翻译自《Netflix Tech Blog》,原作者Brendan Gregg
Linux Performance Analysis in 60,000 Milliseconds
登陆一台 Linux 服务器排查性能问题:开始一分钟你该检查哪些呢?
在 Netflix 我们有一个庞大的 EC2 Linux集群,也有许多性能分析工具用于监视和检查它们的性能。它们包括用于云监测的Atlas (工具代号) ,用于实例分析的 Vector (工具代号) 。
尽管这些工具能帮助我们解决大部分问题,我们有时也需要登陆一台实例、运行一些标准的 Linux 性能分析工具。
在这篇文章,Netflix 性能工程团队将向您展示:在开始的60秒钟,利用标准的Linux命令行工具,执行一次充分的性能检查。
黄金60秒:概述
运行以下10个命令,你可以在60秒内,获得系统资源利用率和进程运行情况的整体概念。查看是否存在异常、评估饱和度,它们都非常易于理解,可用性强。饱和度表示资源还有多少负荷可以让它处理,并且能够展示请求队列的长度或等待的时间。
uptime
dmesg | tail vmstat 1
mpstat -P ALL 1 pidstat 1
iostat -xz 1 free -m
sar -n DEV 1
sar -n TCP,ETCP 1 top
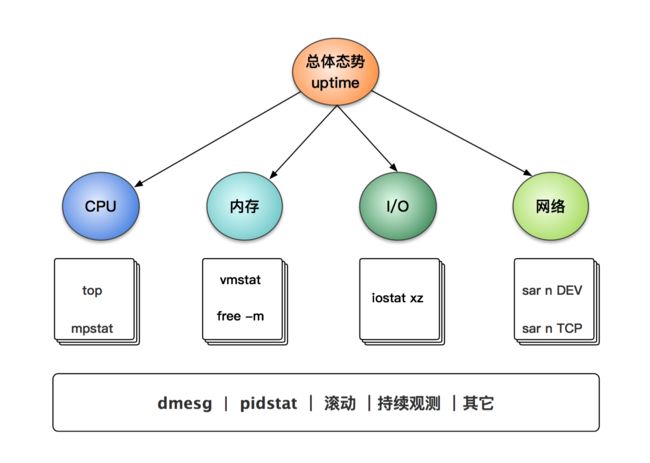
这些命令需要安装sysstat包。
这些命令输出的指标,将帮助你掌握一些有效的方法:一整套寻找性能瓶颈的方法论。这些命令需要检查所有资源的利用率、饱和度和错误信息(CPU、内存、磁盘等)。同时,当你检查或排除一些资源的时候,需要注意在检查过程中,根据指标数据指引,逐步缩小目标范围。
接下来的章节,将结合生产环境的案例演示这些命令。如果希望了解这些工具的详细信息,可以查阅它们的操作文档。
1. uptime
$ uptime
23:51:26up21:31, 1user, loadaverage:30.02,26.43,19.02
这是一个快速查看平均负载的方法,表示等待运行的任务(进程)数量。
在Linux系统中,这些数字包含等待CPU运行的进程数,也包括不间断I/O阻塞的进程数(通常是磁盘I/O)。
它展示了一个资源负载(或需求)的整体概念,但是无法理解其中的内涵,在没有其它工具的情况下。仅仅是一种快速查看手段而已。
这三个数字呈现出平均负载在几何级减弱,依次表示持续1分钟,5分钟和15分钟内。这三个数字能告诉我们负载在时间线上是如何变化的。
举例说明,如果你在一个问题服务器上执行检查,1分钟的值远远低于15分钟的值,可以判断出你也许登录得太晚了,已经错过了问题。
在上面的例子中,平均负载的数值显示最近正在上升,1分钟值高达30,对比15分钟值则是19。这些指标值像现在这么大意味着很多情况:也许是CPU繁忙;vmstat 或者 mpstat 将可以确认,本系列的第三和第四条命令。
2. dmesg | tail
$ dmesg | tail
[1880957.563150] perl invoked oom-killer: gfp_mask=0x280da, order=0, oom_score_adj=0
[...]
