Hive基础知识 01
文章目录
- Hive基础知识
-
- 一、Hive与HDFS的数据映射
- 二、Hive转换与MapReduce过程
- 三、元数据:metastore的功能和存储方式
- 四、元数据:metastore共享问题
- 五、元数据:metastore服务
- 六、Hive客户端与服务端
- 七、启动脚本与SQL脚本
- 八、常用命令与日志配置
- 九、HQL语法:DDL
- 十、HQL语法:DML
- 十一、HQL语法:DQL
- 十二、表的分类
Hive基础知识
一、Hive与HDFS的数据映射
1.Hive对象与HDFS关系
数据库:每个数据库在HDFS中对应一个目录
目录的名字:库名.db
表:每张表在数据库中对应的目录下建立一个与表同名的目录
表的数据:映射的是HDFS上的文件
2.元数据映射
所有Hive中数据库、表与HDFS的映射关系存储在元数据中,Hive服务端会读取元数据找到这张表对应的HDFS数据
3.元数据映射过程
1.先检索数据库的信息
2.再检索表的信息
3.通过表的SD_ID来获取这张表映射的HDFS的地址
4.将整个表的目录中的 所有数据进行读取并返回
二、Hive转换与MapReduce过程
1.基本映射关系
| MapReduce | SQL |
|---|---|
| Input | from |
| Map | select,from |
| Shuffle | group by,order by |
| Reduce | having,limit |
| Output | 将SQL结果保存 |
2.执行解析
select region,count(*) as numb from tb_house where region != '浦东' group by region order by numb;
3.查看执行计划
explain select region,count(*) as numb from tb_house where region != '浦东' group by region order by numb;
三、元数据:metastore的功能和存储方式
1.metastore功能
Hive中的元数据记录了Hive中所有对象信息,包括数据库信息,表的信息,字段的信息,重点记录了Hive表和HDFS文件的映射关系
每次创建表关联文件,Hive都会自动创建表的元数据
每次查询表的数据,Hive都会从元数据中获取表的对应的HDFS信息
2.metastore的存储方式
方式:
嵌入式数据库:Local/Embedded Metastore Database(Derby)
存储在derby
本地数据库
存储在MySQL中,可以直接访问
远程Metastore服务
存储在MySQL中,但是通过一个进程来访问
位置:
默认位置:Hive自带的Derby数据库
缺点:不能共享,不能启动多个实例,一般不用
自定义位置:自定义将元数据存储到其他数据库中
类型:MySQl、Oracle、PostGrepSQL,工作中一般存储到MySQL中
3.metastore的功能?
存储Hive中所有对象的信息:数据库、表、列
存储Hive中表与HDFS的映射关系
四、元数据:metastore共享问题
1.工作中的应用场景
工作中不使用Hive来实现数据仓库中的分布式计算,
使用替代品:SparkSQL、Impala、Presto,因为他们计算更快,性能更好,语法都兼容Hive的语法
2.如果用SparkSQL来处理Hive数据仓库中的表,SparkSQL怎么知道Hive中有哪些表?
让SparkSQL读取Hive元数据
3.如何SparkSQL获取了Hive的元数据,SparkSQL怎么知道这个元数据的含义是什么?
解析元数据的含义
4.如果多个框架都需要访问Hive的元数据,每个框架都封装解析代码,就非常冗余,如何解决这个问题?
