Flink实战案例:状态管理(十一)自定义操作符状态(五)广播状态(Broadcast state)(三)
声明:本系列博客是根据SGG的视频整理而成,非常适合大家入门学习。
《2021年最新版大数据面试题全面开启更新》
Broadcast State使用场景
无论是分布式批处理还是流处理,将部分数据同步到所有实例上是一个十分常见的需求。例如,我们需要依赖一个不断变化的控制规则来处理主数据流的数据,主数据流数据量比较大,只能分散到多个算子实例上,控制规则数据相对比较小,可以分发到所有的算子实例上。Broadcast State与直接在时间窗口进行两个数据流的Join的不同点在于,控制规则数据量较小,可以直接放到每个算子实例里,这样可以大大提高主数据流的处理速度。
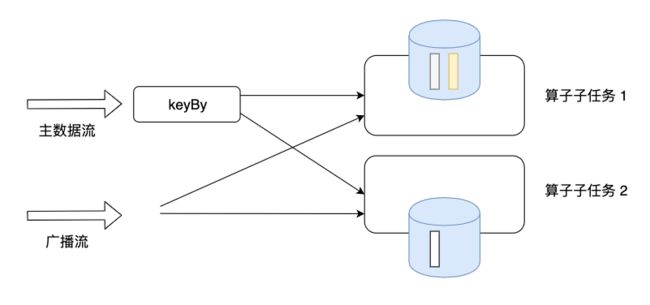
我们继续使用电商平台用户行为分析为例,不同类型的用户往往有特定的行为模式,有些用户购买欲望强烈,有些用户反复犹豫才下单,有些用户频繁爬取数据,有盗刷数据的嫌疑,电商平台运营人员为了提升商品的购买转化率,保证平台的使用体验,经常会进行一些用户行为模式分析。基于这个场景,我们可以构建一个Flink作业,实时监控识别不同模式的用户。为了避免每次更新规则模式后重启部署,我们可以将规则模式作为一个数据流与用户行为数据流connect在一起,并将规则模式以Broadcast State的形式广播到每个算子实例上。
电商用户行为识别案例
下面开始具体构建一个实例程序。第一步,我们定义一些必要的数据结构来描述这个业务场景,包括用户行为和规则模式两个数据结构。

/**
* 用户行为
* categoryId为商品类目ID
* behavior包括点击(pv)、购买(buy)、加购物车(cart)、喜欢(fav)
* */
case class UserBehavior(userId: Long,
itemId: Long,
categoryId: Int,
behavior: String,
timestamp: Long)
/**
* 行为模式
* 整个模式简化为两个行为
* */
case class BehaviorPattern(firstBehavior: String, secondBehavior: String)
然后我们在主逻辑中读取两个数据流:
// 主数据流 val userBehaviorStream: DataStream[UserBehavior] = ... // BehaviorPattern数据流 val patternStream: DataStream[BehaviorPattern] = ...
