THE SWIRLDS HASHGRAPH CONSENSUS ALGORITHM:FAIR, FAST, BYZANTINE FAULT TOLERANCE 学习总结
-
DAG简介
· DAG(Directed Acyclic Graph):“有向无环图”
DAG使得区块链从单链进化到树状和网状、从区块粒度细化到交易粒度、从单点跃迁到并发写入,是区块链从容量到速度的一次革新。
· 传统区块链和DAG的区别:
1. 单元:区块链组成单元是Block(区块),DAG组成单元是TX(交易);
2. 拓扑结构:区块链是由区块组成的单链,只能按出块时间同步依次写入;DAG是由交易单元组成的网络,可以异步并发写入交易; 3. 粒度:区块链每个区块单元记录多个用户的多笔交易,DAG每个单元记录单个用户交易。
-
Hashgraph简介

Hashgraph是一种DAG图,它不同于区块链的链式结构,而是一种以Hash算法为支撑的有向无环图。一般来说,(左图)传统的区块链就像一颗有主干的树,要不断地剪掉分支,保持主干,通过区块链接形成一条单一的合法主链
Hashgraph(哈希图)不剪枝,使用DAG的结构。它的基本组成单元是event(事件),每个事件都不会被抛弃,最终组合成为一个整体。这是一种更有效率的数据结构。
为什么更有效率呢? 因为Hashgraph不抛弃事件,结构的增长不会受到限制,任何人都可以创建交易,这样,交易的吞吐量就会大增,从这角度看,它实现了更高的交易速度,Hashgraph算法的核心技术点是两个部分:Gossip about Gossip(谣言算法)和Virtual Voting(虚拟投票)。
-
Hashgraph优点&缺点
优点:
①交易非常快速,根据官网的测试数据,可以达到250000TPS。
②公平,使用一致性时间戳,在论文里证明了攻击者操纵交易的顺序是非常困难的。
③安全,达到共识算法最高的安全标准(异步拜占庭容错,Asynchronous Byzantine Fault Tolerant),可以防止对错误信息达成共识。
④Hashgraph的共识算法是非确定性的,但是能保证最终确定性。同时,因为所有节点都是对等节点,避免了潜在的DDOS攻击的风险。也就是说虽然无法保证在某个时间点,所有节点状态保持一致,但能保证在最终某个时刻下,所有节点对某个时间点之前的网络达成一致,这与PoW是相似的。
但是Hashgraph也不是没有缺点,首先,它目前并没有开源,整个共识系统由一家商业公司Swirlds所有。其次,谣言算法是否真的适用于大规模公链环境,还不确定,因为一旦大规模的节点加入或退出,整个哈希图的遍历时间以及安全性难以保障。最后,在Hashgraph协议中所有节点必须保存全网数据,不知道它如何解决数据压缩问题。
