通过 TensorFlow 实现 AI 语音降噪提升 QQ 音视频通话质量

腾讯 PCG QQ 团队 刘秋男 黄飞 石世昌 华超 杨梁
腾讯 QQ,8 亿人都在使用的即时通信软件,大量用户使用它进行免费视频、音频通话。用户在进行音频通话时可能处于各种场景,嘈杂的背景声音对通话产生干扰,高质量的音频降噪能够有效提升用户通话体验。
QQ 团队基于开源 TensorFlow 机器学习平台实现了音频降噪、音质提升和模型优化算法,将降噪算法应用于 QQ 音视频通话场景中,为用户提供 AI 赋能的智能通讯。
前言
传统降噪方法大部分结合数学、物理原理进行推导,其过程中难免基于人认知的理想先验假设,这降低了传统降噪方法对多种类、非平稳噪声的适应性。传统降噪因其计算量低,能够实时进行语音降噪的优势广为使用,但对实际场景中频发的多种类、非平稳噪声表现不佳。
AI 降噪是最近兴起的基于数据驱动的降噪方法,能够有效的应对各种突发的非平稳噪声,前提是需要大量的训练数据与合适的模型设计。模型在移动端上的部署需要权衡模型大小、降噪效果、CPU 占用率和内存占用率等多个因素,给降噪技术带来了一定的挑战。
本文基于 TensorFlow 平台搭建了一个 AI 降噪与噪声场景分类的并行训练框架,如 Fig.1 所示,打通了数据合成、模型搭建、训练推理及部署流程。此框架集中了 TensorFlow 众多 API,训练好模型后使用 TensorFlow Lite 转为 .tflite 文件。借助 TensorFlow Lite 的量化功能减小模型尺寸,在模型的降噪效果基本不受影响的前提下,极大提升了性能优势并成功部署到产品中上线。

