Spark是一个快速的集群化的实时计算系统。支持Java, Scala, Python 和R语言的高级API。
一 Spark生态:

支持Spark Sql用于sql和结构化数据查询处理;支持MLlib用于机器学习;支持GraphX用于图形处理;支持Spark Streaming和Structured Sql(spark2.1.1版本发布)用于实时计算。(其中,我们使用的Spark功能主要是Spark Sql和Structured Sql。其中Spark sql用于查询模块,可以联合多个数据源进行查询。Structured Sql用于流式数据处理。)
部署方式有:
1、本地运行模式:new SparkConf().setAppName(“sparkName”)
.setMaster(config.getString(“local[*]”)))
2、Stanalone模式:
1)由master/slaves服务组成的
2)各个节点上的资源被抽象成粗粒度的slot,有多少slot就能同时运行多少task。
3)部署时通过spark-env.sh和slave配置文件进行配置,使用start-all.sh可以一键启动。
3、EC2模式:
部署于云端。
4、Spark on Mesos模式:
支持粗粒度模式和细粒度模式。
1)粗粒度模式:应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过 程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。比如你提交应用程序时,指定使用5个executor运行你的应用程序,每个executor占用5GB内存和5个CPU,每个executor内部设置了5个slot,则Mesos需要先为executor分配资源并启动它们,之后开始调度任务。另外,在程序运行过程中,mesos的master和slave并不知道executor内部各个task的运行情况,executor直接将任务状态通过内部的通信机制汇报给Driver,从一定程度上可以认为,每个应用程序利用mesos搭建了一个虚拟集群自己使用。
2)细粒度模式:鉴于粗粒度模式会造成大量资源浪费,Spark On Mesos还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,思想是按需分配。与粗粒度模式一样,应用程序启动时,先会启动executor,但每个executor占用资源仅仅是自己运行所需的资源,不需要考虑将来要运行的任务,之后,mesos会为每个executor动态分配资源,每分配一些,便可以运行一个新任务,单个Task运行完之后可以马上释放对应的资源。每个Task会汇报状态给Mesos slave和Mesos Master,便于更加细粒度管理和容错,这种调度模式类似于MapReduce调度模式,每个Task完全独立,优点是便于资源控制和隔离,但缺点也很明显,短作业运行延迟大。
5、Spark on yarn模式:
支持粗粒度模式,只要用yarn的resource manage进行调度管理。(目前选择的是该模式)
(细粒度模式尚未实现 https://issues.apache.org/jira/browse/YARN-1197)
集成性:
Spark可以很好的集成HDFS,HBase,Elatatic Search,kudu等存储系统,mysql等关系性数据库和json csv等静态文件处理。
二、Spark基本架构:

1)Cluster Manager:在standalone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器
2)Worker节点:从节点,负责控制计算节点,启动Executor或者Driver。
3)Driver: 运行Application 的main()函数
4)Executor:执行器,是为某个Application运行在worker node上的一个进程
三、运行流程
1)创建Spark context
2)Spark context向Cluster manager申请运行Executor资源,并启动StandaloneExecutorbackend
3)Executor向SparkContext申请Task
4)SparkContext将应用程序分发给Executor
5)SparkContext构建成DAG图,将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行
6)Task在Executor上运行,运行完释放所有资源
四、Cluster模式和client模式
yarn-cluster模式下,driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行。yarn-cluster模式不适合运行交互类型的作业。

Yarn-client模式下,Application Master仅仅向YARN请求executor,client会和请求的container通信来调度他们工作。

五、Spark sql
Spark sql应用于查询模块。
以CSV文件为例,前端查询为select * from CSV.test
1)通过CSV.test查询数据库获取对应的csv文件存储路径path。
2)spark读取path对应的hdfs文件生成dataset
3)dataset.createTempView()生成临时表testTable
4)spark执行sql,select * from testTable并返回结果
六、Structured Streaming
Spark2.0中提出一个概念,continuous applications(连续应用程序)。
Spark Streaming等流式处理引擎致力于流式数据的运算,比如通过map运行一个方法来改变流中的每一条记录,通过reduce可以基于时间做数据聚合。但是,事实上很少有只在流式数据上做运算的需求,相对的,流式处理往往是一个大型应用的一部分。continuous applications提出后,实时运算作为一部分,不同系统间的交互等也可以由Structured Streaming来处理。如下图,左侧为Spark Streaming类的流式引擎,交互是由使用者来处理;右侧为Strctured Streaming类的连续应用,交互由应用来处理。(https://databricks.com/blog/2016/07/28/continuous-applications-evolving-streaming-in-apache-spark-2-0.html)
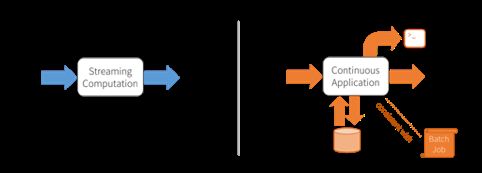
Structured Streaming是一个建立在Spark sql引擎上的可扩展高容错的流式处理引擎。它使得可以像对静态数据进行批量处理一样来处理流式数据。Structured Streaming provides fast, scalable, fault-tolerant, end-to-end exactly-once stream processing without the user having to reason about streaming.
Structured Streaming抽象了一个DataSet中无边界的表。structured streaming将流数据看作是一张没有边界的表,流数据不断的向表尾增加数据
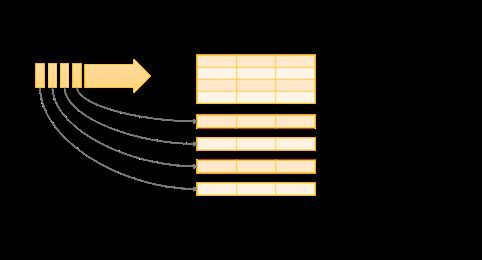
在每一个周期(默认1s),新的内容将会增加到表尾,查询的结果将会更新到结果表中。一旦结果表被更新,就需要将改变后的表内容输出到外部的sink中。
如Kafka—etl—es的过程,spark每秒钟从source—kafka读取一批数据,写入无边界表中,通过dataset的spark sql操作进行ETL转换,更新result表,随着result表更新,变化的result行将被写入外部sink—es。
source类型:File source,Kafka source Socket source
sink类型:File sink,Foreach sink,Console sink,Memory sink,其中es sink是由Elastatic search扩展的。
输出模式:
Complete mode: 不删除任何数据,在 Result Table 中保留所有数据,每次触发操作输出所有窗口数据;
Append mode: 当确定不会更新窗口时,将会输出该窗口的数据并删除,保证每个窗口的数据只会输出一次;
Updated mode: 删除不再更新的时间窗口,每次触发聚合操作时,输出更新的窗口。
聚合:输出模式必须是Append或Updated。sink为es时只能是Append。
Event time:时间发生时间,来源于source数据中的时间列。
Watermark:数据过期时间。