通过metastore服务,实现元数据共享
五、元数据:metastore服务
1.metastore功能
实现元数据共享服务,专门负责管理Hive的元数据,接收所有需要访问元数据的请求
2.metastore的配置
#编辑hive-site.xml文件,添加以下内容
hive.metastore.uris
thrift://node3:9083
3.metastore的启动
#1.先启动metastore服务
hive --service metastore
#2.再启动Hive的服务端和客户端
hive
#3.查看metastore端口开放情况
netstat -atunlp | grep 9083
六、Hive客户端与服务端
1.Hive Shell
功能:
Hive特殊的客户端,启动时会自动包含启动服务端
命令:
hive
特点:
服务端客户端一体,交互性不太友好
2.Beeline与hiveserver2
功能:
Beeline:纯客户端
hiveserver2:Hive中独立的服务进程
命令:
beeline启动Hive服务端:
#1.第一种方式
beeline -u jdbc地址 -n 用户名 -p 密码
#2.第二种方式
beeline
!connect jdbc地址
用户名
密码
hiveserver2启动Hive服务端:
#1.第一种方式
hive --service hiveserver2
#2.第二种方式
hiveserver2
2.1启动测试1
#1.启动metastore(9083端口)
hive --service metastore
#2.启动Hive服务端(10000端口)
hiveserver2
#3.启动客户端,当前启动会出现错误,需要做配置
beeline
!connect jdbc:hive2://node3:10000
root
123456
2.2配置
关闭hdfs和yarn
#1.关闭hdfs
stop-dfs.sh
#2.关闭yarn
stop-yarn.sh
编辑core.xml
#1.切换到指定目录
cd /export/server/hadoop-2.7.5/etc/hadoop/
#2.编辑core-site.xml文件
vim core-site.xml
#3.添加以下内容
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
分发core-site.xml文件
#1.向node2分发
scp core-site.xml node2:$PWD
1.向node3分发
scp core-site.xml node3:$PWD
启动hdfs和yarn
#1.启动hdfs
start-dfs.sh
2.启动yarn
start-dfs.sh
2.3复制standalone包
#1.切换到指定目录
cd /export/server/hive-2.1.0-bin
#2.复制文件
cp jdbc/hive-jdbc-2.1.0-standalone.jar lib/
2.4启动测试2
#1.启动metastore,加&使其在后台运行
hive --service metastore &
#2.启动Hive服务端
hiveserver2
#3.启动客户端,方式1直接进入
beeline
!connect jdbc:hive2://node3:10000
root
123456
#4.启动客户端,方式2直接连接
beeline -u jdbc:hive2://node3:10000 -n root -p 123456
#5.退出
!q
特点:
交互性好,一般用于交互式查询
3.JDBC
语法:
基本与MySQL的JDBC一致
#step1:指定驱动类
#step2:构建连接对象
#step3:构建SQL对象
#step4:执行SQL获取结果
测试:
package com.miao.hive.client.jdbc;
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveJdbcClient {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
try {
//声明驱动
Class.forName(driverName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit(1);
}
//构建连接
Connection con = DriverManager.getConnection("jdbc:hive2://node3:10000/default", "root", "123456");
//构建SQL对象
Statement stmt = con.createStatement();
String tableName = "tb_house";
String sql = "select region,t_price,s_price from " + tableName +" limit 100";
System.out.println("Running: " + sql);
//执行SQL语句
ResultSet res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getInt(2)+ "\t" + res.getInt(3));
}
}
}
应用:一般用于封装交互式的程序:Navicat、DataGrip
4.关闭metastore和hiveserver2
#1.关闭metastore
kill -9 5014
#2.关闭hiveserver2
kill -9 5097
七、启动脚本与SQL脚本
1.创建日志目录
mkdir /export/server/hive-2.1.0-bin/logs
日志的四个级别:
DEBUG:详细的日志级别
INFO:显示的信息会包含主要的日志信息
WARN:只记录警告级别的日志
ERROR:只记录错误级别的日志
2.编辑Metastore启动脚本
#1编辑metastore.sh文件
vim /export/server/hive-2.1.0-bin/bin/start-metastore.sh
#2.添加以下内容
#!/bin/bash
#HIVE_HOME
HIVE_HOME=/export/server/hive-2.1.0-bin
#run metastore
$HIVE_HOME/bin/hive --service metastore >> $HIVE_HOME/logs/metastore.log 2>&1 &
3.编辑HiveServer2启动脚本
#1.编辑hiveserver2.sh文件
vim /export/server/hive-2.1.0-bin/bin/start-hiveserver2.sh
#2.添加以下内容
#!/bin/bash
#HIVE_HOME
HIVE_HOME=/export/server/hive-2.1.0-bin
#run hiveserver2
$HIVE_HOME/bin/hiveserver2 >> $HIVE_HOME/logs/hiveserver2.log 2>&1 &
4.编辑Beeline启动脚本
#1.编辑beeline.sh文件
vim /export/server/hive-2.1.0-bin/bin/start-beeline.sh
#2.添加以下内容
#!/bin/bash
#HIVE_HOME
HIVE_HOME=/export/server/hive-2.1.0-bin
#run beeline
$HIVE_HOME/bin/beeline -u jdbc:hive2://node3:10000 -n root -p 123456
5.修改权限
chmod u+x /export/server/hive-2.1.0-bin/bin/start-*
6.HiveSQL脚本的封装
需求:每天00:01分自动对昨天的数据做分析
select count(*) from table where daystr = '2021-05-01';
问题1:每天的0点01分自动执行,怎么实现?
