定义
关于最小生成树的定义,需要先了解如下这几个相关概念:
- 连通图:在无向图中,若任意两个顶点vi与vj都有路径相通,则称该无向图为连通图。
- 强连通图:在有向图中,若任意两个顶点vi与vj都有路径相通,则称该有向图为强连通图。
- 连通网:在连通图中,若图的边具有一定的意义,每一条边都对应着一个数,称为权;权代表着连接两个顶点的代价,称这种连通图叫做连通网。
- 生成树:一个连通图的生成树是指一个连通子图,它含有图中全部n个顶点,但只有足以构成一棵树的n-1条边。一颗有n个顶点的生成树有且仅有n-1条边,如果生成树中再添加一条边,则必定成环。
- 最小生成树:在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树。
因此,最小生成树算法研究的问题是:在AOV网中找出串联n个顶点代价总和最小的边集。
构造最小生成树可以有多种算法。大多数算法都是利用了最小生成树的一种简称为MST的性质:假设N = (V, {E})是一个连通网,U是顶点集V的一个非空子集。若(u, v)是一条具有最小权值的边,其中,u ∈ U,v ∈ V - U,则必存在一棵包含边(u, v)的最小生成树。
下面我们要介绍的Prim(普里姆)算法和Kruskal(克鲁斯卡尔)算法就是两个利用了MST的性质构造最小生成树的算法。
Prim(普里姆)算法
该算法也称为“加点法”,每次迭代选择代价最小的边对应的节点加入到最小生成树中。算法从某个节点S出发,逐步覆盖整个连通网的所有顶点。
算法思想
假设G = (V, {E})是连通网,TE是G上的最小生成树中边的集合。算法从U = {u0}(u0 ∈ V),TE = {}开始,重复执行下述操作:在所有u ∈ U, v ∈ V - U的边(u, v) ∈ E中找一条代价最小的边(u0, v0)并入集合TE中,同时将v0并入U中,直到U == V为止。此时TE中必有n - 1条边,则T = (V, {TE})为G的最小生成树。
算法描述
假设现要求如下示例图所示的最小生成树(其中,红色线段为最终的最小生成树结果):
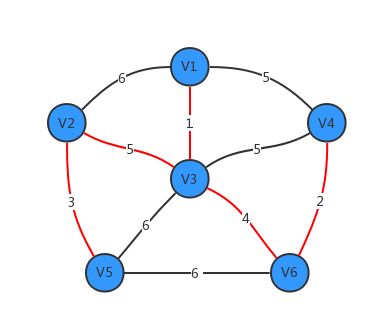
我们使用Guava的ValueGraph作为该图的数据结构,每个顶点对应一个lowsestCost变量来表示节点当前迭代过程中的最小代价,当lowsestCost设为0时,表示该节点已并入了集合U中。初始时将节点V1并入集合U中,表示算法将从节点V1开始迭代,持续迭代n - 1次找出lowsestCost值最小的节点就能求出整个包含n个节点的连通网中的最小生成树。
第一步,我们通过ValueGraphBuilder构造图的实例,并输入示例图中的边集:
//undirected()构建无向图
MutableValueGraph graph = ValueGraphBuilder.undirected()
.nodeOrder(ElementOrder.natural())
.expectedNodeCount(10)
.build();
graph.putEdgeValue(V1, V2, 6);
graph.putEdgeValue(V1, V3, 1);
graph.putEdgeValue(V1, V4, 5);
graph.putEdgeValue(V2, V3, 5);
graph.putEdgeValue(V2, V5, 3);
graph.putEdgeValue(V3, V4, 5);
graph.putEdgeValue(V3, V5, 6);
graph.putEdgeValue(V3, V6, 4);
graph.putEdgeValue(V4, V6, 2);
graph.putEdgeValue(V5, V6, 6);
初始输出结果如下:
nodes: [v1, v2, v3, v4, v5, v6],
edges: {[v4, v1]=5, [v2, v1]=6, [v3, v1]=1, [v5, v2]=3, [v3, v2]=5,
[v5, v3]=6, [v4, v3]=5, [v6, v3]=4, [v6, v4]=2, [v6, v5]=6}
我们引入一个临时结构来记录每个节点运算的中间结果:
private static class CloseEdge {
public String preNode; //标识该最小代价是从哪个顶点指向过来的
public int lowsestCost; //最小代价
}
第二步,声明最小生成树的结果,并初始化每个节点的CloseEdge的信息:
//最小生成树的结果graph,通过拷贝原graph的属性
MutableValueGraph result = ValueGraphBuilder.from(graph).build();
//节点的附加信息,用于保存计算的中间结果
Map closeEdges = new ArrayMap<>();
/**
* 初始化节点的权重信息
*/
for (String node : graph.nodes()) {
CloseEdge extra = new CloseEdge();
extra.preNode = startNode; //前一个节点为startNode节点
//有边连接时,lowsestCost为其边上的权值;没有边连接时,则为无穷大