-
Event(事件)数据结构
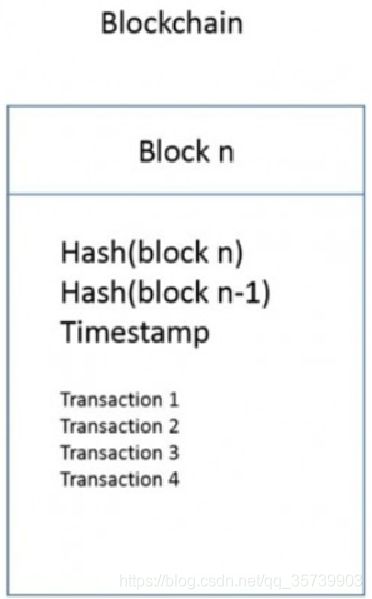
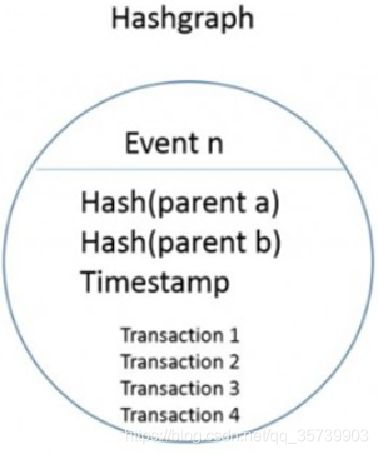
接下来就详细的分析hashgragh共识算法。它没有区块的概念,而是产生了与之非常类似的Event(事件),作为对比,左图是区块的数据结构,右图是事件的数据结构。
每个Event包含了两个Hash值,第一个Hash指向本节点的最新事件,第二个Hash指向其他节点传递的最新事件。
结构的下方存储了当前节点记录的各个交易,最后对整个事件加上时间戳并且签名,这样就构成了整个事件的结构。
-
Gossip About Gossip
首先来看hashgraph第一个核心技术:谣言算法Gossip About Gossip。
Gossip简单来说就是,节点随机选择一个连接的邻节点,向其发送一条信息(Event)。 节点收到gossip信息时,首先对该信息进行签名,再把签名打包进一个新的信息中,然后随机发送给网络中连接的任一节点。这样,每个节点发出的Gossip信息都包含了前一个Gossip信息的签名验证,实际上就是做了一个见证工作(Witnessing)。这就是要演算法的基本思想。
下面通过结构图来演示该算法运作流程与事件的状态变化。
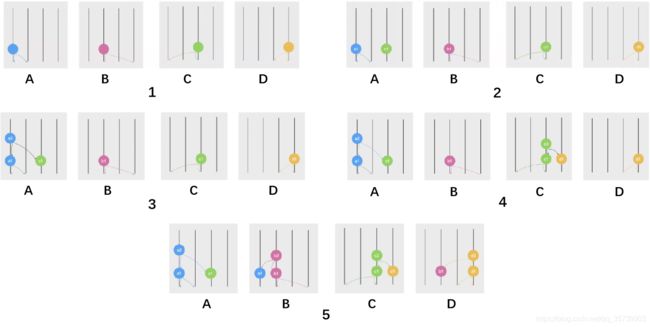
参与共识的每个节点都会保存一份完整的hashgraph副本图,初始时,每个节点上的副本图都是空的,当开始有节点产生Event之后,就会在自己的副本图上进行记录。
图1,有ABCD四个节点,每个节点都创建第一个事件时,展示他们各自的副本图。
图2,当 A 收到 C 发来的事件c1,A 就会更新本地的 hashgraph 副本。
图2经过一段时间变成图3,节点A基于 事件 a1 和 事件 c1 创建一个新的事件a2,并且会将新生成的事件a2 Gossip 出去。
假设刚才在图3中 A 收到 C 的事件后,C 也收到了 D 的事件,那么同理,C节点也会创建一个新的事件c2,图4中各个节点的副本图是这样的。
图5中某个时间点之后,大家都收到了彼此发给对方的消息。在节点相互 Gossip 通信的过程中,它们各自 hashgraph 副本都不相同,比如图5中的节点 A 和 B,A 记录了自己所创建的所有事件a1、a2和接收到的c1,而 B 同样记录了自己所有的事件b1 和 b2还有接收的a1。但是 A 缺少 B 的所有事件,而 B 则缺少 A 的最新事件 a2。
