2021-03-14~15~16 大数据课程笔记 day53day54day55

@R星校长
1. 大数据集群搭建及管理问题
- 提出问题:
需要搭建1000台服务器的集群,其中集群包含Hive、Hbase、Flume、Kafka、Spark等集群,需要多长时间搭建好? - 思考:
搭建四台集群与搭建1000台集群的区别?比较相似。 - 解决问题:(以搭建HDFS为例)
1. 集群环境规划:
首先我们需要进行集群基础环境的规划:比如每台节点的网络ip规划,节点时间同步,每台节点的名称,每台节点安装jdk,节点之间配置免密等。
其次需要进行Hadoop的集群规划:比如搭建HDFS的版本,搭建的HDFS模式,搭建单机模式?还是完全分布式模式?还是HA的完全分布式模式?搭建HDFS是否需要依赖?比如zookeeper。
最后对节点进行规划:比如那些节点搭建zookeeper?那些节点搭建Hadoop集群等。
2. 实际搭建步骤:
基础环境的搭建。
搭建zookeeper集群。
搭建HDFS集群。
- 存在的问题:
- 各个大数据技术包的下载。升级复杂。
- 配置文件多节点之间分发。部署过程复杂。
- 大数据技术各个版本的匹配兼容。版本对应混乱,兼容性差。
- 集群使用状态、日志查看麻烦。去节点查看详细内容,安全性差。
2. CDH简介
- CDH简介:
目前Hadoop发行版非常多,除了原生的Apache Hadoop外,还有Cloudera发行版(CDH)、Hortonworks发行版[2018年与Cloudera公司已经合并],MapR的MapR产品、AWS[Amazon Web Services]的EMR[Elastic MapReduce]等。目前市场份额占比最高的是前三家。所有这些发行版都是基于Apache Hadoop衍生出来的,之所以有这么多版本,是由于Apache Hadoop的开源协议决定的:任何人可以对其进行修改,并作为开源或者商业产品发布或者销售。
Apache Hadoop 版本: 最原始的版本,所有的发行版都是基本这个版本改进,也称为社区版Hadoop。
Cloudera版本:Cloudera’s Distribution Including Apache Hadoop ,简称CDH。
Hortonworks版本:Hortonworks Data Platform ,简称“HDP”。
对于国内的用户来说,CDH版本使用最多。CDH基于Web的用户界面,支持大多数Hadoop的组件,包括:HDFS、MapReduce、Hive、Hbase、Zookeeper等组件,并且简化了大数据平台的安装和使用,使集群方便管理。
Cloudera 的CDH和Apache原生的Hadoop的区别如下:
- CDH对版本的划分非常清晰,CDH共有6个版本,前三个版本已经不再更新,目前更新的两个版本为CDH5和CDH6,CDH4基于Hadoop2.0,CDH5基于Hadoop2.2-2.6,CDH6基于Hadoop3.0,而原生的Apache Hadoop版本比较多,CDH相比原生Apache Hadoop做到版本统一管理。
- CDH相比原生Hadoop 在兼容性、安全性、稳定性上有较大改善,对Hadoop一些bug进行了修复,支持Kerberos安全认证,更新速度快且CDH文档完善清晰。
- CDH支持yum包,rpm包,tar包,Cloudera Manager几种方式安装,原生的Apache Hadoop只支持tar包安装。
- 提供了部署、安装、配置工具,大大提高了集群部署的效率,可以在短时间内部署好集群。
- 运维简单,提供了管理、监控、诊断、配置修改工具,管理配置方便,定位问题快速,准确,使运维工作简单高效。
- CDH集成组件
CDH集成了数据整合、存储、计算、搜索、分析等大数据相关技术组件,如下图: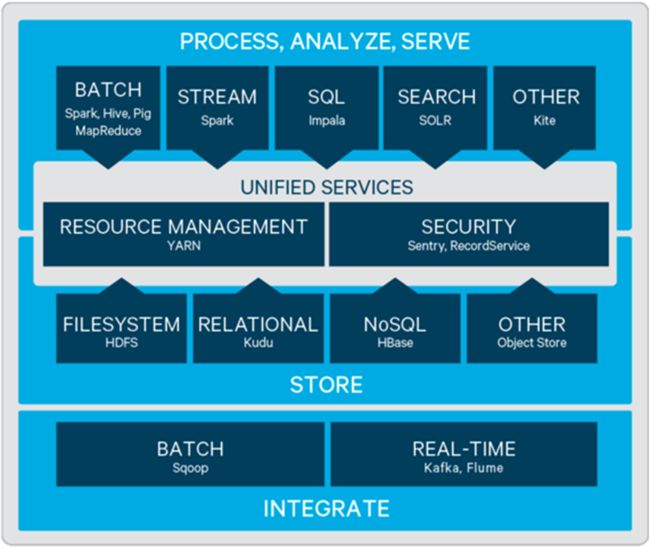
CDH中文官网:https://cn.cloudera.com/
CDH英文官网:https://www.cloudera.com
CDH官方文档:
https://www.cloudera.com/documentation/enterprise/latest.html - CDH 界面:

- CDH 架构:
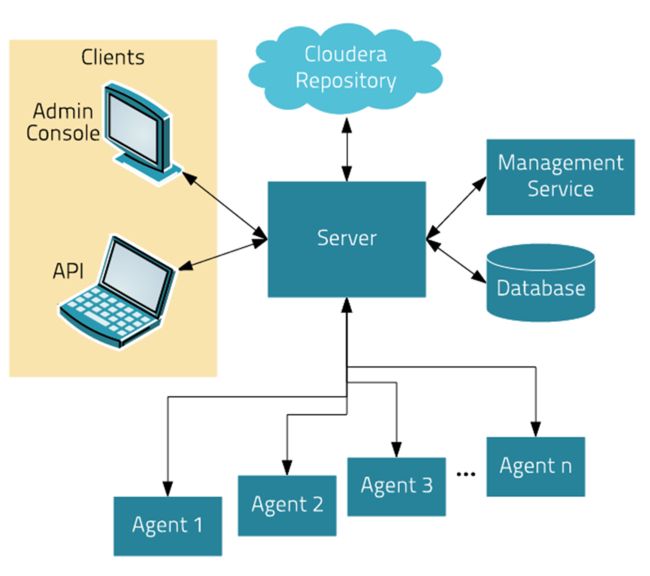
Server: Cloudera Manager 的核心是 Cloudera Manager Server ,Server 管理控制台服务和托管应用程序逻辑,负责软件的安装、配置、服务的启动与关闭及管理集群。
Agent: 安装在每台主机上。Agent 负责进程的启动和停止,解压配置,触发安装及监控主机。
Management Service: 由一组角色组成的服务,这些角色执行各种监视,警报和报告功能。
DataBase: 存储配置及监控信息。
ClouderaRepository:Cloudera Manager 分发软件的存储库。
Clients: 与Server交互的接口,有两部分,Admin Console : 管理员 web 界面版。Api: 用于开发者创建Cloudera Manager程序。
3. Cloudera Manager安装
- 系统环境准备,安装基础环境。
1. 选择三台已经安装 Centos7 Liunx 系统的节点,分配资源。
ClouderManager6.3.x 版本支持的系统如下:
安装 CDH 节点推荐内存为 64G,大部分内存被 Cloudera Management Service 占用,因为做了大量的数据分析和整合。这里,划分三台节点如下:
| 节点名称 | 节点ip | 节点角色 | 分配内存 |
|---|---|---|---|
| cm1 | 192.168.179.201 | Server,Agent | 16G |
| cm2 | 192.168.179.202 | Agent | 4G |
| cm3 | 192.168.179.203 | Agent | 4G |
针对目前学习来说:
如果实际的物理机器内存为32G,推荐cm Server内存为16G,cm Agent内存分别为4G。
如果实际的物理机器内存为16G,推荐cm Server内存为10G,cm Agent内存分别为2G。
如果实际的物理机器内存为12G,推荐cm Server内存为8G,cm Agent内存分别为2G。
如果实际的物理机器内存为8G,推荐cm Server内存为6G,cm Agent内存分别为2G。
注意:后两种情况,实际机器内存不足,需要在VM虚拟机中设置允许交换内存。设置方式如下:
在VMware中点击“编辑”->“首选项”,找到内存,预留内存是给当前真实物理机预留的内存量。在额外内存中,如果实际物理机内存不足10G就设置“允许交换大部分虚拟机内存”,设置这个的意思是当虚拟机内存不足时,可以允许内存与磁盘交换数据,从而获取更多的内存执行当前运行的程序。
截止到这里,以上只是准备好的三台划分好内存和核心的空节点。
注意:实际物理机器安装Vmware的磁盘至少还要预留50G磁盘空间,这里建议给每台虚拟机200G磁盘。
2. 配置ip
在每台节点上配置 ip,打开 /etc/sysconfig/network-scripts/ifcfg-ens33 编辑内容如下,这里的 ifcfg-ensxx 名称不定:
1. TYPE=Ethernet
2. BOOTPROTO=static #使用static配置
3. DEFROUTE=yes
4. PEERDNS=yes
5. PEERROUTES=yes
6. IPV4_FAILURE_FATAL=no
7. IPV6INIT=yes
8. IPV6_AUTOCONF=yes
9. IPV6_DEFROUTE=yes
10. IPV6_PEERDNS=yes
11. IPV6_PEERROUTES=yes
12. IPV6_FAILURE_FATAL=no
13. NAME=ens33
14. UUID=17b5d8c8-5d5d-4c3b-a75c-6fe7200e0bcb
15. DEVICE=ens33
16. ONBOOT=yes #开机启动此配置
17. IPADDR=192.168.179.201 #静态IP
18. GATEWAY=192.168.179.2 #默认网关
19. NETMASK=255.255.255.0 #子网掩码
20. DNS1=192.168.179.2 #DNS配置
重启网络服务使ip生效:
1. #重启网络服务 centos6 : service network restart
2. systemctl restart network
3.
