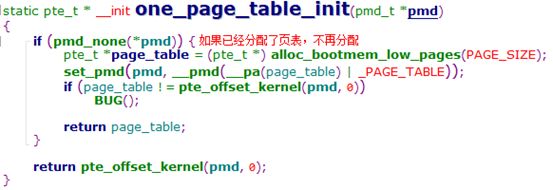
深入理解Linux内核01:内存寻址
目录
1. 内存地址
1.1 三种地址
1.1.1 逻辑地址(logical address)
1.1.2 线性地址(linear address)
1.1.3 物理地址(physical address)
1.2 对内存的并发访问
1.2.1 并发访问场景
1.2.2 内存仲裁器
2. 硬件中的分段
2.1 实模式与保护模式
2.2 段选择符和段寄存器
2.2.1 段选择符的构成
2.2.2 段寄存器
2.3 段描述符
2.3.2 段描述符字段
2.3.3 常用段描述符
2.3.4 快速访问段描述符
2.4 分段单元工作步骤
3. Linux中的分段
3.1 有限使用分段机制
3.2 4个主要的段描述符
3.3 Linux GDT
3.3.1 概述
3.3.2 布局
4. 硬件中的分页
4.1 页、页框和页表
4.2 80386常规分页
4.2.1 两级分页模式
4.2.2 页目录项 & 页表项字段
4.3 64位系统中的分页
4.4 硬件高速缓存简介
4.4.1 引入目的
4.4.2 组织形式
4.4.3 硬件位置与工作原理
4.4.4 缓存命中
4.4.5 缓存命中后的操作
4.4.6 多处理器系统中的cache
4.5 TLB简介
5. Linux中的分页
5.1 通用型四级分页模型
5.2 线性地址字段
5.2.1 PAGE_SHIFT
5.2.2 PMD_SHIFT
5.2.3 PUD_SHIFT
5.2.4 PGDIR_SHIFT
5.2.5 PRTS_PER_PTE / PMD / PUD / PGD
5.3 页目录项 & 页表项数据类型
5.4 页表处理宏与函数
5.4.1 表项类型转换
5.4.2 表项值获取
5.4.3 表项判空宏
5.4.4 表项设置宏
5.4.5 表项清空宏
5.4.6 读页标志的函数
5.4.7 设置页标志的函数
5.4.8 对页表项操作的宏
5.4.9 页分配函数
5.4.10 其他宏
5.5 实例:线性地址到物理地址的转换
5.5.1 实验目的与环境
5.5.2 实现与现象
5.5.3 实现分析
5.6 物理内存布局
5.6.1 保留页框
5.6.2 实际物理内存布局
5.6.3 内核使用的物理内存布局
5.7 进程页表
5.8 内核页表
5.8.1 不同阶段使用不同内核页表
5.8.2 临时内核页表
5.8.3 最终内核页表
补充:进程页表分配概述
5.9 固定映射的线性地址
5.9.1 ZONE_HIGHMEN的用途
5.9.2 固定映射的概念
5.9.3 固定映射的实现
5.10 对cache的处理
5.10.1 cache line大小
5.10.2 内核对cache的优化使用
5.11 对TLB的处理
5.11.1 内核确定刷新时机
5.11.2 TLB刷新函数与调用时机
5.11.3 lazy TLB简介
1. 内存地址
1.1 三种地址
1.1.1 逻辑地址(logical address)
注:讨论逻辑地址的背景为X86架构中的分段机制
① 包含在机器语言指令中用来指定一个操作数或一条指令的地址
② 逻辑地址 = 段(segment) + 偏移量(offset或displacement)
③ 在实模式中,段基址为段寄存器中的值;在保护模式中,段基址为段寄存器中段选择符指向的段描述符中设定的基地址
1.1.2 线性地址(linear address)
① 在32位CPU中,线性地址是一个32位无符号整数
② 可以用来表示高达4GB的地址
1.1.3 物理地址(physical address)
① 用于内存芯片寻址
② 与处理器芯片地址线上的信号对应
③ 物理地址由32位或36位(X86 PAE模式)无符号整数表示
说明:X86 MMU的分段单元(segmentation unit)和分页单元(paging unit)实现逻辑地址 --> 线性地址 --> 物理地址的转换
其中分段单元依靠段描述符工作,分页单元依靠页表工作

1.2 对内存的并发访问
1.2.1 并发访问场景
① 在SMP系统中,所有CPU共享同一内存
② DMA控制器也会和CPU并发访问内存
1.2.2 内存仲裁器
① 内存仲裁器(memory arbiter)是插在总线和每个RAM之间的硬件
② 内存仲裁器的作用是当某个RAM空闲时,只准许一个CPU或DMA访问内存,并延迟对其他访问者的服务
③ 仲裁器由硬件电路管理,对编程是隐藏的
2. 硬件中的分段
2.1 实模式与保护模式
① X86架构中有2种地址转换模式:实模式(real mode)和保护模式(protected mode)
② 实模式存在的主要目的,
a. 与早期处理器兼容
b. 操作系统自举阶段使用
2.2 段选择符和段寄存器
2.2.1 段选择符的构成


① 逻辑地址 = 段标识符 + 段内相对地址偏移量
② 段标识符是一个16位长的字段,称为段选择符(Segment Selector)
③ 偏移量是一个32位长的字段
④ 段选择符存储在段寄存器中
2.2.2 段寄存器
① 在保护模式下,段寄存器的唯一目的就是存放段选择符
② X86架构共6个段寄存器,cs / ss / ds / es / fs / gs,其中3个有专门用途,
cs:代码段寄存器,指向包含程序指令的段
ss:栈段寄存器,指向包含当前程序栈的段
ds:数据段寄存器,指向包含静态数据或全局数据的段
说明:RPL和CPL
① 段选择符的最低2位为RPL,即请求者特权级
② 将段选择符加载到cs寄存器后,cs寄存器的最后2位就用于指明CPU的当前特权级,即CPL(Cuurent Privilege Level)
2.3 段描述符
① 每个段由一个8B的段描述符(Segment Descriptor)表示,他描述了段的特征
② 段描述符存放在全局描述符表(Global Descriptor Table,GDT)或局部描述符表(Local Descriptor Table,LDT)中
③ 通常只定义一个GDT,而每个进程除了存放在GDT中的段之外,如果需要创建附加的段,就可以有自己的LDT
④ GDT在内存中的地址和大小存放在gdtr控制寄存器中;当前正在被使用的LDT在内存中的地址和大小存放在ldtr控制寄存器中
⑤ 段选择符中的索引号,就是用于在描述符表中索引描述符
说明1:GDT的第一项总是设置为0,以确保空段选择符的逻辑地址会被认为是无效的,因此引起一个处理器异常
说明2:能够保存在GDT中的段描述符的最大数量是8192个,即2^13 - 1
2.3.2 段描述符字段

