opencv3/4入门学习笔记(几万字长篇,慎入)
欢迎交流,weixin见博客签名,坐标:重庆
入门时连续三个多月的学习笔记,一句话:坚持就对了。
持续更新,,,,,,
opencv安装参考链接
安装脚本链接:https://github.com/milq/milq/blob/master/scripts/bash/install-opencv.sh
资源参考:https://www.learnopencv.com/
1.读图: Mat src = imread("D:/vcprojects/images/test.png", IMREAD_GRAYSCALE); // 读取图像返回灰度图
opencv版本3.x : CV_LOAD_IMAGE_GRAYSCALE opencv版本4.x : cv::IMREAD_GRAYSCALE
显示图像:imshow("input", src);
2.色彩空间转换函数- cvtColor和图像保存 - imwrite
cvtColor(src, gray, COLOR_BGR2GRAY); //BGR转灰度图
imwrite("D:/gray.png", gray); // 将图像gray保存到路径
3.OpenCV中图像对象创建与赋值
创建一个和src对象大小和类型相同的空白图片对象
Mat m4 = Mat::zeros(src.size(), src.type());
4.OpenCV中图像像素读写操作
直接读取图像像素和指针读取,后者效率更高
5. OpenCV中像素算术操作
图像可进行以下操作:加add、减subtract、乘multiply、除divide
6. Look Up Table(LUT)查找表,解释了LUT查找表的作用与用法,代码实现与API介绍
// 使用LUT转化成不同颜色风格 applyColorMap(src, dst, COLORMAP_COOL); //不同颜色转化 cvtColor(src, gray, COLOR_BGR2YCrCb);
7. 像素操作之逻辑操作
- bitwise_and
- bitwise_xor
- bitwise_or
上面三个类似,都是针对两张图像的位操作
- bitwise_not
针对输入图像, 图像取反操作,二值图像分析中经常用
8.通道分离与合并
OpenCV中默认imread函数加载图像文件,加载进来的是三通道彩色图像,色彩空间是RGB色彩空间、通道顺序是BGR(蓝色、绿色、红色)、对于三通道的图像OpenCV中提供了两个API函数用以实现通道分离与合并。
- split // 通道分离
- merge // 通道合并
split(src, mv);
mv[0] = Scalar(0);
merge(mv, dst1);//将蓝色通道去掉,然后再和原图合并,得到去掉蓝色通道的图像,其他通道一样的操作
扩展一下:
在很多CNN的卷积神经网络中输入的图像一般会要求[h, w, ch]其中h是高度、w是指宽度、ch是指通道数数目、OpenCV DNN模块中关于图像分类的googlenet模型输入[224,224,3]表示的就是224x224大小的三通道的彩色图像输入。
9.色彩空间与色彩空间转换
- RGB色彩空间
- HSV色彩空间
- YUV色彩空间
- YCrCb色彩空间
API知识点
- 色彩空间转换函数cvtColor
- 提取指定色彩范围区域inRange
inRange(hsv, Scalar(35, 43, 46), Scalar(77, 255, 255), mask);
说明:hsv源图像,scalar类型的像素值下限,scalar类型的像素值上限,目标图像
10.像素值统计
- 最小(min)
- 最大(max)
- 均值(mean)
- 标准方差(standard deviation)
API知识点
- 最大最小值minMaxLoc
- 计算均值与标准方差meanStdDev
means.at(0, 0), stddev.at(0, 0)
means.at(1, 0), stddev.at(1, 0)
means.at(2, 0), stddev.at(2, 0)
11.像素归一化
归一化之前要将整形数据转化为浮点数,防止数据出错
imshow显示的数据也要是整形的
OpenCV中提供了四种归一化的方法
- NORM_MINMAX
- NORM_INF
- NORM_L1
- NORM_L2
最常用的就是NORM_MINMAX归一化方法。
相关API函数:
normalize(
InputArray src, // 输入图像
InputOutputArray dst, // 输出图像
double alpha = 1, // NORM_MINMAX时候低值
double beta = 0, // NORM_MINMAX时候高值
int norm_type = NORM_L2, // 只有alpha
int dtype = -1, // 默认类型与src一致
InputArray mask = noArray() // mask默认值为空
)
12. 视频读写
VideoCapture 视频文件读取、摄像头读取、视频流读取
VideoWriter 视频写出、文件保存、
- CAP_PROP_FRAME_HEIGHT
- CAP_PROP_FRAME_WIDTH
- CAP_PROP_FRAME_COUNT
- CAP_PROP_FPS
实例:VideoWriter writer("./opencv_tutorial/data/video/test.mp4", CV_FOURCC('D', 'I', 'V', 'X'), fps, S, true);//v4.0以前版本
VideoWriter writer("./opencv_tutorial/data/video/test.mp4", VideoWriter::fourcc('D', 'I', 'V', 'X'), fps, S, true); //4.0以后用VideoWriter::fourcc('D', 'I', 'V', 'X')这种方式
不支持音频编码与解码保存,不是一个音视频处理的库!主要是分析与解析视频内容。保存文件最大支持单个文件为2G
13.图像翻转(Image Flip)
图像翻转的本质像素映射,OpenCV支持三种图像翻转方式
- X轴翻转,flipcode = 0 //倒像
- Y轴翻转, flipcode = 1 //镜像
- XY轴翻转, flipcode = -1 //对角影射
相关的API
flip
- src输入参数
- dst 翻转后图像
- flipcode
14.图像插值(Image Interpolation)
最常见四种插值算法
INTER_NEAREST - 最近邻插值
INTER_LINEAR - 线性插值(默认)
INTER_AREA - 区域插值
INTER_CUBIC - 三次样条插值
INTER_LANCZOS4 - Lanczos插值
相关的应用场景
几何变换、透视变换、插值计算新像素
resize,
如果size有值,使用size做放缩插值,否则根据fx与fy
卷积、
关于这四种插值算法的详细代码实现与解释
图像处理之三种常见双立方插值算法 - CSDN博客
图像放缩之双立方插值 - CSDN博客
图像放缩之双线性内插值 - CSDN博客
图像处理之Lanczos采样放缩算法 - CSDN博客
15.几何形状绘制
绘制几何形状
- 绘制直线:line(image, Point(x1, y1), Point(x2, y2), Scalar(b, g, r), 1, LINE_AA, 0);
- 绘制圆:circle(image, Point(256, 256), 50, Scalar(0, 0, 255), 2, LINE_8, 0);
- 绘制矩形:
Rect rect(100, 100, 200, 200); //左上顶点坐标x, y, width, height
rect.area(); //返回rect的面积 40000
rect.size(); //返回rect的尺寸 [200 × 200]
rect.tl(); //返回rect的左上顶点的坐标 [100, 100]
rect.br(); //返回rect的右下顶点的坐标 [300, 300]
rect.width(); //返回rect的宽度 200
rect.height(); //返回rect的高度 200
rect.contains(Point(x, y)); //返回布尔变量,判断rect是否包含Point(x, y)点
rectangle(image, rect, Scalar(255, 0, 0), 2, LINE_8, 0);
- 绘制椭圆:ellipse(image, Point(256, 256), Size(150, 50), 360, 0, 360, Scalar(0, 255, 0), 2, LINE_8, 0);
填充几何形状
OpenCV没有专门的填充方法,只是把绘制几何形状时候的线宽 - thickness参数值设置为负数即表示填充该几何形状或者使用参数CV_FILLED
随机数方法:
RNG 表示OpenCV C++版本中的随机数对象,int x1 = rng.uniform(a, b);生成[a, b)之间的随机数,包含a,但是不包含b。
char c = waitKey(20); //20表示等待时间,返回的c表示键值
16.图像ROI与ROI操作(加深理解)
图像ROI解释:
图像的ROI(region of interest)是指图像中感兴趣区域、在OpenCV中图像设置图像ROI区域,实现只对ROI区域操作。
- 矩形ROI区域提取
- 矩形ROI区域copy
roi.setTo(Scalar(255, 0, 0));
imshow("result", src);//将roi区域转成蓝色,然后显示原图,可以理解为通过Mat roi = src(rect);获取的ROI区域是原图像的子集
- 不规则ROI区域
- ROI区域mask生成
- 像素位 and操作
- 提取到ROI区域
- 加背景or操作
- add 背景与ROI区域
cvtColor(src2, hsv, COLOR_BGR2HSV);
inRange(hsv, Scalar(35, 43, 46), Scalar(99, 255, 255), mask);
练习:Scalar类型像素色彩上下限全图查找后自动选择,实现自动抠图的效果
17.图像直方图
图像直方图的解释
图像直方图是图像像素值的统计学特征、计算代价较小,具有图像平移、旋转、缩放不变性等众多优点,广泛地应用于图像处理的各个领域,特别是灰度图像的阈值分割、基于颜色的图像检索以及图像分类、反向投影跟踪。常见的分为
- 灰度直方图
- 颜色直方图
Bins是指直方图的大小范围, 对于像素值取值在0~255之间的,最少有256个bin,此外还可以有16、32、48、128等,256除以bin的大小应该是整数倍。
OpenCV中相关API
calcHist(&bgr_plane[0], 1, 0, Mat(), b_hist, 1, bins, ranges);
cv.calcHist([image], [i], None, [256], [0, 256])
函数详解:void calcHist(const Mat* images, int nimages, const int* channels, InputArray mask, OutputArray hist, int dims, const int* histSize, const float** ranges, bool uniform=true, bool accumulate=false )
参数详解:
onst Mat* images:输入图像分离出来的三个通道图像
int nimages:输入图像的个数
const int* channels:需要统计直方图的第几通道
InputArray mask:掩膜,,计算掩膜内的直方图 ...Mat()
OutputArray hist:输出的直方图数组
int dims:需要统计直方图通道的个数
const int* histSize:指的是直方图分成多少个区间,就是 bin的个数
const float** ranges: 统计像素值得区间
bool uniform=true::是否对得到的直方图数组进行归一化处理
bool accumulate=false:在多个图像时,是否累计计算像素值得个数
18.图像直方图均衡化
图像直方图均衡化可以用于图像增强、对输入图像进行直方图均衡化处理,提升后续对象检测的准确率在OpenCV人脸检测的代码演示中已经很常见。此外对医学影像图像与卫星遥感图像也经常通过直方图均衡化来提升图像质量。
OpenCV中直方图均衡化的API很简单
- equalizeHist(src, dst)
19.图像直方图比较
图像直方图比较,就是计算两幅图像的直方图数据,比较两组数据的相似性,从而得到两幅图像之间的相似程度,直方图比较在早期的CBIR中是应用很常见的技术手段,通常会结合边缘处理、词袋等技术一起使用。
OpenCV中直方图比较的API很简单
compareHist(hist1, hist2, method)
-method:常见比较方法有
0:相关性:相似性
1:卡方:方差:
2:交叉:
3:巴氏
常用 相关性和巴氏方法
20.图像直方图反向投影
应用:可用于对象的跟踪。
文字解释:
图像直方图反向投影是通过构建指定模板图像的二维直方图空间与目标的二维直方图空间,进行直方图数据归一化之后, 进行比率操作,对所有得到非零数值,生成查找表对原图像进行像素映射之后,再进行图像模糊输出的结果。
直方图反向投影流程:
- 计算直方图
- 计算比率R
- LUT查找表
- 卷积模糊
- 归一化输出
相关API
- calcBackProject

参数解释:
const Mat* images:输入图像,图像深度必须位CV_8U,CV_16U或CV_32F中的一种,尺寸相同,每一幅图像都可以有任意的通道数
int nimages:输入图像的数量
const int* channels:用于计算反向投影的通道列表,通道数必须与直方图维度相匹配,第一个数组的通道是从0到image[0].channels()-1,第二个数组通道从图像image[0].channels()到image[0].channels()+image[1].channels()-1计数
InputArray hist:输入的直方图,直方图的bin可以是密集(dense)或稀疏(sparse)
OutputArray backProject:目标反向投影输出图像,是一个单通道图像,与原图像有相同的尺寸和深度
const float ranges**:直方图中每个维度bin的取值范围
double scale=1:可选输出反向投影的比例因子
bool uniform=true:直方图是否均匀分布(uniform)的标识符,有默认值true
21.图像卷积操作——均值滤波
图像卷积可以看成是一个窗口区域在另外一个大的图像上移动,对每个窗口覆盖的区域都进行点乘得到的值作为中心像素点的输出值。窗口的移动是从左到右,从上到下。窗口可以理解成一个指定大小的二维矩阵,里面有预先指定的值。
相关API(C++)
- blur(
InputArray src, // 输入
OutputArray dst, 输出
Size ksize, // 窗口大小
Point anchor = Point(-1,-1), // 默认值,对图像进行卷积的其实像素位置
int borderType = BORDER_DEFAULT // 默认值
)
22.图像均值与高斯模糊
均值模糊 是卷积核的系数完全一致,高斯模糊考虑了中心像素距离的影响,对距离中心像素使用高斯分布公式生成不同的权重系数给卷积核,然后用此卷积核完成图像卷积得到输出结果就是图像高斯模糊之后的输出。
高斯滤波的效果会更均衡、图像更淡,
OpenCV高斯模糊 API函数
void GaussianBlur(
InputArray src,
OutputArray dst,
Size ksize, // Ksize为高斯滤波器窗口大小,越大越模糊
double sigmaX, // X方向滤波系数,越大越模糊
double sigmaY=0, // Y方向滤波系数,默认
int borderType=BORDER_DEFAULT // 默认边缘插值方法
)
当Size(0, 0)就会从sigmax开始计算生成高斯卷积核系数,当时size不为零是优先从size开始计算高斯卷积核系数
23.中值模糊
中值滤波本质上是统计排序滤波器的一种,中值滤波对图像特定噪声类型(椒盐噪声)会取得比较好的去噪效果,也是常见的图像去噪声与增强的方法之一。中值滤波也是窗口在图像上移动,其覆盖的对应ROI区域下,所有像素值排序,取中值作为中心像素点的输出值
OpenCV中值滤波API函数如下:
medianBlur (
InputArray src,
OutputArray dst,
int ksize // 必须是奇数,而且必须大于1
)
24.图像噪声
RNG rng(12345); //生成随机数 randn(noise, (15, 15, 15), (30, 30, 30)); //产生高斯噪声,均值15,方差30 add(image, noise, dst);// 噪声和原图叠加
图像噪声产生的原因很复杂,有的可能是数字信号在传输过程中发生了丢失或者受到干扰,有的是成像设备或者环境本身导致成像质量不稳定,反应到图像上就是图像的亮度与颜色呈现某种程度的不一致性。从噪声的类型上,常见的图像噪声可以分为如下几种:
- 椒盐噪声,
是一种随机在图像中出现的稀疏分布的黑白像素点, 对椒盐噪声一种有效的去噪手段就是图像中值滤波
- 高斯噪声/符合高斯分布
一般会在数码相机的图像采集(acquisition)阶段发生,这个时候它的物理/电/光等各种信号都可能导致产生高斯分布噪声。
- 均匀分布噪声
均匀/规则噪声一般都是因为某些规律性的错误导致的
25.图像去噪声
图像去噪声在OCR、机器人视觉与机器视觉领域应用开发中是重要的图像预处理手段之一,对图像二值化与二值分析很有帮助,OpenCV中常见的图像去噪声的方法有
- 均值去噪声:椒盐噪声
- 高斯模糊去噪声:高斯噪声
- 非局部均值去噪声:fastNlMeansDenoisingColored(src, result4, 15, 15, 10, 30);
- 双边滤波去噪声
- 形态学去噪声
26.边缘保留滤波算法 – 高斯双边模糊
前面我们介绍的图像卷积处理无论是均值还是高斯都是属于模糊卷积,它们都有一个共同的特点就是模糊之后图像的边缘信息不复存在,受到了破坏。我们今天介绍的滤波方法有能力通过卷积处理实现图像模糊的同时对图像边缘不会造成破坏,滤波之后的输出完整的保存了图像整体边缘(轮廓)信息,我们称这类滤波算法为边缘保留滤波算法(EPF)。最常见的边缘保留滤波算法有以下几种
- 高斯双边模糊:常用于美颜、磨皮处理
- Meanshift均值迁移模糊
- 局部均方差模糊
- OpenCV中对边缘保留滤波还有一个专门的API
本周我们的分享就从最经典的高斯双边模糊开始,高斯模糊是考虑图像空间位置对权重的影响,但是它没有考虑图像像素分布对图像卷积输出的影响,双边模糊考虑了像素值分布的影响,对像素值空间分布差异较大的进行保留从而完整的保留了图像的边缘信息。
C++:
bilateralFilter(
InputArray src,
OutputArray dst,
int d,
double sigmaColor,
double sigmaSpace,
int borderType = BORDER_DEFAULT
)
27.边缘保留滤波算法 – 均值迁移模糊(mean-shift blur)
均值迁移模糊是图像边缘保留滤波算法中一种,经常用来在对图像进行分水岭分割之前去噪声,可以大幅度提升分水岭分割的效果。均值迁移模糊的主要思想如下:
就是在图像进行开窗的时候同样,考虑像素值空间范围分布,只有符合分布的像素点才参与计算,计算得到像素均值与空间位置均值,使用新的均值位置作为窗口中心位置继续基于给定像素值空间分布计算均值与均值位置,如此不断迁移中心位置直到不再变化位置(dx=dy=0),但是在实际情况中我们会人为设置一个停止条件比如迁移几次,这样就可以把最后的RGB均值赋值给中心位置。
OpenCV中均值迁移滤波的API函数:
C++:
pyrMeanShiftFiltering(
InputArray src,
OutputArray dst,
double sp,//窗口半径
double sr,//颜色值空间大小
int maxLevel = 1,// 默认1
TermCriteria termcrit =
TermCriteria(TermCriteria::MAX_ITER+TermCriteria::EPS, 5, 1) //停止条件,5次
)
28.图像积分图算法
概述
积分图像是Crow在1984年首次提出,是为了在多尺度透视投影中提高渲染速度,是一种快速计算图像区域和与平方和的算法。其核心思想是对每个图像建立自己的积分图查找表,在图像积分处理计算阶段根据预先建立的积分图查找表,直接查找从而实现对均值卷积线性时间计算,做到了卷积执行的时间与半径窗口大小的无关联。图像积分图在图像特征提取HAAR/SURF、二值图像分析、图像相似相关性NCC计算、图像卷积快速计算等方面均有应用,是图像处理中的经典算法之一。
图像积分图建立与查找
在积分图像(Integral Image - ii)上任意位置(x, y)处的ii(x, y)表示该点左上角所有像素之和, 其中(x,y)是图像像素点坐标。
图一的语音解释
OpenCV中的相关API如下:
integral(
InputArray src, // 输入图像
OutputArray sum, // 和表
OutputArray sqsum, // 平方和表
OutputArray tilted, // 瓦块和表
int sdepth = -1, // 和表数据深度常见CV_32S
int sqdepth = -1 // 平方和表数据深度 常见 CV_32F
)
29.快速的图像边缘滤波算法
高斯双边模糊与mean shift均值模糊两种边缘保留滤波算法,都因为计算量比较大,无法实时实现图像边缘保留滤波,限制了它们的使用场景,OpenCV中还实现了一种快速的边缘保留滤波算法。高斯双边与mean shift均值在计算时候使用五维向量是其计算量大速度慢的根本原因,该算法通过等价变换到低纬维度空间,实现了数据降维与快速计算。
OpenCV API函数为:
void cv::edgePreservingFilter(
InputArray src,
OutputArray dst,
int flags = 1,
float sigma_s = 60,
float sigma_r = 0.4f
)
其中sigma_s的取值范围为0~200, sigma_r的取值范围为0~1
当sigma_s取值不变时候,sigma_r越大图像滤波效果越明显
当sigma_r取值不变时候,窗口sigma_s越大图像模糊效果越明显
当sgma_r取值很小的时候,窗口sigma_s取值无论如何变化,图像双边滤波效果都不好!
