前言
最近在实际业务中用到了大量和排序相关的问题,而排序在不依赖于外部库的前提下,原生的函数sort就肯定是你的首选。今天这篇文章我们依然秉承着学以致用的原则,先说说理论,然后再结合业务用到的一些排序场景跟大家探讨探讨这个函数的一些用法
1、Array.sort
根据MDN的解释,
`sort`方法使用了`in-place`算法对数组中的元素进行排序,这种排序是不需要具备`stable`的。而默认的排序顺序是依据元素的Unicode编码的大小。
这么一段介绍涉及到两个软件科学中的概念:in-place和stable。这里简单说一下二者的概念。
in-place算法不是一种排序算法,而是一种实现。它的大致意思就是说不使用辅助的数据结构,就可以将输入数据进行原地排序后输出。这种实现一般都会将输入进行覆盖从而得到输出。诸如冒泡排序、选择排序等算法都是输入in-place算法。在函数式编程中,属于副作用的一种算法。更详细的介绍请参考: in-place
stable的概念是属于排序算法的一种分类,也就是说排序算法会划分为两类(当然从不同角度上来说可以分成很多类),如果在待排序的数组中某几个相同次序的值可以以之前的顺序排序到结果数组中,那么这种排序算法便称这种算法具有稳定性。反之为非稳定。
举个例子:排序数组是:[{ id: 1, text: 'first' }, { id: 5, text: 'second' }, { id: 10, text: 'third' }, { id: 5, text: 'fourth'}],按照id的升序排序,得到的结果如果是:[{ id: 1, text: 'first' }, { id: 5, text: 'second' }, { id: 5, text: 'fourth'}, { id: 10, text: 'third' }],可以看到{ id: 5, text: 'second' }保持在之前的输入位置,这种排序便是具备稳定性。
关于排序算法的这两种特征可以参考下图:
[图片上传失败...(image-dfe083-1540622656257)]
另外提到的一个排序默认的规则是按照Unicode的大小,比如你排序这个数组:[1, 111, 8, 49],如果不使用指定的比较函数的时候,结果如下:[1, 111, 49, 8]。看得出来是将排序的元素转为字符串,然后逐个比较字符的Unicode大小。
如果我们有传入比较函数的话,比较函数接受两个参数(a, b),并返回一个值来决定排序的顺序。规则如下:
- 如果返回值小于0,那么a的新的索引值会在b小,也就是a会排在b之前
- 如果返回值大于0,那么反之,a会排在b之后
- 如果返回值等于0,那么a、b的位置都不用动
2、Array.sort的实现细节
接下来我们来做个试验:
const a = [1, 4, 77, 233, 2] ;
a.sort((a, b) => {
console.log(a, b)
return a - b
})
我们关注打印的结果是:
1 4
4 77
77 233
233 2
77 2
4 2
1 2
现在我们加大复杂程度:
const a = [9, 2, 4, 5, 6, 7, 8, 10, 11, 12, 15]
a.sort((a, b) => {
console.log(a, b)
return a - b
})
我们再看一下这个的打印结果:
9 15
9 7
4 9
5 9
6 9
2 9
8 9
10 9
12 9
11 9
10 11
11 12
12 15
7 4
7 5
4 5
7 6
5 6
7 2
6 2
5 2
4 2
7 8
每次值的比较大家有没有发现端倪?