说明:Linux中的交互以页为单位,所以不会将整个段交换到磁盘上
2.3.3 常用段描述符
2.3.3.1 代码段描述符

① 代码段描述符存放在GDT或LDT中
② 代码段描述符S标志为1,说明是非系统段
2.3.3.2 数据段描述符
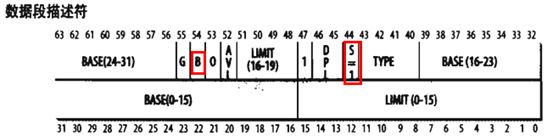
① 数据段描述符存放在GDT或LDT中
② 数据段描述符S标志为1,说明是非系统段
③ 栈段通过一般的数据段实现
2.3.3.3 系统段描述符
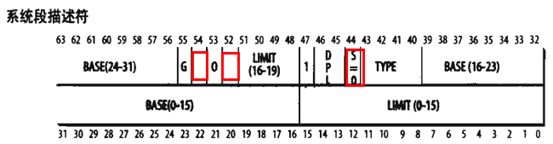
系统段描述符的S标志为0,下面列出2种常见的系统段及其特性
① 任务状态段描述符(TSSD)
a. 代表一个任务状态段(Task State Segment,TSS),用于保存处理器寄存器的内容
b. TSSD只能出现在GDT中
c. 根据相应进程是否正在CPU上运行,Type字段的值分别为11或9
② 局部描述符表描述符(LDTD)
a. 代表一个包含LDT的段
b. LDTD只能出现在GDT中
c. Type字段的值为2
2.3.4 快速访问段描述符
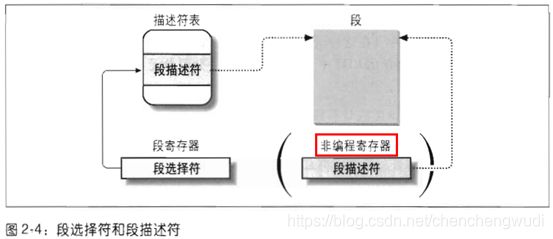
① 段寄存器中存放的只是段选择符,实际的段描述符在内存中
② 每次访问内存获取段描述符会降低逻辑地址到线性地址的转换过程,所以X86处理器设置了6个非编程的寄存器,用于存储对应段的段描述符
③ 后续针对这个段的逻辑地址转换,只需访问该非编程寄存器即可,无需访问内存
④ 仅当段寄存器的内容改变时,才有必要访问GDT或LDT,并更新对应非编程寄存器的值
说明:所谓非编程寄存器,就是不能被程序员所设置的寄存器
2.4 分段单元工作步骤
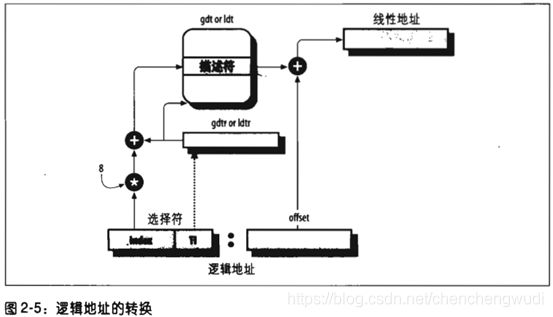
① 检查段选择符的TI字段,以确定段描述符保存在GDT还是LDT中
② 段描述符地址 = gdtr / ldtr + 段选择符index字段 * 8(每个段描述符8B)
③ 线性地址 = 段描述符base字段 + 逻辑地址的偏移量
说明:在有段寄存器相关不可编程寄存器的情况下,只有当段寄存器的内容被改变时,才需要执行前2步操作
3. Linux中的分段
3.1 有限使用分段机制
Linux以非常有限的方式使用了X86的段机制,主要原因如下,
① Linux的设计目标之一就是可以被移植到绝大多数流行的处理器平台上,而大多数RISC结构处理器没有段机制
② 当所有进程使用相同的段寄存器值时,内存管理变得更简单,也就是说他们能共享一组相同的线性地址
3.2 4个主要的段描述符
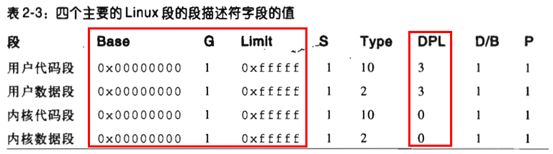
① 所有段的基地址为0x0,粒度为4KB页,偏移量为0xfffff,所以每个段都是从0地址开始的4GB线性地址空间
② 上述4个段描述符由__USER_CS、__USER_DS、__KERNEL_CS和__KERNEL_DS索引,使用时直接将上述索引加载到段寄存器即可
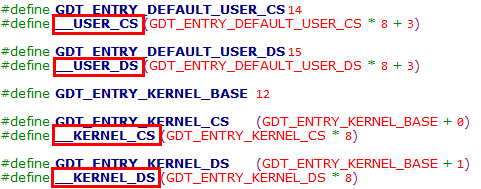
说明:注意此处用户代码段 & 用户数据段段选择符的RPL为3,所以在构造宏时进行了加3操作
③ 使用上述的4个段描述符就造成了如下的结果,
a. 用户态和内核态下的所有进程使用相同的线性地址空间
b. 逻辑地址的偏移量字段的值与相应线性地址的值总是一致的
也就是说,我们实现了既使用段机制又绕过段机制的目的
说明:特权级改变与段寄存器更新
由于CPL由存储在cs寄存器中的段选择符的RPL字段指定,所以当特权级发生改变时,一些段寄存器也必须进行相应地更新,例如,
① 当CPL = 3时,ds寄存器必须含有用户数据段的段选择符,ss寄存器必须指向一个用户数据段中的用户栈
② 当CPL = 0时,ds寄存器必须含有内核数据段的段选择符,ss寄存器必须指向一个内核数据段中的内核栈
3.3 Linux GDT
3.3.1 概述
① 在单处理器系统中,只有一个GDT;在SMP系统中,每个CPU对应一个GDT
② GDT存放在cpu_gdt_table数组中