那么就牵扯到节点间的通信,在图5中,当A准备把 a2 发给B ,同时A在更新自己副本上B的数据,发现自己缺少B这部分前序的数据,那么B会把它的历史数据同步(Sync)给A。而B的副本上已经有 a1 了,因此在收到 a2 之后无需再同步。最终,hashgraph 就会更新成图6:

接下来,来解释 Hashgraph 共识算法中定义了哪些状态。
-
可见(see)&强可见(strongly seeing)
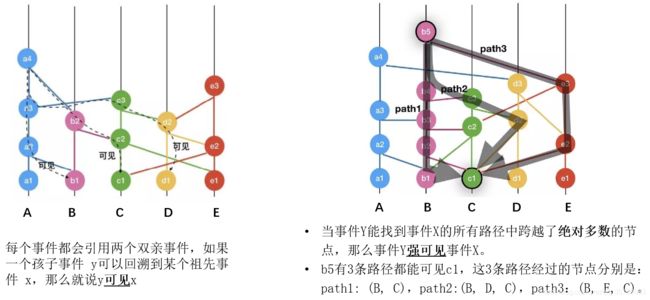
由于某个节点的hashgraph副本图中,每个事件都会引用两个双亲事件,如果一个孩子事件 y可以回溯到某个祖先事件 x,那么就说y可见x。而且,同一个节点产生的事件,后续事件总是可见先前所有事件,如左图:a4可见a3,a2,a1。
当事件Y能找到事件X的所有路径中跨越了绝对多数的节点,那么事件Y强可见事件X。注意:这里的绝对多数是指 超过节点数 2/3。
比如右图,想要判断 b5是否强可见 c1,我们需要做的就是,把所有从 b5 能可见 c1 的路径都找出来,如果这些路径集合中,能够包含超过 2/3 的节点(也就是要包含至少 4 个节点),那么就说 b5 强可见 c1。可以看到,b5有3条路径都能可见c1,这3条路径经过的节点分别是:path1: (B, C),path2:(B, D, C),path3:(B, E, C)。这三条路径一共经过了 B, C, D, E 4 个节点,满足超过 2/3 节点的要求,因此,可以说事件b5强可见事件c1。
-
轮次(Round)&创建轮(round created)
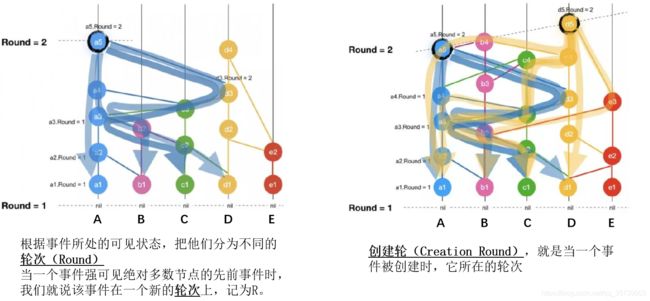
轮次:
在 Hashgraph 中,根据事件所处的可见状态,把他们分为不同的轮次(Round) 当一个事件强可见绝对多数节点的先前事件时,我们就说该事件在一个新的轮次上,记为R。比如初始状态时,所有节点均一致,就可以把它定义为是一个新的轮次,R=1。左图中:事件 a5 强可见了 R 轮的 a1, b1, c1, d1 共 4 个事件,也就是说强可见了绝对多数节点的第 R 轮的事件,因此,a5 就在一个新的轮次 R + 1 上。
创建轮:
创建轮(Creation Round),就是当一个事件被创建时,它所在的轮次通常,一个事件被创建时,它会被立即赋予一个轮次号,它跟双亲事件是在同一个轮次。也就是说,如果该事件的双亲事件在第 R 轮,那么该事件的创建轮就是 R 。