计算执行时间:
double tt = getTickCount();
edgePreservingFilter(src, dst, 1, 60, 0.44);
double end = (getTickCount() - tt) / getTickFrequency();//结果为秒
30.OpenCV中的自定义滤波器
图像卷积最主要功能有图像模糊、锐化、梯度边缘等,前面已经分享图像卷积模糊的相关知识点,OpenCV除了支持上述的卷积模糊(均值与边缘保留)还支持自定义卷积核,实现自定义的滤波操作。自定义卷积核常见的主要是均值、锐化、梯度等算子。下面的三个自定义卷积核分别可以实现卷积的均值模糊、锐化、梯度功能。
1, 1, 1 0, -1, 0 1, 0
1, 1, 1 -1, 5, -1 0 -1
1, 1, 1 0, -1, 0
OpenCV自定义滤波器API:
void cv::filter2D(
InputArray src,
OutputArray dst,
int ddepth, // 默认-1,结果和原图类型相同
InputArray kernel, // 卷积核或者卷积窗口大小
Point anchor = Point(-1,-1),//
double delta = 0,
int borderType = BORDER_DEFAULT
)
int ddepth, // 默认-1,表示输入与输出图像类型一致,但是当涉及浮点数计算时候,需要设置为CV_32F。滤波完成之后需要使用convertScaleAbs函数将结果转换为字节类型。
convertScaleAbs(dst3, dst3);//对原浮点输入图像转为8位图像
31.图像梯度 – Sobel算子
卷积的作用除了实现图像模糊或者去噪,还可以寻找一张图像上所有梯度信息,这些梯度信息是图像的最原始特征数据,进一步处理之后就可以生成一些比较高级的特征用来表示一张图像实现基于图像特征的匹配,图像分类等应用。Sobel算子是一种很经典的图像梯度提取算子,其本质是基于图像空间域卷积,背后的思想是图像一阶导数算子的理论支持。OpenCV实现了基于Sobel算子提取图像梯度的API,表示与解释如下:
void cv::Sobel(
InputArray src, // 输入图像
OutputArray dst, // 输出结果
int ddepth, // 图像深度CV_32F
int dx,// 1,X方向 一阶导数
int dy, // 1,Y方向 一阶导数
int ksize = 3, // 窗口大小
double scale = 1, // 放缩比率,1 表示不变
double delta = 0, // 对输出结果图像加上常量值
int borderType = BORDER_DEFAULT
)
add(grad_x, grad_y, dst, Mat(), CV_16S); //8位两个图像叠加输出16位
convertScaleAbs(dst, dst);//再转为8位图像
32.图像梯度 – 更多梯度算子
图像的一阶导数算子除了sobel算子之外,常见的还有robert算子与prewitt算子,它们也都是非常好的可以检测图像的梯度边缘信息,通过OpenCV中自定义滤波器,使用自定义创建的robert与prewitt算子就可以实现图像的rober与prewitt梯度边缘检测,OpenCV中的自定义算子滤波函数如下:
filter2D(
InputArray src,
OutputArray dst,
int ddepth,
InputArray kernel,//可自定义算子卷积核
Point anchor = Point(-1,-1),
double delta = 0,
int borderType = BORDER_DEFAULT
)
33. 图像梯度 – 拉普拉斯算子(二阶导数算子)
图像的一阶导数算子可以得到图像梯度局部梯度相应值,二阶导数可以通过快速的图像像素值强度的变化来检测图像边缘,其检测图像边缘的原理跟图像的一阶导数有点类似,只是在二阶导数是求X、Y方向的二阶偏导数,对图像来说:
X方向的二阶偏导数就是 dx = f(x+1, y) + f(x-1, y) – 2f(x, y)
Y方向的二阶偏导数就是 dy = f(x, y+1) + f(x, y-1) – 2f(x, y)
对X方向与Y方向进行叠加最终就得到delta对应的二阶导数算子,看第一张图像最下面的部分就是对应的四邻域的二阶导数算子,我们可以进一步扩展增强为八邻域的算子。
OpenCV中Laplacian滤波函数就是二阶导数发现边缘的函数:
void cv::Laplacian(
InputArray src,
OutputArray dst,
int ddepth, // 深度默认是-1表示输入与输出图像相同,一般用CV_32F
int ksize = 1,// 必须是奇数, 等于1是四邻域算子,大于1改用八邻域算子,八邻域比四邻域边缘更清晰
double scale = 1,
double delta = 0, // 对输出图像加上常量值
int borderType = BORDER_DEFAULT
)
PS:
拉普拉斯算子是一种特别容易受到噪声干扰的边缘发现算子,所以经常对要处理的图像首先进行一个高斯模糊,然后再进行拉普拉斯算子的边缘提取,而且在一些场景中会把这两步合并成为一步,就是我们经常听说的LOG算子。
34.图像锐化或增强
也就是对图像提高对比度或额外增加亮度
图像卷积的主要有三功能分别是图像的模糊/去噪、图像梯度/边缘发现、图像锐化/增强,前面的两个功能我们以前通过相关知识点的分享加以了解,学习了相关API的使用。图像锐化的本质是图像拉普拉斯滤波加原图权重像素叠加的输出 :
-1 -1 -1
-1 C -1
-1 -1 -1
当C值大于8时候表示图像锐化、越接近8表示锐化效果越好
当C值等于8时候图像的高通滤波:找出高对比度的地方
当C值越大,图像锐化效果在减弱、中心像素的作用在提升
35.USM 锐化增强算法
此方法增强后的结果会更真实
图像卷积处理实现锐化有一种常用的算法叫做Unsharpen Mask方法,这种锐化的方法就是对原图像先做一个高斯模糊,然后用原来的图像减去一个系数乘以高斯模糊之后的图像,然后再把值Scale到0~255的RGB像素值范围之内。基于USM锐化的方法可以去除一些细小的干扰细节和噪声,比一般直接使用卷积锐化算子得到的图像锐化结果更加真实可信。
USM锐化公式表示如下:
(源图像– w*高斯模糊)/(1-w);其中w表示权重(0.1~0.9),默认为0.6
OpenCV中的代码实现步骤
- 高斯模糊:也可以替换成均值模糊
- 权重叠加
- 输出结果
API详解:void cvAddWeighted( const CvArr* src1, double alpha,const CvArr* src2, double beta,double gamma, CvArr* dst );
参数1:src1,第一个原数组.
参数2:alpha,第一个数组元素权重
参数3:src2第二个原数组
参数4:beta,第二个数组元素权重
参数5:gamma,图1与图2作和后添加的数值。不要太大,不然图片一片白。总和等于255以上就是纯白色了。
参数6:dst,输出图片
36.Canny边缘检测器
1986年,JOHN CANNY 提出一个很好的边缘检测算法,被称为Canny边缘检测器。Canny边缘检测器是一种经典的图像边缘检测与提取算法,应用广泛,主要是因为Canny边缘检测具备以下特点:
- 有效的噪声抑制
- 更强的完整边缘提取能力
Canny算法是如何做到精准的边缘提取的,主要是靠下面五个步骤
- 高斯模糊 – 抑制噪声
- 梯度提取得到边缘候选
- 角度计算与非最大信号抑制
- 高低阈值链接、获取完整边缘
- 输出边缘
OpenCV中Canny边缘检测的API如下:
void cv::Canny(
InputArray image,
OutputArray edges,
double threshold1,
double threshold2,
int apertureSize = 3,
bool L2gradient = false :L1
)
threshold1 是Canny边缘检测算法第四步中高低阈值链接中低阈值
threshold2 是Canny边缘检测算法第四步中高低阈值链接中高阈值、高低阈值之比在2:1~3:1之间
最后一个参数是计算gradient的方法L1或者L2
关于Canny算法本身更多解释与代码实现:
图像处理之Canny边缘检测 - 关注微信公众号【OpenCV学堂】 - CSDN博客
37.图像金字塔
图像金字塔概念
图像金字塔是对一张输入图像先模糊再下采样为原来大小的1/4(宽高缩小一半)、不断重复模糊与下采样的过程就得到了不同分辨率的输出图像,叠加在一起就形成了图像金字塔、所以图像金字塔是图像的空间多分辨率存在形式。这里的模糊是指高斯模糊,所以这个方式生成的金字塔图像又称为高斯金字塔图像。高斯金字塔图像有两个基本操作
reduce 是从原图生成高斯金字塔图像、生成一系列低分辨图像
expand是从高斯金字塔图像反向生成高分辨率图像
规则:
- 图像金字塔在redude过程或者expand过程中必须是逐层
- reduce过程中每一层都是前一层的1/4
38.拉普拉斯金字塔
也可以用于提取图像特征
对输入图像实现金字塔的reduce操作就会生成不同分辨率的图像、对这些图像进行金字塔expand操作,然后使用reduce减去expand之后的结果就会得到图像拉普拉斯金字塔图像。
举例如下:
输入图像G(0)
金字塔reduce操作生成 G(1), G(2), G(3)
拉普拉斯金字塔:
L0 = G(0)-expand(G(1))
L1 = G(1)-expand(G(2))
L2 = G(2)–expand(G(3))
G(0)减去expand(G(1))得到的结果就是两次高斯模糊输出的不同,所以L0称为DOG(高斯不同)、它约等于LOG所以又称为拉普拉斯金字塔。所以要求的图像的拉普拉斯金字塔,首先要进行金字塔的reduce操作,然后在通过expand操作,最后相减得到拉普拉斯金字塔图像。
39.图像模板匹配
模板匹配的前提限制条件比较严格:相同光源成像下,相同尺寸等,是像素级的比较。
模板匹配被称为最简单的模式识别方法、同时也被很多人认为是最没有用的模式识别方法。这里里面有很大的误区,就是模板匹配是工作条件限制比较严格,只有满足理论设置的条件以后,模板匹配才会比较好的开始工作,而且它不是基于特征的匹配,所以有很多弊端,但是不妨碍它成为入门级别模式识别的方法,通过它可以学习到很多相关的原理性内容,为后续学习打下良好的基础。
OpenCV中模板匹配的API为
void cv::matchTemplate (
InputArray image,
InputArray templ,
OutputArray result,
int method,
InputArray mask = noArray()
)
其中method表示模板匹配时候采用的计算像素相似程度的方法,常见有如下
TM_SQDIFF = 0
TM_SQDIFF_NORMED = 1
平方不同与平方不同的归一化版本,值越大越不匹配
TM_CCORR = 2
TM_CCORR_NORMED = 3
相关性,值越大相关性越强,表示匹配程度越高。
归一化版本值在0~1之间,1表示高度匹配,0表示完全不匹配
TM_CCOEFF = 4
TM_CCOEFF_NORMED = 5
相关因子,值越大相关性越强,表示匹配程度越高。
归一化版本值在0~1之间,1表示高度匹配,0表示完全不匹配
40.二值图像介绍
二值图像就是只有黑白两种颜色表示的图像,其中0 – 表示黑色, 1 – 表示白色(255) 。二值图像处理与分析在机器视觉与机器人视觉中非常重要,涉及到非常多的图像处理相关的知识,常见的二值图像分析包括轮廓分析、对象测量、轮廓匹配与识别、形态学处理与分割、各种形状检测与拟合、投影与逻辑操作、轮廓特征提取与编码等。此外图像二值化的方法也有很多,OpenCV主要是支持几种经典的二值化算法。
从编程与代码角度,OpenCV中二值图像单通道的、字节类型的Mat对象、对于任意的输入图像首先需要把图像转换为灰度、然后通过二值化方法转换为二值图像。本质上,从灰度到二值图像,是对数据的二分类分割,所以很多数据处理的方法都可以使用,但是图像是特殊类型的数据,它有很多限制条件,决定了只有一些合适的方法才会取得比较好的效果。这些算法的最主要的一个任务就是寻找合理的分割阈值T、对于给定任意一个像素点灰度值
P(x, y) > T ? 255 : 0
多数人接触二值图像都是从下面的这个程序实现二值分割的,就是使用T=127作为阈值,对灰度图像进行二值分割。
41.OpenCV中的基本阈值操作
假设我们已经寻找到合适的阈值T,那么对图像二值化分割可以看成是一种基本的阈值化操作,其实OpenCV除了支持正常的二值化阈值分割操作之外,还支持一些其它的阈值操作,OpenCV中支持的阈值操作的API如下:
double cv::threshold(
InputArray src,
OutputArray dst,
double thresh,
double maxval,
int type
)
其中type表示阈值分割的方法,支持如下五种:
THRESH_BINARY = 0 二值分割
THRESH_BINARY_INV = 1 反向二值分割
THRESH_TRUNC = 2 截断:高于阈值的设置为阈值
THRESH_TOZERO = 3 取零:高于阈值的保留,低于阈值的取零
THRESH_TOZERO_INV = 4 反向取零:高于阈值的取零,低于阈值的保留
返回值double:表示用自动阈值分割方法时返回自动分割的阈值
42.OpenCV中图像二值寻找算法 – OTSU全局阈值分割
图像二值化,除了我们上次分享的手动阈值设置与根据灰度图像均值的方法之外,还有几个根据图像直方图实现自动全局阈值寻找的方法,OpenCV中支持的有OTSU与Triangle两种直方图阈值寻找算法。其中OTSU的是通过计算类间最大方差来确定分割阈值的阈值选择算法,OTSU算法对直方图有两个峰,中间有明显波谷的直方图对应图像二值化效果比较好,而对于只有一个单峰的直方图对应的图像分割效果没有双峰的好。
OpenCV中OTSU算法使用只需要在
threshold函数的type类型声明THRESH_OTSU即可
double t = threshold(gray, binary, 0, 255, THRESH_BINARY | THRESH_OTSU);//分割方法为二值分割,二值寻找方法为OTSU
43.OpenCV中图像二值寻找算法 – TRIANGLE 三角阈值法
图像二值化,除了我们上次分享的手动阈值设置与根据灰度图像均值的方法之外,还有几个根据图像直方图实现自动全局阈值寻找的方法,OpenCV中支持的有OTSU与Triangle两种直方图阈值寻找算法。上次分享提到OTSU基于类内最小方差实现阈值寻找, 它对有两个波峰之间有一个波谷的直方图特别好,但是有时候图像的直方图只有一个波峰,这个时候使用TRIANGLE方法寻找阈值是比较好的一个选择。
OpenCV中TRIANGLE算法使用只需要在
threshold函数的type类型声明THRESH_TRIANGLE即可
double t = threshold(gray, binary, 0, 255, THRESH_BINARY | THRESH_TRIANGLE);//分割方法为二值分割,二值寻找方法为THRESH_TRIANGLE
44.OpenCV中图像二值化自适应阈值算法
一种局部阈值方式,即opencv集成的自适应二值化。自适应阈值化能够根据图像不同区域亮度分布的,改变阈值,OpenCV中的自适应阈值算法主要是基于均值实现,根据计算均值的方法不同分为盒子模糊均值与高斯模糊均值,然后使用原图减去均值图像,得到的差值图像进行自适应分割,相关的API如下:
void cv::adaptiveThreshold(
InputArray src,
OutputArray dst,
double maxValue, 一般取255