![]()
cpu_gdt_table数组在arch/i386/head.S中定义

③ GDT的地址和大小存放在cpu_gdt_descr数组中,初始化gdtr时使用

cpu_gdt_descr数组在cpu_init函数中初始化

3.3.2 布局

GDT共32项,其中14项是空的(null)、保留的(reserved)或未使用的(not used),插入未使用的项的目的是为了使经常一起访问的描述符能够处于同一个32B的硬件高速缓存行中(cache line)
下面仅说明主要的几项,
① 用户数据段 / 用户代码段 / 内核数据段 / 内核代码段
这是最常用的4个端描述符,前文已有介绍
② 任务状态段(TSS)
每个TSS段相应的线性地址空间都是内核数据段相应线性地址空间的一个子集
③ LDT段
该段包含缺省局部描述符,这个段通常被所有进程共享
说明:Linux中的LDT
① 大多数用户态进程不使用LDT,因此内核定义了一个缺省的LDT供大多数进程共享
② 缺省的LDT定义在default_ldt数组中
![]()
③ 目前只有在Linux上模拟运行Windows程序(比如Wine)才会使用LDT
4. 硬件中的分页
4.1 页、页框和页表
① 在线性地址空间中划分页
a. 为了地址转换效率,线性地址被划分为以固定长度为单位的组,称为页(page)
b. 页内部连续的线性地址被映射到连续的物理地址中
c. 映射时,内核只需指定页的物理地址及其访问权限,而无需按字节指定
② 在物理地址空间中划分页框
a. 物理地址也被划分成固定长度的页框(page frame)
b. 页框的长度和页的长度一致,即一个页可以放入一个页框中,而且是可以放在任意一个页框中
③ 页表实现页 & 页框的映射
a. 把线性地址映射到物理地址的数据结构称为页表(page table)
b. 页表存储在内存中,在启用分页单元之前必须由内核对页表进行适当的初始化
4.2 80386常规分页
4.2.1 两级分页模式
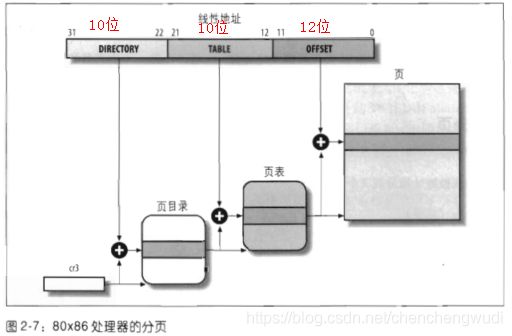
① 这是80386物理上支持的分页模式,要区别于后续Linux支持的分页模型。分页模型需要考虑兼容各种体系结构,但最终要符合硬件分页模式
② 80386采用常规采用两级分页模式,第一级为页目录,第二级为页表。相应地,线性地址为分为三个部分,即页目录索引 + 页表索引 + 页内偏移
注:采用多级页表的目的是为了减少每个进程页表所需内存数量,具体原理可参考《Linux操作系统原理与应用》内存寻址笔记chapter 3.2.3
http://note.youdao.com/noteshare?id=585de97534f9309ae045f79ddd8e03a2&sub=C3C2D175196F435DB87A60B95CBB2273
③ 每个活动的进程必须有一个分配给他的页目录(后续将看到,该目录由task_struct->mm->pgd字段管理),但是没有必要马上为进程的所有页表都分配内存,只有在进程实际需要一个页表时才给该页表分配内存
4.2.2 页目录项 & 页表项字段
页目录项和页表项使用相同的结构,如下图所示,

上图仅为某个具体Linux内核版本的实现示例,下面简述相关字段,
4.2.2.1 Present标志
① 如果被置为1,所指的页或页表在内存中
② 如果被置为0,所指的页或页表不在内存中,此时这个表项剩余的位可由操作系统用于自己的目的。如果执行一个地址转换所需的页表项或页目录项的Present标志被置为0,则分页单元把该线性地址存放在cr2寄存器中,然后产生一个缺页异常
4.2.2.2 页框物理地址的最高20位
① 由于页框大小为4KB,所以物理地址4KB对齐,因此物理地址的低12位总为0,这也是可以用这12为存储页表属性的原因
② 如果这是一个页目录项,相应的页框就含有一个页表;如果这是一个页表项,相应的页框就含有一页数据
4.2.2.3 Accessed标志
① 当分页单元对相应页框进行寻址时,设置该位;对该位的重置必须由操作系统完成,分页单元不进行
② 当该项对应的页框被交换出去时,该标志位可由操作系统使用
4.2.2.4 Dirty标志
① 只应用于页表项
② 当对一个页框进行写操作时设置该位;对该位的重置页必须由操作系统完成
③ 当该项对应的页框被交换出去时,该标志可由操作系统使用
4.2.2.5 Read / Write标志
① 含有页或页表的访问权限
② 与段的3种访问权限(只读、读写、执行)不同,页的存取权限只有2种(只读,读写)
③ Intel Pentium 4在64位页表项种增加了NX(No eXecute)标志,但仅在PAE模式下可用
4.2.2.6 User / Supervisor标志
① 含有页或页表的访问特权级
② 当该位为0,则只有CPL小于3(对于Linux就是在内核态)时才能对其寻址;当该位为1,则总能对其寻址
4.2.2.7 PCD和PWT标志
① 控制硬件高速缓存对页或页表的处理方式
4.2.2.8 Page Size标志
① 只应用于页目录项
② 如果设置为1,则页目录项指向的是2MB或4MB的页框
4.2.2.9 Global标志
① 只应用于页表项
② 该标志在Pentium Pro中引入
③ 该标志防止常用页从TLB中被刷新出去
④ 只有将cr4寄存器的页全局启用(Page Global Enable,PGE)置位后才起作用
说明1:扩展分页(extended pagind)
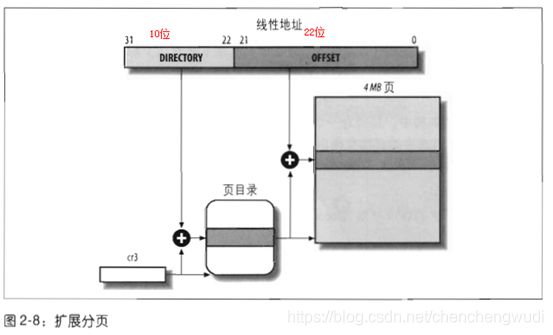
① 从Pentium模型开始,80x86引入扩展分页模式,允许页框大小为4MB,扩展分页用于把大段连续的线性地址转换成相应的物理地址
此时线性地址不需要页表项,只需要分成2部分,即页目录索引 + 页内偏移
② 扩展分页的页目录项和正常分页的差别有2处,
a. Page Size标志被置为1
b. 20位物理地址字段只有最高10位有意义,因为此时页框是4MB对齐的,所以低22位为0
说明2:物理地址扩展(Physical Address Extension)分页机制
① PAE的目的是在32位处理器中扩展可使用的物理地址
注意:此处只能扩展可用的物理地址,线性地址空间仍然只有4GB
② 在实现时,将物理地址总线从32位扩展到36位(这点类似8086)
③ 此时就需要一种新的分页机制,能够把32位的线性地址转换为36位的物理地址,Intel引入了一种三级分页机制
个人:PAE并非学习重点,相关细节不再展开
4.3 64位系统中的分页
32位处理器中的两级分页模式并不适用于64位处理器;而且由于64位可以提供的线性空间也远超过所需,所以也无需这么多的寻址位数
以下位常见的64位系统分页方式,


