本篇的主题是分段线性拟合,也叫回归树,是一种集成算法,它同时使用了决策和线性回归的原理,其中有两点不太容易理解,一个是决策树中熵的概念,一个是线性拟合时求参数的公式为什么是由矩阵乘法实现的。如需详解,请见前篇:
《机器学习_决策树与信息熵》
《机器学习_最小二乘法,线性回归与逻辑回归》
1. 画出股票的趋势线
我们常在股票节目里看到这样的驱势线:
比如说平台突破就可以买入了,几千支股票,能不能用程序的方式筛选哪支突破了呢?需要解决的主要问题是:怎么判断一段时间内股票的涨/跌/横盘,以及一段趋势的起止点和角度呢?
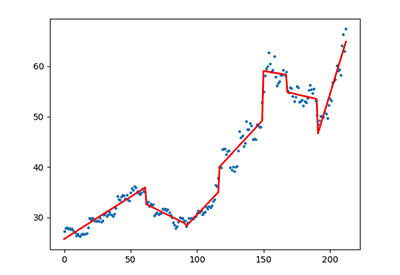
这里我们使用分段线性拟合,图中蓝色的点是某支股票每日的收盘价,红色的直线为程序画出的趋势线。稍做修改,还可以轻松地画出每段趋势所在的箱体,阻力线和支撑线,以及判断此前一般时间的趋势。下面我们就来看看原理和具体算法。
2. 线性回归
先看看线性回归(Linear regression),线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。简单地说,二维中就是画一条直线,让它离所有点都尽量地近(距离之和最小),用线抽象地表达这些点。具体请见《机器学习_最小二乘法,线性回归与逻辑回归》。
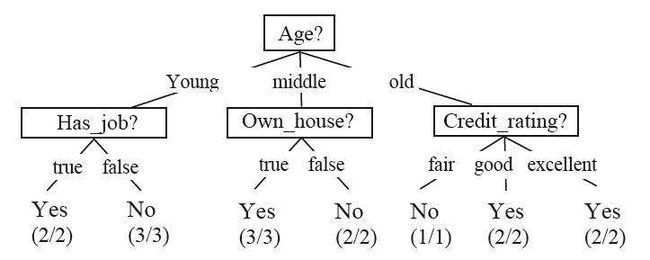
3. 决策树
我们再看看决策树,决策树(Decision Tree)决策树是一个预测模型;它是通过一系列的判断达到决策的方法。具体请见《机器学习_决策树与信息熵》。
4. 树回归
树回归把决策树和线性回归集成在一起,先决策树,在每个叶节点上构建一个线性方程。比如说数据的最佳拟合是一条折线,那就把它切成几段用线性拟合,每段切多长呢?我们定义一个步长(以忽略小的波动,更好地控制周斯),在整个区域上遍历,找最合适的点(树的分叉点),用该点切分成两段后,分别线性拟合,取整体误差和最小的点,以此类拟,再分到三段,四段……,为避免过拟合,具体实现一般同时使用前剪枝和后剪枝。
5. 代码
# -*- coding: utf-8 -*-
import tushare as ts
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 用feature把dataSet按value分成两个子集
def binSplitDataSet(dataSet, feature, value):
mat0 = dataSet[np.nonzero(dataSet[:,feature] > value)[0],:]
mat1 = dataSet[np.nonzero(dataSet[:,feature] <= value)[0],:]
return mat0,mat1
# 求给定数据集的线性方程
def linearSolve(dataSet):
m,n = np.shape(dataSet)
X = np.mat(np.ones((m,n))); # 第一行补1,线性拟合要求
Y = np.mat(np.ones((m,1)))
X[:,1:n] = dataSet[:,0:n-1];
Y = dataSet[:,-1] # 数据最后一列是y
xTx = X.T*X
if np.linalg.det(xTx) == 0.0:
raise NameError('This matrix is singular, cannot do inverse,\n\
try increasing dur')
ws = xTx.I * (X.T * Y) # 公式推导较难理解
return ws,X,Y
# 求线性方程的参数
def modelLeaf(dataSet):
ws,X,Y = linearSolve(dataSet)
return ws
# 预测值和y的方差
def modelErr(dataSet):
ws,X,Y = linearSolve(dataSet)
yHat = X * ws
return sum(np.power(Y - yHat,2))
def chooseBestSplit(dataSet, rate, dur):
# 判断所有样本是否为同一分类
if len(set(dataSet[:,-1].T.tolist()[0])) == 1:
return None, modelLeaf(dataSet)
m,n = np.shape(dataSet)
S = modelErr(dataSet) # 整体误差
bestS = np.inf
bestIndex = 0
bestValue = 0
for featIndex in range(n-1): # 遍历所有特征, 此处只有一个
# 遍历特征中每种取值
for splitVal in set(dataSet[:,featIndex].T.tolist()[0]):
mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal)