extra.lowsestCost = graph.edgeValueOrDefault(startNode, node, Integer.MAX_VALUE);
closeEdges.put(node, extra);
}
第三步,开始迭代前,首先将startNode首先并入U集合中,即lowsestCost赋为0,并定义查找最小权值的方法:
//初始化时,先将startNode并入U集合(lowsestCost = 0)
closeEdges.get(startNode).lowsestCost = 0;
/**
* 找到一条{U, V - U}中权值最小的边,minCostNode是V - U集合中的顶点
*/
String minCostNode = ""; //存放权值最小边的节点
int min = Integer.MAX_VALUE;
for (String node : closeEdges.keySet()) {
CloseEdge value = closeEdges.get(node);
/**
* lowsestCost == 0时,表示该边已经并入了U集合,不在查找范围
*/
if (value.lowsestCost > 0 && value.lowsestCost < min) {
min = value.lowsestCost;
minCostNode = node;
}
}
第四步,迭代更新lowsestCost值,并将结果放入ValueGraph类型的result中:
for (int i = 0; i < closeEdges.size() - 1; i++) { //循环n -1次
/**
* 找到一条{U, V - U}中权值最小的边,minCostNode是V - U集合中的顶点
*/
String minCostNode = findMinCostNode(); //上述定义方法
if (!TextUtils.isEmpty(minCostNode)) {
CloseEdge minEdge = closeEdges.get(minCostNode);
/**
* 将最小的权重边放入结果Graph中
*/
result.putEdgeValue(minEdge.preNode, minCostNode, minEdge.lowsestCost);
minEdge.lowsestCost = 0; //将找到的最小的边并入U集合中
/**
* 并入minCostNode后,更新minCostNode到其他节点的lowsestCost信息,作为下次循环查找的条件
*/
for (String node : graph.adjacentNodes(minCostNode)) { //优化:只遍历邻接点即可
final int cost = graph.edgeValueOrDefault(minCostNode, node, Integer.MAX_VALUE);
CloseEdge current = closeEdges.get(node);
if (current.lowsestCost > 0 && cost < current.lowsestCost) {
current.lowsestCost = cost; //更新权值
//该最小权值是从minCostNode指向过来的
current.preNode = minCostNode;
}
}
}
}
最终程序运行的最小生成树的结果如下(对应开始时示例图中的红色线段):
nodes: [v1, v2, v3, v4, v5, v6],
edges: {[v3, v1]=1, [v5, v2]=3, [v3, v2]=5, [v6, v3]=4, [v6, v4]=2}
总结
Prim算法涉及到两层循环(第一层为迭代更新lowsestCost,第二层为找权值最小的边),由此,Prim算法的时间复杂度为O(n²)。更重要的是,这里可以看出算法的时间复杂度仅仅与图中节点的数量有关,而与图中边的数量无关,因此适用于求边稠密图的最小生成树。而下面要介绍的Kruskal算法的时间复杂度为O(e * log e)(e为图中边的数目),因此它相对于Prim算法而言,更适合于求边稀疏的最小生成树。
具体Prim算法的示例demo实现,请参考:https://github.com/Jarrywell/GH-Demo/blob/master/app/src/main/java/com/android/test/demo/graph/Prim.java
Kruskal(克鲁斯卡尔)算法
该算法也称为“加边法”,初始时最小生成树的边数为0,没迭代一次选择一条满足条件的最小代价边加入到最小生成树的边集合中。
算法思想
假设连通网G=(V, {E}),令最小生成树的初始状态为只有n个顶点而无边的非连通图T=(V, {}),图中每个顶点自成一个连通分量。在E中选择权值最小的边,若该边依附的顶点落在T中不同的连通分量中,则将此边加入到T中;否则,舍去此边而选下一条权值最小的边。依次类推,直到T中所有顶点都在同一个连通分量上(此时含有n-1边)为止,这时的T就是一棵最小的生成树。
算法描述
假设现要求如下示例图所示的最小生成树(其中,红色线段为最终的最小生成树结果):
我们使用Guava的ValueGraph作为该图的数据结构,每个顶点对应一个vest变量来表示节点当前属于哪个连通分量(初始化是每个顶点自成一个连通分量,即没有任何边连接;vest为节点的序号),并将边按照边权值大小递增排序,每次选择一条不在同一连通分量中的边并入最小生成树的集合中,直到所有节点都在同一连通分量中。