说明:无论使用几级分页模式,线性地址总是被划分为索引 + 页内偏移的形式
4.4 硬件高速缓存简介
4.4.1 引入目的
① 引入硬件高速缓存(hardware cache memory)的目的是为了弥合CPU和RAM之间的速度不匹配
② cache的引入基于局部性原理(locality principle)
4.4.2 组织形式
① 80x86引入了称为行(line)的新单位,每行由几十个字节组成
② 低速的RAM和高速的Cache之间以行为单位,以burst mode相互传输数据,实现高速缓存
③ Cache和RAM有3种关联模式,即直接映射(direct mapped)、充分关联(fully associative)、N-路组关联(N-way set assiciative),详情可参考计算机体系结构笔记
4.4.3 硬件位置与工作原理
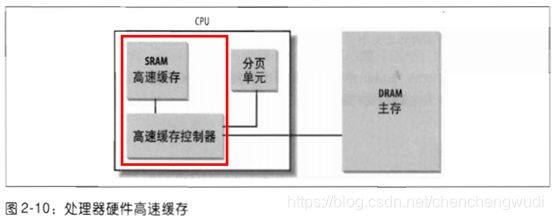
① 高速缓存单元插在分页单元和DRAM之间,由硬件高速缓存内存(hardware cache memory)和高速缓存控制器(cache controller)组成
② cache memory中存放DRAM中真正的行
③ cache controller中存放一个表项数组,每个表项对应cache memory中的一个行,每个表项由一个标签(tag)和描述高速缓存行状态的几个标志(flag)组成
④ cache controller通过表项中的tag能够识别出这个行所映射的物理内存单元
⑤ 在引入cache的系统中,内存物理地址通常被划分为3部分,即标签 + memory controller子集索引 + 行内偏移量
4.4.4 缓存命中
① 当访问一个RAM内存单元时,CPU从物理地址中取出子集索引号,然后将地址中的标签字段与子集中所有行的标签比较,如果发现某一行的标签和这个物理地址的标签相同,则CPU命中一个高速缓存(cache hit),否则高速缓存没有命中(cache miss)
② 在各类基准测试(Benchmark)和实际应用场景中,CPU Cache 的命中率通常能达到 95% 以上
4.4.5 缓存命中后的操作
当cache hit时,cache controller根据存取类型进行不同的操作
4.4.5.1 读操作
① cache controller从cache line中选择数据并送到CPU寄存器
② 由于不需要访问内存,从而节约了CPU时间
4.4.5.2 写操作
控制器根据设置,可能采取如下两个基本策略之一,
① 通写(write-through)
a. cache controller即写内存也写cache line
b. write-through的策略很直观,但是问题也很明显,那就是这个策略很慢。无论数据是不是在cache里面,我们都需要把数据写到内存中
② 回写(write-back)
a. 只写cache line不写内存
b. 只有当CPU执行一条要求刷新cache表项的指令时,或者当一个flush硬件信号产生时(通常在cache miss之后),cache controller才把cache line写回到内存中
说明1:当cache miss时,cache line被写回到内存中,如果有比较的话,把正确的行从内存中读取放到cache的表项中
说明2:页目录项 & 页表项中的PCD位和PWT位用于控制cache的行为,也就是将不同的cache管理策略与每一个页框相关联
① PCD位(Page Cache Disable)
表示是否启用高速缓存,当PCD = 1时,表示不启用高速缓存
② PWT位(Page Write-Through)
表示是否采用写透方式,当PWT = 1时,写透方式就是既写内存也写高速缓存
由于页目录项 & 页表项由硬件定义,所以这些是硬件行为。Linux默认清除所有页目录项 & 页表项中的PCD和PWT标志,也就是所有页框都启用cache,对于写操作均采用write-through策略
4.4.6 多处理器系统中的cache
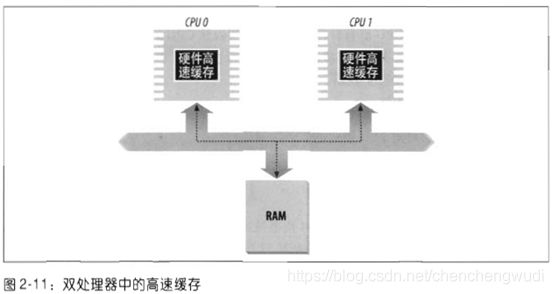
① 多CPU系统中,每个CPU有各自的L1-cache,后续芯片中又引入了各CPU独享的L2-cache和多CPU共享的L3-cache(容量更大但速度较慢的)
② 多级cache之间的一致性由硬件处理,Linux忽略这些硬件细节并假设只有一个单独的cache
说明:cr0寄存器的CD标志位用来enable / disable cache电路;NW标志位用来标识使用write-through还是write-back策略
4.5 TLB简介
① 分页单元进行地址转换时需要访问内存中的页表,在多级分页中,还要访问多次,所以转速速度被降低;但是访问内存又是非常频繁的操作
② 引入TLB用于加快线性地址的转换。当一个线性地址被第一次使用时,通过慢速访问内存中的页表计算出相应的物理地址;同时,该页表项被存放在一个TLB表项中,以便后续对同一个线性地址的引用可以快速得到转换
③ 在多处理器系统中,每个CPU有自己的TLB,且各TLB之间无需同步。因为运行在各个CPU上的进程可以使用相同的线性地址,但是与不同的物理地址关联
④ 当CPU的cr3寄存器被修改时,硬件自动使本地TLB中的所有表项无效,因为修改cr3寄存器是切换整个页表集
5. Linux中的分页
5.1 通用型四级分页模型
如上文所述,Linux为适应不同的硬件体系结构,从2.6.11版本开始引入了通用型四级分页模型