4. #查看ip centos6 : ifconfig
5. ip addr
三台节点配置的 ip 分别为:
192.168.179.201,192.168.179.202,192.168.179.203
注意:每台节点克隆后需要删除每台节点/etc/udev/rules.d/70-persistent-net.rules 文件,清除 mac 地址。重启每台节点即可。
3. 配置每台节点的hostname
修改每台节点 /etc/hostname 文件 (centos6:/etc/sysconfig/network),每台节点直接覆盖写上对应的 hostname 即可,分别为:cm1,cm2,cm3。设置好每台节点的 hostname 之后重启每台节点即可生效。
1. vi /etc/hostname
2. cm3 #hostname文件中只需配置这一行
3.
4. 配置节点ip、hostname映射
在每台节点/etc/hosts文件后追加如下内容,配置ip与hostname之间的映射。
1. 192.168.179.201 cm1
2. 192.168.179.202 cm2
3. 192.168.179.203 cm3
5. 关闭防火墙
在每台节点上执行如下命令,关闭防火墙,并设置开机不启动:
1. #检查防火墙状态:centos6 : service iptables status
2. firewall-cmd --state
3.
4. #关闭防火墙,centos6 : service iptables stop
5. systemctl stop firewalld
6.
7. #设置开机不启动防火墙: centos6 :chkconfig iptables off
8. systemctl disable firewalld
9.
10. #检查防火墙开机启动状态:
11. systemctl list-unit-files | grep firewall
12.
13. #检查机器中的启动服务: centos6 : chkconfig --list
14. systemctl list-unit-files
6. 关闭SELinux
SELinux就是Security-Enhanced Linux的简称,安全加强的linux。传统的linux权限是对文件和目录的owner, group和other的rwx进行控制,而SELinux采用的是委任式访问控制,也就是控制一个进程对具体文件系统上面的文件和目录的访问,SELinux规定了很多的规则,来决定哪个进程可以访问哪些文件和目录。虽然SELinux很好用,但是在多数情况我们还是将其关闭,因为在不了解其机制的情况下使用SELinux会导致软件安装或者应用部署失败。
在每台节点/etc/selinux/config中将SELINUX=enforcing改成SELINUX=disabled即可。
7. 配置本地yum源
这里我们选择使用本地yum源。需要在VM中设置下连接光驱,步骤如下图。
在cm1、cm2、cm3节点上配置本地yum源:
每台节点创建/mnt/cdrom目录:
1. mkdir -p /mnt/cdrom
每台节点执行如下命令,将光盘设备/dev/sr0挂载到/mnt/cdrom目录:
1. mount /dev/sr0 /mnt/cdrom/
2. mount: block device /dev/sr0 is write-protected, mounting read-only
每台节点执行命令:df -h查看是否挂载成功:
1. df -h
上面的mount命令挂载后在机器重启后会失效,为了可以实现开机自动挂载,可以在每台节点的/etc/fstab文件的最后面加入下面语句:
1. /dev/sr0 /mnt/cdrom iso9660 defaults 0 0
下面可以创建本地yum源,在每台节点的/etc/yum.repos.d目录下创建local.repo文件,内容如下:
1. [local]
2. name=local repo
3. baseurl=file:///mnt/cdrom
4. enable=1
5. gpgcheck=1
6. gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
以上内容中,在centos6 中需要配置gpgkey内容如下: gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6。baseurl是指Yum源的地址,该路径下有个repodata目录,就是yum 安装源目录。file://表示yum源为文件。
如果只想让local.repo生效,可以在每台节点的/etc/yum.repos.d目录下创建一个backup目录,将其他的以“.repo”结尾的文件都移动到backup目录中。
1. mkdir -p /etc/yum.repos.d/backup
2. mv /etc/yum.repos.d/CentOS-* /etc/yum.repos.d/backup/
在每台节点上执行以下命令,更新yum源:
1. yum clean all
2. yum makecache
8. 配置SSH免秘钥登录
在CDH中需要任意两个节点之间都可以免秘钥登录。节点两两免秘钥的根本原理如下:假设A节点需要免秘钥登录B节点,只要B节点上有A节点的公钥,那么A节点就可以免密登录当前B节点。
第一,需要在每台节点上安装ssh客户端,否则,不能使用ssh命令(最小化安装Liunx,默认没有安装ssh客户端),这里在Centos7系统中默认已经安装,此步骤可以省略:
1. yum -y install openssh-clients
第二,在每台节点执行如下命令,在每台节点的“~”目录下,创建.ssh目录,注意,不要手动创建这个目录,因为有权限问题。
1. cd ~
2. ssh localhost
3. #这里会需要输入节点密码#
4. exit
第三,在每台节点上执行如下命令,给当前节点创建公钥和私钥:
1. ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
第四,将cm1,cm2,cm3的公钥copy到cm1上,这样,cm1,cm2,cm3节点都能登录cm1节点。命令如下:
1. 在cm1上执行如下命令,需要输入密码:
2. [root@cm1 .ssh]# ssh-copy-id cm1 #会在当前~/.ssh目录下生成authorized_keys文件,文件中存放当前cm1的公钥#
3. 在cm2上执行如下命令,需要输入密码:
4. [root@cm2 ~]# ssh-copy-id cm1 #会将cm2的公钥追加到cm1节点的authorized_keys文件中#
5. 在cm3上执行如下命令,需要输入密码:
6. [root@cm3 ~]# ssh-copy-id cm1 #会将cm3的公钥追加到cm1节点的authorized_keys文件中#
最后,将 cm1 节点上~/.ssh/authorized_keys拷贝到 cm2 和 cm3 节点的~/.ssh/目录下,执行如下命令:
1. 在cm1上执行如下命令,需要输入密码:
2. [root@cm1 .ssh]# scp ~/.ssh/authorized_keys cm2:`pwd`
3. [root@cm1 .ssh]# scp ~/.ssh/authorized_keys cm3:`pwd`
经过以上步骤,节点两两免密完成。
9. 节点同步时间
在 cm1 , cm2 , cm3 每 台节点上执行如下命令,安装 ntp 服务及配置定时任务:
1. yum -y install ntp #安装ntp服务#
2. rm -rf /etc/localtime #删除现有时区#
3. ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime #修改上海时区#
4. /usr/sbin/ntpdate -u pool.ntp.org #同步时间#
5. date #查看时间#
6. #crontab -e 写入如下定时内容:#
7. */10 * * * * /usr/sbin/ntpdate -u pool.ntp.org >/dev/null 2>&1 #同步时间定时任务#
8. systemctl restart crond #重启定时任务 ,centos6:service crond restart#
9. crontab -l #查看定时任务#
10.
11. systemctl enable ntpd #设置ntpd 开机启动,不然后期安装CDH时会有警告。centos6:chkconfig ntpd on
12. systemctl start ntpd #启动ntpd服务 service ntpd start
10. 安装 jdk
给每台节点安装jdk,这里我们安装的CDH版本为6.3.2,在官网:
https://docs.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_java_requirements.html#java_requirements
描述中这里需要使用 jdk8,但是对应的 jdk 小版本有要求,具体如下:
这里我们选择jdk8版本中的1.8u181版本安装。在每台节点安装jdk,在每台节点中创建/software目录,将jdk8安装包通过ftp工具上传到/software目录下,每台节点执行如下命令安装jdk:
1. [root@cm1 ~]# mkdir -p /software
2. [root@cm1 ~]# rpm -ivh /software/jdk-8u181-linux-x64.rpm
以上命令执行完成之后,会在每台节点的/usr/java下安装jdk。在每台节点配置jdk的环境变量:
1. vim /etc/profile
2. #在每台节点中配置profile文件,在最后追加内容如下:#
3. export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64
4. export PATH=$JAVA_HOME/bin:$PATH
5. export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
执行完成以上命令之后,在每台节点上执行 “source /etc/profile”使配置生效。
11. 安装 mysql 数据库
在cm1中安装mysql数据库,在Centos6中安装mysql可以直接执行命令:
yum install –y mysql-server
但是在Centos7中yum源中没有自带mysql的安装包,需要执行命令下载mysql 的rpm配置文件,然后进行repo的安装,安装repo后在/etc/yum.repos.d路径下会有对应的mysql repo配置,然后再安装mysql,这里安装的mysql是5.7版本。命令如下:
1. #下载mysql repo,下载完成后会在当前执行命令目录下生成 rpm -ivh mysql57-community-release-el7-9.noarch.rpm文件。
2. [root@cm1 ~]# wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
3.