Fig.1 基于 TensorFlow 的训练框图
训练框架搭建
数据处理
数据是以一边读取一边合成的方式动态合成带噪音频,数据读取和音频混合使用了 librosa、numpy 等开源框架,最后用 tf.data.Dataset.from_generator() 函数进行封装,模型在训练时直接调用此接口提取数据。
展示部分数据处理代码如下,自定义数据生成器 data_generator(),其中使用 librosa 开源框架读取音频为 numpy 数组格式,然后按照不同信噪比制作混合音频,每次 yield 一个样本,tf.data.Dataset_from_generator() 函数通过自身的迭代器与自定义的数据生成器遍历数据集。
def snr_mixer(clean_file, noise_file, snr, sample_rate=16000):
clean_audio, _ = librosa.load(clean_file, sr=sample_rate)
noise_audio, _ = librosa.load(noise_file, sr=sample_rate)
snr = np.random.randint(-5, 20)
speech, noise_ori, noisy = generate_mix_audio(clean_audio, noise_audio, snr)
return speech, noise_ori, noisy
def data_generator():
for file in self.clean_files:
idx = random.randint(0, len(self.noise_files) - 1)
noise_file = self.noise_names[idx]
speech, noise_ori, noisy = snr_mixer(file, noise_file, snr)
......
for index in range(num_blocks):
noisy_speech = noisy[.....]
clean_speech = speech[.....]
yield noisy_speech.astype('float32'), clean_speech.astype['float32']
dataset = tf.data.Dataset.from_generator(
data_generator,
(tf.float32, tf.float32),
output_shapes=(tf.TensorShape([]),tf.TensorShape([])))
dataset_val = tf.data.Dataset.from_generator(
...)
模型搭建
使用 tf.keras.layers 的各接口就可以快速的搭建模型,展示部分模型构建流程代码如下。模型的处理对象是时域语音信号,因此涉及到音频信号处理使用了 tf.signal 库。给定输入张量和输出张量,可以实例化一个 Model 类。
网络模型搭建完成后,需要对网络的学习过程进行配置,否则后续进行训练或者验证的时候会报错。可以使用 Model 类的成员函数 compile() 配置训练模型,可以自定义损失函数,或者使用库中自带损失函数,指定使用的优化器等。
模型配置完成后,调用 Model 类的成员函数 fit() 进行模型的训练。
from tf.keras.models import Model
from tf.keras.layers import Conv1D, Dense, LSTM, Input
noisy_audio = Input(batch_shape=(None, None), name='input_1')
windows = tf.signal.frame(noisy_audio, win_len, win_shift)
stft_res = tf.signal.rfft(windows)
....
istft_res = tf.signal.irfft(forward_res)
....
Output = ....
model = Model(inputs=noisy_audio, outputs=Output)
# Define Loss Function and optimizer
sgd = tf.keras.optimizers.SGD(lr=learning_rate, momentum=0.9)
model.compile(loss=self_define_loss(), optimizer=sgd)
model.fit(x=dataset,
epochs=20,
callbacks=[....],
validation_data=dataset_val)模型部署及量化
TensorFlow Lite 是针对移动设备和嵌入式设备的轻量化模型推理解决方案,占用空间小,低延迟,具备在移动设备运行更快的内核解释器。
模型在训练时使用的数据是若干等时长的音频数据,为学习长时间音频的时序信息,模型中加入了 LSTM 结构。模型频域处理模块需要使用傅立叶正反变换计算,目前 TensorFlow Lite 还不支持 TensorFlow 中的傅立叶变换算子,但可以通过使用 TensorFlow select 运算符来实现模型的转换。在考虑模型性能的情况下,我们重新实现了傅立叶正反变换算子,将模型以傅立叶正反变换为界分为两部分保存,针对我们的模型将傅立叶变换进行了简化加速。同时为保持流式处理与模型训练时的场景一致,流式处理的过程中会不断更新 LSTM 中的单元状态值,用于下一次输入音频的推理计算。
下面展示将模型切分保存为 .tflite 文件的流程,首先建立模型,加载训练好的模型参数;然后,建立 model_pre 和 model_aft,加载各自部分对应的模型参数;最后,定义 TensorFlow Lite 转换器(Converter),将分别保存对应的 .tflite 文件。
model.load_weights(weights_file)
weights = model.get_weights()
model_pre = Model(inputs=[inp1, states_in_1], outputs=[out1, states_out_1])
model_aft = Model(inputs=[inp2, states_in_2],
outputs=[out2, states_out_2])
model_pre.set_weights(weights[:fir_parameter_nums])
model_aft.set_weights(weights[fir_parameter_nums:])
# 将前半部分模型转为 .tflite文件
converter = tf.lite.TFLiteConverter.from_keras_model(model_pre)
if Quantification:
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
with tf.io.gfile.GFile(file_path + '_pre.tflite', 'wb') as f:
f.write(tflite_model)
# 将后半部分模型转为 .tflite文件
converter = tf.lite.TFLiteConverter.from_keras_model(model_aft)
if Quantification:
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
with tf.io.gfile.GFile(file_path + '_2.tflite', 'wb') as f:
f.write(tflite_model)
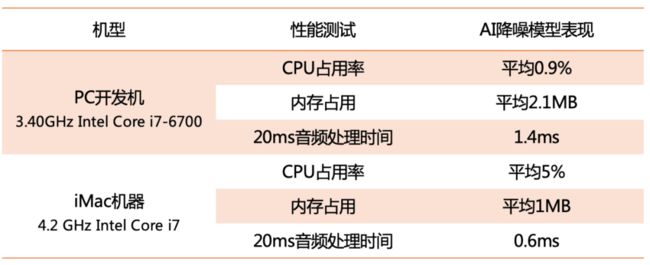
TensorFlow Lite 提供训练后量化功能,通过设置优化标志针对模型尺寸进行优化,对浮点 TensorFlow 模型进行转换。对原 32 位模型进行 8 位量化后模型的大小降到原来的 1/4,对模型降噪效果几乎没有损害。Tab.1 为降噪模型部署在 Windows 开发机和 Mac 笔记本上时测量 CPU 占用率、内存占用等性能指标。
Tab.1 降噪模型的性能指标
音频降噪
新冠疫情的爆发让在线课堂、远程会议常态化,随之而来的则是一阵宠物嚎叫、孩子嘶吼、隔壁邻居的装修声等令人尴尬的场景。针对各种噪声场景进行合适的数据扩充能够提升模型的泛化能力,结合精细化设计的网络结构能够让 AI 降噪模型适应生活中常见的几百种噪声。
音频降噪模块
本团队研发的 AI 降噪算法包括音频降噪模块和音质提升模块,模型结构如 Fig.2 所示,模型针对带噪声音频中的干净人声进行建模。音频降噪模块提取带噪音频的频域特征,通过带噪声音频与干净音频的的频域特征计算出频域范围下的 mask。由于建模对象为具有时序关系的音频信号,因此选取 LSTM 结构为主进行时序建模,学习干净音频对应的 mask。
大多论文求 mask 时只建模语音信号的幅值信息,舍去了语音信号的相位信息,这种做法会降低降噪模型的表现上限。我们设计的频域模块模拟了复数乘法的计算过程,分别对音频信号的实部和虚部进行建模。基于数学推导,使用输入带噪声音频和干净 label 音频计算实部和虚部 mask 的 ground truth,与模型学习到的 mask 计算 L2 范数作为目标函数的一部分,可以辅助提升降噪模型的效果。

