python--nltk库预处理德语文本
1.文本预处理
程序的目的是找出高频不认识的词汇,因此直接删除停用词后再分词,以减小文本处理量。将文本噪音去除放在了最后,原因是书籍文本一般较为规整,在前序两步完成后已变为字符串,最后处理简单方便(仅判断是否为字符即可)。因此分3步做文本预处理。
- 删除停用词
- 分词
- 去除文本噪音
1.1 删除停用词
nltk中停用词查找方式:
import nltk
from nltk.corpus import stopwords
set(stopwords.words('german'))
德语原有停止词共232个
1.2 分词
即,将语句转为单独字符串
#step2 tokenize
word_tokens=word_tokenize(text)
filtered_txt=[]
for w in word_tokens:
if w not in stopwords:
filtered_txt.append(filtered_txt)
1.3 去除文本噪音
#清除无效字符,返回tagged_clean
#删除filtered_txt 中元素[0]不包含在字母表中的元素
list_len=len(filtered_txt)
filtered_clean=[]
for i in range(list_len):
words=tagged_added[i]
if words[0].isalpha():
filtered_clean.append(tagged_added[i])
2. 标准化文本
德语变格及时态极多,通过NLTK的WordLemmatizer()函数进行词形还原(Lemmatization),另,词形还原在使用时,最好先指定单词的词性。标准化文本步骤:
- 获取词性
- 转换pos位(增加词性)
- 还原词形
2.1 获取词性
在NLP中,使用Parts of speech(POS)技术实现。在nltk中,使用nltk.pos_tag()获取单词在句子中的词性。
#step3 tags标注词性
tagged_added = nltk.pos_tag(tokens)
tagged_added为:
[
('Vorbemerkung', 'NNP'),
('Herausgebers', 'NNPS'),
('Die-Welt-von-Gestern', 'NNP'),
('Vorbemerkung', 'NNP'),
('HerausgebersStefan', 'NNP'),
('Zweigs', 'NNP'),
('›Welt', 'NNP'),
('Gestern‹', 'NNP'),
('großartiges', 'NNS'),
('Denn', 'NNP'),
('Rückschau', 'NNP'),
('weit', 'VBD'),
('mehr', 'JJ'),
('Autobiographie', 'NNP'),
('Blick', 'NNP'),
('beschauliche', 'NN'),
('behütete', 'NN'),
('Kindheit', 'NNP'),
('Jugend', 'NNP'),
... ...
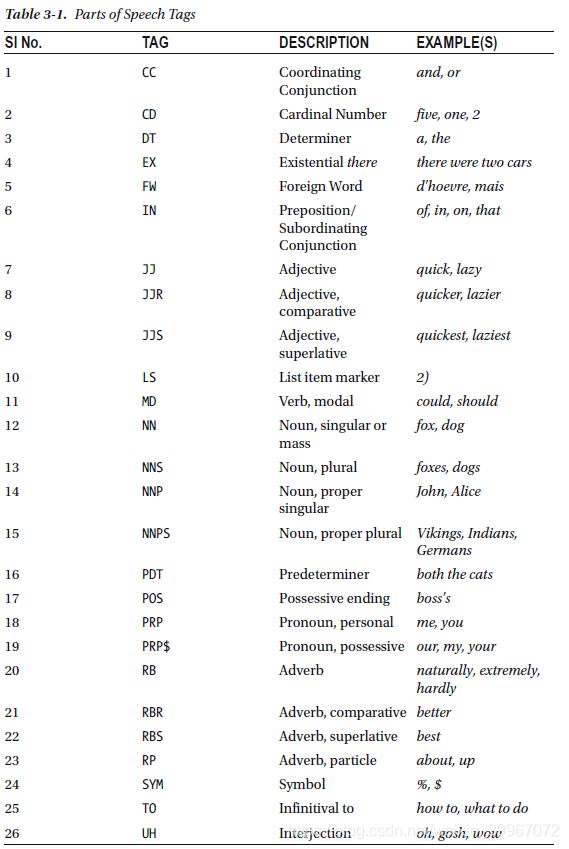
POS词性对照表:

2.2 转换pos位(增加词性)
WordNetLemmatizer()的pos参数定义了词形还原时的先行判断原词为形容词、动词、名词等,以增加原形还原准确度。
以nltk.pos_tag()获取的词性不能直接传入做为pos的实参,因此需定义转换函数:
- nltk tag 定义
#step5-1 单词的词性对应
def get_wordnet_pos(tag):
if tag.startswith('J'):
return wordnet.ADJ
elif tag.startswith('V'):
return wordnet.VERB
elif tag.startswith('N'):
return wordnet.NOUN
elif tag.startswith('R'):
return wordnet.ADV
else:
return None
2.3 还原词形
# step5-2 词形还原
wnl = WordNetLemmatizer()
Lemmatized=[]
for word in tagged_clean:
wordnet_pos = get_wordnet_pos(word[1]) or wordnet.NOUN
Lemmatized.append(wnl.lemmatize(word[0], pos=wordnet_pos))
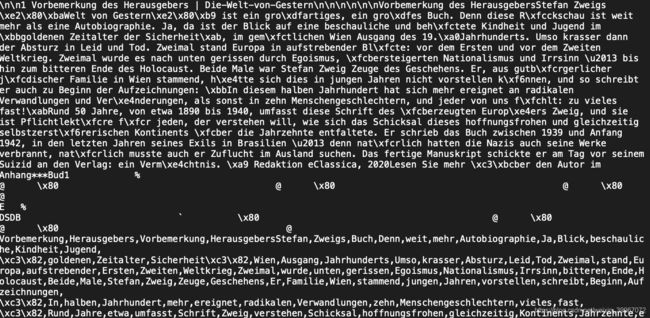
原文为:
预处理后原形为:
*发现德语效果并不好,如umfasst等,并未全部还原为原形。
尝试获取词干方法。
2.4 获取词干
词干获取时可设置语言。
from nltk.stem import SnowballStemmer
print(SnowballStemmer.languages)
('arabic', 'danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian', 'norwegian', 'porter', 'portuguese', 'romanian', 'russian', 'spanish', 'swedish')
参考
-
wordnet
-
如何处理非英文字符:
python-nltk-stemming-lemmatization-natural-language-processing-nlp -
text-cleaning-nltk-library
-
NLTK用法总结
-
NLP入门(三)词形还原(Lemmatization)
-
ntlk词典资源