4. #安装repo,安装完成后再/etc/yum.repos.d 目录下会生成mysql的 repo文件
5. [root@cm1 ~]# rpm -ivh mysql57-community-release-el7-9.noarch.rpm
6.
7. #安装mysql
8. [root@cm1 ~]# yum install mysql-server -y
执行完成之后,启动mysql:systemctl start mysqld,也可以使用service mysqld start启动msyql。
mysql5.7开始初始登录mysql需要使用初始密码,启动后登录mysql需要指定安装时的临时密码,使用命令:grep ‘temporary password’ /var/log/mysqld.log 获取临时密码后,执行如下语句:
1. #使用临时密码登录mysql
2. [root@cm1 log]# mysql -u root -pK-BJt9jV0jb0
3.
4. #默认mysql密码需要含有数字、大小写字符、下划线等,这里设置密码验证级别为低即可
5. mysql> set global validate_password_policy=LOW;
6.
7. #默认mysql密码设置长度是8位,这里修改成6位
8. mysql> set global validate_password_length=6;
9.
10. #初始登录mysql必须重置密码才能操作,这里先修改密码为 123456
11. mysql> alter user 'root'@'localhost' identified by '123456';
也可以删除usr表中的数据,重新设置下mysql root密码也可以,命令如下:
1. [root@cm1 java]# mysql -u root -p123456
2. mysql> use mysql;
3. mysql> select user,authentication_string from user;
4. mysql> delete from user;
5. mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
6. mysql> flush privileges;
执行如下命令,将mysql设置成开机启动,如果不设置开机启动,后期每次启动ClouderaManager时,需要手动启动MySQL。
1. #设置mysql 开机自动启动
2. [root@cm1 ~]# systemctl enable mysqld
3. [root@cm1 ~]# systemctl list-unit-files |grep mysqld
以上设置密码验证级别和密码长度验证当mysql重启后还需要重复设置,如果mysql中密码设置不想要太复杂或者密码长度不想设置长度验证,可以在“/etc/my.cnf”中配置如下内容:
1. [mysqld]
2. plugin-load=validate_password.so
3. validate-password=off
配置完成后执行“systemctl restart mysqld”,重启mysql即可。
12. 安装第三方依赖包
在每台节点上安装ClouderManager需要的第三方依赖包,每台节点执行如下命令:
1. yum install -y chkconfig bind-utils psmisc cyrus-sasl-plain cyrus-sasl-gssapi portmap /lib/lsb/init-functions httpd mod_ssl openssl-devel python python-psycopg2 MySQL-python libxslt zlib sqlite fuse fuse-libs redhat-lsb
2.
至此,安装Cloudera Manager的基础环境准备完成。
- Cloudera Manager 安装
1. 创建安装目录
在三台节点cm1,cm2,cm3中执行命令“mkdir /opt/cloudera-manager”创建安装目录。
并且将ClouderaManager rpm安装包“cm6.3.1-redhat7.tar.gz”上传至cm1节点的目录“/software”下,并且解压到目录“/opt/cloudera-manager”下,在cm1节点执行命令如下:
1. [root@cm1 software]# tar -zxvf ./cm6.3.1-redhat7.tar.gz -C /opt/cloudera-manager/
2. RPM 安装包分发
在cm1中将以上解压好的安装包分发到其他Agent节点,所有的Agent节点都需要分发,只需要发送cloudera-manager-agent与cloudera-manager-daemons安装包即可。执行如下命令:
1. #将安装包分发到cm2节点
2. [root@cm1 x86_64]# scp /opt/cloudera-manager/cm6.3.1/RPMS/x86_64/cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm cm2:/opt/cloudera-manager/
3. [root@cm1 x86_64]# scp /opt/cloudera-manager/cm6.3.1/RPMS/x86_64/cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm cm2:/opt/cloudera-manager/
4.
5. #将安装包分发到cm3节点
6. [root@cm1 x86_64]# scp /opt/cloudera-manager/cm6.3.1/RPMS/x86_64/cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm cm3:/opt/cloudera-manager/
7. [root@cm1 x86_64]# scp /opt/cloudera-manager/cm6.3.1/RPMS/x86_64/cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm cm3:/opt/cloudera-manager/
3. 在 CM Server 节点安装 CM Server
在cm1节点上安装daemons、servers RPM包,由于安装过程中会检查系统中的依赖包,如果没有会报错,可以安装时指定 --nodeps 不检查依赖关系,命令如下:
1. [root@cm1 ~]# cd /opt/cloudera-manager/cm6.3.1/RPMS/x86_64
2. #后面可以跟上 --nodeps 不检查依赖
3. [root@cm1 x86_64]# rpm -ivh cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm
4. [root@cm1 x86_64]# rpm -ivh cloudera-manager-server-6.3.1-1466458.el7.x86_64.rpm
以上命令执行完成之后,会自动创建目录“/opt/cloudera”,自动将RPM包安装到这个目录下。
4. 在 CM Agent 节点安装 CM Agent
在cm1,cm2,cm3节点上安装daemons、agent RPM包,这里由于已经第3步骤在cm1中已经安装过daemons,不必重复安装,只需要在cm1节点上安装agent RPM安装包即可。
1. #在cm1节点上安装agent 可以指定 --nodeps 不检查依赖
2. [root@cm1 x86_64]# rpm -ivh ./cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm
3.
4. #在cm2、cm3节点上安装 daemons 与agent
5. rpm -ivh ./cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm
6. rpm -ivh ./cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm
当完成安装agent后,会在当前节点生成“/opt/cloudera/cm-agent”目录。
5. 配置CM Agent的server host
在所有的Agent节点上,修改Agent的配置文件“/etc/cloudera-scm-agent/config.ini”,修改“server_host=cm1”,指定所有Agent节点的Server节点为cm1。
6. 配置 CM Server 数据库
在cm1 Server节点上,修改
“/etc/cloudera-scm-server/db.properties”文件,配置内容如下:
1. com.cloudera.cmf.db.type=mysql
2. com.cloudera.cmf.db.host=cm1
3. com.cloudera.cmf.db.name=cmf
4. com.cloudera.cmf.db.user=cmf
5. com.cloudera.cmf.db.password=123456
6. com.cloudera.cmf.db.setupType=EXTERNAL
将“mysql-connector-java-5.1.26-bin.jar”上传至cm1节点的/usr/share/java/目录下,如果没有目录需要先创建目录,并且修改jar包名称为“mysql-connector-java.jar”。
登录mysql数据库,执行如下命令:
1. [root@cm1 ~]# mysql -u root -p123456
2. grant all on *.* to 'cmf'@'%' identified by '123456' with grant option;
3. quit
在CM Server节点cm1上执行如下命令初始化数据库:
1. [root@cm1 ~]# cd /opt/cloudera/cm/schema/
2.