各级名称如下,
页全局目录(Page Global Directory,PGD)
页上级目录(Page Upper Directory,PUD)
页中间目录(Page Moddle Directory,PMD)
页表(Page Table,PT)
说明:最新的Linux已经引入了五级分页模型,但是理解了四级分页模型,二者原理都是一致的
5.2 线性地址字段
① Linux对不同体系结构的适应就体现在线性地址各字段的位数是可配置的
② 对于不需要的目录级,使其字段位数为0即可
Linux通过如下一组宏简化了对页表的配置和处理,
5.2.1 PAGE_SHIFT
① 头文件:include/asm-i386/page.h
② 指定OFFSET字段的位数,4KB页面中,该值为12
③ PAGE_SHIFT的值可以看作以2为底的页大小的对数
④ 由PAGE_SHIFT可以生成PAGE_SIZE宏,用于表示页的大小
#define PAGE_SIZE (1UL << PAGE_SHIFT)⑤ 由PAGE_SIZE可以生成PAGE_MASK宏,用于屏蔽OFFSET的所有位
#define PAGE_MASK (~(PAGE_SIZE-1))5.2.2 PMD_SHIFT
① 头文件:include/asm-i386/pgtable-3level-defs.h
② 指定OFFSET + TABLE字段的总位数
③ 是一个PMD目录项可以映射的区域大小以2为底的对数
④ 由PMD_SHIFT可以生成PMD_SIZE宏,用于表示一个PMD目录项可以映射的区域大小
# define PMD_SIZE (1UL << PMD_SHIFT)⑤ 由PMD_SIZE可以生成PMD_MASK宏,用于屏蔽OFFSET + TABLE字段的所有位
#define PMD_MASK (~(PMD_SIZE-1))5.2.3 PUD_SHIFT
① 头文件:include/asm-generic/pgtable-nopud.h
② 指定OFFSET + TABLE + MIDDLE DIR字段的总位数
③ 是一个PUD目录项可以映射的区域大小以2为底的对数
④ 由PUD_SHIFT可以生成PUD_SIZE宏,用于表示一个PUD目录项可以映射的区域大小
#define PUD_SIZE (1UL << PUD_SHIFT)⑤ 由PUD_SIZE可以生成PUD_MASK宏,用于屏蔽OFFSET + TABLE + MIDDLE DIR字段的所有位
#define PUD_MASK (~(PUD_SIZE-1))5.2.4 PGDIR_SHIFT
① 头文件:include/asm-i386/pgtable-3level-defs.h
② 指定OFFSET + TABLE + MIDDLE DIR + UPPER DIR字段的总位数
③ 是一个PGD目录项可以映射的区域大小以2为底的对数
④ 由PGDIR_SHIFT可以生成PGDIR_SIZE宏,用于表示一个PGD目录项可以映射的区域大小
#define PGDIR_SIZE (1UL << PGDIR_SHIFT)⑤ 由PGDIR_SIZE可以生成PGDIR_MASK宏,用于屏蔽OFFSET + TABLE + MIDDLE DIR + UPPER DIR字段的所有位
#define PGDIR_MASK (~(PGDIR_SIZE-1))5.2.5 PRTS_PER_PTE / PMD / PUD / PGD
用于表示页表、页中间目录、页上层目录和页全局目录中表项的个数
实验:不同设备上的虚拟地址字段
|
|
Ubuntu 16.04(4.15.0) X86-64 |
Ubuntu115(3.2.0) i386 |
X210(2.6.35) ARMv7 |
| PAGE_SHIFT |
12 |
12 |
12 |
| PMD_SHIFT |
21 |
21 |
21 |
| PUD_SHIFT |
30 |
30 |
未引入该宏 |
| PGD_SHIFT |
39 |
30 |
21 |
| PTRS_PER_PTE |
512 |
512 |
512 |
| PTRS_PER_PMD |
512 |
512 |
1 |
| PTRS_PER_PUD |
512 |
1 |
1 |
| PTRS_PER_PGD |
512 |
4 |
2048 |
| 线性地址划分 |
9 + 9 + 9 + 9 + 12 (共48位) |
2 + 9 + 9 + 12 (三级分页) |
9 + 11 + 12 (两级分页) |
从上表可以看出Linux的通用四级分页模式是如何适配不同硬件的,我们着重分析下物理分页级数少于四级时的使用情况
① 由于至少使用两级分页,所以PGD和PT是必然存在的
② 在实际使用三级时,取消了PUD;在实际使用两级时,取消了PUD和PMD
说明1:三级分页时可以取消PMD而不是PUD吗 ?
如果取消PMD,则偏移和表项数如下标所示,
| PAGE_SHIFT |
12 |
| PMD_SHIFT |
21 |
| PUD_SHIFT |
21 |
| PGD_SHIFT |
30 |
| PTRS_PER_PTE |
512 |
| PTRS_PER_PMD |
1 |
| PTRS_PER_PUD |
512 |
| PTRS_PER_PGD |
4 |
| 线性地址划分 |
2 + 9 + 9 + 12 (三级分页) |
所以从结果上看,取消PMD也是可以的,只是后续代码的处理也要跟着修改
更正:虽然从数值上看没问题,但是在逻辑上会有问题,因为在Linux的分页模型中,PMD中每个页表项指向的就是一个页表(PT),所以保留PUD而取消PMD是不可行的(注意,这是软件设计层面的不可行,不是硬件,因为硬件上实际只使用了三级分页)
说明2:当某一级目录项只有1个时,所需的位数就是0位,即2^0 = 1
5.3 页目录项 & 页表项数据类型
在32位处理器中,页目录项 & 页表项就是一个32位无符号整数,Linux内核中对其进行了封装并定义了数据类型
typedef struct { unsigned long pte_low; } pte_t;
typedef struct { unsigned long pgd; } pgd_t;
typedef struct { pgd_t pgd; } pud_t;
typedef struct { pud_t pud; } pmd_t;
typedef struct { unsigned long pgprot; } pgprot_t;说明1:结构体封装
封装的好处是可以提高程序的健壮性,如果不封装的话,任何32位无符号整数都可以传入页表相关的处理函数
对这个观点的支持就是在X210对应的内核版本中,只有使能STRICT_MM_TYPECHECKS宏,才会对上述类型进行结构体封装,否则只是重定义了unsigned long类型