目前Broadcast State只支持使用Key-Value形式,需要使用MapStateDescriptor来描述。这里我们使用一个比较简单的行为模式,因此Key是一个空类型。当然我们也可以根据业务场景,构造复杂的Key-Value对。然后,我们将模式流使用broadcast方法广播到所有算子子任务上。
// Broadcast State只能使用 Key->Value 结构,基于MapStateDescriptor
val broadcastStateDescriptor =
new MapStateDescriptor[Void, BehaviorPattern]("behaviorPattern", classOf[Void], classOf[BehaviorPattern])
val broadcastStream: BroadcastStream[BehaviorPattern] = patternStream
.broadcast(broadcastStateDescriptor)
用户行为模式流先按照用户ID进行keyBy,然后与广播流合并:
// 生成一个KeyedStream val keyedStream = userBehaviorStream.keyBy(user => user.userId) // 在KeyedStream上进行connect和process val matchedStream = keyedStream .connect(broadcastStream) .process(new BroadcastPatternFunction)
BroadcastPatternFunction是KeyedBroadcastProcessFunction的具体实现,它基于Broadcast State处理主数据流,生成(Long, BehaviorPattern),分别表示用户ID和命中的行为模式。下面的代码展示了具体的使用方法。
/**
* 四个泛型分别为:
* 1. KeyedStream中Key的数据类型
* 2. 主数据流的数据类型
* 3. 广播流的数据类型
* 4. 输出类型
* */
class BroadcastPatternFunction
extends KeyedBroadcastProcessFunction[Long, UserBehavior, BehaviorPattern, (Long, BehaviorPattern)] {
// 用户上次性能状态句柄,每个用户存储一个状态
private var lastBehaviorState: ValueState[String] = _
// Broadcast State Descriptor
private var bcPatternDesc: MapStateDescriptor[Void, BehaviorPattern] = _
override def open(parameters: Configuration): Unit = {
lastBehaviorState = getRuntimeContext.getState(
new ValueStateDescriptor[String]("lastBehaviorState", classOf[String])
)
bcPatternDesc = new MapStateDescriptor[Void, BehaviorPattern]("behaviorPattern", classOf[Void], classOf[BehaviorPattern])
}
// 当BehaviorPattern流有新数据时,更新BroadcastState
override def processBroadcastElement(pattern: BehaviorPattern,
context: KeyedBroadcastProcessFunction[Long, UserBehavior, BehaviorPattern, (Long, BehaviorPattern)]#Context,
collector: Collector[(Long, BehaviorPattern)]): Unit = {
val bcPatternState: BroadcastState[Void, BehaviorPattern] = context.getBroadcastState(bcPatternDesc)
// 将新数据更新至Broadcast State,这里使用一个null作为Key
// 在本场景中所有数据都共享一个Pattern,因此这里伪造了一个Key
bcPatternState.put(null, pattern)
}
override def processElement(userBehavior: UserBehavior,
context: KeyedBroadcastProcessFunction[Long, UserBehavior, BehaviorPattern, (Long, BehaviorPattern)]#ReadOnlyContext,
collector: Collector[(Long, BehaviorPattern)]): Unit = {
// 获取最新的Broadcast State
val pattern: BehaviorPattern = context.getBroadcastState(bcPatternDesc).get(null)
val lastBehavior: String = lastBehaviorState.value()
if (pattern != null && lastBehavior != null) {
// 用户之前有过行为,检查是否符合给定的模式
if (pattern.firstBehavior.equals(lastBehavior) &&
pattern.secondBehavior.equals(userBehavior.behavior))
// 当前用户行为符合模式
collector.collect((userBehavior.userId, pattern))
}
lastBehaviorState.update(userBehavior.behavior)
}
}
总结下来,使用Broadcast State需要进行下面三步:
- 接收一个普通数据流,并使用
broadcast方法将其转换为BroadcastStream,因为Broadcast State目前只支持Key-Value结构,需要使用MapStateDescriptor描述它的数据结构。 - 将
BroadcastStream与一个DataStream或KeyedStream使用connect方法连接到一起。 - 实现一个
ProcessFunction,如果主流是DataStream,则需要实现BroadcastProcessFunction;如果主流是KeyedStream,则需要实现KeyedBroadcastProcessFunction。这两种函数都提供了时间和状态的访问方法。
在KeyedBroadcastProcessFunction个函数类中,有两个函数需要实现:
processElement:处理主数据流(非Broadcast流)中的每条元素,输出零到多个数据。ReadOnlyContext可以获取时间和状态,但是只能以只读的形式读取Broadcast State,不能修改,以保证每个算子实例上的Broadcast State都是相同的。processBroadcastElement:处理流入的广播流,可以输出零到多个数据,一般用来更新Broadcast State。
此外
onTimer()在先前注册的计时器触发时调用。定时器可以在任何处理方法中注册,并用于执行计算或将来清理状态。我们在示例中没有实现此方法以保持代码简洁。但是,当用户在一段时间内未处于活动状态时,它可用于删除用户的最后一个操作,以避免由于非活动用户而导致状态增长。
小结
本文解释了Broadcast State的原理和使用场景,并以电商平台用户行为分析为例演示了具体的使用方法。