int adaptiveMethod,
int thresholdType,
int blockSize,
double C
)
其中blockSize取值必须是奇数,C取值在10左右
adaptiveMethod自适应方法类型:
ADAPTIVE_THRESH_GAUSSIAN_C = 1 高斯模糊
ADAPTIVE_THRESH_MEAN_C = 0 均值模糊
当阈值操作类型thresholdType为:THRESH_BINARY
二值图像 = 原图 – 均值图像 > -C ? 255 : 0
当阈值操作类型thresholdType为:THRESH_BINARY_INV
二值图像 = 原图 – 均值图像 > -C ? 0 : 255
45.图像二值化与去噪
对于一张需要二值化的图像,我们有两种选择
选择一
直接对输入图像转换为灰度图像,然后二值化
选择二
首先对输入图像进行降噪,去除噪声干扰,然后再二值化
在进行去噪声的时候,还记得前面我们分享的几种去噪声方法,可以选择的有
均值模糊去噪声
高斯模糊去噪声
双边/均值迁移模糊去噪声
非局部均值去噪声
pyrMeanShiftFiltering(src, dst, 10, 100);//先均值迁移模糊去噪
或者
GaussianBlur(src, dst, Size(3, 3), 0, 0);//先高斯模糊去噪
cvtColor(dst, gray, COLOR_BGR2GRAY);//再二值化
46.二值图像 联通组件寻找
连通组件标记算法介绍
连接组件标记算法(connected component labeling algorithm)是图像分析中最常用的算法之一,算法的实质是扫描二值图像的每个像素点,对于像素值相同的而且相互连通分为相同的组(group),最终得到图像中所有的像素连通组件。扫描的方式可以是从上到下,从左到右,对于一幅有N个像素的图像来说,最大连通组件个数为N/2。扫描是基于每个像素单位,OpenCV中进行连通组件扫码调用的时候必须保证背景像素是黑色、前景像素是白色。最常见的连通组件扫码有如下两类算法:
- 一步法:基于图的搜索算法
- 两步法:基于扫描与等价类合并算法
OpenCV中支持连通组件扫描的API有两个,一个是带统计信息一个不带统计信息。
不带统计信息的API及其解释如下:
int cv::connectedComponents(
InputArray image, // 输入二值图像,黑色背景
OutputArray labels, // 输出的标记图像,背景index=0
int connectivity = 8, // 连通域,默认是8连通,8或4
int ltype = CV_32S // 输出的labels类型,默认是CV_32S
)
输出int:有多少个labels
47.二值图像连通组件状态统计
OpenCV中的连通组件标记算法有两个相关的API,
一个是不带统计信息的API
int cv::connectedComponents(
InputArray image, // 输入二值图像,黑色背景
OutputArray labels, // 输出的标记图像,背景index=0
int connectivity = 8, // 连通域,默认是8连通
int ltype = CV_32S // 输出的labels类型,默认是CV_32S
)
另外一个是会输出连通组件统计信息的相关API,
int cv::connectedComponentsWithStats(
InputArray image,
OutputArray labels,
OutputArray stats,//统计信息结构体
OutputArray centroids,
int connectivity,// 连通域,默认是8连通
int ltype, // 输出的labels类型,默认是CV_32S
int ccltype
)
相关的统计信息包括在输出stats的对象中,每个连通组件有一个这样的输出结构体。
CC_STAT_LEFT
Python: cv.CC_STAT_LEFT
连通组件外接矩形左上角坐标的X位置信息
CC_STAT_TOP
Python: cv.CC_STAT_TOP
连通组件外接左上角坐标的Y位置信息
CC_STAT_WIDTH
Python: cv.CC_STAT_WIDTH
连通组件外接矩形宽度
CC_STAT_HEIGHT
Python: cv.CC_STAT_HEIGHT
连通组件外接矩形高度
CC_STAT_AREA
Python: cv.CC_STAT_AREA
连通组件的面积大小,基于像素多少统计。
Centroids输出的是每个连通组件的中心位置坐标(x, y)
48.二值图像分析 – 轮廓发现
图像连通组件分析,可以得到二值图像的每个连通组件,但是我们还无法得知各个组件之间的层次关系与几何拓扑关系,如果我们需要进一步分析图像轮廓拓扑信息就可以通过OpenCV的轮廓发现API获取二值图像的轮廓拓扑信息,轮廓发现API如下:
void cv::findContours(
InputOutputArray image,
OutputArrayOfArrays contours,//检测到的轮廓,每个轮廓被表示成一个point向量
OutputArray hierarchy,//可选的输出向量,包含图像的拓扑信息。其中元素的个数和检测到的轮廓的数量相等
int mode,//说明需要的轮廓类型和希望的返回值方式
int method,//轮廓近似方法
Point offset = Point()
)
各个参数详解如下:
Image表示输入图像,必须是二值图像,二值图像可以threshold输出、Canny输出、inRange输出、自适应阈值输出等。
Contours获取的轮廓,每个轮廓是一系列的点集合
Hierarchy轮廓的层次信息,每个轮廓有四个相关信息,分别是同层下一个、前一个、第一个子节点、父节点
mode 表示轮廓寻找时候的拓扑结构返回
取值一:RETR_EXTERNAL只检测最外围轮廓,包含在外围轮廓内的内围轮廓被忽略
取值二:RETR_LIST 检测所有的轮廓,包括内围、外围轮廓,但是检测到的轮廓不建立等级关系,彼此之间独立,没有等级关系,这就意味着这个检索模式下不存在父轮廓或内嵌轮廓,所以hierarchy向量内所有元素的第3、第4个分量都会被置为-1,具体下文会讲到
取值三:RETR_CCOMP 检测所有的轮廓,但所有轮廓只建立两个等级关系,外围为顶层,若外围
内的内围轮廓还包含了其他的轮廓信息,则内围内的所有轮廓均归属于顶层
取值四:CV_RETR_TREE, 检测所有轮廓,所有轮廓建立一个等级树结构。外层轮廓包含内层轮廓,内
层轮廓还可以继续包含内嵌轮廓。
Method表示轮廓点集合取得是基于什么算法,常见的是基于CHAIN_APPROX_SIMPLE链式编码方法
对于得到轮廓,OpenCV通过下面的API绘制每个轮廓
void cv::drawContours(
InputOutputArray image,
InputArrayOfArrays contours,//检测到的轮廓,每个轮廓被表示成一个point向量
int contourIdx,//指定要绘制轮廓的编号,如果是负数,则绘制所有的轮廓
const Scalar & color,
int thickness = 1,//绘制轮廓的线的粗细,如果是负数,则轮廓内部被填充
int lineType = LINE_8,//8邻域的线型绘制,绘制轮廓的线的连通性
InputArray hierarchy = noArray(),//关于层级的可选参数,只有绘制部分轮廓时才会用到
int maxLevel = INT_MAX,//绘制轮廓的最高级别,这个参数只有hierarchy有效的时候才有效
//maxLevel=0,绘制与输入轮廓属于同一等级的所有轮廓即输入轮廓和与其相邻的轮廓
//maxLevel=1, 绘制与输入轮廓同一等级的所有轮廓与其子节点。
//maxLevel=2,绘制与输入轮廓同一等级的所有轮廓与其子节点以及子节点的子节点
Point offset = Point()
)
当thickness为正数的时候表示绘制该轮廓
当thickness为-1表示填充该轮廓
49.二值图像分析 – 轮廓外接矩形
对图像二值图像的每个轮廓,OpenCV都提供了API可以求取轮廓的外接矩形,其中求取轮廓外接矩形有两种方式,一种是可以基于像素的包覆此轮廓的最小正矩形,API解释如下:
Rect cv::boundingRect(
InputArray points
)
输入参数points可以一系列点的集合,对轮廓来说就是该轮廓的点集
返回结果是一个矩形,x, y, w, h
得到包覆轮廓的最小斜矩形API如下:
RotatedRect cv::minAreaRect(
InputArray points
)
输入参数points可以一系列点的集合,对轮廓来说就是该轮廓的点集
返回结果是一个旋转矩形,包含下面的信息:
- 矩形中心位置
- 矩形的宽高
- 旋转角度
Mat k = getStructuringElement(MORPH_RECT, Size(3, 3), Point(-1, -1));//形态学处理,获取结构化元素
dilate(binary, binary, k);//膨胀函数
50.二值图像分析 – 矩形面积与弧长计算
可以用于对目标图像进行筛选
对图像二值图像的每个轮廓,我们可以计算轮廓的弧长与面积,根据轮廓的面积与弧长可以实现对不同大小对象的过滤,寻找到我们感兴趣的roi区域,这个也是图像二值分析的任务之一。OpenCV对轮廓点集计算面积的API函数如下
double cv::contourArea(
InputArray contour,
bool oriented = false
)
计算轮廓的面积,其原理是基于格林公式。
参数contour表示输入的轮廓点集
参数oriented默认是false返回的面积是正数,如果方向参数为true表示会根据是顺时针或者逆时针方向返回正值或者负值面积。
double cv::arcLength(
InputArray curve,
bool closed
)
计算轮廓曲线的弧长。
参数curve表示输入的轮廓点集
参数closed默认表示是否闭合区域
51.二值图像分析 – 使用轮廓逼近
对图像二值图像的每个轮廓,可以使用轮廓逼近,逼近每个轮廓的真实几何形状,从而通过轮廓逼近的输出结果判断一个对象是什么形状。OpenCV轮廓逼近的API如下:
void cv::approxPolyDP(
InputArray curve,
OutputArray approxCurve,
double epsilon,
bool closed
)
其中:
Curve表示轮廓曲线
approxCurve 表示轮廓逼近输出的顶点数目
epsilon 轮廓逼近的顶点距离真实轮廓曲线的最大距离,该值越小表示越逼近真实轮廓
close 表示是否为闭合区域,1:闭合
52.二值图像分析 – 使用几何矩计算轮廓中心与横纵比过滤
对图像二值图像的每个轮廓,可以计算轮廓几何矩,根据几何矩可以计算图像的中心位置,估计得到中心位置可以计算中心矩、然后再根据中心矩可以计算胡矩。OpenCV中可以通过如下的API一次计算出上述三种矩,API如下:
Moments cv::moments(
InputArray array,
bool binaryImage = false
)
array是输入的图像轮廓点集合
输出的图像几何矩。
53.二值图像分析 – 使用Hu矩实现轮廓匹配
对图像二值图像的每个轮廓,可以计算轮廓几何矩,根据几何矩可以计算图像的中心位置,估计得到中心位置可以计算中心矩、然后再根据中心矩可以计算胡矩。OpenCV中可以通过如下的API一次计算出上述三种矩,API如下:
Moments cv::moments(
InputArray array,
bool binaryImage = false
)
array是输入的图像轮廓点集合
输出的图像几何矩,根据几何矩输出结果可以计算胡矩,胡矩计算的API如下:
void cv::HuMoments(
const Moments & moments,
double hu[7]
)
moments参数表示输入的图像矩
hu[7]表示输出的胡矩七个值:旋转不变性,空间尺度不变性
然后我们可以使用hu矩作为输入,对轮廓进行匹配,进行轮廓外形匹配的API如下:
double cv::matchShapes(
InputArray contour1,
InputArray contour2,
int method,
double parameter
)
返回值越小越相似,完全相同的图像返回值是0
contour1第一个轮廓点集合,或者灰度图像
contour2第二个轮廓点集合,或者灰度图像
method表示比较方法,最常见有
CONTOURS_MATCH_I1
CONTOURS_MATCH_I2
CONTOURS_MATCH_I3
Parameter方法声明的参数,OpenCV3.x版本中已经不需要了。
54.二值图像分析 – 对轮廓圆与椭圆拟合
可以用于轮廓缺陷检测
有时候我们需要对找到的轮廓点进行拟合,生成一个拟合的圆形或者椭圆,以便我们对轮廓进行更进一步的处理,满足我们对最终轮廓形状的判断,OpenCV对轮廓进行圆形或者椭圆拟合的API函数如下:
RotatedRect cv::fitEllipse(
InputArray points
)
参数points是轮廓点,
输出RotatedRect包含下面三个信息
- 拟合之后圆或者椭圆的中心位置、
- 长轴与短轴的直径
- 角度
然后我们就可以根据得到拟合信息绘制椭圆、当长轴与短轴相等的时候就是圆。
findContours(binary, contours, hierarchy, RETR_EXTERNAL, CHAIN_APPROX_SIMPLE, Point());//RETR_EXTERNAL:只寻找最外层的轮廓
ellipse(src, rrt, Scalar(0, 0, 255), 2, 8);//第四个参数2:线宽,-1:表示填充
55.二值图像分析 – 凸包检测
可用于传统手势识别
对二值图像进行轮廓分析之后,对获取到的每个轮廓数据,可以构建每个轮廓的凸包,构建完成之后会返回该凸包包含的点集。根据返回的凸包点集可以绘制该轮廓对应的凸包。OpenCV对轮廓提取凸包的API函数如下:
void cv::convexHull(
InputArray points,
OutputArray hull,
bool clockwise = false,
bool returnPoints = true
)
points参数是输入的轮廓点集
hull凸包检测的输出结果,当参数returnPoints为ture的时候返回凸包的顶点坐标是个点集、returnPoints为false的是返回的是一个integer的vector里面是凸包各个顶点在轮廓点集对应的index索引
clockwise 表示顺时针方向或者逆时针方向
returnPoints表示是否返回点集
OpenCV中的凸包寻找算法是基于Graham’s扫描法。
OpenCV中还提供了另外一个API函数用来判断一个轮廓是否为凸包,该方法如下:
bool cv::isContourConvex(
InputArray contour
)
该方法只有一个输入参数就是轮廓点集。
56.二值图像分析 – 直线拟合与极值点寻找
对轮廓进行分析,除了可以对轮廓进行椭圆或者圆的拟合之外,还可以对轮廓点集进行直线拟合,直线拟合的算法有很多,最常见的就是最小二乘法,对于多约束线性方程,最小二乘可以找好直线方程的两个参数、实现直线拟合,OpenCV中直线拟合正是基于最小二乘法实现的。OpenCV实现直线拟合的API如下:
void cv::fitLine(
InputArray points,
OutputArray line,
int distType,
double param,
double reps,
double aeps
)
points表示待拟合的输入点集合
line在二维拟合时候输出的是vec4f类型的数据,在三维拟合的时候输出是vec6f的vector
