android平台基于卷积神经网络的识别
- 相关理论知识
- 卷积神经网络
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一[][] 。由于卷积神经网络能够进行平移不变分类,因此也被称为“平移不变人工神经网络” [] 。对卷积神经网络的研究始于二十世纪80至90年代,时间延迟网络和LeNet-5是最早出现的卷积神经网络 [] ;在二十一世纪后,随着深度学习理论的提出和数值计算设备的改进,卷积神经网络得到了快速发展,并被大量应用于计算机视觉、自然语言处理等领域 。
卷积神经网络仿造生物的视知觉(visual perception)机制构建,可以进行监督学习和非监督学习,其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的计算量对格点化特征。
一个卷积神经网络包含3部分:
(1:卷积层:卷积神经网络的核心
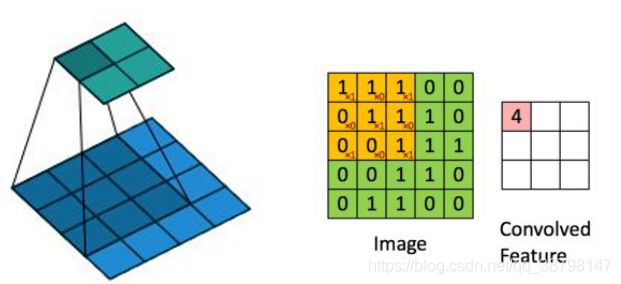
卷积的具体实现,就是拿卷积核去扫描图像。比如卷积核的大小是3*3,与原始图像左上角前三行三列对应位置相乘相加,得到的数作为最终矩阵的第一行第一列。
然后根据步长(假设步长为1),向右移动卷积核,对应原始图像的前三行第2,3,4列相乘相加,得到的数作为最终矩阵的第一行第二列。依次进行扫描得到一个新的矩阵。
一般彩色图像是RGB格式,那么卷积对应三个通道,最终得到三个矩阵。
设输入图像尺寸为w,卷积核尺寸为F,步幅为S,Padding为P,经过卷积之后输出的图像尺寸为(W−F+2P)/S+1。
在卷积层中使用参数共享,这样使得参数大大减少。
另外有几个概念
卷积层的深度:有多少个神经元,深度就是多少;或者说卷积层输出的深度=卷积核的个数
填充值:举个例子
对5*5的图片,卷积核大小是2*2,步长取2,剩下一个没法滑动,那么可以在原先的矩阵上加一层填充值0,变成6*6的矩阵,这样就可以把所有的像素遍历完成。
卷积是为了提取特征,可以看成一个过滤器。比如识别汽车,那么卷积核可能是车轮,做卷积操作以后,符合卷积特征的部分会被放大,而不符合的部分会被缩小。
2:池化层:负责对空间维度进行下采样
一般夹在连续的卷积层中间,用于压缩数据和参数的量,在一定程度上可以减少过拟合。
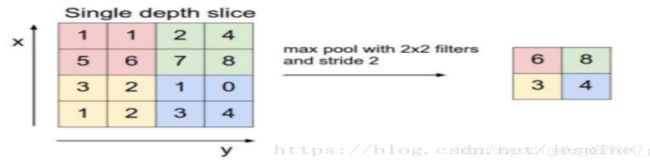
池化的方法一般有:最大池化(max pooling)和平均池化(average pooling)。实际比较常用的是最大池化。
最大池化的思想很简单,选择2*2的过滤器,步长为2。
如图把4*4的图像分割成4个不同的区域,然后对应输出每个区域的最大值。
那么平均池化计算的是区域内的平均值,而不是最大值。
(3:全连接层
通常全连接层在卷积神经网络的尾部,两层之间的所有神经元都有权重连接。
-
- tensorflow框架
TensorFlow基于数据流图,用于大规模分布式数值计算的开源框架。节点表示某种抽象的计算,边表示节点之间相互联系的张量。
-
-
- 计算图
-
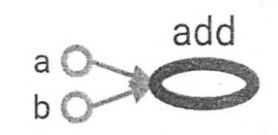
TensorFlow这个名字中Tensor意思是张量,表面TensorFlow的数据结构。Flow是流,表示张量之间通过计算相互转换。TensorFlow是一个通过计算图来表述计算的编程系统。其中每一个计算都是图上的一个节点,节点之间的边描述了的依赖关系。图中a,b,add三个圈代表三个节点,三个计算,其中a和b不依赖与其他的ji节点(计算),而add依赖于a和b的计算
计算图的使用:import tensorflow as tf
a = tf.constant([1.0, 2.0], name="a1") # 常量的创建方法
b = tf.constant([2.0, 3.0], name="b1")
result = a + b
print(a.graph is tf.get_default_graph())
# 通过变量名.graph可以获取变量所在的计算图,get_default_graph()可以获取more你的
-
-
- 张量
-
张量可以简单理解为多维数组,零阶张量表示张量,也就是一个数字,一阶张量表示一个一维向量(数组),n阶向量就表示n维数组。但是张量在TensorFlow中的实现不是采用数组的形式,它只是对TensorFlow中运算结果的引用。张量中不保存数字,值保存如何计算得到这些数字的计算过程,如下列运算:
import tensorflow as tf
a = tf.constant([1.0, 2.0], name='a')
b = tf.constant([2.0, 3.0], name='b')
result = tf.add(a, b, name='add')
print(result)
TensorFlow计算获取的张量只显示名字,维度和类型,不显示数组,只显示结构 。
-
-
- 会话
-
使用会话可以执行定义好的运算,会话拥有并管理TensorFlow运行的时候的所有资源,当所有计算结束之后需要关闭会话来回收资源,否则会有资源泄漏的问题
使用会话模式有两种,下面是第一种:sess = tf.Session() # 创建一个会话
sess.run(result) # 通过会话使用张量,张量是计算过程,等于再次计算
sess.close() # 关闭会话,释放资源
使用这种模式需要明确使用close()来关闭会话,但是程序出现异常的时候不会自动关闭导致资源泄漏,所以一般采用第二种方法。这种方式即使报错也会自动关闭会话:with tf.Session() as
sess: sess.run(result)
- 实验
- 实验平台
(1:硬件平台:联想笔记本,i5-7300hq cpu @ 2.5hz
(2:操作系统:windows