3. #【-u用户,-p密码 ,数据库类型,数据库,用户,密码】
4. [root@cm1 ~]#./scm_prepare_database.sh -ucmf -p123456 mysql cmf cmf 123456
7. 准备 CDH Parcels 本地源
在Server节点cm1上“/opt/cloudera/parcel-repo”目录下,上传如下文件即可。
- “CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel”
- “CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel.sha”
- “manifest.json”
8. 启动 CM Server、Agent
在Server节点启动ClouderaManager Server,分别在Agent节点启动ClouderaManager Agent:
1. # 在cm1 节点上启动 Server 服务
2. [root@cm1 ~]# systemctl start cloudera-scm-server
3. # 在cm1、cm2、cm3 节点上启动 Agent 服务
4. [root@cm1 ~]# systemctl start cloudera-scm-agent
注意:Server启动比较慢,需要等待一会才能访问对应的web界面,可以查看启动日志,Sever启动的日志默认在路径“/var/log/cloudera-scm-server/cloudera-scm-server.log”下。Agent启动的日志默认在路径“/var/log/cloudera-scm-agent/cloudera-scm-agent.log ”下。可以通过以上日志来检查启动中是否有错。
Sever首次启动会自动创建表以及数据,不要立即关闭或重启,否则需要删除所有表及数据重新安装。
至此,Cloudera Manager的安装完成。
4. CDH安装
1. 登录 Cloudera Manager webui 界面
Cloudera Manager的webui界面登录地址为cm1:7180,默认的用户名和密码都是admin。输入完成后,点击登录。
2. 选择安装 CDH 的节点
登录之后,一直选择“继续”即可,

选择Cloudera Express,点击“继续”,弹出页面后继续点击“继续”:
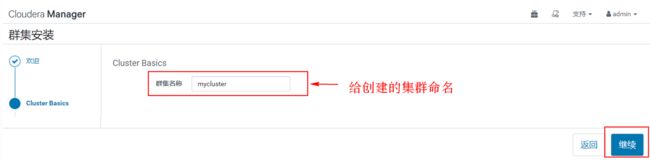
弹出如下页面,该页面是为CDH指定主机,可以使用“模式”通配来选择主机,也可以选择“当前管理的主机”,这里“当前管理的主机”中有节点内容的原因正是由于之前我们在这三台节点配置过agent。如果未来集群增加机器,可以在新主机中搜索添加,后期会自动将agent安装到选中的新节点。
这里我们选择“当前管理的主机”中的所有节点,点击“继续”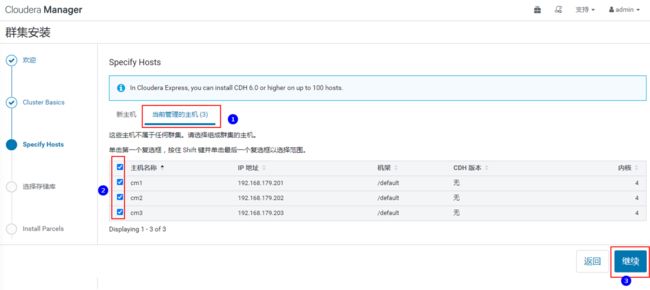
3. 集群安装
选择CDH版本为CDH6.3.2,点击“继续”,如下图: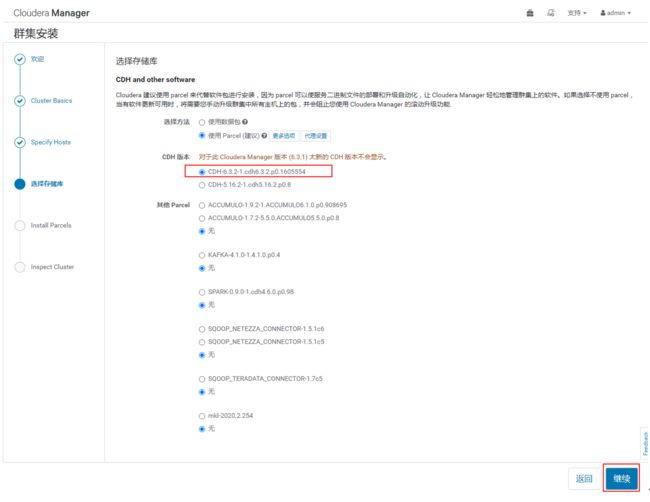
点击“继续”之后,Cloudera Manager主节点会将下载好的CDH分发到各个Agent节点,这时可以在cm1,cm2,cm3节点上看到路径/opt/cloudera/ parcel-cache目录中有Cloudera Manager主节点传过来的CDH安装包,同时在完成传输之后,每个Agent节点还会将CDH安装包解压到/opt/cloudera/parcels路径下,此时,界面显示如下: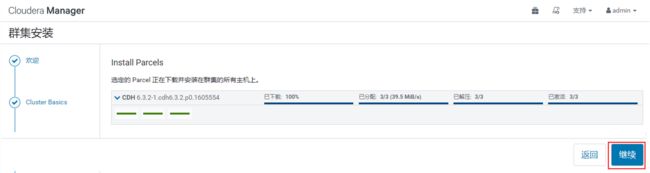
点击“继续”,显示正在检查主机健康状况,稍等片刻,会显示检查结果:

点击检查结果,查看检查主机出现的问题:
这里建议swappiness=10的时候表示最大限度使用物理内存。由于透明超大页面已知会导致意外的节点重新启动,可以在每台节点中执行如下命令,在检查主机正确性后面点击“重新运行”即可解决。命令如下:
1. #在 cm1,cm2,cm3节点上执行如下命令
2. echo 10 > /proc/sys/vm/swappiness
3.
4. echo never > /sys/kernel/mm/transparent_hugepage/defrag
5.
6. echo never > /sys/kernel/mm/transparent_hugepage/enabled
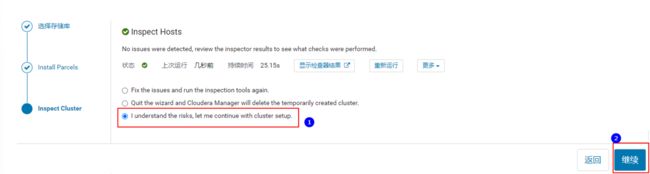
最后,点击“继续”,进入“集群设置”。
4. 集群设置
在进入的集群设置界面中,点击“自定义服务”,选择“HDFS”、“YARN”、“Zookeeper”进行安装,注意:这里提示还会安装Cloudera Management Service ,用于后期的监控、报告、事件和警报。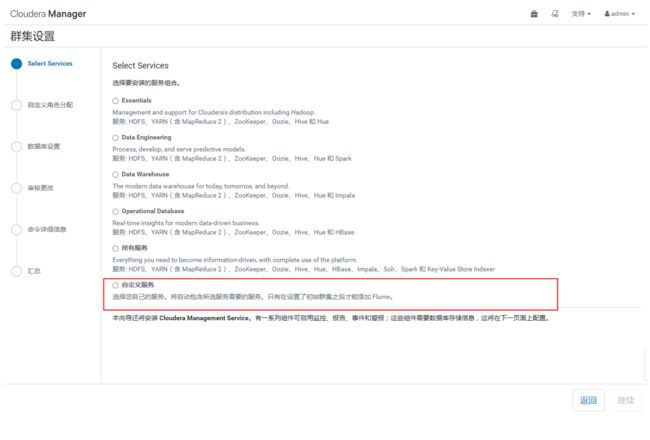
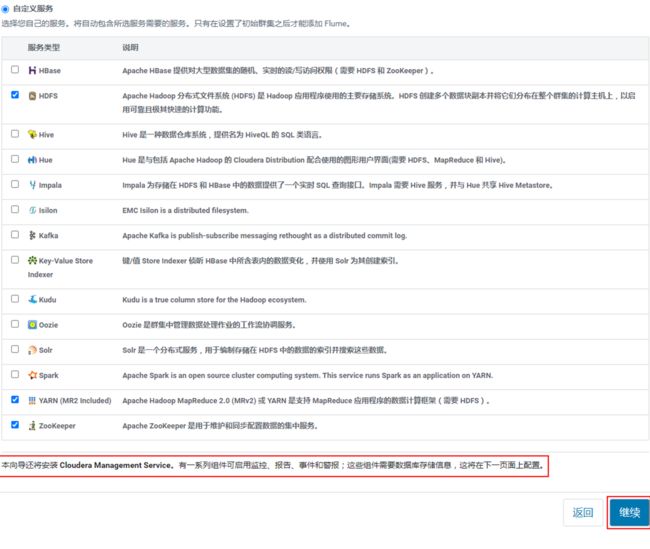
以上点击“继续”,进入“角色分配”页面,显示的是Cloudera Manager自动划分的集群分配,当然这里也可以自己分配节点。如下图所示:
继续点击“继续”,进入“审核更改页面”,在这里可以手动修改一些配置文件,如下图所示:
继续点击“继续”,进入执行集群命令,启动各个组件页面,当所有组件启动完成之后,如下图示: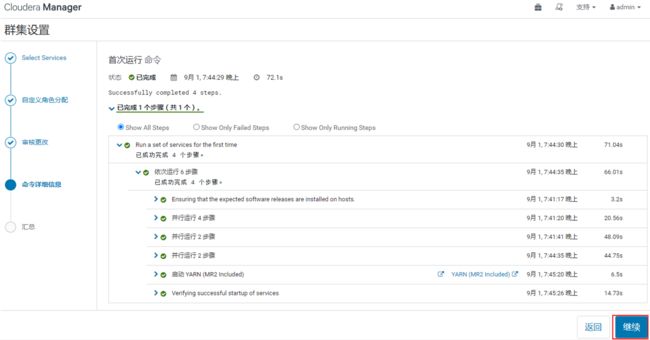
点击“继续”,完成集群设置。
5. CDH 主页面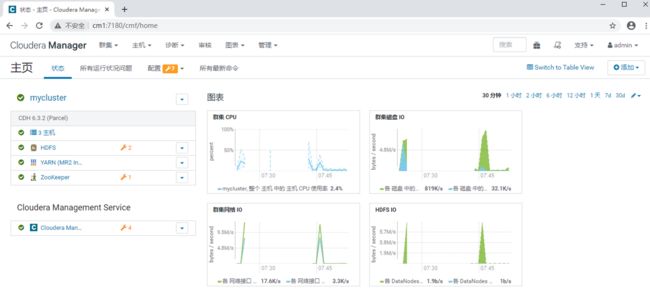
5. ClouderaManager使用
1. ClouderaManager 中的名词术语
主机:host
机架:rack
服务:service
例如:Hadoop、MapReduce、spark
服务实例:service instance
激活的服务就叫服务实例。
角色:role
服务中的角色,例如Yarn中的zookeeper节点,Spark中的Master节点。
角色实例:role instance
分配的角色,就是角色实例。
角色组:role group
主机模板:host template
parcle:
就是CDH的安装包。
静态服务池:static service pool
动态资源池:dynamic resource pool
2. 集群管理
1) 添加、删除集群
2) 启动、停止、重启集群
3) 重命名集群
4) 全体集群配置
5) 移动主机
3. 主机管理
1) 查看主机详细
2) 主机检查
3) 集群添加主机
4) 分配机架
5) 主机模板
6) 维护模式
7) 删除主机
4. 服务管理
1) 添加服务
