全1或全0初始化
全1或全0初始化的训练效果

全1或全0初始化的训练效果
After 858 Batches (2 Epochs):
Validation Accuracy
11.260% -- All Zeros
9.900% -- All Ones
Loss
2.300 -- All Zeros
372.644 -- All Ones
全1和全0的方式都不好,因为大家都一样,反向传播算法不知道更新哪一个
Uniform Distribution
Uniform Distribution的训练效果

Uniform Distribution的训练效果
After 858 Batches (2 Epochs):
Validation Accuracy
65.340% -- tf.random_uniform [0, 1)
Loss
64.356 -- tf.random_uniform [0, 1)
设置Uniform Distribution权重的方式
通用的方法是,设置一个0左右的不太小的区间。
一个好的选择起点是从$ y=\frac 1 {\sqrt{n}} $公式选取[−y, y],公式里的n是神经元输入的个数。
y的不同区间值的效果

y的不同区间值的效果
After 858 Batches (2 Epochs):
Validation Accuracy
91.000% -- [-1, 1)
97.220% -- [-0.1, 0.1)
95.680% -- [-0.01, 0.01)
94.400% -- [-0.001, 0.001)
Loss
2.425 -- [-1, 1)
0.098 -- [-0.1, 0.1)
0.133 -- [-0.01, 0.01)
0.190 -- [-0.001, 0.001)
如果设置的太小会有问题
Normal Distribution
Normal Distribution的训练效果
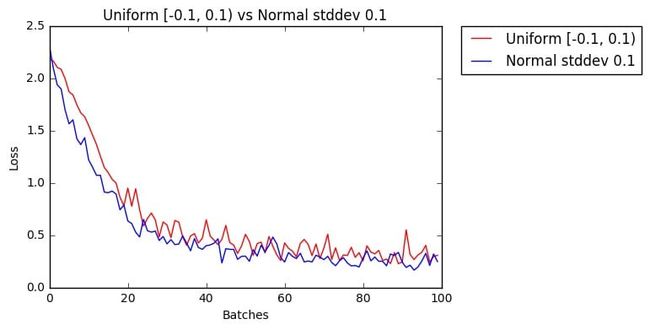
Normal Distribution的训练效果
After 858 Batches (2 Epochs):
Validation Accuracy
96.920% -- Uniform [-0.1, 0.1)
97.200% -- Normal stddev 0.1
Loss
0.103 -- Uniform [-0.1, 0.1)
0.099 -- Normal stddev 0.1
比Uniform Distribution稍微有所提高
Truncated Normal Distribution
Truncated Normal Distribution的训练效果

Truncated Normal Distribution的训练效果
After 858 Batches (2 Epochs):
Validation Accuracy
97.020% — Normal
97.480% -- Truncated Normal
Loss
0.088 — Normal
0.034 -- Truncated Normal
模型再大点差别会更明显,因为正态分布有些过大过小的数会影响模型,而截断他就少受影响
结论
一般来说就用Truncated Normal Distribution,效果是最好的
关于我:
linxinzhe,策略工程师,在某银行从事IT策略研究和规划,领域:企业数字化、企业架构、公司金融、金融科技。文集:linxinzhe.cn