说明2:页目录项数据类型的嵌套定义
此处嵌套定义了pgd_t / pud_t / pmd_t,本来以为有何深意,而且理解起来也比较困难,比如pud_t类型中包含的是一个pgd_t类型变量,而pgd是pud的上一级
后来查看2.6.35版本X86体系结构的代码,这种炫技的方式已经被废止,使用了更易理解的方式定义
说明3:pgprot_t在32位处理器中也是一个32位无符号数,用于表示一个表项的保护标志
5.4 页表处理宏与函数
5.4.1 表项类型转换
表项类型转换宏,用于将无符号整数转换为所需的表项类型
// 参数:无符号整数
// "返回值":所需表项类型值
#define __pte(x) ((pte_t) { (x) } )
#define __pgd(x) ((pgd_t) { (x) } )
#define __pud(x) ((pud_t) { __pgd(x) } )
#define __pmd(x) ((pmd_t) { __pud(x) } )
#define __pgprot(x) ((pgprot_t) { (x) } )是的,出于上文炫技式类型定义的原因,这些宏也很晦涩,但是只要知道他们的目的就行,可以将具体类型的实现完全理解为黑盒
5.4.2 表项值获取
表项值获取宏的作用和上面的表项类型转换宏正好相反,用于从具体的表项类型中取出无符号整数,是的,这些宏的实现依然很炫技
// 参数:具体表项类型变量
// "返回值":无符号整数
#define pte_val(x) ((x).pte_low)
#define pgd_val(x) ((x).pgd)
#define pud_val(x) (pgd_val((x).pgd))
#define pmd_val(x) (pud_val((x).pud))
#define pgprot_val(x) ((x).pgprot)5.4.3 表项判空宏
表项判空宏用于判断指定的表项是否为空,如果表项值为0,则返回1;否则返回0
// 参数:具体表项类型变量
#define pte_none(x) (!(x).pte_low)
static inline int pgd_none(pgd_t pgd) { return 0; }
#define pud_none(pud) 0
#define pmd_none(x) (!pmd_val(x))说明1:由于pgd是必须要用到的,所以此处始终返回0,即表项始终不为空
说明2:i386架构使用三级分页,取消了pud,将其假设为只有1个表项且始终存在,所以pud_none也始终返回0,即表项始终不为空
5.4.4 表项设置宏
表项设置宏用于向表项中写入指定的值
// 参数1:指向具体表项类型的指针
// 参数2:具体表项类型变量(注意不是无符号整数)
#define set_pte(pteptr, pteval) (*(pteptr) = pteval)
#define set_pgd(pgdptr, pgdval) set_pud((pud_t *)(pgdptr),\
(pud_t) { pgdval })
#define set_pud(pudptr, pudval) set_pmd((pmd_t *)(pudptr),\
(pmd_t) { pudval })5.4.5 表项清空宏
表项清空宏用于清除相应页表的一个表项,由此禁止进程使用该表项映射的线性地址;表项清空是表项设置的特例,也就是设置为0值
// 参数:指向具体表项类型的指针
#define pte_clear(xp) do { set_pte(xp, __pte(0)); } while (0)
// ptep_get_and_clear在清空一个表项时会同时返回清空前的值
#define ptep_get_and_clear(xp) __pte(xchg(&(xp)->pte_low, 0))
static inline void pgd_clear(pgd_t *pgd) { }
static inline void pud_clear (pud_t * pud) { }
#define pmd_clear(xp) do { set_pmd(xp, __pmd(0)); } while (0)5.4.6 读页标志的函数

说明1:参数为pte类型表项变量
说明2:上述宏只有在pte_present宏为true时才生效,否则产生未定义行为(源码注释)
说明3:pte_present宏
// 参数:pte类型表项变量
#define pte_present(x) ((x).pte_low & (_PAGE_PRESENT | _PAGE_PROTNONE))此处除了检查_PAGE_PRESENT位还检查了_PAGE_PROTNONE位,下面说明下_PAGE_PROTNONE位的含意
_PAGE_PROTNONE是页表中的bit 7,该位同时还表示page size(只在页目录项中生效)
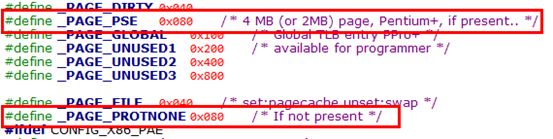
由于page size位仅在页目录项中生效,此处页表项借用了该位,用于标识缺页的原因。在pte_present宏中,只要present位或page size位被设置,均返回1
在Linux中,对于当前在内存中却没有读、写、执行权限的页,内核将其preset位置为0,将page size位置为1。因为preset位被清0,任何试图对此页的访问都会引起一个缺页异常,而内核可以通过检查page size的值来检测到产生异常并不是因为缺页,而是因为没有权限
注意,这段描述是针对X86架构的
5.4.7 设置页标志的函数