2) 对比不同集群上的服务配置
3) 启动、停止、重启服务
4) 滚动重启
5) 终止客户端正在执行的命令
6) 删除服务
7) 配置最大进程数
5. 资源管理
1) 动态资源池
2) 静态服务池
6. 用户管理
7. 安全管理
6. 安装Hive
1. 选择集群,添加 Hive 服务

2. 添加服务向导
选择 HDFS,点击“继续”: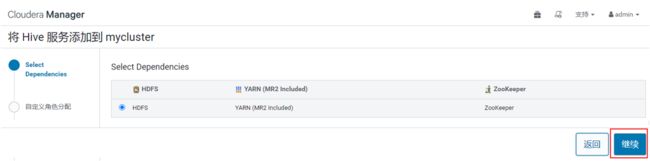
选择默认角色配置即可: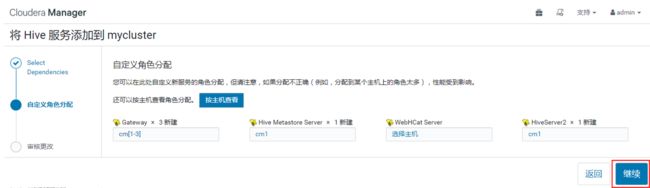
点击“继续”之后,需要配置Hive依赖的mysql数据库,需要在cm1节点上连接mysql,执行创建数据库及分配权限语句:
1. [root@cm1 ~]# mysql -u root -p123456
2. mysql> create database hive DEFAULT CHARACTER SET utf8;
3. mysql> grant all on hive.* TO 'hive'@'%' IDENTIFIED BY 'hive';
4. mysql> flush privileges;
在弹出的页面中选择数据库,填写用户名及密码,点击“测试连接”,测试数据库连接成功后,点击“继续”:
点击继续之后,设置hive的数据目录及端口,默认即可,点击继续之后等待Hive安装完成即可。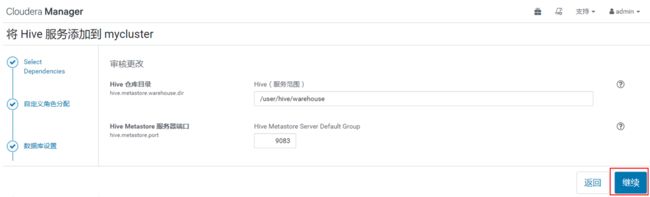
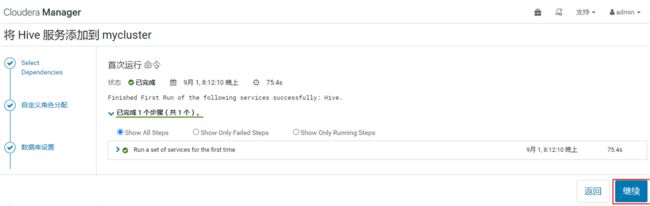
7. oozie的安装
oozie 是一个基于 Hadoop 的工作流引擎,也叫任务调度器,它以 xml 的形式写调度流程,可以调度 mr,pig,hive,shell,jar,spark 等。在工作中如果多个任务之间有依赖执行顺序要求,可以使用 oozie 来进行调度执行。
1. 选择集群,添加 oozie 服务
选择一个集群,搭建添加服务,选择 “oozie”,点击“下一步”。

2. 添加服务向导
选择HDFS
选择节点,分配oozie角色: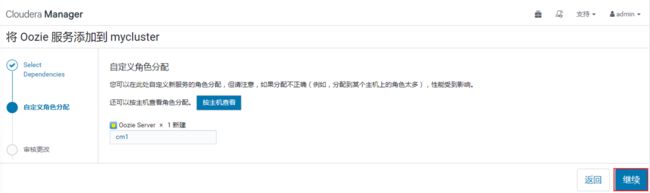
当点击“继续”后,需要给oozie配置数据库,需要在cm1节点上连接mysql,执行创建数据库及分配权限语句:
1. [root@cm1 ~]# mysql -u root -p123456
2. mysql> create database oozie DEFAULT CHARACTER SET utf8;
3. mysql> grant all on oozie.* TO 'oozie'@'%' IDENTIFIED BY 'oozie';
4. mysql> flush privileges;
在弹出的页面中选择数据库,填写用户名及密码,点击“测试连接”,测试数据库连接成功后,点击“继续”:
在弹出的页面中,选择默认oozie使用的数据目录,默认即可,点击“继续”:
等待服务向导完成,点击“继续”->“完成”,完成 oozie 安装。
8. Hue 介绍及安装
HUE是一个开源的Apache Hadoop UI系统,早期由Cloudera开发,它是基于Python Web框架Django实现,后来贡献给开源社区。它包括3个部分hue ui,hue server,hue db。通过使用Hue我们可以通过浏览器方式操纵Hadoop集群,查看修改hdfs的文件,管理hive的元数据,运行Sqoop,编写Oozie工作流等大量工作。Hue的安装可以依赖hive和oozie,所以这里先安装了Hive和oozie。
1. 选择集群,添加服务:
2. 添加服务向导:
选择“hue”服务,点击“继续”:
选择依赖的 HDFS,点击“继续”:
角色按照默认配置即可,点击“继续”,完成hue的安装。
当点击“继续”后,需要给hue配置数据库,需要在cm1节点上连接mysql,执行创建数据库及分配权限语句:
1. [root@cm1 ~]# mysql -u root -p123456
2. mysql> create database hue DEFAULT CHARACTER SET utf8;
3. mysql> grant all on hue.* TO 'hue'@'%' IDENTIFIED BY 'hue';
4. mysql> flush privileges;
在弹出的页面中选择数据库,填写用户名及密码,点击“测试连接”,测试数据库连接成功后,点击“继续”:
等待服务向导完成,点击“继续”->“完成”,完成 hue 安装。
9. Hue 的使用
以上将hue安装在cm1节点上,这里登陆hue时,地址为:http://cm1:8889,首次登陆hue需要登陆hue的账号密码,这里输入user:myhue,password:myhue。最好这里使用hdfs用户。因为hdfs用户可以操作hdfs中的文件,如果使用其他用户只能在当前用户的目录下创建文件。
1. hue 创建用户
点击“管理用户”->“添加用户”可以创建用户,并且可以指定权限,是否在HDFS中创建主目录等。

2. hue操作HDFS文件
可以创建新的文件,也可以修改,最好HDFS中大文件不要在hue中操作。hue中的用户默认是进入当前用户的主目录进行操作。

点击以上”文件”进入到HDFS文件系统,进行创建文件夹或者文件,还可以对文件进行编辑。
3. hue操作hive中的数据
登录hue之后,点击“查询”->“编辑器”->“Hive”,编写sql创建Hive表:
创建完成后,点击hive数据库刷新,可以看到刚才创建的Hive表,创建表完成之后,可以右键表找到“在浏览器中打开”,可以查询、导入、删除表等操作,导入数据时选择的数据可以是HDFS中也可以是本地中的文件数据:
点击“提交”将HDFS中文件数据导入到表中。点击“查询”查询表中的数据,如下:
在 Hive SQL 面板中还可以查询数据,在查询编辑器中执行查询 sql 语句:
执行 sql 语句之后,hql 转换成 MR 作业,可以点击“作业”查看任务:
4. hue 添加 rdbms 数据库
hue也支持RDBMS关系数据库的展示及操作。启动Cloudera Manager 登录Hue之后,在配置中搜索“hue_safety_valve.ini”配置项,配置如下内容,保存更改:
1. [librdbms]
2. [[databases]]
3. [[[mysql]]]
4. nice_name="all mysql databases"
5. engine=mysql
6. host=192.168.179.14
7. port=3306
8. user=root
9. password=123456
10. options={ "init_command":"SET NAMES 'utf8'"}
11.