[1880957.563400] Out of memory: Kill process 18694 (perl) score 246 or sacrifice child
[1880957.563408] Killed process 18694 (perl) total-vm:1972392kB, anon-rss:1953348kB, file-r
ss:0kB
[2320864.954447] TCP: Possible SYN flooding on port 7001. Dropping request. Check SNMP cou
nters.
这个结果输出了最近10条系统信息。
可以查看到引起性能问题的错误。上面的例子包含了oom-killer,以及TCP丢包。
PS:这个真的很容易忽略啊,真真的踩过坑!! 另外,除了error级的日志,info级的也要留个心眼,可能包含一些隐藏信息。
[译者注:oom-killer]
一层保护机制,用于避免 Linux 在内存不足的时候不至于出太严重的问题,把无关紧要的进程杀掉,有些壮士断腕的意思
3. vmstat 1
$ vmstat 1
procs ---------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
34 0 0 200889792 73708 591828 0 0 0 5 6 10 96 1 3 0 0
32 0 0 200889920 73708 591860 0 0 0 592 13284 4282 98 1 1 0 0
32 0 0 200890112 73708 591860 0 0 0 0 9501 2154 99 1 0 0 0
32 0 0 200889568 73712 591856 0 0 0 48 11900 2459 99 0 0 0 0
32 0 0 200890208 73712 591860 0 0 0 0 15898 4840 98 1 1 0 0
vmstat 是一个获得虚拟内存状态概况的通用工具(最早创建于10年前的BSD)。它每一行记录了关键的服务器统计信息。
vmstat 运行的时候有一个参数1,用于输出一秒钟的概要数据。
第一行输出显示启动之后的平均值,用以替代之前的一秒钟数据。
现在,跳过第一行,让我们来学习并且记住每一列代表的意义。
r:正在CPU上运行或等待运行的进程数。
相对于平均负载来说,这提供了一个更好的、用于查明CPU饱和度的指标,它不包括I/O负载。注: “r”值大于CPU数即是饱和。
free: 空闲内存(kb)
如果这个数值很大,表明你还有足够的内存空闲。
包括命令7“free m”,很好地展现了空闲内存的状态。
si, so: swap入/出。
如果这个值非0,证明内存溢出了。
us, sy, id, wa, st:
它们是CPU分类时间,针对所有CPU的平均访问。
分别是用户时间,系统时间(内核),空闲,I/O等待时间,以及被偷走的时间(其它访客,或者是Xen)。CPU分类时间将可以帮助确认,CPU是否繁忙,通过累计用户系统时间。
等待I/O的情形肯定指向的是磁盘瓶颈;这个时候CPU通常是空闲的,因为任务被阻塞以等待分配磁盘I/O。你可以将等待I/O当作另一种CPU空闲,一种它们为什么空闲的解释线索。
系统时间对I/O处理非常必要。一个很高的平均系统时间,超过20%,值得深入分析:也许是内核处理I/O非常低效。
在上面的例子中,CPU时间几乎完全是用户级的,与应用程序级的利用率正好相反。所有CPU的平均利用率也超过90%。这不一定是一个问题;还需检查“r”列的饱和度。
4. mpstat P ALL 1
$ mpstat -P ALL 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
07:38:49 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
07:38:50 PM all 98.47 0.00 0.75 0.00 0.00 0.00 0.00 0.00 0.00 0.78
07:38:50 PM 0 96.04 0.00 2.97 0.00 0.00 0.00 0.00 0.00 0.00 0.99
07:38:50 PM 1 97.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 2.00
07:38:50 PM 2 98.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00
07:38:50 PM 3 96.97 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3.03
[...]