说明:上述宏只有在pte_preset宏为false时才work(源码注释)
5.4.8 对页表项操作的宏



说明:内核中处理页表的宏很繁杂,后续结合实例在应用中说明,后面的实例更能说明问题,陷入此处的宏定义会越来越乱
5.4.9 页分配函数


5.4.10 其他宏
5.4.10.1 pte_same
pte_same宏用于判断两个页表项是否相同
#define pte_same(a, b) ((a).pte_low == (b).pte_low)5.4.10.2 pmd_large宏
#define pmd_large(pmd) \
((pmd_val(pmd) & (_PAGE_PSE|_PAGE_PRESENT)) == (_PAGE_PSE|_PAGE_PRESENT))pmd_large宏即preset和page size位均被置为1,page size仅对页目录项有效,此时页中间目录项指向一个大型页(2MB或4MB)
5.4.10.3 pmd_bad宏
#define _KERNPG_TABLE (_PAGE_PRESENT | _PAGE_RW |\
_PAGE_ACCESSED | _PAGE_DIRTY)
#define pmd_bad(x) ((pmd_val(x) & (~PAGE_MASK & ~_PAGE_USER))\
!= _KERNPG_TABLE)说明1:如果目录项指向一个不能使用的页表,pmd_bad将返回1
说明2:pmd_val(x) & (~PAGE_MASK)将页目录项的高20位(即物理页框地址的高20位)清空,仅保留权限和属性内容
说明3:pgd_bad和pud_bad总是返回0;没有定义pte_bad,因为引用一个不在内存中的页、不可写的页是合法的(会有缺页异常处理)
5.5 实例:线性地址到物理地址的转换
5.5.1 实验目的与环境
目的:在内核实现线性地址到物理地址的转换,加深对分页机制的理解,同时掌握对页表操作的宏 & 函数
环境:虚拟机版本及架构为Linux ubuntu 3.2.0-79-generic-pae #115-Ubuntu SMP i686
5.5.2 实现与现象
#include
#include
#include
#include
#include
#include
#include
static unsigned long cr0,cr3;
static unsigned long vaddr = 0;
static void get_pgtable_macro(void)
{
cr0 = read_cr0();
cr3 = read_cr3();
printk("cr0 = 0x%lx, cr3 = 0x%lx\n",cr0,cr3);
printk("PGDIR_SHIFT = %d\n", PGDIR_SHIFT);
printk("PUD_SHIFT = %d\n", PUD_SHIFT);
printk("PMD_SHIFT = %d\n", PMD_SHIFT);
printk("PAGE_SHIFT = %d\n", PAGE_SHIFT);
printk("PTRS_PER_PGD = %d\n", PTRS_PER_PGD);
printk("PTRS_PER_PUD = %d\n", PTRS_PER_PUD);
printk("PTRS_PER_PMD = %d\n", PTRS_PER_PMD);
printk("PTRS_PER_PTE = %d\n", PTRS_PER_PTE);
printk("PAGE_MASK = 0x%lx\n", PAGE_MASK);
}
static unsigned long vaddr2paddr(unsigned long vaddr)
{
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *pte;
unsigned long paddr = 0;
unsigned long page_addr = 0;
unsigned long page_offset = 0;
pgd = pgd_offset(current->mm,vaddr);
printk("pgd_val = 0x%lx, pgd_index = %lu\n",
(unsigned long)pgd_val(*pgd),pgd_index(vaddr));
if (pgd_none(*pgd)){
printk("not mapped in pgd\n");
return -1;
}
pud = pud_offset(pgd, vaddr);
printk("pud_val = 0x%lx\n", (unsigned long)pud_val(*pud));
if (pud_none(*pud)) {
printk("not mapped in pud\n");
return -1;
}
pmd = pmd_offset(pud, vaddr);
printk("pmd_val = 0x%lx, pmd_index = %lu\n",
(unsigned long)pmd_val(*pmd),pmd_index(vaddr));
if (pmd_none(*pmd)) {
printk("not mapped in pmd\n");
return -1;
}
pte = pte_offset_kernel(pmd, vaddr);
printk("pte_val = 0x%lx, pte_index = %lu\n",
(unsigned long)pte_val(*pte),pte_index(vaddr));
if (pte_none(*pte)) {
printk("not mapped in pte\n");
return -1;
}
page_addr = pte_val(*pte) & PAGE_MASK;
page_offset = vaddr & ~PAGE_MASK;
paddr = page_addr | page_offset;
printk("page_addr = %lx, page_offset = %lx\n",
page_addr, page_offset);
printk("vaddr = %lx, paddr = %lx\n", vaddr, paddr);
return paddr;
}
static int __init v2p_init(void)
{
unsigned long vaddr = 0 ;
printk("vaddr to paddr module is running..\n");
get_pgtable_macro(); // 打印分页机制相关宏定义
printk("\n");
// 分配物理页框,返回线性地址
vaddr = __get_free_page(GFP_KERNEL);
if (vaddr == 0) {
printk("__get_free_page failed..\n");
return 0;
}
sprintf((char *)vaddr, "hello world from kernel");
printk("get_page_vaddr=0x%lx\n", vaddr);
vaddr2paddr(vaddr); // 实现地址转换
msleep_interruptible(100 * 1000); // 可被打断的睡眠
return 0;
}
static void __exit v2p_exit(void)
{
printk("vaddr to paddr module is leaving..\n");
free_page(vaddr);
}
module_init(v2p_init);
module_exit(v2p_exit);
MODULE_LICENSE("GPL"); 上述模块运行的结果如下图所示,
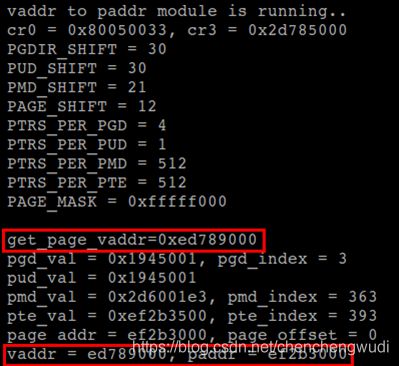
可见线性地址0xed789000的页被映射到物理地址0xef2b3000的页框
说明1:睡眠的作用
代码中在完成地址转换后进入可被打断的睡眠,经过验证,如果没有这段操作直接退出,大概率会出现显示PTE没有被映射的情况(可能的原因就是因为cache的存在,在调用vaddr2paddr函数时,读取的页表所在内存尚未更新,实际的原因可能与编译器的优化等因素相关,暂时还无法解释)
说明2:映射关系图示
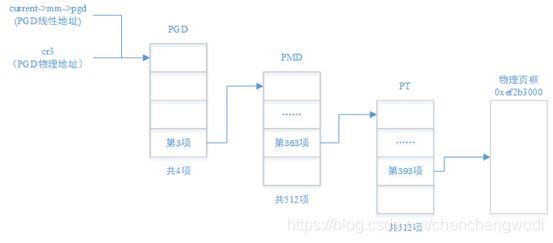
在实现和理解上,PGD / PUD / PMD / PT都是数组,所以都是起始地址 + 索引的访问方式
讨论:实验结果分析
上述实验在虚拟机中进行,有2个疑问,
① 大概率会出现PTE值为0的情况,这是明显不合理的,因为分配的内存已经在使用了
② 当PTE非零时,物理地址页框地址不合理。如上图中,将线性地址0xed789000映射到物理地址0xef2b3000
__get_free_page分配的内存属于zone normal,应该已经建立了线性地址映射,上述线性地址对应的物理地址应该是0xed789000 - PAGE_OFFSET
后续在实验代码中增加了更多打印信息,结果如下,
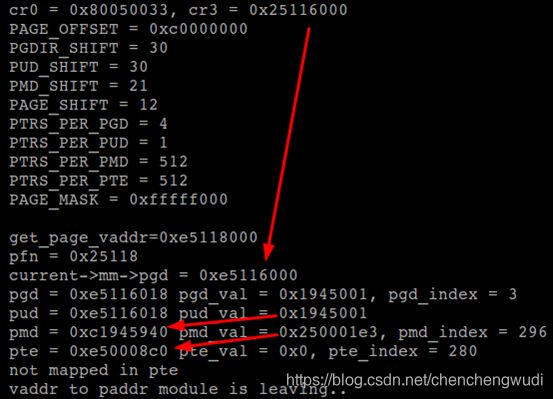
上图各级物理地址与虚拟地址均符合0xC0000000的线性映射关系,而最后一级的pmd_val的物理地址也在normal zone范围内,但是按此指向读取到的pte_val确实0
于此同时,我们将__get_free_page得到的虚拟地址进行如下转换,
page = virt_to_page(vaddr);
// printk("page->virtual = %p\n", page->virtual); // no member virtual
pfn = page_to_pfn(page);
printk("pfn = 0x%lx\n", pfn);可见得到的物理页号0x25118也是符合线性映射关系的,所以猜测可能是虚拟机测试环境与真机不同导致的问题
我们同时附上测试环境启动log中的内存信息,
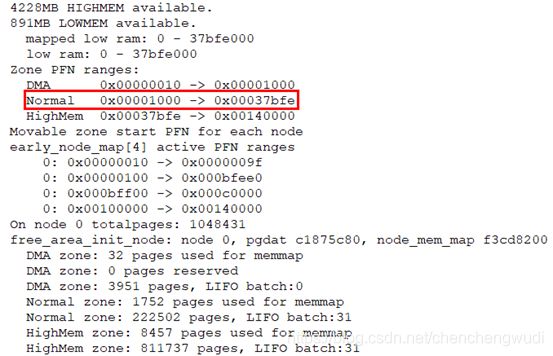
我们在X210开发板上进行相同的验证,结果也相同,在最后一级的pte value为0,但是经过后续验证,__get_free_page & kmalloc分配的内存确实是建立线性映射的,此处暂且存疑,后续解释
5.5.3 实现分析
5.5.3.1 PGD地址的存储
PGD也是存储在内存中了,所以PGD也有物理地址和线性地址,在硬件层面的分页组件进行地址映射时,需要使用物理地址;在软件层面寻址时,需要使用线性地址(一旦使能MMU,在软件层面就没有物理地址了)
其中PGD的物理地址存储在cr3控制寄存器中,供分页组件使用;PGD的线性地址存储在mm_struct结构的pgd字段,供软件层面计算使用
① mm_struct结构中的pgd字段
struct mm_struct {
// 其他字段
struct mm_struct *mm; // 描述进程的用户态虚拟地址空间,内核线程该字段为空
struct mm_struct *active_mm; // 描述上次使用的虚拟地址空间
};
struct mm_struct {
// 其他字段
pgt_t *pgd;
};mm_struct结构中的pgd字段为pgt_t *类型,是因为PGD可以理解为一个数组,此处记录的是数组首地址
② PGD在哪里