distType表示在拟合时候使用距离计算公式是哪一种,OpenCV支持如下六种方式:
DIST_L1 = 1
DIST_L2 = 2
DIST_L12 = 4
DIST_FAIR = 5
DIST_WELSCH = 6
DIST_HUBER = 7
param对模型拟合距离计算公式需要参数C,5~7 distType需要参数C
reps与aeps是指对拟合结果的精度要求
57.二值图像分析 – 点多边形测试
判断点在多边形的内部、外部、轮廓上,可用于检测一个对象相对于轮廓的位置关系,比如越界检测。
对于轮廓图像,有时候还需要判断一个点是在轮廓内部还是外部,OpenCV中实现这个功能的API叫做点多边形测试,它可以准确的得到一个点距离多边形的距离,如果点是轮廓点或者属于轮廓多边形上的点,距离是零,如果是多边形内部的点是是正数,如果是负数返回表示点是外部。表示如下:
double cv::pointPolygonTest(
InputArray contour,
Point2f pt,
bool measureDist
)
Contour轮廓所有点的集合
Pt 图像中的任意一点
MeasureDist如果是True,则返回每个点到轮廓的距离,如果是False则返回+1,0,-1三个值,其中+1表示点在轮廓内部,0表示点在轮廓上,-1表示点在轮廓外
58.二值图像分析 – 寻找最大内接圆
对于轮廓来说,有时候我们会需要选择最大内接圆,OpenCV中没有现成的API可以使用,但是我们可以通过点多边形测试巧妙的获取轮廓最大内接圆的半径,从点多边形测试的返回结果我们知道,它返回的是像素距离,而且是当前点距离轮廓最近的距离,当这个点在轮廓内部,其返回的距离是最大值的时候,其实这个距离就是轮廓的最大内接圆的半径,这样我们就巧妙的获得了圆心的位置与半径,剩下的工作就很容易了完成,绘制一个圆而已,一行代码就可以搞定,而且前面我们的知识点分享已经交代了如何在OpenCV中去绘制常见几何形状啦。需要特别说明一下的这个估计在OpenCV3.4.x之后的版本中可能会有出现在opencv官方的tutorial中。
59.二值图像分析 – 霍夫直线检测
霍夫检测对噪声比较敏感,适合检测比较大的明显的直线
图像霍夫变换是一种特别有用的图像变换,通过把图像的坐标从2D平面坐标系变换到极坐标空间,可以发现原来在平面坐标难以提取的几何特征信息(如:直线、圆等),图像的直线与圆检测就是典型的利用霍夫空间特性实现二值图像几何分析的例子。假设有如下的直线参数方程:
r = x*cos(theta) + y * sin(theta)
其中角度theta指r与X轴之间的夹角,r为到直线几何垂直距离。
OpenCV关于霍夫直线检测有两个API,我们首先分享第一个函数,它是提取到直线在霍夫空间的几何特征,然后输出直线得两个极坐标参数。根据这两个参数我们可以组合得到空间坐标直线。该API如下:
void cv::HoughLines(
InputArray image,
OutputArray lines,
double rho,
double theta,
int threshold,
double srn = 0,
double stn = 0,
double min_theta = 0,
double max_theta = CV_PI
)
霍夫变换前需要去噪和二值化,它对噪声比较敏感
Image 输入二值图像
Lines 输出直线
Rho 极坐标r得步长
Theta角度步长
Threshold累加器阈值
Srn、stn多尺度霍夫变换时候需要得参数,经典霍夫变换不需要
min_theta 最小角度
max_theta最大角度
60.二值图像分析 – 霍夫直线检测二
霍夫检测对噪声比较敏感,需要先去噪
OpenCV中还有另外一个霍夫直线检测的API,该API更为常用,它会直接返回直线的空间坐标点,比返回霍夫空间参数更加的直观,容易理解,而且还可以声明线段长度、间隔等参数,非常有用。该参数详解如下:
void cv::HoughLinesP(
InputArray image,
OutputArray lines,
double rho,
double theta,
int threshold,
double minLineLength = 0,
double maxLineGap = 0
)
Image输入二值图像
Lines 返回的直线两个点
Rho 极坐标r得步长
Theta角度步长
Threshold累加器阈值
minLineLength最小线段长度
maxLineGap 允许最大线段间隔像素
61.二值图像分析 – 霍夫圆检测
霍夫检测对噪声比较敏感,需要先去噪
根据极坐标,圆上任意一点的坐标可以表示为如上形式, 所以对于任意一个圆, 假设中心像素点p(x0, y0)像素点已知, 圆半径已知,则旋转360由极坐标方程可以得到每个点上得坐标同样,如果只是知道图像上像素点, 圆半径,旋转360°则中心点处的坐标值必定最强.这正是霍夫变换检测圆的数学原理
X = x0+rcos(theta)
Y = y0+rsin(theta)
OpenCV中霍夫圆检测的API与参数解释如下:
void cv::HoughCircles(
InputArray image,
OutputArray circles,
int method,
double dp,
double minDist,
double param1 = 100,
double param2 = 100,
int minRadius = 0,
int maxRadius = 0
)
image表示输入单通道的灰度图像
circles 表示检测的圆信息(圆心+半径)
method 圆检测的方法:霍夫梯度
dp表示图像分辨率是否有变化,默认1表示保持跟原图大小一致, 在其它参数保持不变的情况下。dp的取值越高,越容易检测到圆,
minDist表示检测到的圆,两个圆心之间的最小距离:最小为10
param1 表示边缘提取的高阈值
param2表示霍夫空间的累加阈值
minRadius 表示可以检测圆的最小半径
maxRadius 表示可以检测圆的最大
62.图像形态学 - 膨胀与腐蚀
膨胀与腐蚀是图像形态学最基础的两个操作,形态学的其它操作都是基于这两个操作基础上得到的,图像形态学是二值图像分析的重要分支学科。在OpenCV中膨胀与腐蚀对应两个相关的API,膨胀可以看成是最大值滤波,即用最大值替换中心像素点;腐蚀可以看出是最小值滤波,即用最小值替换中心像素点。
膨胀的API如下:
void cv::dilate(
InputArray src,
OutputArray dst,
InputArray kernel,
Point anchor = Point(-1,-1),
int iterations = 1,
int borderType = BORDER_CONSTANT,0:常数填充
const Scalar & borderValue = morphologyDefaultBorderValue()
)
src 输入图像,任意通道的
dst 输出图像,类型与通道数目必须跟输入保持一致
kernel 结构元素
anchor 中心位置锚定
iterations 循环次数
borderType 边缘填充类型
腐蚀的API如下:
void cv::erode(
InputArray src,
OutputArray dst,
InputArray kernel,
Point anchor = Point(-1,-1),
int iterations = 1,
int borderType = BORDER_CONSTANT,
const Scalar & borderValue = morphologyDefaultBorderValue()
)
src 输入图像,任意通道的
dst 输出图像,类型与通道数目必须跟输入保持一致
kernel 结构元素
anchor 中心位置锚定
iterations 循环次数
borderType 边缘填充类型
// 定义结构元素 3x3大小矩形
Mat se = getStructuringElement(MORPH_RECT, Size(3, 3), Point(-1, -1));
MORPH_RECT:获取矩形类型的结构元素
63.图像形态学 - 膨胀与腐蚀
膨胀与腐蚀操作不仅可以对二值图像有效操作,对彩色与灰度图像也有作用,对于二值图像的腐蚀与膨胀来说,选择一个好的结构元素至关重要,OpenCV中获取结构元素的API与参数解释如下:
Mat cv::getStructuringElement(
int shape,
Size ksize,
Point anchor = Point(-1,-1)
)
shape是指结构元素的类型,常见的有矩形、圆形、十字交叉:矩形:MORPH_RECT,交叉形:MORPH_CROSS,椭圆形:MORPH_ELLIPSE;
ksize 是指结构元素大小
anchor 中心锚点的位置
64.图像形态学 – 开操作
形态学的开操作是基于腐蚀与膨胀两个操作的组合实现的
开操作 = 腐蚀 + 膨胀
开操作的作用:
开操作可以删除二值图像中小的干扰块,降低图像二值化之后噪点过多的问题,
void cv::morphologyEx(
InputArray src,
OutputArray dst,
int op,
InputArray kernel,
Point anchor = Point(-1,-1),
int iterations = 1,
int borderType = BORDER_CONSTANT,
)
src 输入图像:任意图像
dst 输出图像
op 形态学操作:开或闭操作
kernel 结构元素:常见的有矩形、圆形、十字交叉
anchor 中心位置锚定
iterations 循环次数
borderType 边缘填充类型
其中op指定为MORPH_OPEN 即表示使用开操作
65.图像形态学 – 闭操作
形态学的闭操作跟开操作一样也是基于腐蚀与膨胀两个操作的组合实现的
闭操作 = 膨胀 + 腐蚀
闭操作的作用:
闭操作可以填充二值图像中孔洞区域,形成完整的闭合区域连通组件
void cv::morphologyEx(
InputArray src,
OutputArray dst,
int op,
InputArray kernel,
Point anchor = Point(-1,-1),
int iterations = 1,
int borderType = BORDER_CONSTANT,
)
src 输入图像
dst 输出图像
op 形态学操作
kernel 结构元素
anchor 中心位置锚定
iterations 循环次数
borderType 边缘填充类型
其中op指定为MORPH_CLOSE 即表示使用闭操作
开闭操作后如果有局部处理不好的地方,可以再尝试变换另外一种结构元素来操作,比如十字交叉对闭操作后出现矩形的区域有好的效果。
66.图像形态学 – 开闭操作时候结构元素应用演示
OpenCV中图像形态学开操作与闭操作,根据结构元素的不同可以实现不同的二值图像处理效果,我们可以通过下面的结构元素对图像进行开操作,提取二值图像中水平与垂直线,这个方法比霍夫直线检测要好用得多, 在一些应用场景中会特别有用,图像分析、OCR布局分析中形态学操作十分重要,我们通过两个例子来说明开闭操作的作用。
一, 开操作提取水平线,实现填空题横线位置提取
结构元素大小为20x1
第一张图与第二张图,是开操作提取填空题中水平横线的操作,其步骤分为:
- 转灰度
- 转二值,可选降噪
- 形态学操作,提取水平线
- 轮廓发现,确定位置
二, 闭操作实现不同层次的轮廓填充
结构元素分为两种:
矩形结构元素25x25大小
圆形结构元素15x15大小
第三张图、第四张图像对应闭操作的相关运行结果。
67.图像形态学 – 顶帽操作
找出开操作消失的部分,比如微小的部分、噪声
形态学的顶帽操作是图像输入与开操作之间的差异,顶帽操作有时候对于我们提取图像中微小部分特别有用,顶帽操作:
顶帽 = 原图 – 开操作
void cv::morphologyEx(
InputArray src,
OutputArray dst,
int op,
InputArray kernel,
Point anchor = Point(-1,-1),
int iterations = 1,
int borderType = BORDER_CONSTANT,
)
src 输入图像
dst 输出图像
op 形态学操作
kernel 结构元素
anchor 中心位置锚定
iterations 循环次数
borderType 边缘填充类型
其中op指定为MORPH_TOPHAT 即表示使用顶帽操作
68.图像形态学 – 黑帽操作
黑帽运算之后的效果图突出了与原图像轮廓周围的区域更暗的区域,且这一操作和选择的核大小相关。所以黑帽运算用来分离比邻近点暗一些的斑块。
形态学的黑帽操作是闭操作与输入图像之间的差异,黑帽操作可以表示如下:
黑帽操作 = 闭操作 – 输入图像
void cv::morphologyEx(
InputArray src,
OutputArray dst,
int op,
InputArray kernel,
Point anchor = Point(-1,-1),
int iterations = 1,
int borderType = BORDER_CONSTANT,
)
src 输入图像
dst 输出图像
op 形态学操作
kernel 结构元素
anchor 中心位置锚定
iterations 循环次数
borderType 边缘填充类型
其中op指定为MORPH_BLACKHAT即表示使用顶帽操作
69.图像形态学 – 图像梯度
找出微小的差异地方
图像形态学的梯度跟我们前面介绍的图像卷积计算出来的梯度有本质不同,形态学梯度可以帮助我们获得连通组件的边缘与轮廓,实现图像轮廓或者边缘提取。根据使用的形态学操作不同,形态学梯度又分为
- 基本梯度
- 内梯度
- 外梯度
基本梯度是图像膨胀与腐蚀操作之间的差值
内梯度是输入图像与腐蚀之间的差值
外梯度是膨胀与输入图像之间的差值
void cv::morphologyEx(
InputArray src,
OutputArray dst,
int op,
InputArray kernel,
Point anchor = Point(-1,-1),
int iterations = 1,
int borderType = BORDER_CONSTANT,
)
src 输入图像
dst 输出图像
op 形态学操作
kernel 结构元素
anchor 中心位置锚定
iterations 循环次数
borderType 边缘填充类型
其中op指定为MORPH_GRADIEN即表示使用基本梯度操作,MORPH_DILATE:膨胀,MORPH_ERODE:腐蚀。
70.形态学应用 – 使用基本梯度实现轮廓分析
图像的效果不是特别清晰,通过形态学梯度实现图像二值化
基于形态学梯度实现图像二值化,进行文本结构分析是OCR识别中常用的处理手段之一,这种好处比简单的二值化对图像有更好的分割效果,主要步骤如下:
- 图像形态学梯度
- 灰度
- 全局阈值二值化
- 轮廓分析
71.形态学操作 – 击中击不中
形态学的击中击不中操作,根据结构元素不同,可以提取二值图像中的一些特殊区域,得到我们想要的结果。击中击不中操作的API也是我们前面一直用的API,只是对OP参数的修改
void cv::morphologyEx(
InputArray src,
OutputArray dst,
int op,
InputArray kernel,
Point anchor = Point(-1,-1),
int iterations = 1,
int borderType = BORDER_CONSTANT,
)
src 输入图像
dst 输出图像
op 形态学操作
kernel 结构元素
anchor 中心位置锚定
iterations 循环次数
borderType 边缘填充类型
其中op指定为MORPH_HITMISS即表示使用击中击不中
72.二值图像分析 – 缺陷检测一