数值的比较顺序貌似不一样,也就是说排序算法用的貌似不是同一个
为啥会这样?这个就需要我们从源码去找答案:array.js
代码中的实现方式是这样的:当数组的长度小于10的时候,使用了插入排序,如果长度大于10,那么就使用快速排序。
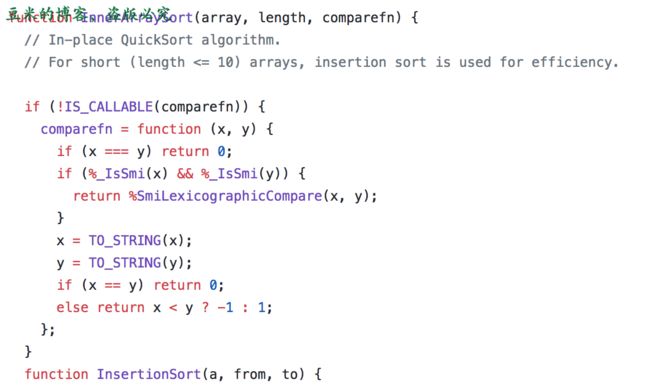
接下去开始我们的排序算法之旅~~~
2.1、插入排序
插入即表示将一个新的数据插入到一个有序数组中,并继续保持有序。例如有一个长度为N的无序数组,进行N-1次的插入即能完成排序;第一次,数组第1个数认为是有序的数组,将数组第二个元素插入仅有1个有序的数组中;第二次,数组前两个元素组成有序的数组,将数组第三个元素插入由两个元素构成的有序数组中......第N-1次,数组前N-1个元素组成有序的数组,将数组的第N个元素插入由N-1个元素构成的有序数组中,则完成了整个插入排序。
JS的简易实现版本如下:
function insertionSort(arr){
var i, len = arr.length, el, j;
for(i = 1; i 0 && arr[j - 1] > el){
// 如果插入的值比要比较的值小,那么就将这个值往后挪
arr[j] = arr[j-1];
j--;
}
// 等挪完就有一个空位置给插入的值,就完成了一次排序
arr[j] = el;
}
return arr;
}
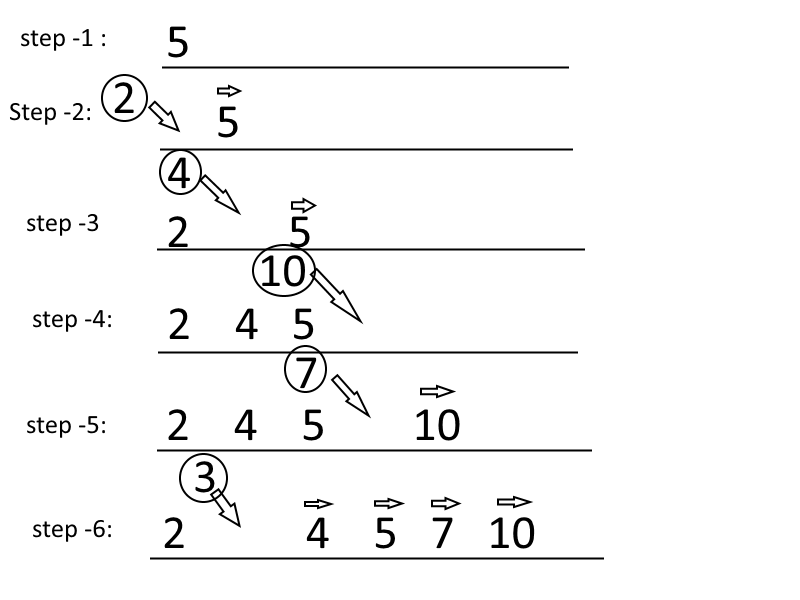
以数组[1, 4, 77, 233, 2]来举例,按照上面的算法,所有比较的值就如之前打印的那样。顺序如下:
- 初始化的有序数组是1
- 从第二个数字4开始,暂存数字4,将数字4与数字1比较,发现while不成立,数字4占坑成功,形成有序数组:[1, 4]
- 从第三个数字77开始,因为是升序排列,所以只需要比较上一个步骤得到的有序数组的最后一个元素,同样的发现while语句不成立,数字77占坑成功,形成有序数组[1, 4, 77]
- 从第四个数字233开始,和77一样,占坑成功,形成有序数组:[1, 4, 77, 233]
- 从第五个数组2开始,j = 4; el = 2; while循环成立,进入循环,2与有序数组[1, 4, 77, 233]会一个个比较,一个个值往后挪,直到遇到数字1,循环终端,此时出来的有序数组是: [1, , 4, 77, 233],留坑成功,此时的j = 1,于是循环结束后,数字2占坑成功,形成最后的有序数组是: [1, 2, 4, 77, 233]
附上一张别人制作的示意图帮助理解:
2.2、快速排序:
快速排序使用分治法(Divide and conquer)策略,本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。其实现原理是:
从数列中挑出一个元素,称为 “基准”(pivot);
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
JS的实现版本是:
function quickSort(arr, left, right){
var len = arr.length,
pivot,
partitionIndex;
if(left < right){
pivot = right;
partitionIndex = partition(arr, pivot, left, right);
console.log(partitionIndex)
//sort left and right
quickSort(arr, left, partitionIndex - 1);
quickSort(arr, partitionIndex + 1, right);
}
return arr;
}
function partition(arr, pivot, left, right){
// 拿到基准值
var pivotValue = arr[pivot],
partitionIndex = left;
// 从最左边到最右边的值与基准值比较
for(var i = left; i < right; i++) {
if(arr[i] < pivotValue){
swap(arr, i, partitionIndex);
partitionIndex++;
}
}
swap(arr, right, partitionIndex);
return partitionIndex;
}
function swap(arr, i, j){
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
以[9, 2, 4, 5, 6, 7, 8, 10, 11, 12, 15]为例,使用quickSort([9, 2, 4, 5, 6, 7, 8, 10, 11, 12, 15], 0, 10),其排序顺序如下:
- 我们以数字15为基准值
- 第一次进入quickSort之后,进行分区,大于15的放在15右边,小于15的放在左边,结果发现全部的数字都小于15,于是基准值新的索引还是10
- 接下去递归调用,以基准值新的索引为分界线,重复排序左边那些比其小的值和右边那些比其大的值,这里右边的数组为空,所以只需要排序左边的。
- 左边接下去以12为基准值,发现和15一样,一样的操作,如此递归,直到以8为基准值的时候
