yyx yyx 228177 3月 4 16:41 libsnappy.so.1.3.0
成功
启动集群,并且启动Hive
开启Map输出阶段压缩
开启map输出阶段压缩可以减少job中map和ReduceTask间数据传输量,配置如下
1.开启hive中传输数据压缩功能
set hive.exec.compress.intermediate=true;
2.开启mapReduce中map输出压缩功能
set mapreduce.map.output.compress=true;
3.设置mapreduce中map数据的压缩方式
set mapreduce.map.output.compress.codec=
org.apache.hadoop.io.compress.SnappyCodec;
4.执行查询语句
(因为数据太少,使用压缩反而得不偿失)
select count(ename) name from emp;
+-------+--+
| name |
+-------+--+
| 14 |
+-------+--+
开启Reduce输出阶段压缩
当Hive将输出写到表中时,输出内容同样可以进行压缩。属性hive.exec.compress.output控制着这个功能。用户可能需要保持默认设置文件中的默认值false,这样默认的输出就是非压缩的纯文本文件了。用户可以通过设置为ture,开启压缩的功能1.开启hive最终输出数据压缩功能
1.开启hive最终输出数据压缩功能
set hive.exec.compress.output=true;
2.开启mapreduce最终输出数据压缩
0: jdbc:hive2://hadoop01:10000> set mapreduce.output.fileoutputformat.compress=true;
No rows affected (0.002 seconds)
3.设置mapreduce最终数据输出压缩方式
0: jdbc:hive2://hadoop01:10000> set mapreduce.output.fileoutputformat.compress.codec =
0: jdbc:hive2://hadoop01:10000> org.apache.hadoop.io.compress.SnappyCodec;
4.设置mapreduce最终数据输出压缩为块压缩
0: jdbc:hive2://hadoop01:10000> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
No rows affected (0.001 seconds)
5.测试输出结果是否为压缩文件
0: jdbc:hive2://hadoop01:10000> insert overwrite local directory
0: jdbc:hive2://hadoop01:10000> '/opt/module/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;
[yyx@hadoop01 datas]$ cd distribute-result/
[yyx@hadoop01 distribute-result]$ ll
总用量 16
-rw-r--r--. 1 yyx yyx 199 3月 4 17:45 000000_1.snappy
-rw-r--r--. 1 yyx yyx 4 3月 4 17:45 000001_0.snappy
-rw-r--r--. 1 yyx yyx 310 3月 4 17:45 000002_1.snappy
-rw-r--r--. 1 yyx yyx 4 3月 4 17:45 000003_2.snappy
[yyx@hadoop01 distribute-result]$ cat 000000_1.snappy
急02FORDANALYST75661981-12-33000.0\N20
7876ADAMSCLERK77881987-5-231100.0\N20 902,0·817800.0\N20JONESMANAGER7839^$1-4-22975$369SMITH
文件存储格式
Hive支持的存储数据的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET。
前两个为行存储,后两个为列存储
行存储:
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
列存储:
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TextFile:
默认格式,数据不做压缩,磁盘开销大,数据解析开销大,可以结合i,Hive不会对数据进行切分,从而无法对数据进行操作Gzip,Bzip2使用,但是使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行操作
Orc:

