重点讲解hadoop搭建步骤及常见问题和相应解决方法。
一、搭建环境
Ubuntu 12.10,java环境,hadoop 1.0.3
二、安装Java JDK
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html(建议下载最新版)
我下载的为jdk-7u25-linux-x64.tar.gz压缩包,此外还可能有.bin安装格式
在shell终端下进入jdk-7u25-linux-x64.tar.gz文件所在目录
复制文件到/usr/lib/jvm(若无jvm文件请自行创建)
cp jdk-7u25-linux-x64.tar.gz /usr/lib/jvm
解压文件即可
tar xzvf jdk-7u25-linux-x64.tar.gz
若为.bin格式,例如jdk-6u30-linux-i586.bin文件,安装步骤如下
同样复制JDK到安装目录/usr/lib/jvm,安装文件
./jdk-6u30-linux-i586.bin
安装完成后,文件jvm下面会有jdk1.7.0_25文件夹。
现在要配置Java环境,需要修改/etc/profile文件
用文本编辑器打开proflie文件
在profile文件末尾加入:
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_25
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/hadoop-1.0.3
export PATH=$JAVA_HOME/bin:$PATH
事实上一个问题就是大家安装的JDK,hadoop版本,安装路径可能都不完全一样,那么不一样时该如何修改上面的路径呢
解释一下这几个环境变量,应该就能自行修改了
1. PATH环境变量。作用是指定命令搜索路径,在shell下面执行命令时,它会到PATH变量所指定的路径中查找看是否能找到相应的命令程序。我们需要把 jdk安装目录下的bin目录增加到现有的PATH变量中,bin目录中包含经常要用到的可执行文件如javac/java/javadoc等待,设置好 PATH变量后,就可以在任何目录下执行javac/java等工具了
2. CLASSPATH环境变量。作用是指定类搜索路径,要使用已经编写好的类,前提当然是能够找到它们了,JVM就是通过CLASSPTH来寻找类的。我们 需要把jdk安装目录下的lib子目录中的dt.jar和tools.jar设置到CLASSPATH中,当然,当前目录“.”也必须加入到该变量中
3. JAVA_HOME环境变量。它指向jdk的安装目录,Eclipse/NetBeans/Tomcat等软件就是通过搜索JAVA_HOME变量来找到并使用安装好的jdk
令更新的profile文件生效
source /etc/profile
配置完成后测试一下JDK
java -version
从图中可以看到 java ersion “1.7.0_25” 即安装成功

三、安装SSH
网上很多教程说安装SSH非常之简单,这是对于没有出现问题的人而言的,那么当安装时报错怎么办,下面一步步讲解
首先将一下原理
使用一种被称为"公私钥"认证的方式来进行ssh登录. "公私钥"认证方式简单的解释是
首先在客户端上创建一对公私钥 (公钥文件:~/.ssh/id_rsa.pub; 私钥文件:~/.ssh/id_rsa)
然后把公钥放到服务器上(~/.ssh/authorized_keys), 自己保留好私钥
当ssh登录时,ssh程序会发送私钥去和服务器上的公钥做匹配.如果匹配成功就可以登录了
原理很简单,那么来安装ssh
sudo apt-get install openssh-server
如果正常安装,下面启动它
/etc/init.d/ssh start
验证一下是否启动成功
ps -e | grep ssh
出现下面界面说明没有问题

由于hadoop集群需要使用ssh免密钥登陆,下面来设置免密钥化
ssh-keygen -t rsa -P ""cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
测试SSH登录是否成功
ssh localhost
出现下面的图说明你真是一个幸运的好孩子