- [9, 2, 4, 5, 6, 7, 8]以8为基准值,left = 0/right = 6,然后进行分区,大于8的放到右边,于是按照partition函数的逻辑,for循环之后的数组应该是:[2, 4, 5, 6, 7, 9, 8], partitionIndex = 5
- 然后基准值和partitionIndex的值再做下交换就是: [2, 4, 5, 6, 7, 8, 9],并将partitionIndex返回,再以该值为分界线做下一次的分治。
- 如此往复循环得到最终的有序数组。
找到一张partition函数执行的示意图:

3、Array.sort的进阶使用
3.1、多重排序
在实际应用中,难免会对同一个数组的多个字段进行排序,我们举个例子来说明使用。
有如下例子,有如下的数组:
const a = [{
state: 10,
type: 1,
date: new Date('2018-01-01')
},{
state: 5,
type: 2,
date: new Date('2018-01-02')
},{
state: 5,
type: 1,
date: new Date('2018-01-03')
},{
state:25,
type:1,
date: new Date('2018-01-04')
},{
state:30,
type:1,
date: new Date('2018-01-05')
},{
state:5,
type:1,
date: new Date('2018-01-01')
},{
state: 25,
type: 2,
date: new Date('2018-01-02')
}]
上面的数组排序规则是先按照state的升序,之后按照type的升序排列,最后再按照date的降序排列
这种多重排序的设计多个判断,所以我们在比较函数中需要根据规则返回对应的值:
a.sort((a, b) => {
if (a.state !== b.state) {
return a.state - b.state
}
if (a.type !== b.type) {
return a.type - b.type
}
return b.date.getTime() - a.date.getTime()
})
现在我们把刚才state的排序规则改一下,按照这个规则来排序:25 > 20 > 15 > 10 > 5 > 30 ? 现在代码应该怎么实现呢?只是单纯使用sort函数可以实现这个要求吗?这个问题留给大家去思考吧?应该会有很多实现方式的吧?
顺便提一下有一个库叫做thenBy,可以简写上面的多重排序为如下形式:
const firstBy = require('thenby')
a.sort(firstBy('state').thenBy('type').thenBy((a, b) => b.date.getTime() - a.date.getTime()))
3.2、随机排序某个数组
我们可以使用sort来随机打乱某个数组,实现的方式如下:
a.sort(function(){ //Array elements now Shuffling
return 0.5 - Math.random()
})
3.3、Schwartzian transform(施瓦茨变换)
不知道大家有没有听过这个概念,反正我是最近深入学习sort排序的时候才翻到。
施瓦茨变换(Schwartzian Transform)[https://en.wikipedia.org/wiki/Schwartzian_transform]由Perl 黑客Randal L. Schwartz 所创造,提供了一种高效排序的思路。该变换的本质就是将排序函数里面那些重复的操作统一在外部做掉,因为我们没办法减少sort函数里面compare方法调用的次数,但是我们可以减少每次调用的计算量。尤其对于那些计算复杂的排序,这种优化的效率更为客观。
举个例子:
我们想要将这个数组按照字符串的长度进行升序排序:const fruits = ['apple', 'orange', 'pear', 'grape', 'banana'],
按照正常的排序操作:
fruits.sort((a, b) => a.lenght - b.length)
该比较函数将会执行总共6次,那么将会有12次计算字符串的长度,然后每个字符串的长度将会至少重复计算两次。如果这种计算特别耗时的话,这将是一个低效的排序算法。那么如何优化呢?
这个时候我们根据施瓦茨变换的思路,将字符串的长度计算挪到外面,修改后的代码如下:
var lengths = fruits.map(function (e, i) {
return {index: i, value: e.length };
});
lengths.sort(function (a, b) {
return +(a.value > b.value) || +(a.value === b.value) - 1;
});
var sortedFruits = lengths.map(function (e) {
return fruits[e.index];
});
这样我们就减少了诸多次重复的字符串长度计算的代码,效率大有提升。
该变换旨在给大家提供一个思路,望大家在写代码的时候可以多思考思考~
参考
- JS-Sorting-Algorithm
- JS: Interview Questions
- JavaScript Array sort: Sorting Array Elements