批量操作
首先创建一个用于演示的索引
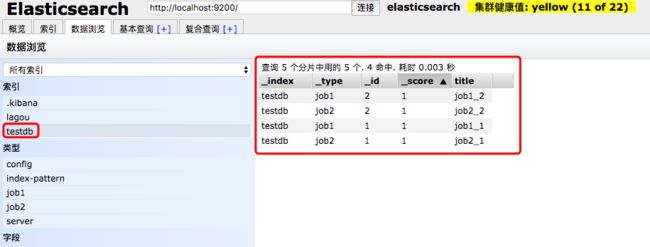
_mget批量查询

也可以这样写
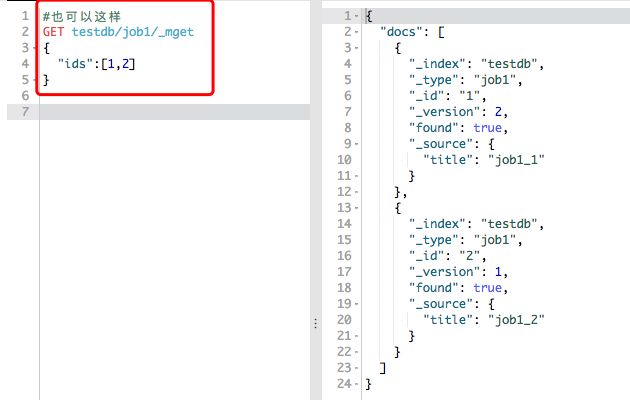
bulk批量导入
批量导入可以合并多个操作,比如index,delete,update,create等等。也可以帮助从一个索引导入另一个索引。需要注意的是,每一条数据都由两行构成(delete除外),其它命令比如index和create都是由元信息行和数据行组成,update比较特殊,它的数据行可能是doc,也可能是upset或者script,如果不了解的朋友可以参考前面的update的翻译。
action_and_meta_data\n
optional_source\n
举个例子:
{"index":{"_index":"test","_type":"type1","_id":"1"}}
{"field1":"value1"}
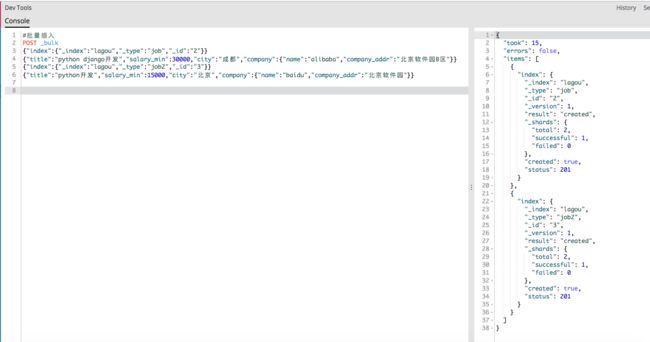
bulk各种操作

映射
定义:创建索引的时候,可以预先定义字段的类型以及相应属性
elasticsearch会根据JSON源数据的基础类型猜测你想要的字段映射。将输入的数据转变成可搜索的索引项。Mapping就是我们自己定义的字段的数据类型,同时告诉elasticsearch如何索引数据以及是否可以被搜索。
作用:会让索引建立的更加细致和完善
类型:静态映射和动态映射
内置类型
string类型:text,keyword(string类型在es5开始已经废弃)
数字类型:long,integer,short,byte,double,float
日期类型:date
bool类型:boolen
binary类型:binary
复杂类型:object,nested
geo类型:geo-point,geo-shape
专业类型:ip,competion
常用属性
属性:描述
store:值为yes表示存储,为no表示不存储,默认为no,适合所有类型
index:yes表示分析,no表示不分析,默认值为true,适合string类型
null_value:如果字段为空,可以设置一个默认值,比如“NA”,适合所有类型
analyzer:可以设置索引和搜索时用的分析器,默认使用的是standard分析其,还可以使用whitespace,simple.english
include_in_all:默认es为每个文档定义一个特殊域_all,它的作用是让每个字段被搜索到,如果不想某个字段被搜索到,可以设置为false,适合所有类型
format:时间格式字符串的模式,适合date类型
创建映射例子:
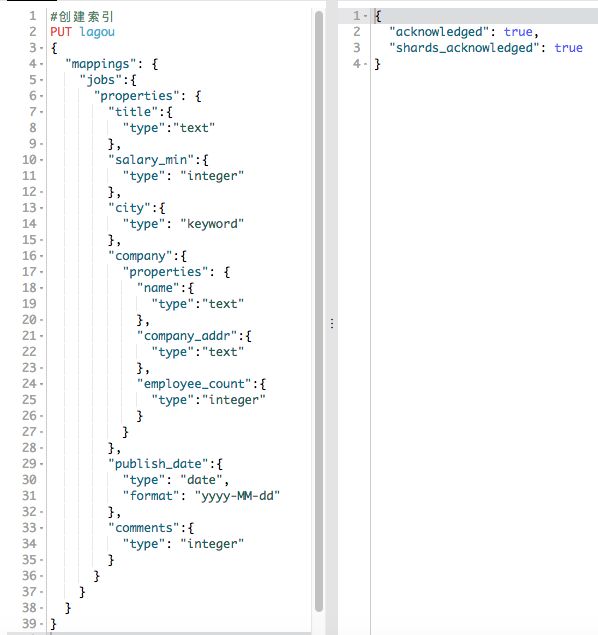
对应这个映射创建一条数据
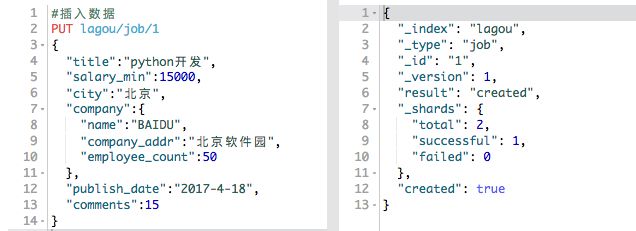
当然,映射也是可以获取的