这个命令可以按时间线打印每个CPU的消耗,常常用于检查不均衡的问题。
如果只有一个繁忙的CPU,可以判断是属于单进程的应用程序。
5. pidstat 1
$ pidstat 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
07:41:02 PM UID PID %usr %system %guest %CPU CPU Command
07:41:03 PM 0 9 0.00 0.94 0.00 0.94 1 rcuos/0
07:41:03 PM 0 4214 5.66 5.66 0.00 11.32 15 mesos-slave
07:41:03 PM 0 4354 0.94 0.94 0.00 1.89 8 java
07:41:03 PM 0 6521 1596.23 1.89 0.00 1598.11 27 java
07:41:03 PM 0 6564 1571.70 7.55 0.00 1579.25 28 java
07:41:03 PM 60004 60154 0.94 4.72 0.00 5.66 9 pidstat
07:41:03 PM UID PID %usr %system %guest %CPU CPU Command
07:41:04 PM 0 4214 6.00 2.00 0.00 8.00 15 mesos-slave
07:41:04 PM 0 6521 1590.00 1.00 0.00 1591.00 27 java
07:41:04 PM 0 6564 1573.00 10.00 0.00 1583.00 28 java
07:41:04 PM 108 6718 1.00 0.00 0.00 1.00 0 snmp-pass
07:41:04 PM 60004 60154 1.00 4.00 0.00 5.00 9 pidstat
^C
pidstat 有一点像顶级视图-针对每一个进程,但是输出的时候滚屏,而不是清屏。
它非常有用,特别是跨时间段查看的模式,也能将你所看到的信息记录下来,以利于进一步的研究。
上面的例子识别出两个 java 进程引起的CPU耗尽。
“%CPU” 是对所有CPU的消耗;1591% 显示 java 进程占用了几乎16个CPU。
6. iostat xz 1
$ iostat -xz 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
73.96 0.00 3.73 0.03 0.06 22.21
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvda 0.00 0.23 0.21 0.18 4.52 2.08 34.37 0.00 9.98 13.80 5.42 2.44 0.09
xvdb 0.01 0.00 1.02 8.94 127.97 598.53 145.79 0.00 0.43 1.78 0.28 0.25 0.25
xvdc 0.01 0.00 1.02 8.86 127.79 595.94 146.50 0.00 0.45 1.82 0.30 0.27 0.26
dm-0 0.00 0.00 0.69 2.32 10.47 31.69 28.01 0.01 3.23 0.71 3.98 0.13 0.04
dm-1 0.00 0.00 0.00 0.94 0.01 3.78 8.00 0.33 345.84 0.04 346.81 0.01 0.00
dm-2 0.00 0.00 0.09 0.07 1.35 0.36 22.50 0.00 2.55 0.23 5.62 1.78 0.03
[...]
这是一个理解块设备(磁盘)极好的工具,不论是负载评估还是作为性能测试成绩。
r/s, w/s, rkB/s, wkB/s: 这些是该设备每秒读%、写%、读Kb、写Kb。可用于描述工作负荷。一个性能问题可能只是简单地由于一个过量的负载引起。
await: I/O平均时间(毫秒)
这是应用程序需要的时间,它包括排队以及运行的时间。
远远大于预期的平均时间可以作为设备饱和,或者设备问题的指标。
avgqusz: 向设备发出的平均请求数。
值大于1可视为饱和(尽管设备能对请求持续运行,特别是前端的虚拟设备-后端有多个磁盘)。
%util: 设备利用率
这是一个实时的繁忙的百分比,显示设备每秒钟正在进行的工作。
值大于60%属于典型的性能不足(可以从await处查看),尽管它取决于设备。
值接近100% 通常指示饱和。
如果存储设备是一个前端逻辑磁盘、后挂一堆磁盘,那么100%的利用率也许意味着,一些已经处理的I/O此时占用100%,然而,后端的磁盘也许远远没有达到饱和,其实可以承担更多的工作。
切记:磁盘I/O性能低并不一定是应用程序问题。许多技术一贯使用异步I/O,所以应用程序并不会阻塞,以及遭受直接的延迟(例如提前加载,缓冲写入)。
7. free m
$ free -m
total used free shared buffers cached
Mem: 245998 24545 221453 83 59 541
-/+ buffers/cache: 23944 222053
Swap: 0 0 0
buffers: buffer cache,用于块设备I/O。
cached:page cache, 用于文件系统。
我们只是想检查这些指标值不为0,那样意味着磁盘I/O高、性能差(确认需要用iostat)。
上面的例子看起来不错,每一个都有很多Mbytes。
“/+ buffers/cache”: 提供了关于内存利用率更加准确的数值。
Linux可以将空闲内存用于缓存,并且在应用程序需要的时候收回。
所以应用到缓存的内存必须以另一种方式包括在内存空闲的数据里面。
甚至有一个网站linux ate my ram,专门探讨这个困惑。
它还有更令人困惑的地方,如果在Linux上使用ZFS,正如我们运行一些服务,ZFS拥有自己的文件系统混存,也不能在free -m 的输出里正确反映。
这种情况会显示系统空闲内存不足,但是内存实际上可用,通过回收 ZFS 的缓存。
8. sar n DEV 1
$ sar -n DEV 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
12:16:48 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