大家好,我们这周打算分享二值图像分析的案例,通过这些案例知识把前面所学的知识点串联起来使用,实现有一定工业实用价值的代码。今天这个也是别人问我的,分为两个部分,一个部分是提取指定的轮廓,第二个部分通过对比实现划痕检测与缺角检测。本次分享主要搞定第一部分,学会观察图像与提取图像ROI对象轮廓外接矩形与轮廓。
findContours(binary, contours, hierarchy, RETR_LIST, CHAIN_APPROX_SIMPLE);//轮廓提取,CV_RETR_LIST:检测所有的轮廓,包括内围、外围轮廓
73.二值图像分析 – 缺陷检测二
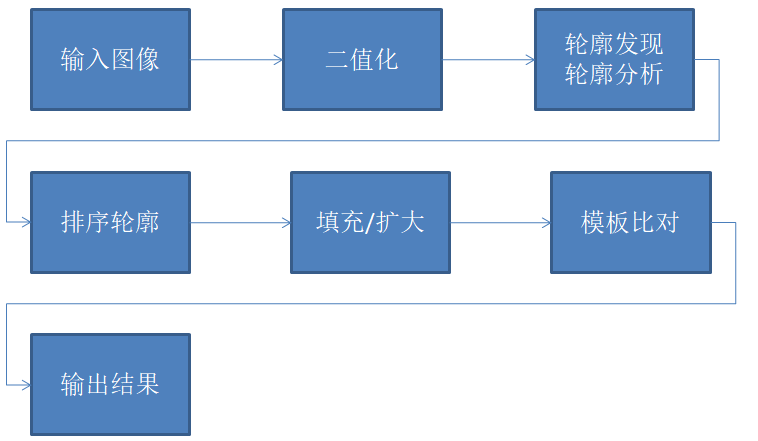
对于得到的刀片外接矩形,首先需要通过排序,确定他们的编号,然后根据模板进行相减得到与模板不同的区域,对这些区域进行形态学操作,去掉边缘细微差异,最终就得到了可以检出的缺陷或者划痕刀片。检测流程如下:
本程序检测出有缺陷的对象,并且对其进行编号和标记
74.二值图像分析 – 提取最大轮廓与编码关键点
这个问题来自大概四年前一个网友问我得,他需要提取星云的面积,做一些计算,其实在图像二值化的时候,我们需要考虑下面的因素,二值化方法选择:
全局阈值二值化
基于形态学梯度二值化
inRange二值化
基于Canny边缘二值化
自适应二值化
我们在二值化方法选择上选择了全局阈值(希望大家可以尝试更多不同二值化方法做对比),得到二值图像,然后进行轮廓分析,根据面积寻找最大轮廓,然后根据轮廓进行多边形逼近,获得轮廓关键点,最后可以绘制轮廓与关键点。
75.图像去水印/修复
在OpenCV中有时候我们需要一个批量的去水印的方法,这个在很多时候需要用到,对得到图像进行批量的去水印,其本质上是一种图像修复,OpenCV也提供一个图像修复的API,可以部分解决这里问题,
void cv::inpaint(
InputArray src,
InputArray ipaintMask,表示修复模板
OutputArray dst
double inpaintRadius,表示修复的半径
int fags
)
opencv提供了两种选择 INPAINT_TELEA 和 INPAINT_NS
基于Navier-Stokes的修复方法
基于图像梯度的快速匹配方法又称(Telea法)
76.图像透视变换应用
应用于图像的倾斜矫正
对于很多的文本扫描图像,有时候因为放置的原因导致ROI区域倾斜,这个时候我们会想办法把它纠正为正确的角度视角来,方便下一步的布局分析与文字识别,这个时候通过透视变换就可以取得比较好的裁剪效果,一步就可以实现裁剪与调整。使用透视变换相关几何变换的好处如下:
- 透视变换不会涉及到几何变换角度旋转
- 透视变换对畸变图像有一定的展开效果
- 透视变换可以完成对图像ROI区域提取
77.视频读写与处理
OpenCV中对视频内容的处理本质上对读取视频的关键帧进行解析图像,然后对图像进行各种处理,OpenCV的VideoCapture是一个视频读取与解码的API接口,支持各种视频格式、网络视频流、摄像头读取。正常的视频处理与分析,主要是针对读取到每一帧图像,衡量一个算法处理是否能够满足实时要求的时候通常通过FPS(每秒多少帧的处理能力)。一般情况下每秒大于5帧基本上可以认为是在进行视频处理。
int fps = capture.get(CAP_PROP_FPS);
int width = capture.get(CAP_PROP_FRAME_WIDTH);
int height = capture.get(CAP_PROP_FRAME_HEIGHT);
int num_of_frames = capture.get(CAP_PROP_FRAME_COUNT);
78.识别与跟踪视频中的特定颜色对象
这个是其实图像处理与二值分析的视频版本,通过读取视频每一帧的图像,然后对图像二值分析,得到指定的色块区域,主要步骤如下:
- 色彩转换BGR2HSV
- inRange提取颜色区域mask
- 对mask区域进行二值分析得到位置与轮廓信息
- 绘制外接椭圆与中心位置
- 显示结果
其中涉及到的知识点主要包括图像处理、色彩空间转换、形态学、轮廓分析等。
79.视频分析 - 背景/前景 提取
视频场景分析中最常用的技术之一就是通过背景消除来提取前景移动对象,得到前景的对象mask图像,最常用的背景消除技术就是通过帧差相减,用前面一帧作为背景图像,与当前帧进行相减,不过这种方法对光照与噪声影响非常敏感,所有好的办法是通过对前面一系列帧提取背景模型进行相减,OpenCV中实现的背景模型提取算法有两种,一种是基于高斯混合模型GMM实现的背景提取,另外一种是基于最近邻KNN实现的。都有相关的API可以供开发者使用。相关API
Ptr cv::createBackgroundSubtractorMOG2(
int history = 500,
double varThreshold = 16,
bool detectShadows = true
)
参数解释如下:
history表示过往帧数,500帧,选择history = 1就变成两帧差
varThreshold表示像素与模型之间的马氏距离,值越大,只有那些最新的像素会被归到前景,值越小前景对光照越敏感。
detectShadows 是否保留阴影检测,请选择False这样速度快点。
创建
Ptr pBackSub = createBackgroundSubtractorMOG2();
Ptr pBackSub = createBackgroundSubtractorKNN();
80.视频分析 – 背景消除与前景ROI提取
通过视频中的背景进行建模,实现背景消除,生成mask图像,通过对mask二值图像分析实现对前景活动对象ROI区域的提取,是很多视频监控分析软件常用的手段之一,该方法很实时!整个步骤如下:
- 初始化背景建模对象GMM
- 读取视频一帧
- 使用背景建模消除生成mask
- 对mask进行轮廓分析提取ROI
- 绘制ROI对象
81.角点检测 – Harris角点检测
计算速度慢,计算输出没有排序,需要手动输入阈值
角点是一幅图像上最明显与重要的特征,对于一阶导数而言,角点在各个方向的变化是最大的,而边缘区域在只是某一方向有明显变化
OpenCV中相关API与解释如下:
void cv::cornerHarris(
InputArray src,
OutputArray dst,
int blockSize,
int ksize,
double k,
int borderType = BORDER_DEFAULT
)
src单通道输入图像
dst是输出response
blockSize计算协方差矩阵的时候邻域像素大小
ksize表示soble算子的大小
k表示系数,:0.04-0.06
82.角点检测 – shi-tomas角点检测
Harris角点检测是一种计算速度很慢的角点检测算法,很难实时计算,所有最常用的是shi-tomas角点检测算法,它的运行速度很快。
OpenCV中相关API与解释如下:
void cv::goodFeaturesToTrack(
InputArray image,
OutputArray corners,
int maxCorners,
double qualityLevel,
double minDistance,
InputArray mask = noArray(),
int blockSize = 3,
bool useHarrisDetector = false,
double k = 0.04
)
src:单通道输入图像,八位或者浮点数
corners:是输出的关键点坐标集合
maxCorners:表示最大返回关键点数目
qualityLevel:表示拒绝的关键点 R < 小于qualityLevel × max response将会被直接丢弃
minDistance :表示两个关键点之间的最短距离:5或者10个
mask: 表示mask区域,如果有表明只对mask区域做计算
blockSize: 计算梯度与微分的窗口区域
useHarrisDetector: 表示是否使用harris角点检测,默认是false 为shi-tomas
k = 0.04默认值,当useHarrisDetector为ture时候起作用
83.角点检测 – 亚像素级别角点检测
用于更精准的特征匹配
OpenCV中角点检测的结果实际不够精准,因为真实的计算中有些位置可能是在浮点数的空间内才最大值,这样就需要我们通过给定的响应值,在像素邻域空间进行拟合,实现亚像素级别的角点检测。OpenCV中相关API与解释如下:
void cv::cornerSubPix(
InputArray image,
InputOutputArray corners,
Size winSize,
Size zeroZone,
TermCriteria criteria
)
image单通道输入图像,八位或者浮点数
corners是输入输出的关键点坐标集合
winSize表示插值计算时候窗口大小
zeroZone表示搜索区域中间的dead region边长的一半,有时用于避免自相关矩阵的奇异性。如果值设为(-1,-1)则表示没有这个区域。
criteria角点精准化迭代过程的终止条件
84.视频分析 - 移动对象的KLT光流跟踪算法
光流跟踪方法分为稠密光流跟踪与稀疏光流跟踪算法,KLT是稀疏光流跟踪算法,这个算法最早是由Bruce D. Lucas and Takeo Kanade两位作者提出来的,所以又被称为KLT。稀疏光流算法工作有三个假设前提条件:
- 亮度恒定
- 短距离移动
- 空间一致性:视场不能偏移、移动和改变尺寸
OpenCV中KLT算法API及其参数解释如下:
void cv::calcOpticalFlowPyrLK(
InputArray prevImg, // 前一帧图像
InputArray nextImg, // 后一帧图像
InputArray prevPts, // 前一帧的稀疏光流点
InputOutputArray nextPts, // 后一帧光流点
OutputArray status, // 输出状态,1 表示正常该点保留,否则丢弃
OutputArray err, // 表示错误
Size winSize = Size(21, 21), // 光流法对象窗口大小
int maxLevel = 3, // 金字塔层数,0表示只检测当前图像,不构建金字塔图像
TermCriteria criteria = TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, 0.01), // 窗口搜索时候停止条件:30次,差异小于0.01了
int flags = 0, // 操作标志
double minEigThreshold = 1e-4 // 最小特征值响应,低于最小值不做处理
)
85.视频分析KLT光流跟踪02 - 删除静止点与绘制跟踪轨迹
光流跟踪方法分为稠密光流跟踪与稀疏光流跟踪算法,KLT是稀疏光流跟踪算法,这个算法最早是由Bruce D. Lucas and Takeo Kanade两位作者提出来的,所以又被称为KLT。稀疏光流算法工作有三个假设前提条件:
- 亮度恒定
- 短距离移动
- 空间一致性
OpenCV中KLT算法API及其参数解释如下:
void cv::calcOpticalFlowPyrLK(
InputArray prevImg, // 前一帧图像
InputArray nextImg, // 后一帧图像
InputArray prevPts, // 前一帧的稀疏光流点
InputOutputArray nextPts, // 后一帧光流点
OutputArray status, // 输出状态,1 表示正常该点保留,否则丢弃
OutputArray err, // 表示错误
Size winSize = Size(21, 21), // 光流法对象窗口大小
int maxLevel = 3, // 金字塔层数,0表示只检测当前图像,不构建金字塔图像
TermCriteria criteria = TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, 0.01), // 窗口搜索时候停止条件
int flags = 0, // 操作标志
double minEigThreshold = 1e-4 // 最小特征值响应,低于最小值不做处理
)
在84的知识点分享中我们已经可以跟踪到前后两帧之前的位置移动,但是这个还不足够,我们需要绘制移动对象从初始到最终的完整可以检测的运动轨迹,同时对一些静止的角点进行删除,所以我们需要对状态为1的角点,计算它们之间的距离,只有dx+dy>2(dx=abs(p1.x –p2.x), dy=abs(p1.y-p2.y))的我们才对它进行保留跟踪。
86.视频分析 – 稠密光流分析
是基于前后两帧所有像素点的移动估算算法,其效果要比稀疏光流算法更好
光流跟踪方法分为稠密光流跟踪与稀疏光流跟踪算法,KLT是稀疏光流跟踪算法,前面我们已经介绍过了,OpenCV还支持稠密光流的移动对象跟踪方法,OpenCV中支持的稠密光流算法是由Gunner Farneback在2003年提出来的,它是基于前后两帧所有像素点的移动估算算法,其效果要比稀疏光流算法更好,相关的API如下:
void cv::calcOpticalFlowFarneback(
InputArray prev,
InputArray next,
InputOutputArray flow,输入输出
double pyr_scale,
int levels,
int winsize,
int iterations,
int poly_n,
double poly_sigma,
int flags
)
prev 前一帧
next 后一帧
flow 光流,计算得到的移动能量场
pyr_scale 金字塔放缩比率:一般是1/2
levels 金字塔层级数目
winsize 表示窗口大小:窗口越大计算越慢
iterations 表示迭代次数:一般1或2次
poly_n 表示光流生成时候,对邻域像素的多项式展开,n越大越模糊越稳定
poly_sigma 表示光流多项式展开时候用的高斯系数,n越大,sigma应该适当增加
flags有两个:
0:OPTFLOW_USE_INITIAL_FLOW表示使用盒子模糊进行初始化光流
256:OPTFLOW_FARNEBACK_GAUSSIAN表示使用高斯窗口
87.视频分析 – 基于帧差法实现移动对象分析
跟踪移动的对象帧差法比光流法更好
光流跟踪与背景消除都是基于建模方式的视频分析方法,其实这类方法最原始的一个例子就是对视频移动对象的帧差法跟踪,这个在视频分析与处理中也是一种很常见的手段,有时候会取得意想不到的好效果,帧差法进一步划分有可以分为
- 两帧差
- 三帧差
假设有当前帧frame, 前一帧prev1,更前一帧prev2
两帧差方法直接使用前一帧 减去当前帧 diff = frame – prev1
三帧差方法计算如下:
diff1 = prev2 – prev1
diff2 = frame – prev1
diff = diff1 & diff2
帧差法在求取帧差之前一般会进行高斯模糊,用以减低干扰,通过得到的diff图像进行形态学操作,用以合并与候选区域,提升效率。帧差法的缺点有如下:
- 高斯模糊是高耗时计算:减少光线的干扰,sigma不能太大,不然会更耗时
GaussianBlur(preGray, preGray, Size(0, 0), 15);sigma取15
- 容易受到噪声与光线干扰
88.视频分析 – 基于均值迁移的对象移动分析
缺陷:对象大小变化,搜索窗口大小没有变化
可以继续跟踪消失后再出现的对象
均值迁移移动对象分析,主要是基于直方图分布与反向投影实现移动对象的轨迹跟踪,其核心的思想是对反向投影之后的图像做均值迁移(meanshift)从而发现密度最高的区域,也是对象分布最大的区域。完整的算法流程如下:
1, 读取图像一帧转为HSV
2, HSV直方图