查询
elasticsearch是功能非常强大的搜索引擎,使用它的目的就是为了快速的查询到需要的数据。
查询分类:
基本查询:使用elasticsearch内置查询条件进行查询
组合查询:把多个查询组合在一起进行复合查询
过滤:查询同时,通过filter条件在不影响打分的情况下筛选数据
match查询:会将被查询对象先进行分词处理,在作为关键词进行查询。如下图就把title中包含python的数据查询出来了。
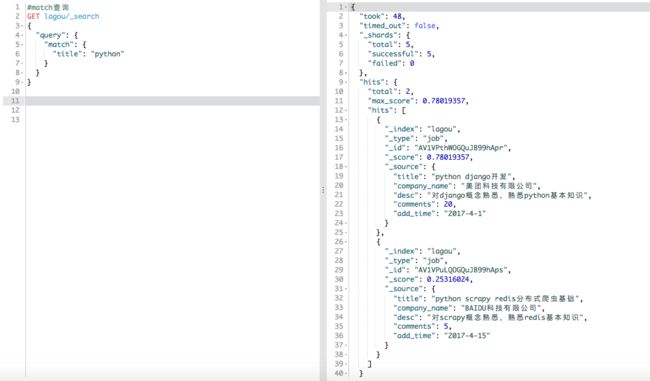
我们将title换成python网站,发现也可以检索出这两条信息,原因是match操作会将title中的字段进行分词,然后作为关键字进行搜索,类似于or的关系。