IndexData是一个轻量级的index,默认**每隔一万做一个索引 **(这里做的索引时记录某行的个字段在Row Data中offset)
Row Data:存储具体数据,先取部分行,然后对这些行案列进行存储。对每个列进行了编码,分成多个Stream来存储
StriprFotter:存储各个Stream的类型,长度信息等
每个文件有一个FileFooter,这里面存储的是每个Stripe的行数,每个Column的数据类型等;每个文件的尾部是一个PostScript,这里记录了整个文件的压缩类型以及FileFooter的长度信息。在读取文件时,会seek到文件尾部读PostScript,从里面解析到FileFooter长度,再读FileFooter,从里面解析各个Stript信息再读各个Stripe《从后往前读》
主流文件存储格式对比
从查迅速的和压缩比对比,数据:
一共十万条,大小18MB
将其上传至
/opt/module/datas
[yyx@hadoop01 datas]$ ll
总用量 18580
drwxrwxr-x. 3 yyx yyx 282 3月 4 17:45 distribute-result
-rw-r--r--. 1 yyx yyx 19014993 2月 3 15:52 log.data
-rw-rw-r--. 1 yyx yyx 36 2月 4 15:31 student.txt
-rw-rw-r--. 1 yyx yyx 144 2月 18 20:37 text.txt
创建表并导入数据(TEXTFILE存储格式)
0: jdbc:hive2://hadoop01:10000> create table log_text (
0: jdbc:hive2://hadoop01:10000> track_time string,
0: jdbc:hive2://hadoop01:10000> url string,
0: jdbc:hive2://hadoop01:10000> session_id string,
0: jdbc:hive2://hadoop01:10000> referer string,
0: jdbc:hive2://hadoop01:10000> ip string,
0: jdbc:hive2://hadoop01:10000> end_user_id string,
0: jdbc:hive2://hadoop01:10000> city_id string)
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by '\t'
0: jdbc:hive2://hadoop01:10000> stored as textfile;
0: jdbc:hive2://hadoop01:10000> load data local inpath '/opt/module/datas/log.data' into table log_text;

创建表,存储数据格式为ORC,并且插入数据
0: jdbc:hive2://hadoop01:10000> create table log_orc(
0: jdbc:hive2://hadoop01:10000> track_time string,
0: jdbc:hive2://hadoop01:10000> url string,
0: jdbc:hive2://hadoop01:10000> session_id string,
0: jdbc:hive2://hadoop01:10000> referer string,
0: jdbc:hive2://hadoop01:10000> ip string,
0: jdbc:hive2://hadoop01:10000> end_user_id string,
0: jdbc:hive2://hadoop01:10000> city_id string
0: jdbc:hive2://hadoop01:10000> )
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by '\t'
0: jdbc:hive2://hadoop01:10000> stored as orc ;
No rows affected (0.111 seconds)
0: jdbc:hive2://hadoop01:10000> insert into table log_orc select * from log_text;
创建表,并且存储格式为parquet
create table log_parquet(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as parquet;
insert into table log_parquet select * from log_text ;
三种压缩方式查询都在1秒之内,总体相差不大
将native文件分发给三台虚拟机(使三台虚拟机都可以snappy压缩)
[yyx@hadoop01 lib]$ xsync native/
重新启动Hadoop集群以及hive
分别创建非压缩的ORC存储表以及一个用snappy压缩的ORC存储表,检验速率以及压缩比
非压缩的ORC存储
create table log_orc_none(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc tblproperties ("orc.compress"="NONE");
插入数据insert into table log_orc_none select * from log_text ;

创建snappy压缩的ORC表并插入数据
0: jdbc:hive2://hadoop01:10000> create table log_orc_snappy(
0: jdbc:hive2://hadoop01:10000> track_time string,
0: jdbc:hive2://hadoop01:10000> url string,
0: jdbc:hive2://hadoop01:10000> session_id string,
0: jdbc:hive2://hadoop01:10000> referer string,
0: jdbc:hive2://hadoop01:10000> ip string,
0: jdbc:hive2://hadoop01:10000> end_user_id string,
0: jdbc:hive2://hadoop01:10000> city_id string
0: jdbc:hive2://hadoop01:10000> )
0: jdbc:hive2://hadoop01:10000> row format delimited fields terminated by '\t'
0: jdbc:hive2://hadoop01:10000> stored as orc tblproperties ("orc.compress"="SNAPPY");
No rows affected (0.139 seconds)
0: jdbc:hive2://hadoop01:10000> insert into table log_orc_snappy select * from log_text ;

而orc默认的压缩比snappy还小

ORC存储文件默认使用ZLIB压缩(deflate算法),比snappy压缩更小
总结
在实际的开发中,hive表的存储数据格式一般选择ORC或者parquet,压缩方式一般用snappy,lzo