3, 反向投影该帧,需要根据实际情况修改反向投影的低值和高值
inRange(hsv, Scalar(26, 43, 46), Scalar(34, 255, 255), mask);
4, 使用means shift寻找最大分布密度
5, 更新窗口直至最后一帧
OpenCV中meanshift的API函数如下:
int cv::meanShift(
InputArray probImage,
Rect & window,
TermCriteria criteria
)
probImage输入图像,是直方图反向投影的结果
window 搜索窗口,ROI对象区域
criteria 均值迁移停止条件
89.视频分析 – 基于连续自适应均值迁移(CAM)的对象移动分析
对消失后再出现的对象跟踪有良好效果
CAM是连续自适应的均值迁移跟踪算法,它跟均值迁移相比较有两个改进
- 会根据跟踪对象大小变化自动调整搜索窗口大小
- 返回位置信息更加完整,包含了位置与角度信息
OpenCV中CAMShift的API函数如下:
RotatedRect cv::CamShift(
InputArray probImage,
Rect & window,
TermCriteria criteria
)
probImage输入图像,是直方图反向投影的结果
window 搜索窗口,ROI对象区域
criteria 均值迁移停止条件
RotatedRect:返回跟踪结果信息:中心位置,角度等
特别需要注意的是:
C++版本中会自动更新搜索窗口,
Python语言版本中必须每次从返回信息中手动更新。
90.视频分析 –对象移动轨迹绘制
移动对象分析,我们可以绘制对象运行轨迹曲线,这个主要是根据移动对象窗口轮廓,获取中心位置,然后使用中心位置进行绘制即可得到。大致的程序步骤如下:
- 初始化路径点数组
- 对每帧的预测轮廓提取中心位置添加到路径数组
- 绘制路径曲线
91.对象检测 – HAAR级联检测器使用
HAAR级联检测器,OpenCV中的HAAR级联检测器支持人脸检测、微笑、眼睛与嘴巴检测等,通过加载这些预先训练的HAAR模型数据可以实现相关的对象检测,
void cv::CascadeClassifier::detectMultiScale(
InputArray image,
std::vector< Rect > & objects,
double scaleFactor = 1.1,
int minNeighbors = 3,
int flags = 0,
Size minSize = Size(),
Size maxSize = Size()
)
各个参数解释如下:
Image:输入图像
Objects 人脸框
ScaleFactor 放缩比率
minNeighbors 表示最低相邻矩形框
flags 标志项OpenCV3.x以后不用啦,
minSize 可以检测的最小人脸
maxSize 可以检测的最大人脸
// String haar_data_file = "./opencv_tutorial/data/haarcascades/haarcascade_frontalface_alt_tree.xml";
// String haar_data_file = "./opencv_tutorial/data/haarcascades/haarcascade_frontalface_alt.xml";
String haar_data_file = "./opencv_tutorial/data/haarcascades/haarcascade_frontalface_alt2.xml";//这个效果会好点
equalizeHist(gray, gray);//直方图均衡化,增强梯度,提高检出率
92.对象检测-HAAR特征介绍
HAAR小波基函数,因为其满足对称性,对人脸这种生物对称性良好的对象特别适合用来做检测器,常见的Haar特征分为三类:
边缘特征、
线性特征、
中心特征和对角线特征,
不同特征可以进行多种组合,生成更加复杂的级联特征,特征模板内有白色和黑色两种矩形,并定义该模板的特征值为白色矩形像素和减去黑色矩形像素和,Haar特征值反映了图像的对比度与梯度变化。
OpenCV中HAAR特征计算是积分图技术,这个我们在前面也分享过啦,所以可以非常快速高效的开窗检测, HAAR级联检测器具备有如下特性:
- 高类间变异性
- 低类内变异性
- 局部强度差
- 不同尺度
- 计算效率高
93.对象检测-LBP特征介绍
可以看成另类的图像梯度特征提取,运算速度比HAAR快,并且更高效
局部二值模式(Local Binary Pattern)主要用来实现2D图像纹理分析。其基本思想是用每个像素跟它周围的像素相比较得到局部图像结构,假设中心像素值大于相邻像素值则则相邻像素点赋值为1,否则赋值为0,最终对每个像素点都会得到一个二进制八位的表示,比如11100111。假设3x3的窗口大小,这样对每个像素点来说组合得到的像素值的空间为[0~2^8]。这种结果称为图像的局部二值模式或者简写为了LBP。
PS: 仔细看第一张图就明白LBP是如何计算!
另外推荐看一下我以前的文章:
详解LBP特征与应用(人脸识别)
94.ORB FAST特征关键点检测
ORB - (Oriented Fast and Rotated BRIEF)算法是基于FAST特征检测与BRIEF特征描述子匹配实现,相比BRIEF算法中依靠随机方式获取而值点对,ORB通过FAST方法,FAST方式寻找候选特征点方式是假设灰度图像像素点A周围的像素存在连续大于或者小于A的灰度值,选择任意一个像素点P,假设半径为3,周围16个像素表示
则像素点P被标记为候选特征点、通常N取值为9、12,上图N=9。
为了简化计算,我们可以只计算1、9、5、13四个点,至少其中三个点满足上述不等式条件,即可将P视为候选点。然后通过阈值进行最终的筛选即可得到ORB特征点
static Ptr cv::ORB::create (
int nfeatures = 500,
float scaleFactor = 1.2f,
int nlevels = 8,
int edgeThreshold = 31,
int firstLevel = 0,
int WTA_K = 2,
ORB::ScoreType scoreType = ORB::HARRIS_SCORE,
int patchSize = 31,
int fastThreshold = 20
)
nfeatures 最终输出最大特征点数目
scaleFactor 金字塔上采样比率
nlevels 金字塔层数
edgeThreshold 边缘阈值
firstLevel= 0
WTA_K这个是跟BRIEF描述子用的
scoreType 对所有的特征点进行排名用的方法
auto orb_detector = ORB::create(1000);//orb_detector类型声明为自动匹配,create第一个参数设置为1000,其他参数为默认值
95.BRIEF特征描述子 匹配
得到特征点数据之后,根据BRIEF算法就可以建立描述子。选择候选特征点周围SxS大小的像素块、随机选择n对像素点。其中P(x)是图像模糊处理之后的像素值,原因在于高斯模糊可以抑制噪声影响、提供特征点稳定性,在实际代码实现中通常用均值滤波替代高斯滤波以便利用积分图方式加速计算获得更好的性能表现。常见滤波时候使用3x3~9x9之间的卷积核。滤波之后,根据上述描述子的生成条件,得到描述子。
作者论文提到n的取值通常为128、256或者512。得到二进制方式的字符串描述子之后,匹配就可以通过XOR方式矩形,计算汉明距离。ORB特征提取跟纯BRIEF特征提取相比较,BRIEF方式采用随机点方式得最终描述子、而ORB通过FAST得到特征点然后得到描述子。
流程如下:

96.描述子匹配
图像特征检测首先会获取关键点,然后根据关键点周围像素ROI区域的大小,生成描述子,完整的描述子向量就表示了一张图像的特征,是图像特征数据,这种方式也被称为图像特征工程,即通过先验模型与合理计算得到图像特征数据的过程,有了特征数据我们就可以利用特征数据实现对象检测与对象识别,这个最简单一个方法就是特征匹配,OPenCV提供了两种图像特征匹配的算法
- 暴力匹配
- FLANN匹配
其中FLANN是一种高效的数值或者字符串匹配算法,SIFT/SURF是基于浮点数的匹配,ORB是二值匹配,速度更快。对于FLANN匹配算法,当使用ORB匹配算法的时候,需要重新构造HASH。对匹配之后的输出结果,根据距离进行排序,就会得到距离比较的匹配点,这个才是好的特征匹配。
97.基于描述子匹配的已知对象定位
图像特征点检测、描述子生成以后,就可以通过OpenCV提供的描述子匹配算法,得到描述子直接的距离,距离越小的说明是匹配越好的,设定一个距离阈值,一般是最大匹配距离的1/5~1/4左右作为阈值,得到所有小于阈值的匹配点,作为输入,通过单应性矩阵,获得这两个点所在平面的变换关系H,根据H使用透视变换就可以根据输入的对象图像获得场景图像中对象位置,最终绘制位置即可。
98.SIFT特征提取 – 关键点提取
SIFT特征提取是图像特征提取中最经典的一个算法,归纳起来SIFT特征提取主要有如下几步:
- 构建高斯多尺度金字塔
- 关键点查找/过滤与精准定位
- 窗口区域角度方向直方图
- 描述子生成
SIFT特征是非常稳定的图像特征,在图像搜索、特征匹配、图像分类检测等方面应用十分广泛,但是它的缺点也是非常明显,就是计算量比较大,很难实时,所以对一些实时要求比较高的常见SIFT算法还是无法适用。如今SIFT算法在深度学习特征提取与分类检测网络大行其道的背景下,已经越来越有鸡肋的感觉,但是它本身的算法知识还是很值得我们学习,对我们也有很多有益的启示,本质上SIFT算法是很多常见算法的组合与巧妙衔接,这个思路对我们自己处理问题可以带来很多有益的帮助。今天我们首先高清楚SIFT特征提取的前面两个步骤,尺度空间金字塔与关键点过滤。
OpenCV已经实现了SIFT算法,但是在OpenCV3.0之后因为专利授权问题,该算法在扩展模块xfeature2d中,需要自己编译才可以使用,OpenCV Python中从3.4.2之后扩展模块也无法使用,需要自己单独编译python SDK才可以使用。其使用方法与我们前面介绍的ORB完全一致。都是遵循下面的步骤
- 创建对象
- 通过detect方法提取对象关键点
- 同drawKeypoints绘制关键点
构建多尺度高斯金字塔
为了在每组图像中检测 S 个尺度的极值点,DoG 金字塔每组需 S+2 层图像,因为每组的第一层和最后一层图像上不能检测极值,DoG 金字塔由高斯金字塔相邻两层相减得到,则高斯金字塔每组最少需 S+3 层图像,实际计算时 S 通常在2到5之间。
99.SIFT特征提取 – 描述子生成
SIFT特征提取是图像特征提取中最经典的一个算法,归纳起来SIFT特征提取主要有如下几步:
- 构建高斯多尺度金字塔
- 关键点查找/过滤与精准定位
- 窗口区域角度方向直方图
- 描述子生成
前面我们已经详细解释了SIFT特征点是如何提取的,有了特征点之后,我们对特征点周围的像素块计算角度方向直方图,在计算直方图之前首先需要对图像进行梯度计算,这里可以使用SOBEL算子,然后根据dx与dy计算梯度和与角度
100.HOG特征与行人检测
HOG(Histogram of Oriented Gradient)特征在对象识别与模式匹配中是一种常见的特征提取算法,是基于本地像素块进行特征直方图提取的一种算法,对象局部的变形与光照影响有很好的稳定性,最初是用HOG特征来来识别人像,通过HOG特征提取+SVM训练,可以得到很好的效果,OpenCV已经有了。HOG特征提取的大致流程看第一张图
101. HOG特征描述子 – 多尺度检测
HOG(Histogram of Oriented Gradient)特征本身不支持旋转不变性,通过金字塔可以支持多尺度检测实现尺度空间不变性,OpenCV中支持HOG描述子多尺度检测的相关API如下: virtual void cv::HOGDescriptor::detectMultiScale( InputArray img, std::vector< Rect > & foundLocations, double hitThreshold = 0, Size winStride = Size(), Size padding = Size(), double scale = 1.05, double finalThreshold = 2.0, bool useMeanshiftGrouping = false ) Img表示输入图像 foundLocations表示发现对象矩形框 hitThreshold表示SVM距离度量,默认0表示,表示特征与SVM分类超平面之间 winStride表示窗口步长 padding表示填充 scale表示尺度空间 finalThreshold 最终阈值,默认为2.0 useMeanshiftGrouping 不建议使用,速度太慢拉 这个其中窗口步长与Scale对结果影响最大,特别是Scale,小的尺度变化有利于检出低分辨率对象,同事也会导致FP发生,高的可以避免FP但是会产生FN(有对象漏检)。窗口步长是一个或者多个block区域。
102. HOG特征描述子 – 提取描述子
对于HOG特征,我们可以通过预先训练的特征数据,进行多尺度的对象检测,OpenCV中基于HOG的行人检测是一个典型案例,同时我们还可以实现自定义对象的检测,这种自定义对象检测,可以分为两个部分,第一部分:通过提取样本的HOG描述子,生成样本的特征数据,第二部分通过SVM进行分类学习与训练,保存为模型。这样我们以后就可以通过模型来实现自定义对象检测啦。今天我们首先分享第一部分,提取HOG描述子。OpenCV中提取HOG描述子的API表示如下:
virtual void cv::HOGDescriptor::compute(
InputArray img,
std::vector< float > & descriptors,
Size winStride = Size(),
Size padding = Size(),
const std::vector< Point > & locations = std::vector< Point >() )
输入图像大小WxH=72x128 默认的HOG描述子窗口大小为64x128,窗口移动的步长8x8 对于每个窗口内部,每个Cell大小是8x8的,所以窗口可以划分为8x16的Cells大小 对于每个Block区域来说,每次移动步长是一个Cell,8x16Cells可以得到总数7x15个Block 每个Block都是4个Cell, 36个向量,所以对于输入图像得到: 7x15x36x2 = 7560个特征描述子,这些描述子可以作为浮点数特征数据,对于需要输入的样本图像来说,需要首先执行以下预处理,把图像大小resize为跟窗口大小一致或者把窗口resize跟图像大小一致,这样有利于下一步处理。
103. HOG特征描述子 – 使用描述子特征生成样本数据
对于HOG特征,我们可以通过预先训练的特征数据,进行多尺度的对象检测,OpenCV中基于HOG的行人检测是一个典型案例,同时我们还可以实现自定义对象的检测,这种自定义对象检测,可以分为两个部分,第一部分:通过提取样本的HOG描述子,生成样本的特征数据,第二部分通过SVM进行分类学习与训练,保存为模型。这样我们以后就可以通过模型来实现自定义对象检测啦。今天我们分享第二部分,使用HOG描述子特征数据生成数据集,进行SVM分类训练,实现对象分类识别。 这里我已一个很常见的应用,电表检测为例,这类问题早期主要通过特征匹配实现,但是这个方法比较容易受到各种因素干扰,不是很好,通过提取HOG特征、进行SVM特征分类、然后开窗检测,是一个很好的解决方法。 在OpenCV中训练SVM模型,其数据格式常见的是“行模式”就是一行(多列向量)是一个样本,对应一个整数标签(label)。这里采用默认的窗口大小为64x128 提取HOG特征向量,得到的每个样本的向量数目等于7x15x36=3780,有多少个样本就有多少行, 对于的标签是每一行对应自己的标签,有多少个训练样本,标签就有多少行!