Fig.2 AI 降噪模型结构
音质提升模块
音频降噪模块主要针对主讲人声音进行建模,认为其他的背景音如开门声、键盘声等都是噪声,可能会将有用的信息抹去的情况,听起来部分音频被消音。为了最大可能的避免这个情况,提升用户的通话体验,我们在音频降噪模块后面设计了音质提升模块。
该模块基于时域设计,沿用了使用较多的 Encoder-LSTM-Decoder 结构,Encoder、Decoder 部分以 Conv1D 卷积为主,时域特征提取模块以 LSTM 为主。
模型优化
用于音、视频通话中的降噪算法必须同时满足高质量降噪和实时处理两个高要求,设备计算力的限制往往会以牺牲降噪质量为代价,在这两大要求上同时追求极致成为了极大的挑战。为此,基于蒸馏技术进行模型优化。
在具体任务中模型参数量的增加能一定程度提高模型的表征学习能力,提升模型的指标效果,但受限于产品侧的各项性能要求,需要模型尽可能在有限参数量下达到指标评估最优。因此在保证模型性能(速度,内存占用)满足产品侧要求的条件下,为进一步提升模型效果,针对降噪模型设计和采用蒸馏策略,流程如 Fig.3 所示。

Fig.3 降噪模型蒸馏流程
预训练比 student 模型大 10 倍左右参数量的 teacher 模型,全量数据训练下,teacher 模型要比 student 模型有更优的评估指标。针对音频去噪模型,在具有一定物理含义的编码层(Encoder)、解码层(Decoder)和降噪音频输出上,利用指标更优的 teacher 模型引导性能更优的 student 模型,从而在保证性能的同时进一步优化评估指标。
算法效果
时频域直观效果
如 Fig.4,分别从时域和频域的角度上观察音频降噪模块的输出音频和再经过音质提升模块的输出音频,音质提升模块的加入使噪声去除的更加干净。
音质提升模块是提升降噪效果的有效手段,精心设计的音质提升模块不会导致模型参数量的大幅上升,在可接受的性能影响范围内完全可以部署在用户手机当中,进行实时降噪。

Fig.4 音频降噪效果时频图展示
客观指标评估
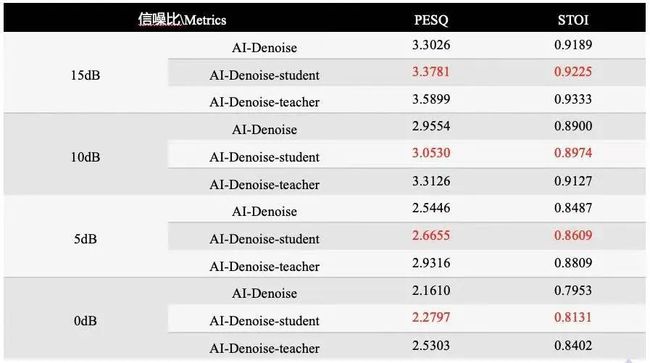
降噪模型的客观评价指标通过 PESQ(Perceptual evaluation of speech quality)和 STOI(Short-Time Objective Intelligibility)来衡量。我们选取了办公场景下常见的百种噪声:键盘声、关门声、风扇声等噪音,结合干净人声按照 0dB、5dB、10dB 和 15dB 信噪比制作混合音频,用于测试降噪模型的表现。
Tab.2 展示了降噪模型进行蒸馏前后的评估指标对比,AI-Denoise 所在行表示未经过蒸馏技术,正常训练收敛的模型指标,AI-Denoise-teacher 表示放大了参数量的降噪模型,AI-Denoise-student 表示经过蒸馏后与 AI-Denoise 模型相同结构的模型。从表格中看出,AI-Denoise 模型经过蒸馏后在 PESQ 和 STO 指标上均有提升。
Tab.2 AI-Denoise 降噪模型蒸馏前后指标
目前的降噪模型在多信噪比混合场景下的评估指标,如 Fig.5 所示。

Fig.5 降噪模型的评估指标
听觉效果
我们以办公场景噪声为例,在 TensorFlow 公众号文章中展示模型的降噪效果,欢迎大家点击试听。
总结与展望
本文以 TensorFlow 助力:AI 语音降噪打造 QQ 音视频通话新体验为题,介绍了基于 TensorFlow 搭建深度学习模型、TensorFlow Lite 助力模型部署落地的实现过程。
首先介绍了如何基于 TensorFlow 搭建 AI 降噪模型的训练框架,包括数据处理、模型的建立与训练和模型的部署方法;然后,分别介绍降噪模型的音频降噪模块和音质提升模块;继而,通过蒸馏技术优化模型来平衡性能指标与效果评估指标;最后,从视觉、听觉和客观评价指标方面分别展示算法效果。以上功能的实现离不开 Google TensorFlow 生态的支持。
未来将继续在 TensorFlow 这一强大工具的支持下,利用 AI 方法来提升用户在音视频通话时的体验。
参考资料
1. Luo, Yi, and Nima Mesgarani. "Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation." IEEE/ACM transactions on audio, speech, and language processing 27.8 (2019): 1256-1266.
2. Hu Y, Liu Y, Lv S, et al. Dccrn: Deep complex convolution recurrent network for phase-aware speech enhancement[J]. arXiv preprint arXiv:2008.00264, 2020.
想了解更多 TensorFlow Lite 案例,请扫描下方二维码,关注 TensorFlow 官方公众号获取更多信息。