但是,如果你在安装SSH时出错了怎么办?没有关系,我现在就来拯救你。
楼主本人就属于出错这种,遇到 connection refused,而且还折腾了一下午,尝试了基本上所有方法,甚至打算重装系统...
如果安装时出错了,即install ssh发现安装失败时
• 方法一
sudo apt-get update
更新的快慢取决于你的网速了,如果中途因为时间过长您中断了更新(Ctrl+z),当您再次更新时,会更新不了,报错为:“Ubuntu无法锁定管理目录(/var/lib/dpkg/),是否有其他进程占用它?“需要如下操作
sudo rm /var/lib/dpkg/lock
sudo rm /var/cache/apt/archives/lock
操作完成后继续执行下面的命令即可
sudo apt-get install openssh-server
• 方法二
如果你和你的小伙伴用了上面的方法还是安装失败的话,可以试试下面的方法
既然无法正确安装,说明可能你已经安装了SSH,但安装出了问题,那么我们就应该卸载掉错误的版本,重新安装正确的版本
打开你很少会用的Ubuntu软件中心吧,搜索SSH

把这个家伙卸载掉,然后重新安装或者修复即可。
• 方法三(慎用)
如果你还是失败了,呵呵,喜闻乐见啊,不过没有关系,还有一个偏方给你
sudo gedit /etc/apt/sources.list
这一步打开了你的源文件(建议修改前先备份),从网上找你ubuntu对应版本的源吧,替换掉当前的源
保存后update一下,然后尝试install openssh
四、hadoop配置
下载Hadoop稳定的发行版本。下载地址http://hadoop.apache.org/common/releases.html
下载好后最好解压在主文件夹下
Hadoop可以在单节点上以所谓的伪分布式模式运行,此时每一个Hadoop守护进程都作为一个独立的Java进程运行。
• 修改hadoop配置文件
用文本编辑器打开conf/hadoop-env.sh文件,找到下面的地方,把JAVA_HOME后面的路径修改为你自己JDK安装路径

core-site.xml
hadoop.tmp.dir /home/alex_young/tmp A base for other temporary directories. fs.default.name hdfs://localhost:9000
localhost为你到本机名,9000为设定接口,只要不冲突即可。
hdfs-site.xml
dfs.name.dir /home/alex_young/hadoop-1.0.3/hdfs/name dfs.data.dir /home/alex_young/hadoop-1.0.3/hdfs/data dfs.replication 1
重要的是value设置为1,data和name不必需,但路径要正确。
mapred-site.xml
mapred.job.tracker localhost:9001 mapred.local.dir /home/alex_young/hadoop-1.0.3/mapred/local mapred.system.dir /home/alex_young/hadoop-1.0.3/mapred/system
如对以上上个xml文件修改不明白,可访问http://blog.csdn.net/yangjl38/article/details/7583374参考
• 配置主机名
打开conf/masters文件,添加作为secondarynamenode的主机名,作为单机版环境,这里只需填写localhost就OK了
打开conf/slaves文件,添加作为slave的主机名,一行一个。作为单机版,这里也只需填写localhost就OK了
PS. 每当ubuntu安装成功时,我们的机器名都默认为:ubuntu,但为了以后集群中能够容易分辨各台服务器,需要给每台机器取个不同的名字。机器名由 /etc/hostname文件决定,打开/etc/hostname文件
sudo gedit /etc/hostname
回车后就打开/etc/hostname文件了,将/etc/hostname文件中的ubuntu改为你想取的机器名。重启系统后才会生效
五、在单机上运行hadoop
进入hadoop目录下,格式化hdfs文件系统,初次运行hadoop时一定要有该操作
![]()
启动bin/start-all.sh,输入命令jps
如果有Namenode,SecondaryNameNode,TaskTracker,DataNode,JobTracker五个进程,就说明你的hadoop单机版环境配置好了。
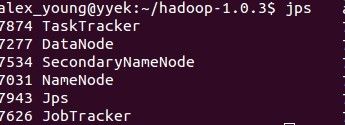
幸福来的太不容易了...
PS.如果你start-all.sh后发现缺少进程,请查看日志,并认真检查三个xml文件是否设置正确