104. 对于得到的结构化HOG特征数据,我们就可以通过初始化SVM进行回归分类训练,这里采用的训练器是SVM线性分类器,SVM还有另外一个分类器就是对于线性不可分数据的径向分类器。OpenCV中使用径向分类器SVM有时候会训练很长时间,而且结果很糟糕,甚至会报一些莫名其妙的错误,感觉不是特别好。所以推荐大家真对线性不可分的问题可以选择神经网络ANN模块。 在训练之前,首先简单的认识一下SVM,我们这边是通过二分类来完成,是很典型的线性可分离的SVM。 对线性可分的选择用SVM,通过很少的样本学习就会取得很好的效果。OpenCV中SVM训练的API如下: virtual bool cv::ml::StatModel::train( InputArray samples, int layout, InputArray responses ) Sample表示训练样本数据/HOG特征数据 Layout 有两种组织方式ROW_SAMPLE与COL_SAMPLE Responses 每个输入样本的标签 对于训练好的数据我们可以通过save方法进行保存,只要提供一个保存路径即可。 相关数据文件:https://github.com/gloomyfish1998/opencv_tutorial
105. HOG特征描述子 – 使用HOG进行对象检测
对于已经训练好的HOG+SVM的模型,我们可以通过开窗实现对象检测,从而完成自定义对象检测。以电表检测为例,这样我们就实现HOG+SVM对象检测全流程。OpenCV中实现对每个窗口像素块预测,需要首先加载SVM模型文件,然后使用predict方法实现预测。这种方法的缺点就是开窗检测是从左到右、从上到下,是一个高耗时的操作,所以步长选择一般会选择HOG窗口默认步长的一半,这样可以减少检测框的数目,同时在predict时候会发现多个重复框,求取它们的平均值即可得到最终的检测框。
106. AKAZE特征与描述子
AKAZE特征提取算法是局部特征描述子算法,可以看成是SIFT算法的改进、采用非线性扩散滤波迭代来提取与构建尺度空间、采用与SIFT类似的方法寻找特征点、在描述子生成阶段采用ORB类似的方法生成描述子,但是描述子比ORB多了旋转不变性特征。ORB采用LDB方法,AKAZE采用 M-LDB
107. Brisk特征提取与描述子匹配
BRISK(Binary robust invariant scalable keypoints)是一种基于尺度空间不变性类似ORB特征描述子的特征提取算法。BRISK主要步骤可以分为如下两步: 1. 构建尺度空间金字塔实现关键点定位 2. 根据关键点生成描述子
108. 特征提取之关键点检测 - GFTTDetector
该方法是基于shi-tomas角点检测变化而来的一种特征提取方法,OpenCV创建该检测器的API与goodfeaturetotrack的API参数极其类似: Ptr cv::GFTTDetector::create( int maxCorners = 1000, double qualityLevel = 0.01, double minDistance = 1, int blockSize = 3, bool useHarrisDetector = false, double k = 0.04 ) 唯一不同的,该方法返回一个指针。 PS: 需要注意的是该方法无法提取描述子,只支持提取关键点!
109. BLOB特征分析 – simpleblobdetector使用
BLOB是图像中灰度块的一种专业称呼,更加变通一点的可以说它跟我们前面二值图像分析的联通组件类似,通过特征提取中的SimpleBlobDetector可以实现常见的各种灰度BLOB对象组件检测与分离。使用该检测器的时候,可以根据需要输入不同参数,得到的结果跟输入的参数息息相关。常见的BLOB分析支持如下: - 根据BLOB面积过滤 - 根据灰度/颜色值过滤 - 根据圆度过滤 - 根据长轴与短轴过滤 - 根据凹凸进行过滤
参数列表! SimpleBlobDetector::Params::Params()
bool filterByArea bool filterByCircularity bool filterByColor bool filterByConvexity bool filterByInertia float maxArea float maxCircularity float maxConvexity float maxInertiaRatio float maxThreshold float minArea float minCircularity float minConvexity float minDistBetweenBlobs float minInertiaRatio
110. KMeans 数据分类
K-Means算法的作者是MacQueen, K-Means的算法是对数据进行分类的算法,采用的硬分类方式,是属于非监督学习的算法,预先要求知道分为几个类别,然后每个类别有一个中心点,根据距离度量来决定每个数据点属于哪个类别标签,一次循环实现对所有数据点分类之后,会根据标签重新计算各个类型的中心位置,然后继续循环数据集再次分类标签样本数据,如此不断迭代,直到指定的循环数目或者前后两次delta小于指定阈值,停止计算,得到最终各个样本数据的标签。 OpenCV中KMeans数据分类的API为: double cv::kmeans( InputArray data, int K, InputOutputArray bestLabels, TermCriteria criteria, int attempts, int flags, OutputArray centers = noArray() ) data表示输入的样本数据,必须是按行组织样本,每一行为一个样本数据,列表示样本的维度 K表示最终的分类数目 bestLabels 表示最终分类每个样本的标签 criteria 表示KMeans分割的停止条件 attempts 表示采样不同初始化标签尝试次数 flag表示中心初始化方法 - KMEANS_RANDOM_CENTERS - KMEANS_PP_CENTERS - KMEANS_USE_INITIAL_LABELS centers表示最终分割以后的每个cluster的中心位置
111. KMeans 图像分割
KMean不光可以对数据进行分类,还可以实现对图像分割,什么图像分割,简单的说就要图像的各种像素值,分割为几个指定类别颜色值,这种分割有两个应用,一个可以实现图像主色彩的简单提取,另外针对特定的应用场景可以实现证件照片的背景替换效果,这个方面早期最好的例子就是证件之星上面的背景替换。当然要想实现类似的效果,绝对不是简单的KMeans就可以做到的,还有一系列后续的交互操作需要完成。对图像数据来说,要把每个像素点作为单独的样本,按行组织,只需要调用OpenCV的Mat中函数reshape即可实现 Mat cv::Mat::reshape( int cn, int rows = 0 )const cn参数表示通道数 rows表示改为多少行
112. KMeans 图像分割 – 背景替换
KMeans可以实现简单的证件照片的背景分割提取与替换,大致可以分为如下几步实现 1. 读入图像建立KMenas样本 2. 使用KMeans图像分割,指定指定分类数目 3. 取左上角的label得到背景cluster index 4. 生成mask区域,然后高斯模糊进行背景替换
113. KMeans 图像分割 – 主色彩提取
KMeans分割会计算出每个聚类的像素平均值,根据这个可以得到图像的主色彩RGB分布成分多少,得到各种色彩在图像中的比重,绘制出图像对应的取色卡!这个方面在纺织与填色方面特别有用!主要步骤显示如下: 1. 读入图像建立KMenas样本 2. 使用KMeans图像分割,指定分类数目 3. 统计各个聚类占总像素比率,根据比率建立色卡!
114. KNN算法介绍
OpenCV中机器学习模块的最近邻算法KNN, 使用KNN算法实现手写数字识别,OpenCV在sample/data中有一张自带的手写数字数据集图像,0~9 每个有500个样本,总计有5000个数字。图像大小为1000x2000的大小图像,分割为20x20大小的单个数字图像,每个样本400个像素。然后使用KNN相关API实现训练与结果的保存。大致的顺序如下: 1. 读入测试图像digit.png(可以在我的github下载,不知道地址看置顶帖子) 2. 构建样本数据与标签 3. 创建KNN训练并保存训练结果 OpenCV中KNN创建的API如下: Ptr
115. KNN算法 使用 OpenCV中机器学习模块的最近邻算法KNN, 对使用KNN训练好的XML文件,可以通过算法接口的load方法加载成为KNN分类器,使用findNearest方法进行预测。OpenCV KNN预测方法参数解释如下: virtual float cv::ml::KNearest::findNearest( InputArray samples, int k, OutputArray results, OutputArray neighborResponses = noArray(), OutputArray dist = noArray() ) 其中sample是待预测的数据样本 K表示选择最近邻的数目 Result表示预测结果 neighborResponses表示每个样本的前k个邻居 dist表示每个样本前k的邻居的距离
116. 决策树算法 介绍与使用
OpenCV中机器学习模块的决策树算法分为两个类别,一个是随机森林(Random Trees)、另外一个强化分类(Boosting Classification)。这两个算法都属于决策树算法。 virtual float cv::ml::StatModel::predict( InputArray samples, OutputArray results = noArray(), int flags = 0 )const sample输入样本 result预测结果
117. 图像均值漂移分割
图像均值漂移分割是一种无监督的图像分割方法,前面我们在跟踪相关的内容介绍过均值迁移算法,知道均值迁移可以找到图像中特征直方图空间的峰值分布,这里我们还是使用均值迁移,让它去不断分割找到空间颜色分布的峰值,然后根据峰值进行相似度合并,解决过度分割问题,得到最终的分割图像,对于图像多维度数据颜色值(RGB)与空间位置(x,y),所以需要两个窗口半径,一个是空间半径、另外一个是颜色半径,经过均值漂移窗口的所有的像素点会具有相同的像素值,OpenCV中均值漂移分割的API如下: void cv::pyrMeanShiftFiltering( InputArray src, OutputArray dst, double sp, double sr, int maxLevel = 1, TermCriteria termcrit = TermCriteria(TermCriteria::MAX_ITER+TermCriteria::EPS, 5, 1) ) src 输入图像 dst输出结果 sp 表示空间窗口大小 sr 表示表示颜色空间 maxLevel表示金字塔层数,总层数为maxlevel+1 termcrit表示停止条件
118. Grabcut图像分割
Grabcut是基于图割(graph cut)实现的图像分割算法,它需要用户输入一个bounding box作为分割目标位置,实现对目标与背景的分离/分割,这个跟KMeans与MeanShift等图像分割方法有很大的不同,但是Grabcut分割速度快,效果好,支持交互操作,因此在很多APP图像分割/背景虚化的软件中可以看到其身影。 void cv::grabCut( InputArray img, InputOutputArray mask, Rect rect, InputOutputArray bgdModel, InputOutputArray fgdModel, int iterCount, int mode = GC_EVAL ) img输入的三通道图像 mask输入的单通道图像,初始化方式为GC_INIT_WITH_RECT表示ROI区域可以被初始化为: GC_BGD 定义为明显的背景像素 0 GC_FGD 定义为明显的前景像素 1 GC_PR_BGD 定义为可能的背景像素 2 GC_PR_FGD 定义为可能的前景像素 3 rect 表示roi区域 bgdModel表示临时背景模型数组 fgdModel表示临时前景模型数组 iterCount表示图割算法迭代次数 mode当使用用户提供的roi时候使用GC_INIT_WITH_RECT
119. Grabcut图像分割 – 背景替换
使用Grabcut实现图像对象提取,通过背景图像替换,实现图像合成,通过对背景图像高斯模糊实现背景虚化效果,完整的步骤如下: 1. ROI区域选择 2. Grabcut对象分割 3. Mask生成 4. 使用mask,实现背景与前景的高斯权重融合
120. 二维码检测与识别
OpenCV3.4.4以上版本与OpenCV4.0版本支持该功能! OpenCV在对象检测模块中QRCodeDetector有两个相关API分别实现二维码检测与二维码解析 bool cv::QRCodeDetector::detect( InputArray img, OutputArray points )const img输入图像,灰度或者彩色图像 points 得到的二维码四个点的坐标信息 解析二维码! std::string cv::QRCodeDetector::decode( InputArray img, InputArray points, OutputArray straight_qrcode = noArray() ) img输入图像,灰度或者彩色图像 points 二维码ROI最小外接矩形顶点坐标 qrcode 输出的是二维码区域ROI图像信息 返回的二维码utf-8字符串 上述两个API功能,可以通过一个API调用实现,该API如下: std::string cv::QRCodeDetector::detectAndDecode( InputArray img, OutputArray points = noArray(), OutputArray straight_qrcode = noArray() )
121. OpenCV DNN 获取导入模型各层信息
模型下载地址:https://github.com/gloomyfish1998/opencv_tutorial/tree/master/data/models/googlenet
模型支持1000个类别的图像分类,OpenCV DNN模块支持下面框架的预训练模型的前馈网络(预测图)使用 - Caffe - Tensorflow - Torch - DLDT - Darknet
同时还支持自定义层解析、非最大抑制操作、获取各层的信息等。OpenCV加载模型的通用API为
Net cv::dnn::readNet( const String & model, const String & config = "", const String & framework = "" )
model二进制训练好的网络权重文件,可能来自支持的网络框架,扩展名为如下:
*.caffemodel (Caffe, http://caffe.berkeleyvision.org/) *.pb (TensorFlow, https://www.tensorflow.org/) *.t7 | *.net (Torch, http://torch.ch/) *.weights (Darknet, https://pjreddie.com/darknet/) *.bin (DLDT, https://software.intel.com/openvino-toolkit)
config针对模型二进制的描述文件,不同的框架配置文件有不同扩展名
*.prototxt (Caffe, http://caffe.berkeleyvision.org/) *.pbtxt (TensorFlow, https://www.tensorflow.org/) *.cfg (Darknet, https://pjreddie.com/darknet/) *.xml (DLDT, https://software.intel.com/openvino-toolkit)
framework显示声明参数,说明模型使用哪个框架训练出来的
122. OpenCV DNN 实现图像分类
使用ImageNet数据集支持1000分类的GoogleNet网络模型, 分别演示了Python与C++语言中的使用该模型实现图像分类标签预测。其中label标签是在一个单独的文本文件中读取,模型从上面的链接中下载即可。读取模型的API: Net cv::dnn::readNetFromCaffe( const String & prototxt, const String & caffeModel = String() ) prototxt表示模型的配置文件 caffeModel表示模型的权重二进制文件 使用模型实现预测的时候,需要读取图像作为输入,网络模型支持的输入数据是四维的输入,所以要把读取到的Mat对象转换为四维张量,OpenCV的提供的API为如下: Mat cv::dnn::blobFromImage( InputArray image, double scalefactor = 1.0, const Size & size = Size(), const Scalar & mean = Scalar(), bool swapRB = false, bool crop = false, int ddepth = CV_32F ) image输入图像 scalefactor 默认1.0 size表示网络接受的数据大小 mean表示训练时数据集的均值 swapRB 是否互换Red与Blur通道 crop剪切 ddepth 数据类型 模型下载地址:https://github.com/gloomyfish1998/opencv_tutorial/tree/master/data/models/googlenet 模型说明:https://github.com/opencv/opencv/tree/master/samples/dnn
123. OpenCV DNN 为模型运行设置目标设备与计算后台
OpenCV中加载网络模型之后,可以设置计算后台与计算目标设备,OpenCV DNN模块支持这两个设置的相关API如下: cv::dnn::Net::setPreferableBackend( int backendId ) backendId 表示后台计算id, - DNN_BACKEND_DEFAULT (DNN_BACKEND_INFERENCE_ENGINE)表示默认使用intel的预测推断库(需要下载安装Intel® OpenVINO™ toolkit, 然后重新编译OpenCV源码,在CMake时候enable该选项方可), 可加速计算! - DNN_BACKEND_OPENCV 一般情况都是使用opencv dnn作为后台计算, void cv::dnn::Net::setPreferableTarget( int targetId ) 常见的目标设备id如下: - DNN_TARGET_CPU其中表示使用CPU计算,默认是的 - DNN_TARGET_OPENCL 表示使用OpenCL加速,一般情况速度都很扯 - DNN_TARGET_OPENCL_FP16 可以尝试 - DNN_TARGET_MYRIAD 树莓派上的