12. [notebook]
13. [[interpreters]]
14. [[[hive]]]
15. name=Hive
16. [[[mysql]]]
17. name=Mysql
18. interface=rdbms
19. [[[java]]]
20. name=Java
21. interface=oozie
22. [[[spark2]]]
23. name=Spark
24. interface=oozie
25. [[[shell]]]
26. name=Shell
27. interface=oozie
28. [[[sqoop1]]]
29. name=Sqoop1
30. interface=oozie
31. [[[distcp]]]
32. name=Distcp
33. interface=oozie
以上参数中,nice_name指定在hue中显示的连接名称。name指定连接的mysql数据库名称,不指定这个参数,将默认显示全部的数据库。engine指定mysql数据库类型。host指定数据库地址。port指定数据库端口号。user指定连接用户名。password指定密码。options中指定的“init_command”指定数据库编码为utf8,防止有中文时乱码。
此外,在配置“[notebook]”时,可以只需要配置Hive 与Mysql即可。以上配置完成之后,重启hue。重新进入hue webui中,点击“查询”->“编辑器”,可以看到“MySQL”标签,点击在主页右侧“SQL”中也会出现对应的MySQL中的数据库及表信息。
10. impala 介绍及安装
1. impala 简介
impala 由 Cloudera 公司推出,提供对 HDFS、Hbase 数据的高性能、低延迟的交互式SQL查询功能。 基于Hive使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点。是CDH平台首选的PB级大数据实时查询分析引擎。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点就是基于内存处理数据,查询速度快。
Impala与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共同之处,如数据表元数据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。
Impala与Hive在Hadoop中的关系下图所示。Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快速实验、验证想法的大数据分析工具。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。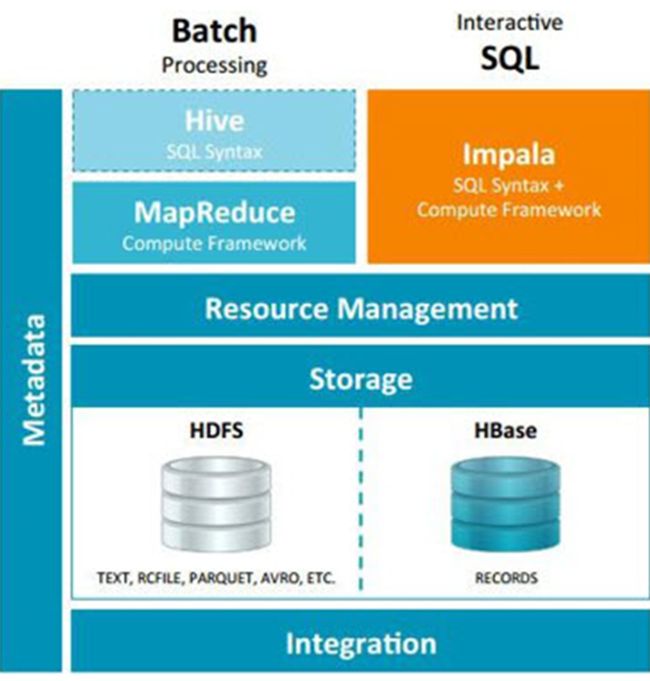
2. Impala 架构

Impala 主要有 Impalad、State Store 、Catlog 和 CLI 组成:
- Impalad:
与DataNode运行在同一节点上,由Impalad进程表示,它接收客户端的查询请求(接收查询请求的Impalad为Coordinator,Coordinator通过JNI[java native interface]调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的其它Impalad进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给Coordinator,由Coordinator返回给客户端。同时Impalad也与State Store保持连接,用于确定哪个Impalad是健康和可以接受新的工作。在Impalad中启动三个ThriftServer: beeswax_server(连接客户端),hs2_server(借用Hive元数据), be_server(Impalad内部使用)和一个ImpalaServer服务。
每个impalad实例会接收、规划并调节来自ODBC或Impala Shell等客户端的查询。每个impalad实例会充当一个Worker,处理由其它impalad实例分发出来的查询片段(query fragments)。客户端可以随便连接到任意一个impalad实例,被连接的impalad实例将充当本次查询的协调者(Ordinator),将查询分发给集群内的其它impalad实例进行并行计算。当所有计算完毕时,其它各个impalad实例将会把各自的计算结果发送给充当 Ordinator的impalad实例,由这个Ordinator实例把结果返回给客户端。每个impalad进程可以处理多个并发请求。
- Imapla State Store:
负责Quary的调度及跟踪集群中的Impalad的健康状态及位置信息,由statestored进程表示,它通过创建多个线程来处理Impalad的注册订阅和与各Impalad保持心跳连接,各Impalad都会缓存一份State Store中的信息,当State Store离线后,因为Impalad有State Store的缓存仍然可以工作,但会因为有些Impalad失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。Impalad发现State Store处于离线时,会进入recovery模式,反复注册,当State Store重新加入集群后,自动恢复正常,更新缓存数据。
- Catalog:
当Impala集群启动后,负责从Hive MetaStore中获取元数据信息,放到impala自己的catalog中。Catalog会与StateStore通信,将原数据信息通过StateStore广播到每个Impalad节点。同时当Impala客户端在某个Impalad中创建表后,Impalad也会将建表的原数据信息通过State Store通知给各个Impalad节点和Catalog,由Catalog同步到Hive的元数据中。
注意Hive中创建表产生的原数据信息,不能同步到catalog中,需要手动执行命令同步。
- CLI(Impala shell):
命令行客户端,提供给用户查询使用的命令行工具。
3. impala 的优势:
1) 基于内存进行计算,能够对PB级数据进行交互式实时查询、分析。
不需要把中间结果写入磁盘,省掉了大量的I/O开销。最大限度的使用内存,中间结果不写磁盘,Impalad之间通过网络以stream的方式传递数据。
2) 无需转换为MR,直接读取HDFS数据。
省掉了MR作业启动的开销,Impala直接通过相应的服务进程来进行作业调度,速度快。
3) C++编写,LLVM统一编译运行。
LLVM是构架编译器(compiler)的框架系统,以C++编写而成,用于优化以任意程序语言编写的程序的编译时间(compile-time)、链接时间(link-time)、运行时间(run-time)以及空闲时间(idle-time)。使用C++实现,做了很多针对性的硬件优化。
4) 兼容HiveSQL,可对Hive数据直接分析。
5) 支持Data Local
Impala支持Data Locality的I/O调度机制,尽可能的将数据和计算分配在同一台机器上执行,减少网络开销。
6) 支持列式存储
7) 支持 JDBC/ODBC 远程访问
4. impala的劣势:
1).对内存的依赖大,要求高
2).完全依赖Hive,不支持Hive的UDF和UDAF函数,不支持查询期的容错。
3).分区超过 1w 性能严重下降
4).稳定性不如 hive
5. Impala 与 Hive 的异同:
相同点:
impala与Hive使用相同的元数据,都支持将数据存储在HDFS和Hbase中,都是对SQL进行词法分析生成执行计划。
不同点:
1) 执行计划:
Hive: 依赖与 MapReduce 执行框架,执行计划分为 map->shuffle->reduce->map->shuffle->reduce… 由于中间有很多次 shuffle,SQL 执行时间长。
Impala: 执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad中执行查询,而不需要转换成MapReduce模式处理,保证impala有更好的并发性和避免不必要的中间sort和shuffle。
2) 数据流
Hive:采用推的方式,每个计算节点计算完成之后将数据主动退给后续节点。
impala:采用拉的方式,后续节点通过getNext主动向前面节点要数据,此方式可以将数据流式的返回给客户端,只要有一条数据处理完成,就可以立即被展示出来,不需要等待全部数据处理完成,更符合sql交互式查询。
3) 内存使用
Hive:在执行过程中如果内存放不下数据,则会使用磁盘,保证SQL能顺序执行完成,每一轮Map-Reduce执行结束后,中间结果也会落地磁盘。
Impala:在遇到内存放不下数据时,就会报错。这使impala处理数据有一定的局限性,最好与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程中不会有写磁盘操作(insert除外)。
4) 调度
Hive:Hive调度依赖于Hadoop的调度策略。
Impala:调度由Impala自己完成,会尽量将处理数据的进程靠近数据本身所在的物理机器。
5) 容错
Hive:依赖于Hadoop的容错能力。
Impala:整体来看,Impala容错一般,用户可以向任意一台impalad提交SQL查询。如果一个Impalad失效,在当前Impala上执行的所有SQL查询将失败,但是用户可以重新提交查询由其他的Impalad代替执行,不影响服务。在查询过程中,没有容错逻辑,如果执行过程中发生故障,则直接返回错误。对于Impala中的State Store目前只有一个,但当State Store失效,也不会影响服务,每个Impalad都缓存了State Store的信息,只是不能在更新集群状态,有可能会把执行任务分配给已经失效的Impalad执行,导致SQL执行失败。
6) 适用方面
Hive:复杂的批处理查询任务,数据转换任务。
Impala:实时数据分析,因为不支持UDF,对处理复杂的问题分析有局限性,与Hive配合使用,对Hive的结果数据集进行实时分析。
6. 安装
1) 选择集群,添加服务
2) 添加服务向导
在弹出的窗口中选择impala,点击“继续”:
角色按照默认配置即可,点击“继续”:
选择impala的数据目录,默认即可,点击“继续”->“完成”,完成impala的安装:

11. impala的使用
在集群主页上,启动impala。
1. 测试 Hive&impala 的速度
首先在cm2中切换hdfs用户,默认ClouderaManager在创建hdfs用户时,禁用了使用hdfs用户进行ssh登录,这里需要执行命令(建议所有节点都执行):
1. # -s 修改用户登入后所使用的shell,/bin/bash可以使用ssh 登录
2. usermod -s /bin/bash hdfs
在cm2节点的xshell上进入hive客户端,在之前hue的使用中,给Hive中插入过表“my_hive_table”,执行sql语句查看在hive中执行速度:
3. [root@cm2 init.d]# su hdfs
4. [hdfs@cm2 init.d]$ hive
5. hive> show tables;
6. OK
7. my_hive_table
8. Time taken: 0.515 seconds, Fetched: 1 row(s)
9. hive> select count(*) from my_hive_table;
10. Query ID = hdfs_20190814201010_cc6c373e-c7a4-4046-8d50-e48e79d02c72
11. Total jobs = 1
12. Launching Job 1 out of 1
13. Number of reduce tasks determined at compile time: 1
14. In order to change the average load for a reducer (in bytes):
15. set hive.exec.reducers.bytes.per.reducer=<number>