12:16:49 AM eth0 18763.00 5032.00 20686.42 478.30 0.00 0.00 0.00 0.00
12:16:49 AM lo 14.00 14.00 1.36 1.36 0.00 0.00 0.00 0.00
12:16:49 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
12:16:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
12:16:50 AM eth0 19763.00 5101.00 21999.10 482.56 0.00 0.00 0.00 0.00
12:16:50 AM lo 20.00 20.00 3.25 3.25 0.00 0.00 0.00 0.00
12:16:50 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
^C
使用这个工具用来检查网络接口吞吐量:
rxkB/s 和** txkB/s**, 作为负载的一种度量方式, 也可以用来检查是否已经达到某种瓶颈。
在上面的例子中,网卡 eth0 收包大道 22 Mbytes/s, 即176 Mbits/sec (就是说,在 1 Gbit/sec 的限制之内)。
此版本也有一个体现设备利用率的 “%ifutil” (两个方向最大值),我们也可以使用 Brendan的 nicstat 工具来度量。
和 nicstat 类似,这个值很难准确获取,看起来在这个例子中并没有起作用(0.00)。
9. sar n TCP,ETCP 1
$ sar -n TCP,ETCP 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
12:17:19 AM active/s passive/s iseg/s oseg/s
12:17:20 AM 1.00 0.00 10233.00 18846.00
12:17:19 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
12:17:20 AM 0.00 0.00 0.00 0.00 0.00
12:17:20 AM active/s passive/s iseg/s oseg/s
12:17:21 AM 1.00 0.00 8359.00 6039.00
12:17:20 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
12:17:21 AM 0.00 0.00 0.00 0.00 0.00
^C
这是一个关键TCP指标的概览视图。包括:
active/s: 本地初始化的 TCP 连接数 /每秒(例如,通过connect() )
passive/s: 远程初始化的 TCP 连接数/每秒(例如,通过accept() )
retrans/s: TCP重发数/每秒
这些活跃和被动的计数器常常作为一种粗略的服务负载度量方式:新收到的连接数 (被动的),以及下行流量的连接数 (活跃的)。
这也许能帮助我们理解,活跃的都是外向的,被动的都是内向的,但是严格来说这种说法是不准确的(例如,考虑到“本地-本地”的连接)。
重发数是网络或服务器问题的一个标志;它也许是因为不可靠的网络(如,公共互联网),也许是由于一台服务器已经超负荷、发生丢包。
上面的例子显示每秒钟仅有一个新的TCP连接。
10. top
$ top
top - 00:15:40 up 21:56, 1 user, load average: 31.09, 29.87, 29.92
Tasks: 871 total, 1 running, 868 sleeping, 0 stopped, 2 zombie
%Cpu(s): 96.8 us, 0.4 sy, 0.0 ni, 2.7 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 25190241+total, 24921688 used, 22698073+free, 60448 buffers
KiB Swap: 0 total, 0 used, 0 free. 554208 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
20248 root 20 0 0.227t 0.012t 18748 S 3090 5.2 29812:58 java
4213 root 20 0 2722544 64640 44232 S 23.5 0.0 233:35.37 mesos-slave
66128 titancl+ 20 0 24344 2332 1172 R 1.0 0.0 0:00.07 top
5235 root 20 0 38.227g 547004 49996 S 0.7 0.2 2:02.74 java
4299 root 20 0 20.015g 2.682g 16836 S 0.3 1.1 33:14.42 java
1 root 20 0 33620 2920 1496 S 0.0 0.0 0:03.82 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.02 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:05.35 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 0:06.94 kworker/u256:0
8 root 20 0 0 0 0 S 0.0 0.0 2:38.05 rcu_sched
top命令包含了许多我们之前已经检查的指标。
它可以非常方便地运行,看看是否任何东西看起来与从前面的命令的结果完全不同,可以表明负载指标是不断变化的。
顶部下面的输出,很难按照时间推移的模式查看,可能使用如 vmstat 和 pidstat 等工具会更清晰,它们提供滚动输出。
如果你保持输出的动作不够快 (CtrlS 要暂停,CtrlQ 继续),屏幕将清除,间歇性问题的证据也会丢失。
追踪分析
你还可以尝试更多、更深的命令和方法。
详见Brendan的 Linux 性能工具辅导课,包括40多种命令,覆盖可观测性、标杆管理、调优、静态性能优化、监视和追踪。
基于可扩展的web,解决系统的扩展和性能问题,是我们矢志不渝的追求。
如果你希望能够解决这类挑战,加入我们!