Linux Crontab:定时任务
* * * * * Linux command
实现
01 00 * * * hive -e 'select count(*) from table where daystr = '2021-05-01';'
问题2:怎么让Hive的SQL语句在Linux的命令行执行?
解决:利用Hive Shell的客户端来实现,查看客户端的用法
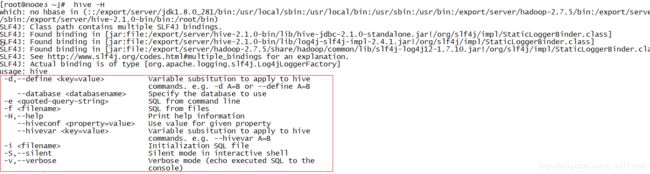
-e:执行命令行中的SQL语句
hive -e 'select count(*) from table where daystr = '2021-05-01;'
直接执行命令行中提供的SQL语句
应用:要执行比较少的单条SQL语句
-f:执行一个SQL文件
#1.创建一个sql文件
vim /export/data/hive.sql
#2.编辑sql语句
show databases;
use default;
select region,s_price,area from tb_house limit 10;
执行SQL文件
hive -f /export/data/hive.sql
定时任务:
01 00 * * * bash /export/data/exec.sh
exec.sh
#!/bin/bash
#1.定义变量
HIVE_HOME=/export/server/hive-2.1.0-bin
#2.运行SQL语句
#$HIVE_HOME/bin/hive -e 'show databases;'
$HIVE_HOME/bin/hive -f /export/data/hive.sql
7.SQL脚本中传递变量
问题:如果运行的SQL文件,SQL文件中的SQL语句中的参数是动态变化的,如何解决?
解决:通过–hiveconf,将Shell脚本中变量转换为一个Hive中的变量
–hiveconf:用于定义Hive中属性的值或者定义Hive中的变量
shell脚本
#!/bin/bash
#1.获取昨天的日期
yesterday=`date -d '-1 day' +%Y%m%d`
#2.定义变量
HIVE_HOME=/export/server/hive-2.1.0-bin
#3.运行SQL语句
#$HIVE_HOME/bin/hive -e 'select count(*) from table where daystr = '${yesterday}';'
$HIVE_HOME/bin/hive --hiveconf yester=${yesterday} -f /export/data/hive.sql
hive.sql文件
select count(*) from table where daystr = '${hiveconf:yester}';
八、常用命令与日志配置
1.常用命令
dfs:用于直接在Hive执行HDFS的操作
set:查看或者临时修改【只在当前的会话窗口有效】
add:添加jar包或者文件到Hive的环境变量中
add jar xxx.jar;
add file xxx
list:列举添加的文件或者jar包
list files
list jars
delete:删除添加的文件或者jar包
2.日志存储配置
重命名日志配置文件
#1.切换到指定目录
cd /export/server/hive-2.1.0-bin/conf/
#2.重命名log4j2.properties文件
mv hive-log4j2.properties.template hive-log4j2.properties
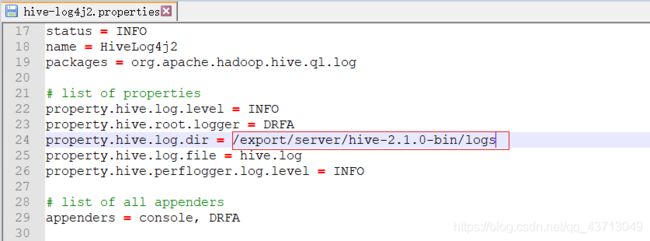
修改配置
#1.编辑log4j2.properties文件
vim hive-log4j2.properties
#2.修改第24行
property.hive.log.dir = /export/server/hive-2.1.0-bin/logs
重启Hive的服务端
九、HQL语法:DDL
1.数据库库的管理
查看所有数据库
show databases;
创建数据库
create database [if not exists ] dbname [comment] [location]
使用数据库
use dbname;
删除数据库
drop database [if exists] dbname [cascade];
2.数据库表的管理
查看所有表
show tables;
show tables in dbname;
创建表
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
(
col1Name col1Type [COMMENT col_comment],
co21Name col2Type [COMMENT col_comment],
co31Name col3Type [COMMENT col_comment],
co41Name col4Type [COMMENT col_comment],
co51Name col5Type [COMMENT col_comment],
……
coN1Name colNType [COMMENT col_comment]
)