比如,右图中,初始(Genisis)情况下,所有节点的状态都是相同的,把它定义为第 R 轮( R = 1),后续创建的事件都是在第 R 轮的。当 a5 和 d5 被创建时,它们的创建轮是第 R 轮,而当它们能够强可见 绝对多数节点 的第 R 轮的见证人事件(即 a1, b1, c1, d1)时,那么a5 和 d5 都变成 R + 1 轮的事件,并且,在它们之后创建的子孙事件都在 R + 1 轮。
-
见证人(Witness)&知名见证人(Famous Witness)
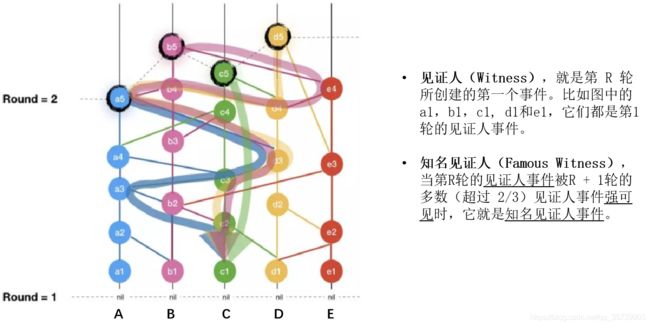
见证人(Witness),就是第 R 轮所创建的第一个事件。比如图中的 a1,b1,c1, d1和e1,它们都是第1轮的见证人事件。
知名见证人(Famous Witness),当第R轮的见证人事件被R + 1轮的多数(超过 2/3)见证人事件强可见时,它就是知名见证人事件。
由图中可以看到,c1 被 R +1 轮的大部分见证人事件(a5,b5,c5,d5)强可见,因此 c1 就是第1轮的某个知名见证人。知名见证人意味着不可更改,这时候系统就可以对该事件进行 commit。
-
接收轮(round received)&共识时间戳
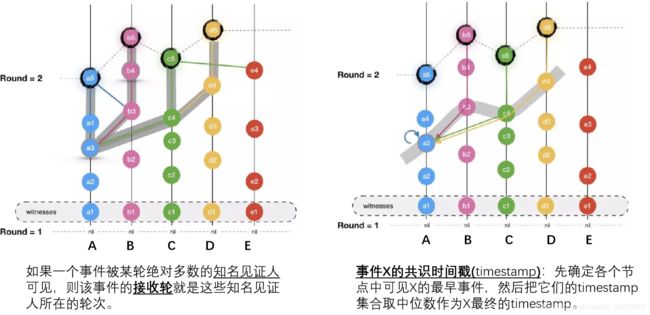
如果一个事件被某轮绝对多数的知名见证人可见,则该事件的接收轮就是这些知名见证人所在的轮次。
在左图中,假定 a5, b5, c5, d5 都是 R = 2 轮的知名见证人,它们都可见 a3 事件,那么 a3 在 R = 2 轮被接受。而对于 b4 来说,只有 b5 可见它,其他见证人并不可见它,因此,它的接收轮还不确定,只能等待后续轮次的见证人满足可见的条件,才能确定它的接收轮。
事件X的共识时间戳(timestamp):先确定各个节点中可见X的最早事件,然后把它们的timestamp集合取中位数作为X最终的timestamp。
比如在右图中,想要确定 a3 的 timestamp,我们从各个可见它的节点中,查找最早可见 a3 的事件。A 节点最早可见 a3 的时间就是 a3 自己,而 B 节点最早可见 a3 的则是 b3,同理得到 c4 和 d4。这样就得到一个 timestamp 集合:[a3, b3, c4, d4],取它们的中位数,就得到一个基准 timestamp作为 a3 的共识时间戳。根据相同的做法可以得到其他所有事件的 timestamp,最终可以得到一个 Total order。
-
虚拟投票(Virtual Vote)