Brendan Gregg
以下为原文:
Linux Performance Analysis in 60,000 Milliseconds
You login to a Linux server with a performance issue:
what do you check in the first minute?
At Netflix we have a massive EC2 Linux cloud, and numerous performance analysis tools to monitor and investigate its performance.
These include Atlas for cloudwide monitoring, and Vector for ondemand instance analysis.
While those tools help us solve most issues, we sometimes need to login to an instance and run some standard Linux performance tools.
In this post, the Netflix Performance Engineering team will show you the first 60 seconds of an optimized performance investigation at the command line, using standard Linux tools you should have available.
First 60 Seconds: Summary
In 60 seconds you can get a high level idea of system resource usage and running processes by running the following ten commands.
Look for errors and saturation metrics, as they are both easy to interpret, and then resource utilization.
Saturation is where a resource has more load than it can handle, and can be exposed either as the length of a request queue, or time spent waiting.
uptime
dmesg | tail vmstat 1
mpstat -P ALL 1 pidstat 1
iostat -xz 1 free -m
sar -n DEV 1
sar -n TCP,ETCP 1 top
Some of these commands require the sysstat package installed.
The metrics these commands expose will help you complete some of the USE Method: a methodology for locating performance bottlenecks.
This involves checking utilization, saturation, and error metrics for all resources (CPUs, memory, disks, e.t.c.).
Also pay attention to when you have checked and exonerated a resource, as by process of elimination this narrows the targets to study, and directs any follow on investigation.
The following sections summarize these commands, with examples from a production system. For more information about these tools, see their man pages.
1. uptime
$ uptime
23:51:26up21:31, 1user, loadaverage:30.02,26.43,19.02
This is a quick way to view the load averages, which indicate the number of tasks (processes) wanting to run. On Linux systems, these numbers include processes wanting to run on CPU, as well as processes blocked in uninterruptible I/O (usually disk I/O).
This gives a high level idea of resource load (or demand), but can’t be properly understood without other tools.
Worth a quick look only.
The three numbers are exponentially damped moving sum averages with a 1 minute, 5 minute, and 15 minute constant.
The three numbers give us some idea of how load is changing over time.
For example, if you’ve been asked to check a problem server, and the 1 minute value is much lower than the 15 minute value, then you might have logged in too late and missed the issue.
In the example above, the load averages show a recent increase, hitting 30 for the 1 minute value, compared to 19 for the 15 minute value.
That the numbers are this large means a lot of something: probably CPU demand; vmstat or mpstat will confirm, which are commands 3 and 4 in this sequence.
2. dmesg | tail
$ dmesg | tail
[1880957.563150] perl invoked oom-killer: gfp_mask=0x280da, order=0, oom_score_adj=0
[...]
[1880957.563400] Out of memory: Kill process 18694 (perl) score 246 or sacrifice child
[1880957.563408] Killed process 18694 (perl) total-vm:1972392kB, anon-rss:1953348kB, file-r
ss:0kB
[2320864.954447] TCP: Possible SYN flooding on port 7001. Dropping request. Check SNMP cou
nters.