第一步,我们通过ValueGraphBuilder构造图的实例,并输入示例图中的边集。(由于这里使用的就是Prim算法中同一个示例图,故此处不再贴图的初始化代码了)
第二步,初始化最小生成树的结果集合以及辅助变量vest的初始值:
//最小生成树的结果graph
ValueGraph result = ValueGraphBuilder.from(graph).build();
/**
* 辅助变量,用于判断两个顶点是否在两个连通分量中
*/
Map vest = new ArrayMap<>();
/**
* 初始化辅助数组vest,一开始每个节点单独成一个连通分量
*/
int index = 0;
for (String node : graph.nodes()) {
vest.put(node, index++); //使用节点需要作为连通分量的序号
}
第三步,将图中边集合按其权值大小增序排列:
/**
* 将图中所有的边,按权值从小到大排序,便于后面一次循环就能从小到大遍历
* EndpointPair数据结构用于存储边的两个顶点U和V
*/
List> edges = sortEdges(graph);
/**
* 将图中的边按其权值大小排序
* @param graph
* @return
*/
List> sortEdges(final ValueGraph graph){
List> edges = new ArrayList<>();
edges.addAll(graph.edges()); //Set转List
/**
* 使用Collections的sort函数进行排序,compare()比较的是边权值
*/
Collections.sort(edges, new Comparator>() {
@Override
public int compare(EndpointPair endPoint1,
EndpointPair endPoint2) {
final int edge1 = graph.edgeValueOrDefault(endPoint1.nodeU(),
endPoint1.nodeV(), 0);
final int edge2 = graph.edgeValueOrDefault(endPoint2.nodeU(),
endPoint2.nodeV(), 0);
return edge1 - edge2;
}
});
return edges;
}
排序输出:
v3 -> v1 = 1
v6 -> v4 = 2
v5 -> v2 = 3
v6 -> v3 = 4
v4 -> v1 = 5
v3 -> v2 = 5
v4 -> v3 = 5
v2 -> v1 = 6
v5 -> v3 = 6
v6 -> v5 = 6
第四步,增序遍历一遍图中所有的边,将满足条件的边(边的节点处于不同的连通分量)放入最小生成树中:
/**
* 按增序遍历图中所有边
*/
for (EndpointPair edge : edges) {
/**
* 获取两个节点所代表的连通分量的sn值
*/
final int nodeUSn = vest.get(edge.nodeU());
final int nodeVSn = vest.get(edge.nodeV());
/**
* 判断一条边的两个顶点是否对应不同的连通分量;若不相同,则将该边加入最小生成树的图中
*/
if (nodeUSn != nodeVSn) {
int value = graph.edgeValueOrDefault(edge.nodeU(), edge.nodeV(), 0);
result.putEdgeValue(edge.nodeU(), edge.nodeV(), value); //最小生成树
Log.i(TAG, edge.nodeU() + " ->" + edge.nodeV() + ": " + value);
/**
* 更新加入最小生成树中边对应的整个连通分量的sn值(后一个连通分量并入
* 前一个连通分量),以此作为下一次遍历的依据
*/
for (String node : vest.keySet()) {
if (vest.get(node) == nodeVSn) {
vest.put(node, nodeUSn);
}
}
}
}
最终程序运行的最小生成树的结果如下(对应开始时示例图中的红色线段):
nodes: [v1, v2, v3, v4, v5, v6],
edges: {[v3, v1]=1, [v5, v2]=3, [v3, v2]=5, [v6, v3]=4, [v6, v4]=2}
总结
Kruskal算法因此至多对e条边各扫描一次,且对边排序的最优时间复杂度为O(log e),因此其时间复杂度为O(e * log e)。由于该算法仅与图中边的数量有关,因此Kruskal算法适用于求边稀疏的最小生成树。
具体Prim算法的示例demo实现,请参考:https://github.com/Jarrywell/GH-Demo/blob/master/app/src/main/java/com/android/test/demo/graph/Kruskal.java
参考文档
《数据结构》(严蔚敏版)
https://www.cnblogs.com/wxdjss/p/5503023.html