term查询:会将被查询对象作为一个关键字直接进行查询,如下图:
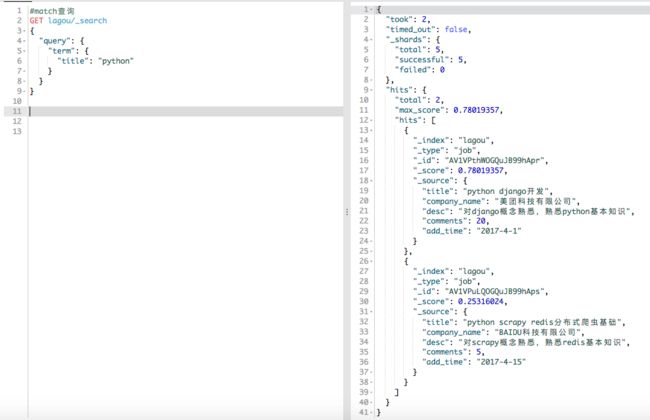

terms查询:将对一组关键字进行查询,如下图:
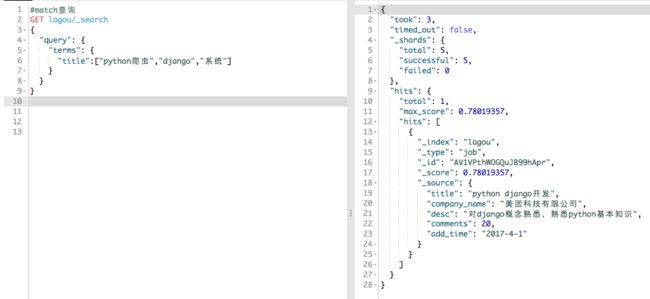
_search操作还有两个参数from和size分别表示从第from条数据开始,返回size条数据。
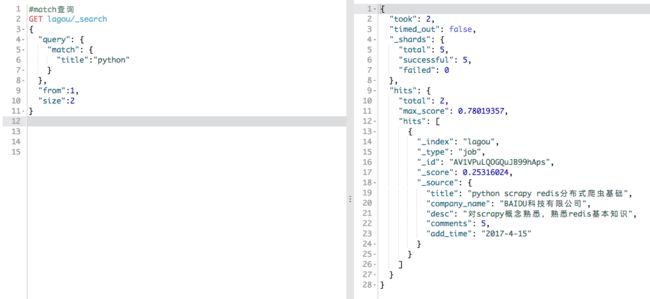
也可以这样写,返回所以数据
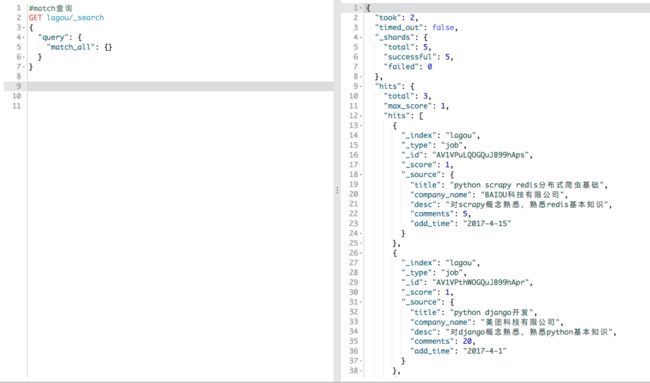
短语查询:
会将被查询对象进行分词作为一个数据,然后查找满足这个数组中所有关键词的字段。
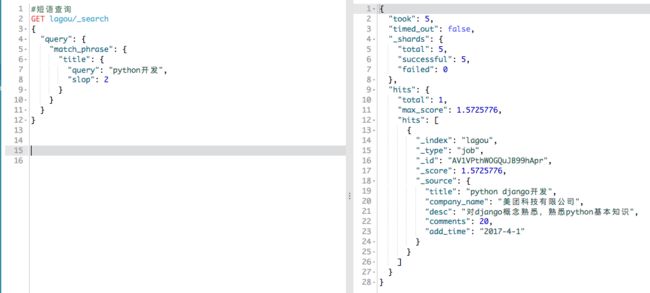
slop的值表示分词之间的最大距离
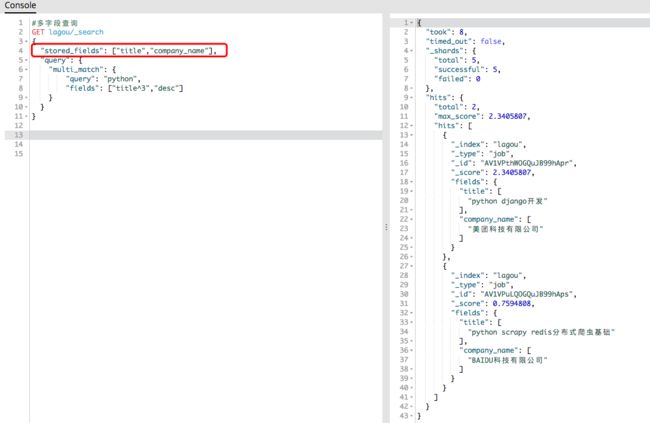
多字段查询
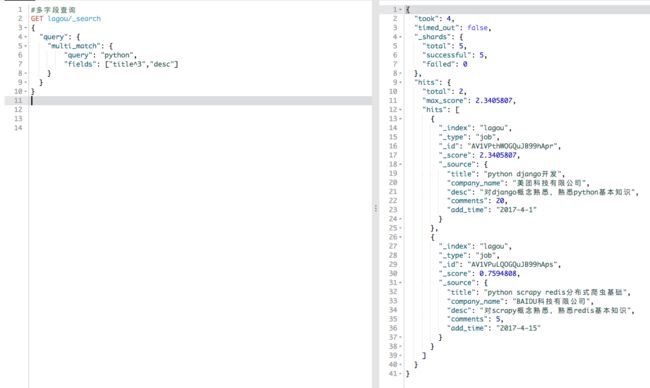
一些属性
store_field
我们还可以设置store_field,限定只返回哪些字段里store属性设置为true的字段
sort
如图表示对“comments”字段表示升序排列,desc换成asc表示降序