This views the last 10 system messages, if there are any.
Look for errors that can cause performance issues.
The example above includes the oomkiller, and TCP dropping a request.
Don’t miss this step! dmesg is always worth checking.
3. vmstat 1
$ vmstat 1
procs ---------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
34 0 0 200889792 73708 591828 0 0 0 5 6 10 96 1 3 0 0
32 0 0 200889920 73708 591860 0 0 0 592 13284 4282 98 1 1 0 0
32 0 0 200890112 73708 591860 0 0 0 0 9501 2154 99 1 0 0 0
32 0 0 200889568 73712 591856 0 0 0 48 11900 2459 99 0 0 0 0
32 0 0 200890208 73712 591860 0 0 0 0 15898 4840 98 1 1 0 0
Short for virtual memory stat, vmstat(8) is a commonly available tool (first created for BSD decades ago).
It prints a summary of key server statistics on each line.
vmstat was run with an argument of 1, to print one second summaries.
The first line of output (in this version of vmstat) has some columns that show the average since boot, instead of the previous second.
For now, skip the first line, unless you want to learn and remember which column is which. Columns to check:
r:
Number of processes running on CPU and waiting for a turn.
This provides a better signal than load averages for determining CPU saturation, as it does not include I/O.
To interpret: an “r” value greater than the CPU count is saturation.
free: Free memory in kilobytes.
If there are too many digits to count, you have enough free memory.
The “free m” command, included as command 7, better explains the state of free memory.
si, so:
Swapins and swapouts. If these are nonzero, you’re out of memory.
us, sy, id, wa, st:
These are breakdowns of CPU time, on average across all CPUs.
They are user time, system time (kernel), idle, wait I/O,
and stolen time (by other guests, or with Xen, the guest's own isolated driver domain).
The CPU time breakdowns will confirm if the CPUs are busy, by adding user + system time.
A constant degree of wait I/O points to a disk bottleneck;
this is where the CPUs are idle, because tasks are blocked waiting for pending disk I/O. You can treat wait I/O as another form of CPU idle, one that gives a clue as to why they are idle.
System time is necessary for I/O processing.
A high system time average, over 20%, can be interesting to explore further: perhaps the kernel is processing the I/O inefficiently.
In the above example, CPU time is almost entirely in userlevel, pointing to application level usage instead.
The CPUs are also well over 90% utilized on average.
This isn’t necessarily a problem; check for the degree of saturation using the “r” column.
4. mpstat P ALL 1
$ mpstat -P ALL 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
07:38:49 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
07:38:50 PM all 98.47 0.00 0.75 0.00 0.00 0.00 0.00 0.00 0.00 0.78
07:38:50 PM 0 96.04 0.00 2.97 0.00 0.00 0.00 0.00 0.00 0.00 0.99
07:38:50 PM 1 97.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 2.00
07:38:50 PM 2 98.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00
07:38:50 PM 3 96.97 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3.03
[...]
This command prints CPU time breakdowns per CPU, which can be used to check for an imbalance.
A single hot CPU can be evidence of a singlethreaded application.
5. pidstat 1
$ pidstat 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
07:41:02 PM UID PID %usr %system %guest %CPU CPU Command
07:41:03 PM 0 9 0.00 0.94 0.00 0.94 1 rcuos/0
07:41:03 PM 0 4214 5.66 5.66 0.00 11.32 15 mesos-slave
07:41:03 PM 0 4354 0.94 0.94 0.00 1.89 8 java
07:41:03 PM 0 6521 1596.23 1.89 0.00 1598.11 27 java
07:41:03 PM 0 6564 1571.70 7.55 0.00 1579.25 28 java
07:41:03 PM 60004 60154 0.94 4.72 0.00 5.66 9 pidstat
07:41:03 PM UID PID %usr %system %guest %CPU CPU Command
07:41:04 PM 0 4214 6.00 2.00 0.00 8.00 15 mesos-slave
07:41:04 PM 0 6521 1590.00 1.00 0.00 1591.00 27 java
07:41:04 PM 0 6564 1573.00 10.00 0.00 1583.00 28 java
07:41:04 PM 108 6718 1.00 0.00 0.00 1.00 0 snmp-pass
07:41:04 PM 60004 60154 1.00 4.00 0.00 5.00 9 pidstat
^C
Pidstat is a little like top’s perprocess summary, but prints a rolling summary instead of clearing the screen.