[PARTITIONED BY (col_name data_type ...)] --分区表结构
[CLUSTERED BY (col_name...) [SORTED BY (col_name ...)] INTO N BUCKETS] --分桶表结构
[ROW FORMAT row_format] -- 指定数据文件的分隔符
row format delimited fields terminated by '列的分隔符' -- 列的分隔符,默认为\001
lines terminated by '行的分隔符' --行的分隔符,默认\n
[STORED AS file_format] -- 指定文件的存储格式
[LOCATION hdfs_path] -- 用于指定表的目录所在位置,默认表的目录在数据库的目录下面
创建表的三种方式
方式一:普通方式
功能:一般用于创建一张表加载数据文件,将文件构建表结构
例如:创建员工表
#1.创建员工表
create database db_emp;
use db_emp;
create table tb_emp(
empno string,
ename string,
job string,
managerid string,
hiredate string,
salary double,
jiangjin double,
deptno string
) row format delimited fields terminated by '\t';
#2.加载数据
load data local inpath '/export/data/emp.txt' into table tb_emp;
方式二:将Select语句的结果保存到一张新表中
create table tb_emp_as as select empno,ename,salary,deptno from tb_emp;
方式三:复制表的结构到一张新表中
create table tb_emp_like like tb_emp;
只复制表结构,不复制数据内容
删除表
drop table [if exists] tbname;
查看表
#查看表的结构
desc tbname;
#查看表的元数据
desc formatted tbname;
清空表
truncate tbname;
十、HQL语法:DML
1.加载文件load
用于将数据文件关联到Hive的表中
load data [local] inpath 'filePath' [overwrite] into tbname;
2.插入数据insert
将SQL语句的结果保存到一张已存在的表中或者目录中
#1.格式1
INSERT OVERWRITE|INTO TABLE tablename1
select_statement1 FROM from_statement;
#2.格式2
FROM from_statement
INSERT OVERWRITE|INTO TABLE tablename1 select_statement1 ;
十一、HQL语法:DQL
1.基本查询
例:查询每个员工的编号、姓名、薪水及部门编号
select empno,ename,salary,deptno from tb_emp;
2.过滤查询
例:查询薪资大于2000的所有员工的姓名及薪水和部门编号
select ename,salary,deptno from tb_emp where salary > 2000;
3.分组查询
例:查询每个部门的人数
select deptno,count(*) as numb from tb_emp group by deptno;
4.排序查询
例:查询所有部门人数超过3人的部门编号并按照人数降序排序
select deptno,count(*) as numb from tb_emp group by deptno having numb > 3 order by numb desc;
5.关联查询
例:查询所有员工的姓名、部门编号和部门名称
select
a.ename,
a.deptno,
b.dname
from tb_emp a join tb_dept b on a.deptno = b.deptno;
6.子查询
例;查询除SALES部门以外的所有部门的员工信息
#格式1
select * from tb_emp where deptno not in (select deptno from tb_dept where dname = 'SALES');
#格式2
with t1 as (
select deptno from tb_dept where dname = 'SALES'
)
select * from t1 ;
十二、表的分类
1.管理表
语法
create table ……
特点:Hive中默认的表类型,不手动删除,管理表一直存在,删除表时,元数据与HDFS映射的表的目录一起被删除
2.临时表
语法
create temporary table ……
特点:表是临时存在,如果客户端一旦断开,表会自动被删除,类似于ZK中的临时节点,是一种特殊的管理表,这种管理表的生命周期伴随客户端的,用于存放临时数据
3.外部表
语法
create external table ……
特点:在删除表时,只删除元数据,数据是不会被删除,工作中大部分的表都是外部表类型