range
当然我们也可以设置查询范围,其中gte表示大于等于,lte表示小于等于,gt/lt表示大于/小于,boost表示权重。
组合查询:
bool查询
注意,老版本的filtered已经被bool替换
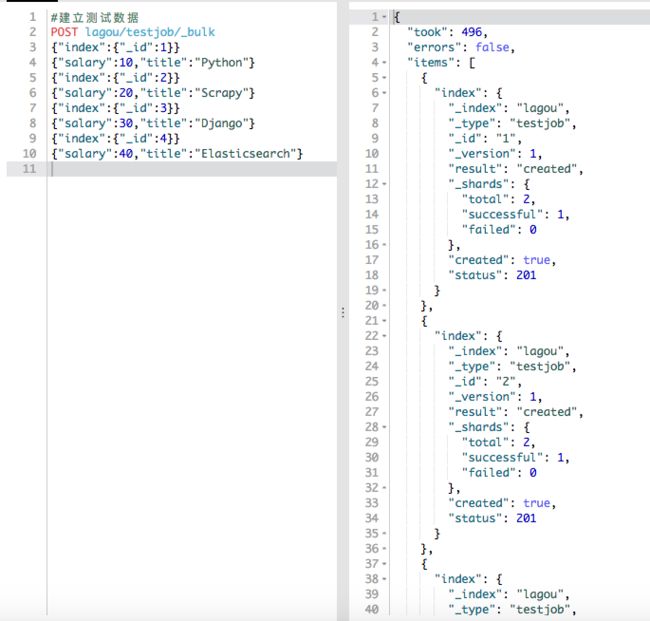
先建立测试数据
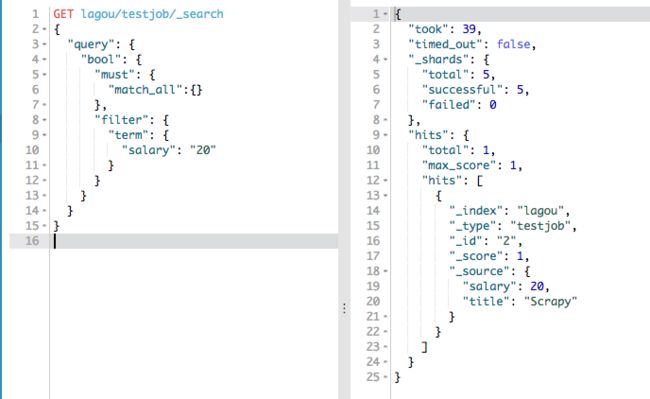
bool接受四种值:must、filter、should、must_not
filter:字段过滤,不参与打分
must:数据里所有查询都必须满足
should:数据里所有查询满足一个就行了
must_not:数据里所有查询都必须不满足
以下查询等价于SQL语句“SELECT * FROM testjob WHERE salary=20”
将scrapy中爬取的数据写入ES
首先安装一个应用:elasticsearch-dsl
>>>pip3 install elasticsearch-dsl
以下是文档中的使用说明

在Scrapy中构建数据模型
在scrapy项目根目录下仿照 django的结构构建一个models文件夹,并在文件夹内创建一个数据模型文件:
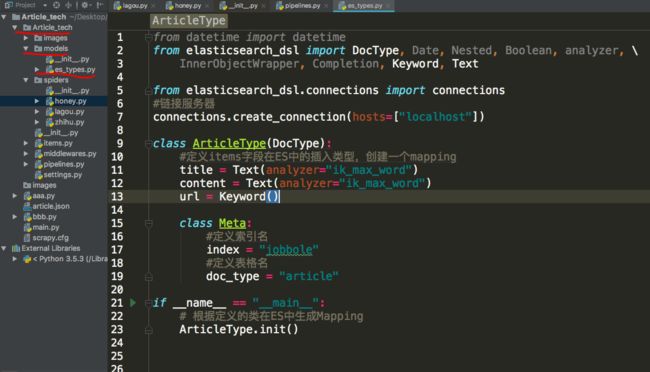

然后我们运行这个脚本,在head页面中就能看到刚创建了一个对应的索引
然后,我们回到scrapy,打开pipeline,写一个将item中数据传入Doctype保存的逻辑
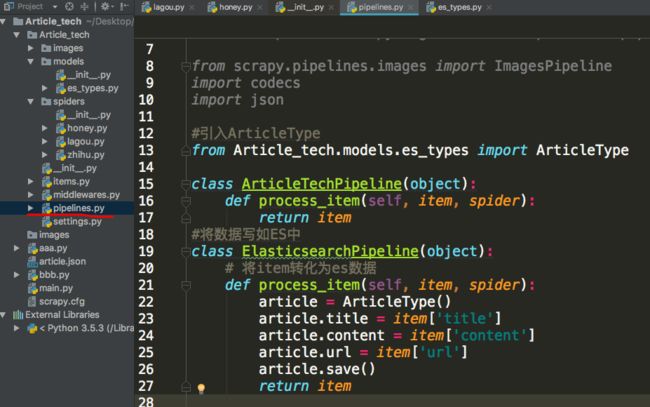
然后在scrapy中执行这个脚本,便能在ES中发现数据。
添加搜索推荐功能:
在需要添加推荐功能的DocType类中添加一个字段,如下所示:

而在items中则需要添加相应的 items搜索建议池