This can be useful for watching patterns over time, and also recording what you saw (copynpaste) into a record of your investigation.
The above example identifies two java processes as responsible for consuming CPU.
The %CPU column is the total across all CPUs; 1591% shows that that java processes is consuming almost 16 CPUs.
6. iostat xz 1
$ iostat -xz 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
73.96 0.00 3.73 0.03 0.06 22.21
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvda 0.00 0.23 0.21 0.18 4.52 2.08 34.37 0.00 9.98 13.80 5.42 2.44 0.09
xvdb 0.01 0.00 1.02 8.94 127.97 598.53 145.79 0.00 0.43 1.78 0.28 0.25 0.25
xvdc 0.01 0.00 1.02 8.86 127.79 595.94 146.50 0.00 0.45 1.82 0.30 0.27 0.26
dm-0 0.00 0.00 0.69 2.32 10.47 31.69 28.01 0.01 3.23 0.71 3.98 0.13 0.04
dm-1 0.00 0.00 0.00 0.94 0.01 3.78 8.00 0.33 345.84 0.04 346.81 0.01 0.00
dm-2 0.00 0.00 0.09 0.07 1.35 0.36 22.50 0.00 2.55 0.23 5.62 1.78 0.03
[...]
This is a great tool for understanding block devices (disks), both the workload applied and the resulting performance.
Look for:
r/s, w/s, rkB/s, wkB/s:
These are the delivered reads, writes, read Kbytes, and write Kbytes per second to the device.
Use these for workload characterization.
A performance problem may simply be due to an excessive load applied.
await:
The average time for the I/O in milliseconds.
This is the time that the application suffers, as it includes both time queued and time being serviced. Larger than expected average times can be an indicator of device saturation, or device problems.
avgqusz:
The average number of requests issued to the device. Values greater than 1 can be evidence of saturation (although devices can typically operate on requests in parallel, especially virtual devices which front multiple backend disks.)
%util:
Device utilization.
This is really a busy percent, showing the time each second that the device was doing work. Values greater than 60% typically lead to poor performance (which should be seen in await), although it depends on the device.
Values close to 100% usually indicate saturation.
If the storage device is a logical disk device fronting many backend disks, then 100% utilization may just mean that some I/O is being processed 100% of the time, however, the backend disks may be far from saturated, and may be able to handle much more work.
Bear in mind that poor performing disk I/O isn’t necessarily an application issue.
Many techniques are typically used to perform I/O asynchronously, so that the application doesn’t block and suffer the latency directly (e.g., readahead for reads, and buffering for writes).
7. free m
$ free -m
total used free shared buffers cached
Mem: 245998 24545 221453 83 -/+ buffers/cache: 23944 222053
Swap: 0 0 0
The right two columns show:
buffers: For the buffer cache, used for block device I/O.
cached: For the page cache, used by file systems.
We just want to check that these aren’t nearzero in size, which can lead to higher disk I/O (confirm using iostat), and worse performance. The above example looks fine, with many Mbytes in each.
The “/+ buffers/cache” provides less confusing values for used and free memory. Linux uses free memory for the caches, but can reclaim it quickly if applications need it. So in a way the cached memory should be included in the free memory column, which this line does. There’s even a website, linuxatemyram, about this confusion.
It can be additionally confusing if ZFS on Linux is used, as we do for some services, as ZFS has its own file system cache that isn’t reflected properly by the free m columns. It can appear that the system is low on free memory, when that memory is in fact available for use from the ZFS cache as needed.