通过之前的谣言算法解决了Hashgraph中节点之间的通信,但这仅仅只是通信步骤,节点之间达成共识还需要虚拟投票机制。虚拟投票是因为通过执行谣言算法后所有节点都是全节点,都存储了完整的网络历史,在需要对某一提案达成共识时并不需要大规模的消息通信,每个节点独立执行投票算法,并且所有节点一定会得出相同的共识结果。
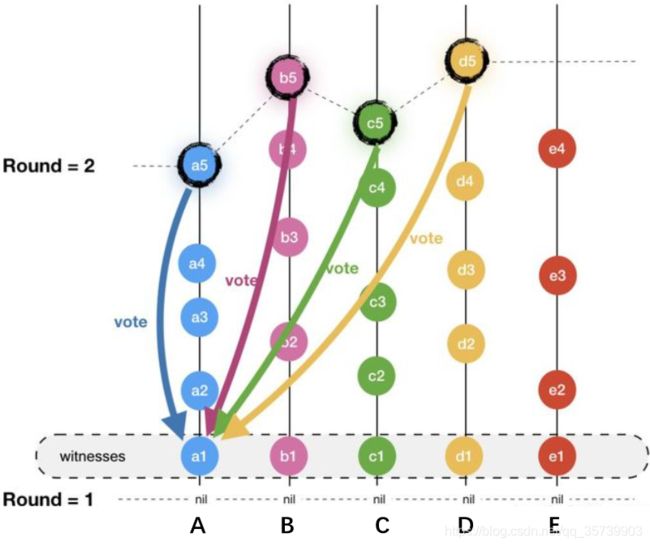
对第R轮的事件a1进行虚拟投票经过的步骤:
1)判断每个节点在R + 1轮的见证人事件。
2)判断第R + 1轮的见证人事件是否强可见a1,如果R+1轮某个见证人事件强可见a1,那就相当于Vote Yes。
3)计算Vote数量,如果超过2/3的R+1轮的见证人事件都投票Yes。就把a1标记为Famous Witness,随后commit a1。
-
计票(Counting)
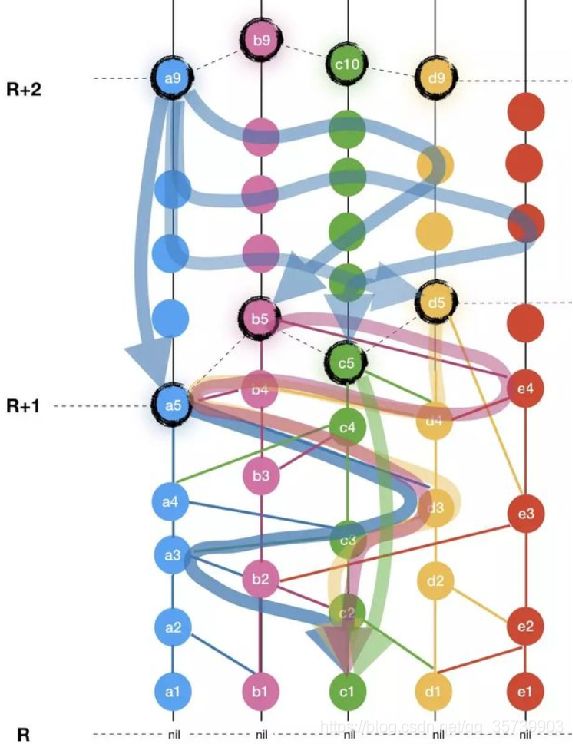
虚拟投票之后,还需要计票过程:
计票过程是在 R + 2 轮进行的。因为即使 R + 1 轮所有见证人事件都强可见第R轮的见证人事件,但它们彼此之间也不知道对方的投票情况。因此,必须由下一轮的见证人事件来收集大家的投票结果。
在图中R + 1 轮的 [a5, b5, c5, d5] 以绝对多数的比例对 c1 形成了强可见状态,使得 c1 满足成为知名见证人人条件。R+2 轮上的每个见证人则对 R+1 轮的见证人收集投票。比如,R + 2 轮的见证人 a9,它强可见了 R+1 轮的那四个投yes的事件a5,b5,c5,d5,因为数量已经达到绝对多数的要求,因此 a9 可以立即确认 c1 事件,也就是说, c1 已经达到全网共识而且不可更改。
事实上,R + 2 轮这个收集投票的过程只是一个学习共识结果并进行提交(commit)的过程,因为一旦知名见证人被确定,剩下的过程就只是各个节点把这个结果进行提交而已了。
-
Hashgraph共识算法流程总结
1. 每个节点都在运行Gossip about Gossip算法,随机找到其他节点把自己知道的事件传递给对方。
2. 每个节点同时也在接受其他节点更新过来的事件,接受方节点内部需要进行额外一系列的运算:
a. 接收和处理接收的事件
b. 创建一个新的事件,并且指向自己的最新事件和Gossip来源节点的最新事件
c. 对所有已知的事件分配创建轮次,并确定事件是否是该轮次内的见证人
d. 对所有已知的见证人进行虚拟投票并计票,选出知名见证人
e. 通过知名见证人和共识时间戳,确定所有事件的共识顺序