124. OpenCV DNN 基于SSD实现对象检测
OpenCV DNN模块支持常见得对象检测模型SSD, 以及它的移动版Mobile Net-SSD,特别是后者在端侧边缘设备上可以实时计算,基于Caffe训练好的mobile-net SSD支持20类别对象检测,其模型下载地址如下: https://github.com/gloomyfish1998/opencv_tutorial/tree/master/data/models/ssd 加载网络之后,推断调用的关键API如下: Mat cv::dnn::Net::forward( const String & outputName = String() ) 参数缺省值为空 对对象检测网络来说: 该API会返回一个四维的tensor,前两个维度是1,后面的两个维度,分别表示检测到BOX数量,以及每个BOX的坐标,对象类别,得分等信息。这里需要特别注意的是,这个坐标是浮点数的比率,不是像素值,所以必须转换为像素坐标才可以绘制BOX/矩形。给大家推荐一篇关于OpenCV DNN加速的文章,欢迎转发 https://mp.weixin.qq.com/s/bM3jKtV9BbMFm5p6O2S3yg
125. OpenCV DNN 基于SSD实现实时视频检测
OpenCV DNN模块支持常见得对象检测模型SSD, 以及它的移动版Mobile Net-SSD,特别是后者在端侧边缘设备上可以实时计算,基于Caffe训练好的mobile-net SSD支持20类别对象检测,其模型下载地址如下:https://github.com/gloomyfish1998/opencv_tutorial/tree/master/data/models/ssd SSD的mobilenet版本不仅可以检测图像,还可以检测视频,达到稳定实时的效果,基于124的分享内容,我稍微做了一下改动实现了在Python与C++中的基于SSD视频对象检测的代码,详细参见源码zip文件即可。 介绍一个API, 获取网络各层执行时间与总的执行时间API: int64 cv::dnn::Net::getPerfProfile( std::vector< double > & timings ) 返回值是网络执行推断的时间 Timings是网络对应的各层执行时间
126. OpenCV DNN 基于残差网络的人脸检测
OpenCV在DNN模块中提供了基于残差SSD网络训练的人脸检测模型,该模型分别提供了tensorflow版本,caffe版本,torch版本模型文件,其中tensorflow版本的模型做了更加进一步的压缩优化,大小只有2MB左右,非常适合移植到移动端使用,实现人脸检测功能,而caffe版本的是fp16的浮点数模型,精准度更好。要先获得这些模型,只要下载OpenCV4.0源码之后, 打开运行sources\samples\dnn\face_detector\download_weights.py该脚本即可。 没有对比就没有伤害,同样一张图像,在OpenCV HAAR与LBP级联检测器中必须通过不断调整参数才可以检测出全部人脸,而通过使用该模型,基本在Python语言中基于OpenCV后台的推断,在25毫秒均可以检测出结果,网络支持输入size大小为300x300。
127. OpenCV DNN 基于残差网络的视频人脸检测
OpenCV在DNN模块中提供了基于残差SSD网络训练的人脸检测模型,还支持单精度的fp16的检测准确度更好的Caffe模型加载与使用,这里实现了一个基于Caffe Model的视频实时人脸监测模型,基于Python与C++代码CPU运行,帧率均可以到达15以上。非常好用。 昨天微信公众号的文章: 两种移动端可以实时运行的网络模型:https://mp.weixin.qq.com/s/5a9a0zir7bJ7769JRj1ixA
128. OpenCV DNN 直接调用tensorflow的导出模型
OpenCV在DNN模块中支持直接调用tensorflow object detection训练导出的模型使用,支持的模型包括 - SSD - Faster-RCNN - Mask-RCNN 三种经典的对象检测网络,这样就可以实现从tensorflow模型训练、导出模型、在OpenCV DNN调用模型网络实现自定义对象检测的技术链路,具有非常高的实用价值。以Faster-RCNN为例,模型下载地址如下:https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md 对于这些模型没有与之匹配的graph.pbtxt文件,OpenCV DNN模块提供python脚本来生成,相关详细说明看我的这篇文章:https://mp.weixin.qq.com/s/YZeCNjlVKTU6lOVrmYLDCQ
129. OpenCV DNN 调用openpose模型实现姿态评估
OpenCV DNN模块中使用openopse的深度学习模型,实现人体单人姿态评估, 首先需要下载人体姿态评估的预训练模型。
基于COCO数据集训练的模型下载地址如下:
http://posefs1.perception.cs.cmu.edu/OpenPose/models/pose/coco/pose_iter_440000.caffemodel
https://raw.githubusercontent.com/opencv/opencv_extra/master/testdata/dnn/openpose_pose_coco.prototxt
基于MPI数据集训练的模型下载地址如下:
http://posefs1.perception.cs.cmu.edu/OpenPose/models/pose/mpi/pose_iter_160000.caffemodel
https://raw.githubusercontent.com/opencv/opencv_extra/master/testdata/dnn/openpose_pose_mpi_faster_4_stages.prototxt
手势姿态模型
http://posefs1.perception.cs.cmu.edu/OpenPose/models/hand/pose_iter_102000.caffemodel
https://raw.githubusercontent.com/CMU-Perceptual-Computing-Lab/openpose/master/models/hand/pose_deploy.prototxt
其中COCO模型会生成18个点,MPI模型生成14个点,手势姿态模型生成20个点,根据这些点可以绘制出人体的关键节点或者手的关键节点。OpenCV DNN支持的姿态评估都是基于预训练的Caffe模型,而且模型没有经过专门的优化处理,速度特别的慢,在CPU上基本是秒级别才可以出结果,离实时运行差好远,但是对一些静态的手势分析还是有一定的帮助与作用。 代码实现可以分为如下几个步骤 1. 加载网络 2. 获取heatmap数据,根据heatmap寻找最大score与位置信息 3. 根据位置信息,绘制连接直线
130. OpenCV DNN 支持YOLO对象检测网络运行 OpenCV DNN模块支持YOLO对象检测网络,最新的OpenCV4.0支持YOLOv3版本的对象检测网络,YOLOv3版本同时还发布了移动端支持的网络模型YOLOv3-tiny版本,速度可以在CPU端实时运行的对象检测网络,OpenCV中通过对DarkNet框架集成支持实现YOLO网络加载与检测。因为YOLOv3对象检测网络是多个层的合并输出,所以在OpenCV中调用时候必须显示声明那些是输出层,这个对于对象检测网络,OpenCV提供了一个API来获取所有的输出层名称,该API为: std::vector cv::dnn::Net::getUnconnectedOutLayersNames()const 该函数返回所有非连接的输出层。 调用时候,必须显式通过输入参数完成推断,相关API如下: void cv::dnn::Net::forward( OutputArrayOfArrays outputBlobs, const std::vector< String > & outBlobNames ) outputBlobs是调用之后的输出 outBlobNames是所有输出层的名称 跟SSD/Faster-RCNN出来的结构不一样,YOLO的输出前四个为 # [center_x, center_y, width, height] 后面的是所有类别的得分,这个时候只要根据score大小就可以得到score最大的对应对象类别,解析检测结果。相关模型下载到YOLO作者的官方网站:https://pjreddie.com/darknet/yolo/
推荐阅读: 对象检测网络中的NMS算法详解 OpenCV中使用YOLO对象检测
131. OpenCV DNN 支持YOLOv3-tiny版本实时对象检测
YOLOv3的模型在CPU上无法做到实时运行,而YOLO作者提供了个YOLOv3版本的精简版对象检测模型,大小只有30MB左右,但是模型可以在CPU上做到实时运行,这个模型就是YOLOv3-tiny模型,其下载地址如下: YOLO: Real-Time Object Detection 相比YOLOv3,YOLOv3-tiny只有两个输出层,而且权重参数层与参数文件大小都大大的下降,可以在嵌入式设备与前端实时运行。
132. OpenCV DNN单张与多张图像的推断
OpenCV DNN中支持单张图像推断,同时还支持分批次方式的图像推断,对应的两个相关API分别为blobFromImage与blobFromImages,它们的返回对象都是一个四维的Mat对象-按照顺序分别为NCHW 其组织方式详解如下: N表示多张图像 C表示接受输入图像的通道数目 H表示接受输入图像的高度 W表示接受输入图像的宽度 Mat cv::dnn::blobFromImage( InputArray image, double scalefactor = 1.0, const Size & size = Size(), const Scalar & mean = Scalar(), bool swapRB = false, bool crop = false, int ddepth = CV_32F ) Mat cv::dnn::blobFromImages( InputArrayOfArrays images, double scalefactor = 1.0, Size size = Size(), const Scalar & mean = Scalar(), bool swapRB = false, bool crop = false, int ddepth = CV_32F ) 参数解释 Images表示多张图像,image表示单张图像 Scalefactor表示放缩 Size表示图像大小 Mean表示均值 swapRB是否交换通道 crop是否剪切 ddepth 输出的类型,默认是浮点数格式
133. OpenCV DNN 图像颜色化模型使用
OpenCV DNN在4.0还支持灰度图像的彩色化模型,是根据2016年ECCV的论文而来,基于卷积神经网络模型,通过对Lab色彩空间进行量化分割,映射到最终的CNN输出结果,最后转换为RGB彩色图像。 相关论文详见: https://arxiv.org/pdf/1603.08511.pdf 模型下载地址: GitHub - richzhang/colorization: Automatic coloriz... OpenCV DNN使用该模型时候,除了正常的Caffe模型与配置文件之外,还需要一个Lab的量化表。 推荐一篇文章,我周一的时候写的: OpenCV4.0如何跑YOLOv3对象检测模型
134. OpenCV DNN ENet实现图像分割
OpenCV DNN支持ENet网络模型的图像分割,这里采用的预先训练的ENet网络模型下载地址如下: GitHub - e-lab/ENet-training 基于Cityscapes数据集的训练预测结果 – 见图一 该模型是torch模型,加载的API为: Net cv::dnn::readNetFromTorch( const String & model, bool isBinary = true ) model参数表示二进制的模型权重文件 isBinary 默认为true 跑ENet网络的时候,OpenCV4.0.x与DLIE一起编译之后,当使用 DNN_BACKEND_INFERENCE_ENGINE,作为推断后台的时候,会得到上采样最大池化错误 切换为DNN_BACKEND_OPENCV 则torch模型正常加载!
135. OpenCV DNN 实时快速的图像风格迁移
OpenCV DNN模块现在还支持图像风格迁移网络模型的加载与使用,支持的模型是基于李飞飞等人在论文《Perceptual Losses for Real-Time Style Transfer and Super-Resolution》中提到的快速图像风格迁移网络,基于感知损失来提取特征,生成图像特征与高分辨率图像。整个网络模型是基于DCGAN + 5个残差层构成,是一个典型的全卷积网络,关于DCGAN可以看这里有详细介绍与代码实现: 使用DCGAN实现图像生成 模型下载地址 GitHub - jcjohnson/fast-neural-style: Feedforward ... 这个网络可以支持任意尺寸的图像输入,作者提供了很多种预训练的风格迁移模型提供使用,我下载了下面的预训练模型:
composition_vii.t7
starry_night.t7
la_muse.t7
the_wave.t7
mosaic.t7
the_scream.t7
feathers.t7
candy.t7
udnie.t7
这些模型都是torch框架支持的二进制权重文件,加载模型之后,就可以调用forward得到结果,通过对输出结果反向加上均值,rescale到0~255的RGB色彩空间,即可显示。
136. OpenCV DNN解析网络输出结果
多数时候DNN模块中深度学习网络的输出结果,可能是二维、三维、或者四维的,具体跟网络的结构有很大的关系,一般常见的图像分类网络,是一个1XN维的向量,通过reshape之后就很容易解析, 解析代码如下: Mat flat = prob.reshape(1,1) Point maxLoc; minMaxLoc(flat, 0, 0, &maxLoc) int predict = maxLoc.x; 如果是对象检测网络SSD/RCNN/Faster-RCNN网络,输出的是NX7的模式 所以其解析方式如下: Mat detectionMat(out.size[2], out.size[3], CV_32F, out.ptr()) 就可以解析该结构! 如果对象检测网络是基于Region的YOLO网络,则解析方式变为 Mat scores = outs[i].row(j).colRange(5, outs[i].cols); 前面五个为cx,cy,w, h, objectness 如果模型网络是图像分割的网络,最后一层输出是3通道的图像对象,则解析方式为: Mat green(224, 224, CV_32F, blob.ptr(0, 1)) // 表示绿色通道!
137. OpenCV DNN 实现性别与年龄预测
学会在OpenCV DNN中如何调用多个模型,相互配合使用! Gender Net and Age Net https://www.dropbox.com/s/iyv483wz7ztr9gh/gender_n... https://www.dropbox.com/s/xfb20y596869vbb/age_net.... 上述两个模型一个是预测性别的,一个是预测年龄的。 性别预测返回的是一个二分类结果 Male Female 年龄预测返回的是8个年龄的阶段! '(0-2)', '(4-6)', '(8-12)', '(15-20)', '(25-32)', '(38-43)', '(48-53)', '(60-100)' 实现步骤 完整的实现步骤需要如下几步: 预先加载三个网络模型 打开摄像头视频流/加载图像 对每一帧进行人脸检测 - 对检测到的人脸进行性别与年龄预测 - 解析预测结果 - 显示结果
138. OpenCV DNN 使用OpenVINO加速
OpenVINO Intel® Distribution of OpenVINO™ Toolkit | Intel® ... 支持raspberry、widnows、linux系统的CPU加速,对OpenCV DNN模块,其它的API调用都进行了加速!其核心是DLIE(Deep Learning Inference Engine), 相关的配置与安装说明可以参考Intel官方网站,支持一键加速。 最新的在线安装web installer w_openvino_toolkit_p_2018.5.456_online 内置已经编译好的OpenCV4.0.1版本 直接配置即可使用!其配置方式与正常的OpenCV+VS2015开发配置相同,唯一不同的是需要把 %install_dir%\inference_engine\bin\intel64\Debug 加到环境变量中去。 然后在调用的时候,直接通过下面这句话就可以使用IE作为计算后台 net.setPreferableBackend(DNN_BACKEND_INFERENCE_ENGINE); 发现对某些模型使用IE作为计算后天的时候,会报错,这个时候需要使用默认后台 net.setPreferableBackend(DNN_BACKEND_OPENCV); 即可: 相关参考 GitHub - opencv/dldt: Deep Learning Deployment Too... Inference Engine Developer Guide | Intel® Software 同时OpenVINO还提供了一系列的API可以单独解析二进制的模型,实现调用,无须OpenCV DNN支持,安装以后可以去sample文件夹学习即可!
139. 案例 – 识别0~9印刷体数字 – PartOne
基于二值图像分析, 通过提取字符的40个特征向量生成字符特征 其中对每个字符的ROI区域,计算4x5的网格,对每个网络计算像素个数,然后生成20个特征向量。在这个过程中充分考虑到浮点数Cell大小与分割,采用基于权重的分割方法,实现网格分割。 同时对ROI区域进行X-Project与Y-Project方向投影,每个投影直方图分为10个Bins,这样就得到了20个向量: 分别对上述的结果进行0~1之间的归一化处理,得到最终的每个字符的40个特征向量表示。 基于字符的特征向量,计算它们之间的L2距离,得到对应的预测结果。 首先来看一下如何提取40个特征向量, 这个里面涉及到两个很关键的技巧,一个是浮点数权重、一个是归一化,浮点数权重是可以提升准确率,归一化在某些程度上是可以保证字符的放缩不变性。
140. 案例 – 识别0~9印刷体数字 – PartTwo
实现识别的完整流程 根据第一部分的训练提取特征数据,作为参考,对输入的图像处理如下: 1. 二值化 2. 提取字符ROI区域 3. 对ROI提取特征向量 4. 对比特征向量,计算L2距离 5. 最小距离对应的标签即为该字符预测结果 PS:python的代码大家可以尝试自己实现 一下,或者谁实现了可以上传一下!
141. estimateRigidTransform函数在4.0版本以后已弃用,3.0版本可以使用,需要带头文件#include "opencv2/video/video.hpp"