if (np.shape(mat0)[0] < dur) or (np.shape(mat1)[0] < dur):
continue # 样本数太少, 前剪枝
newS = modelErr(mat0) + modelErr(mat1) # 计算整体误差
if newS < bestS:
bestIndex = featIndex
bestValue = splitVal
bestS = newS
if (S - bestS) < rate: # 如差误差下降得太少,则不切分
return None, modelLeaf(dataSet)
mat0, mat1 = binSplitDataSet(dataSet, bestIndex, bestValue)
return bestIndex,bestValue
def isTree(obj):
return (type(obj).__name__=='dict')
# 预测函数,数据乘模型,模型是斜率和截距的矩阵
def modelTreeEval(model, inDat):
n = np.shape(inDat)[1]
X = np.mat(np.ones((1,n+1)))
X[:,1:n+1]=inDat
return float(X*model)
# 预测函数
def treeForeCast(tree, inData):
if not isTree(tree):
return modelTreeEval(tree, inData)
if inData[tree['spInd']] > tree['spVal']:
if isTree(tree['left']):
return treeForeCast(tree['left'], inData)
else:
return modelTreeEval(tree['left'], inData)
else:
if isTree(tree['right']):
return treeForeCast(tree['right'], inData)
else:
return modelTreeEval(tree['right'], inData)
# 对测试数据集预测一系列结果, 用于做图
def createForeCast(tree, testData):
m=len(testData)
yHat = np.mat(np.zeros((m,1)))
for i in range(m): # m是item个数
yHat[i,0] = treeForeCast(tree, np.mat(testData[i]))
return yHat
# 绘图
def draw(dataSet, tree):
plt.scatter(dataSet[:,0], dataSet[:,1], s=5) # 在图中以点画收盘价
yHat = createForeCast(tree, dataSet[:,0])
plt.plot(dataSet[:,0], yHat, linewidth=2.0, color='red')
plt.show()
# 生成回归树, dataSet是数据, rate是误差下降, dur是叶节点的最小样本数
def createTree(dataSet, rate, dur):
# 寻找最佳划分点, feat为切分点, val为值
feat, val = chooseBestSplit(dataSet, rate, dur)
if feat == None:
return val # 不再可分
retTree = {}
retTree['spInd'] = feat
retTree['spVal'] = val
lSet, rSet = binSplitDataSet(dataSet, feat, val) # 把数据切给左右两树
retTree['left'] = createTree(lSet, rate, dur)
retTree['right'] = createTree(rSet, rate, dur)
return retTree
if __name__ == '__main__':
df = ts.get_k_data(code = '002230', start = '2017-01-01') # 科大讯飞今年的股票数据
e = pd.DataFrame()
e['idx'] = df.index # 用索引号保证顺序X轴
e['close'] = df['close'] # 用收盘价作为分类标准Y轴, 以Y轴高低划分X成段,并分段拟合
arr = np.array(e)
tree = createTree(np.mat(arr), 100, 10)
draw(arr, tree)
6. 分析:
算法的拟合度和复杂度是使用步长,误差下降和最小样本数控制的,计算的时间跨度(一月/一年)也影响着程序运行时间。例程中计算的是“科大讯飞”近一年来的股价趋势,计算用时约十秒左右(我的机器速度还可以)。
要计算所有的股票,也需要不少时间。所以具体实现时,一方面可以利用当前价格和移动均线的相对位置过滤掉一些股票,另一方面,也可以将计算结果存储下来,以避免对之前数据的重复计算。