(3:软件工具:pycharm,anaconda,android studio
-
- 实验数据,过程,结果
- 数据的获取
- 实验数据,过程,结果
使用Python爬虫获取图片并下载保存至本地:
(1:分析网页结构
(2:获取当前页的所以图片链接
(3:获取当前页的下一页链接
(4:获取所有页的图片的链接
(5:下载图片
# -*- coding: utf-8 -*-
"""根据搜索词下载百度图片"""
import re
import sys
import urllib
import requests
def get_onepage_urls(onepageurl):
"""获取单个翻页的所有图片的urls+当前翻页的下一翻页的url"""
if not onepageurl:
print('已到最后一页, 结束')
return [], ''
try:
html = requests.get(onepageurl)
html.encoding = 'utf-8'
html = html.text
except Exception as e:
print(e)
pic_urls = []
fanye_url = ''
return pic_urls, fanye_url
pic_urls = re.findall('"objURL":"(.*?)",', html, re.S)
fanye_urls = re.findall(re.compile(r'下一页'), html, flags=0)
fanye_url = 'http://image.baidu.com' + fanye_urls[0] if fanye_urls else ''
return pic_urls, fanye_url
def down_pic(pic_urls):
"""给出图片链接列表, 下载所有图片"""
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i + 1) + '.jpg'
with open(string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
if __name__ == '__main__':
keyword = '天安门' # 关键词, 改为你想输入的词即可, 相当于在百度图片里搜索一样
url_init_first = r'http://image.baidu.com/search/flip?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1497491098685_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&ctd=1497491098685%5E00_1519X735&word='
url_init = url_init_first + urllib.parse.quote(keyword, safe='/')
all_pic_urls = []
onepage_urls, fanye_url = get_onepage_urls(url_init)
all_pic_urls.extend(onepage_urls)
fanye_count = 0 # 累计翻页数
while 1:
onepage_urls, fanye_url = get_onepage_urls(fanye_url)
fanye_count += 1
# print('第页' % str(fanye_count))
if fanye_url == '' and onepage_urls == []:
break
all_pic_urls.extend(onepage_urls)
down_pic(list(set(all_pic_urls)))
-
-
- 迁移学习
-
AlexNet和GoogleNet等深度卷积神经网络模型在图像分类中取得巨大成功,在大型图像数据集ImageNet上获得了充分训练,学习到了图像分类识别所需的大量特征。因此,可以运用迁移学习思想,充分利用AlexNet、GoogleNet等预训练模型在ImageNet数据集上学习到的大量知识,将其用于旅游景点图像分类识别问题。一种常用的迁移学习方法是特征迁移,去掉预训练网络的最后一层,将其之前的激活值(可看作是特征向量)送入支持向量机等分类器进行分类训练:另一种是参数迁移,只需重新初始化网络的少数儿层(如最后一层),其余层直接使用预训练网络的权重数,再利用新的数据集对网络参数进行精调。本文采用特征迁移的迁移学习方式,即前面的层的参数都不变,而只训练最后一层的方法。最后一层是一个softmax分类器,这个分类器在原来的网络上是1000个输出节点(ImageNet有1000个类),所以需要删除网络的最后的一层,变为所需要的输出节点数量,然后再进行训练。
Tensorflow中采用的方法是这样的:将自己的训练集中的每张图像输入网络,最后在瓶颈层(bottleneck),就是倒数第二层,会生成一个2048维度的特征向量,将这个特征保存在一个txt文件中,再用这个特征来训练softmax分类器。

训练的准确率高达0.96
最后生成一个模型和一组标签
-
-
- 移植android
-
(1:bazel编译出so和jar文件:
 、
、

(2:在app里配置环境
把得到的pb文件存放到assets文件夹下
将libandroid_tensorflow_inference_java.jar存放到/app/libs目录下,并且右键“add as Libary”
在/app/libs下新建armeabi文件夹,并将libtensorflow_inference.so放进去
配置app:gradle:

(3在app里添加classifier.java和tensorflowimage.java进行图像识别。