16. In order to limit the maximum number of reducers:
17. set hive.exec.reducers.max=<number>
18. In order to set a constant number of reducers:
19. set mapreduce.job.reduces=<number>
20. Starting Job = job_1565783077183_0001, Tracking URL = http://cm1:8088/proxy/application_1565783077183_0001/
21. Kill Command = /opt/cloudera/parcels/CDH-5.4.0-1.cdh5.4.0.p0.27/lib/hadoop/bin/hadoop job -kill job_1565783077183_0001
22. Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
23. 2019-08-14 20:10:28,069 Stage-1 map = 0%, reduce = 0%
24. 2019-08-14 20:10:36,501 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.44 sec
25. 2019-08-14 20:10:41,848 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.01 sec
26. MapReduce Total cumulative CPU time: 4 seconds 10 msec
27. Ended Job = job_1565783077183_0001
28. MapReduce Jobs Launched:
29. Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.01 sec HDFS Read: 6435 HDFS Write: 2 SUCCESS
30. Total MapReduce CPU Time Spent: 4 seconds 10 msec
31. OK
32. 3
33. Time taken: 26.603 seconds, Fetched: 1 row(s)
其次,在cm3节点上执行impala-shell,执行相同的语句查看执行时长:
1. [root@cm3 init.d]# impala-shell
2. [cm3:21000] > show tables;
3. Query: show tables
4. +---------------+
5. | name |
6. +---------------+
7. | my_hive_table |
8. +---------------+
9. Fetched 1 row(s) in 0.21s
10. [cm3:21000] > select count(*) from my_hive_table;
11. Query: select count(*) from my_hive_table
12. +----------+
13. | count(*) |
14. +----------+
15. | 3 |
16. +----------+
17. Fetched 1 row(s) in 0.85s
2. 测试impala创建表同步元数据
在impala中创建一张表,查看是否元数据会同步到Hive的MetaStore,在impala-shell中执行建表语句:
1. [cm3:21000] > create table impala_table (id int,name string,score int) row format delimited fields terminated by '\t';
2. Query: create table impala_table (id int,name string,score int) row format delimited fields terminated by '\t'
3.
4. Fetched 0 row(s) in 0.22s
同时,在cm2节点的Hive客户端查看是否有表“impala_table”,发现在impala中创建的表元数据在Hive中立即可以查询到。
1. hive> show tables;
2. OK
3. impala_table
4. my_hive_table
5. Time taken: 0.016 seconds, Fetched: 2 row(s)
3. 测试 Hive 创建表不同步元数据
在cm2节点,Hive中创建一张表,执行命令如下,在impala中看不到对应的表信息,需要手动更新元数据才可以。
1. hive> create table my_hive_table1 (id int,name string) row format delimited fields terminated by '\t';
2. OK
3. Time taken: 10.224 seconds
在cm3节点查询impala-shell,执行命令如下:
1. [cm3:21000] > show tables;
2. Query: show tables
3. +---------------+
4. | name |
5. +---------------+
6. | impala_table |
7. | my_hive_table |
8. +---------------+
9. Fetched 2 row(s) in 0.11s
如果需要 impala 同步元数据信息,可以在 cm3 中 impala-shell 中执行 “invalidate metadata” 命令:
1. [cm3:21000] > invalidate metadata ;
2. Query: invalidate metadata
3.
4. Fetched 0 row(s) in 3.48s
5. [cm3:21000] > show tables;
6. Query: show tables
7. +----------------+
8. | name |
9. +----------------+
10. | impala_table |
11. | my_hive_table |
12. | my_hive_table1 |
13. +----------------+
14. Fetched 3 row(s) in 0.01s
4. impala Shell 命令
一般命令<进入 impala-shell 使用命令>:
-h(–help)帮助
-v(–version)查询版本信息
-V(–verbose)启用详细输出
显示详细时间,显示执行信息。
--quiet 关闭详细输出
-p 显示执行计划
-i hostname(–impalad=hostname) 指定连接主机
格式hostname:port 默认端口21000
-q query(–query=query)从命令行执行查询,不进入impala-shell
-d default_db(–database=default_db)指定数据库
-B(–delimited)去格式化输出
--output_delimiter=character 指定分隔符,在-B指定情况下使用
将查询结果写往外部文件,或者输出时,指定输出字段间的分隔符号。
例如:impala-shell -f sql.sql -c --print_header --output_delimiter="#"
–print_header 打印列名
将查询结果写往外部文件时可以指定打印列名。
例如:impala-shell -f sql.sql -B -c --print_header
-f query_file(–query_file=query_file)执行查询文件,以分号分隔
-o filename(–output_file filename)结果输出到指定文件
当前就是将1标准输出输出到文件。
-c 查询执行失败时继续执行
举例:impala-shell –B –f xx.sql –c 1>out.txt ,可以将结果输出到文件中,同时有错误直接跳过。
-k(–kerberos) 使用kerberos安全加密方式运行impala-shell
-l 启用LDAP认证
-u 启用LDAP时,指定用户名
特殊用法<在impala-shell中命令>:
- help :在impala-shell中查看帮助
- connect
- refresh
增量刷新元数据库 - invalidate metadata 全量刷新元数据库
- explain
显示查询执行计划、步骤信息 。
例如:explain select * from my_hive_table; - set explain_level 设置显示级别(0,1,2,3) ,默认为1
set explain_level = 3;
explain select * from my_hive_table;
级别越小,内容越精简,级别越大,内容越多。 - shell 不退出impala-shell执行Linux命令
例如:shell cat ./sql.sql; - profile (查询完成后执行) 查询最近一次查询的底层信息 。
5. impala 存储和压缩方式

6. impala SQL
参照ppt。
12. oozie 的使用
Oozie是用于 Hadoop 平台的开源的工作流调度引擎。 用来管理Hadoop作业。 属于web应用程序,由Oozie client和Oozie Server两个组件构成。 Oozie Server是运行于Java Servlet容器(Tomcat)中的web程序。
1. oozie 作用:
- 统一调度hadoop系统中常见的mr任务启动、hdfs操作、shell调度、hive操作等
- 使得复杂的依赖关系、时间触发、事件触发使用xml语言进行表达。
- 一组任务使用一个DAG来表示,使用图形表达流程逻辑更加清晰
- 支持很多种任务调度,能完成大部分hadoop任务处理
- 程序定义支持EL常量和函数,表达更加丰富
2. oozie 中的概念: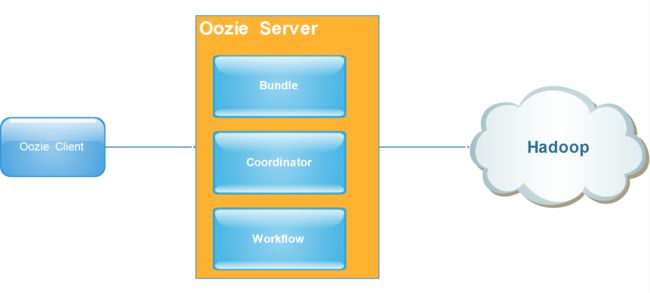
- workflow :工作流 ,顺序执行流程节点,支持fork(分支多个节点),join(合并多个节点为一个)。
- coordinator :多个workflow可以组成一个coordinator,可以把前几个workflow的输出作为后一个workflow的输入,也可以定义workflow的触发条件,来做定时触发。
- bundle:是对一堆coordinator的抽象, 可绑定多个coordinator。
3. oozie web 控制台
1) 将ext-2.2 解压到对应目录
如果使用web控制台,还需要在oozie安装节点cm1上将“ext-2.2”解压到路径“/var/lib/oozie”目录下,首先将“ext-2.2”上传到cm1节点上,在cm1节点上执行如下命令:
1. #安装unzip命令
2. [root@cm1 java]# yum -y install unzip
3. #解压ext到路径 /var/lib/oozie中
4. [root@cm1 ~]# unzip ext-2.2.zip -d /var/lib/oozie/
2) 启用 Oozie 服务器 Web 控制台
在CDH中进入oozie,点击配置,找打“启用 Oozie 服务器 Web 控制台”选项,开启,保存更改之后,重启oozie服务即可。
3) 浏览器或者 CDH 页面访问 oozie 的 webui
webui 地址:cm1:11000
4. oozie job.properties 文件参数

5. oozie 提交任务命令
默认在CDH中安装了oozie后,每台节点都可以当做客户端来提交oozie任务流任务。启动任务,停止任务,提交任务,开始任务和查看任务执行情况的命令如下:
注意:启动任务中的–run 包含了submit和start操作。
1. 启动任务:
2. oozie job -oozie http://ip:11000/oozie/ -config job.properties –run
3.