8. sar n DEV 1
$ sar -n DEV 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
12:16:48 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
12:16:49 AM eth0 18763.00 5032.00 20686.42 478.30 0.00 0.00 0.00 0.00
12:16:49 AM lo 14.00 14.00 1.36 1.36 0.00 0.00 0.00 0.00
12:16:49 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
12:16:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
12:16:50 AM eth0 19763.00 5101.00 21999.10 482.56 0.00 0.00 0.00 0.00
12:16:50 AM lo 20.00 20.00 3.25 3.25 0.00 0.00 0.00 0.00
12:16:50 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
^C
Use this tool to check network interface throughput:
rxkB/s and txkB/s, as a measure of workload, and also to check if any limit has been reached.
In the above example, eth0 receive is reaching 22 Mbytes/s, which is 176 Mbits/sec (well under, say, a 1 Gbit/sec limit).
This version also has %ifutil for device utilization (max of both directions for full duplex), which is something we also use Brendan’s nicstat tool to measure. And like with nicstat, this is hard to get right, and seems to not be working in this example (0.00).
9. sar n TCP,ETCP 1
$ sar -n TCP,ETCP 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
12:17:19 AM active/s passive/s iseg/s oseg/s
12:17:20 AM 1.00 0.00 10233.00 18846.00
12:17:19 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
12:17:20 AM 0.00 0.00 0.00 0.00 0.00
12:17:20 AM active/s passive/s iseg/s oseg/s
12:17:21 AM 1.00 0.00 8359.00 6039.00
12:17:20 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
12:17:21 AM 0.00 0.00 0.00 0.00 0.00
^C
active/s: Number of locallyinitiated TCP connections per second (e.g., via connect()).
passive/s: Number of remotelyinitiated TCP connections per second (e.g., via accept()).
retrans/s: Number of TCP retransmits per second.
The active and passive counts are often useful as a rough measure of server load: number of new accepted connections (passive), and number of downstream connections (active).
It might help to think of active as outbound, and passive as inbound, but this isn’t strictly true (e.g., consider a localhost to localhost connection).
Retransmits are a sign of a network or server issue; it may be an unreliable network (e.g., the public Internet), or it may be due a server being overloaded and dropping packets. The example above shows just one new TCP connection persecond.
10. top
$ top
top - 00:15:40 up 21:56, 1 user, load average: 31.09, 29.87, 29.92
Tasks: 871 total, 1 running, 868 sleeping, 0 stopped, 2 zombie
%Cpu(s): 96.8 us, 0.4 sy, 0.0 ni, 2.7 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 25190241+total, 24921688 used, 22698073+free, 60448 buffers
KiB Swap: 0 total, 0 used, 0 free. 554208 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
20248 root 20 0 0.227t 0.012t 18748 S 3090 5.2 29812:58 java
4213 root 20 0 2722544 64640 44232 S 23.5 0.0 233:35.37 mesos-slave
66128 titancl+ 20 0 24344 2332 1172 R 1.0 0.0 0:00.07 top
5235 root 20 0 38.227g 547004 49996 S 0.7 0.2 2:02.74 java
4299 root 20 0 20.015g 2.682g 16836 S 0.3 1.1 33:14.42 java
1 root 20 0 33620 2920 1496 S 0.0 0.0 0:03.82 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.02 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:05.35 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 0:06.94 kworker/u256:0
8 root 20 0 0 0 0 S 0.0 0.0 2:38.05 rcu_sched
The top command includes many of the metrics we checked earlier.
It can be handy to run it to see if anything looks wildly different from the earlier commands, which would indicate that load is variable.
A downside to top is that it is harder to see patterns over time, which may be more clear in tools like vmstat and pidstat, which provide rolling output.
Evidence of intermittent issues can also be lost if you don’t pause the output quick enough (CtrlS to pause, CtrlQ to continue), and the screen clears.
Followon Analysis
There are many more commands and methodologies you can apply to drill deeper.
See Brendan’s Linux Performance Tools tutorial from Velocity 2015, which works through over 40 commands, covering observability, benchmarking, tuning, static performance tuning, profiling, and tracing.
Tackling system reliability and performance problems at web scale is one of our passions.
If you would like to join us in tackling these kinds of challenges we are hiring!
Posted by Brendan Gregg