决策树以及加强版的随机森林、GTB决策树练习,数据集是网上下载的“泰坦尼克号乘客资料”。
#-*- coding:utf-8 -*-
#-------导入数据
import pandas as pd
titanic=pd.read_csv('h://123.txt')
#print(titanic.head())
#print(titanic.info())
X=titanic[['pclass','age','sex']]
y=titanic['survived']
#print(X.info())
#---------数据预处理
a=X['age'].mean()
print(a)
X['age'].fillna(a,inplace=True)
print(X.info())
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33)
from sklearn.feature_extraction import DictVectorizer
vec=DictVectorizer(sparse=False)
X_train=vec.fit_transform(X_train.to_dict(orient='record'))
X_test=vec. transform(X_test.to_dict(orient='record'))
#print(vec.feature_names_)
#-------调用决策树模型
from sklearn.tree import DecisionTreeClassifier
dtc=DecisionTreeClassifier()
dtc.fit(X_train,y_train)
y_predict_dtc=dtc.predict(X_test)
#--------调用随机森林模型
from sklearn.ensemble import RandomForestClassifier
rfc=RandomForestClassifier()
rfc.fit(X_train,y_train)
y_predict_rfc=rfc.predict(X_test)
#-------调用GBT决策树模型
from sklearn.ensemble import GradientBoostingClassifier
gbc=GradientBoostingClassifier()
gbc.fit(X_train,y_train)
y_predict_gbc=gbc.predict(X_test)
#-------性能分析
from sklearn.metrics import classification_report
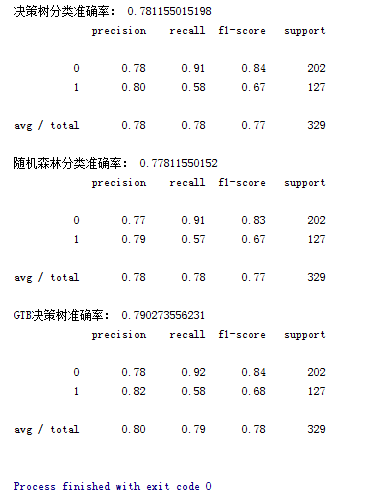
print('决策树分类准确率:',dtc.score(X_test,y_test))
print(classification_report(y_test,y_predict_dtc))
print('随机森林分类准确率:',rfc.score(X_test,y_test))
print(classification_report(y_test,y_predict_rfc))
print('GTB决策树准确率:',gbc.score(X_test,y_test))
print(classification_report(y_test,y_predict_gbc))
结果如下:GTB决策树最好,随机森林最差(。。。无语)。