4. 停止任务:
5. oozie job -oozie http://ip:11000/oozie/ -kill 0000002-150713234209387-oozie-oozi-W
6.
7. 提交任务:
8. oozie job -oozie http://ip:11000/oozie/ -config job.properties –submit
9.
10. 开始任务:
11. oozie job -oozie http://ip:11000/oozie/ -config job.properties –start 0000003-150713234209387-oozie-oozi-W
12.
13. 查看任务执行情况:
14. oozie job -oozie http://ip:11000/oozie/ -config job.properties –info 0000003-150713234209387-oozie-oozi-W
6. oozie 提交任务流
oozie 提交任务需要两个文件,一个是workflow.xml文件,这个文件要上传到HDFS中,当执行oozie任务流调度时,oozie 服务端会在从当前xml中获取当前要执行的任务。
另一个是job.properties文件,这个文件是oozie在客户端提交流调度任务时告诉oozie服务端workflow.xml文件在什么位置的描述配置文件。
配置workflow.xml文件,内容如下:
1. <workflow-app xmlns="uri:oozie:workflow:0.3" name="shell-wf">
2. <start to="shell-node"/>
3. <action name="shell-node">
4. <shell xmlns="uri:oozie:shell-action:0.1">
5. <job-tracker>${jobTracker}job-tracker>
6. <name-node>${nameNode}name-node>
7. <configuration>
8. <property>
9. <name>mapred.job.queue.namename>
10. <value>${queueName}value>
11. property>
12. configuration>
13. <exec>echoexec>
14. <argument>**** first-hello oozie *****argument>
15. shell>
16. <ok to="end"/>
17. <error to="fail"/>
18. action>
19. <kill name="fail">
20. <message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]message>
21. kill>
22. <end name="end"/>
23. workflow-app>
在CDH中进入hue,在HDFS中创建文件workflow.xml:
打开文件编辑器,将以上内容写入workflow.xml中,点击保存:
在cm1,cm2,cm3任意节点上,选择一个节点当做提交oozie任务的客户端,创建job.properties文件,写入以下内容:
1. nameNode=hdfs://cm1:8020
2. jobTracker=cm1:8032
3. queueName=default
4. examplesRoot=examples
5. user.name=myhue #根据当时用户名称来定
6. oozie.wf.application.path=${nameNode}/user/myhue
提交 oozie 任务后会自动转换成 MapReduce 任务执行,这个时候需要Yarn资源调度。默认在Hadoop2.x版本中默认Yarn每个NodeManager节点分配资源为8core和8G,内存配置为“yarn.nodemanager.resource.memory-mb”代表当前NodeManager可以使用的内存总量。每个container启动默认可以使用最大的内存量为“yarn.scheduler.maximum-allocation-mb”,默认为8G。
在 Hadoop3.x 版本之后,Yarn NodeManager 节点默认分配的资源为1core和4G。这里oozie任务任务需要的默认资源是2core和1G,所以这里需要在Yarn中调大每台NodeManager的内存资源,在Yarn 配置中找到配置项“yarn.nodemanager.resource.memory-mb”调节到至少2G以上,同时需要调大每个Container可以使用的最大内存,将“yarn.scheduler.maximum-allocation-mb”调节到至少2G以上,但是应小于“yarn.nodemanager.resource.memory-mb”参数。配置如下:
以上点击“保存修改”完成配置之后,需要重新启动Yarn集群即可。配置完成后,在当前客户端执行提交如下oozie的命令,可以看到返回了一个jobid,可以根据这个jobId,停止任务或者查看任务执行情况。
1. oozie job -oozie http://cm1:11000/oozie/ -config job.properties -run
启动任务之后,可以在oozie的webui页面中看到如下结果: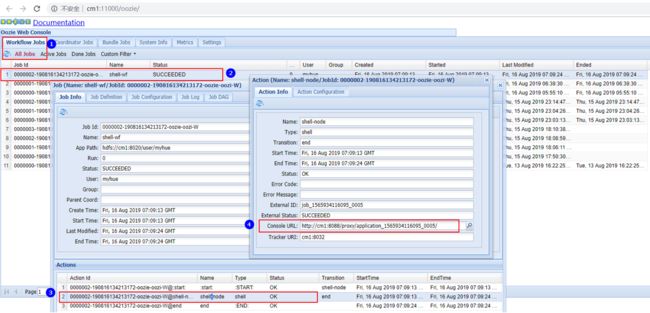
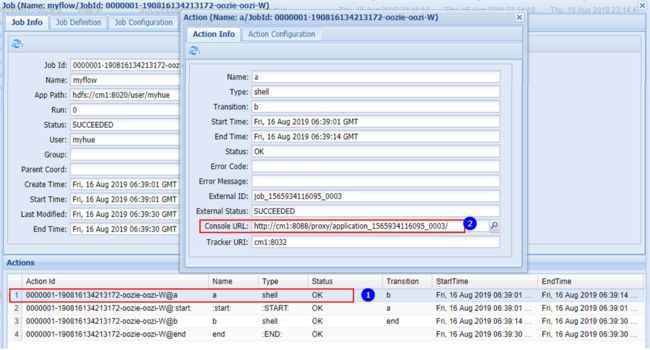
上图中,可以点击任务流中的任务找打对应的console url ,在浏览器中输入url查看结果:
7. oozie 提交含有多个任务的任务流
通过 hue 可以创建 workflow.xml 文件写入以下命令,执行任务 a 和任务 b:
1. <workflow-app xmlns="uri:oozie:workflow:0.3" name="myflow">
2. <start to="a"/>
3. <action name="a">
4. <shell xmlns="uri:oozie:shell-action:0.1">
5. <job-tracker>${jobTracker}job-tracker>
6. <name-node>${nameNode}name-node>
7. <configuration>
8. <property>
9. <name>mapred.job.queue.namename>
10. <value>${queueName}value>
11. property>
12. configuration>
13. <exec>echoexec>
14. <argument>**** first-hello oozie *****argument>
15. shell>
16. <ok to="b"/>
17. <error to="fail"/>
18. action>
19. <action name="b">
20. <shell xmlns="uri:oozie:shell-action:0.1">
21. <job-tracker>${jobTracker}job-tracker>
22. <name-node>${nameNode}name-node>
23. <configuration>
24. <property>
25. <name>mapred.job.queue.namename>
26. <value>${queueName}value>
27. property>
28. configuration>
29. <exec>echoexec>
30. <argument>**** second-i am second *****argument>
31. shell>
32. <ok to="end"/>
33. <error to="fail"/>
34. action>
35. <kill name="fail">
36. <message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]message>
37. kill>
38. <end name="end"/>
39. workflow-app>
在cm1,cm2,cm3任意节点,创建文件:job.properties,写入以下内容:
1. nameNode=hdfs://cm1:8020
2. jobTracker=cm1:8032
3. queueName=default
4. examplesRoot=examples
5. user.name=myhue #根据当时用户名称来定
6. oozie.wf.application.path=${nameNode}/user/myhue
执行提交 oozie 任务的命令:
1. oozie job -oozie http://cm1:11000/oozie/ -config job.properties -run
执行命令之后,进入 oozie webui 查看任务执行情况: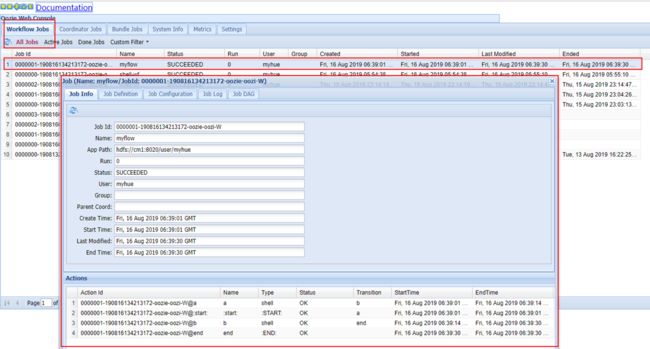
可以点击任务流中的某个任务,查看详细执行信息和登录yarn查看结果。