用户进程页表的PGD所需内存是动态分配的,而内核页表的PGD是编译内核时静态分配的,我们以此为例进行分析
对内核虚拟地址空间的描述结构体在kernel/init_task.c文件中定义,可见此处还静态分配了很多其他组件,目的都是用于初始化init_task,即0号进程

在cpu_init函数中会将0号进程的active_mm字段指定为init_mm
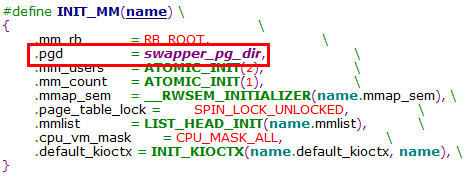
从INIT_MM宏定义可知,内核页表就是swapper_pg_dir
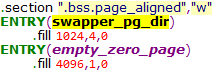
在80386中,PGD页表共1024项,所以swapper_pg_dir是一个有1024个成员的数组,每个成员大小为4B
在汇编语言层面swapper_pg_dir是一个符号地址,也就是PGD的链接地址,而这个地址是一个线性地址
下面看下PGD的物理地址是如何存储的,这点可以分析load_cr3宏的调用与实现

#define __pa(x) ((unsigned long)(x)-PAGE_OFFSET)
#define load_cr3(pgdir) \
asm volatile("movl %0,%%cr3": :"r" (__pa(pgdir)))后续笔记中可知,Linux内核对ZONE_NORMAL区域的内存是进行基于PAGE_OFFSET的简单的线性映射,所以此处通过__pa宏取出内核页表PGD的物理地址,并存入cr3寄存器
5.5.3.2 pgd_offset宏
#define pgd_index(address) (((address) >> PGDIR_SHIFT) & (PTRS_PER_PGD-1))
#define pgd_offset(mm, address) ((mm)->pgd+pgd_index(address))
// 示例调用
pgd_t *pgd;
pgd = pgd_offset(current->mm,vaddr);① pgd_index宏分解出线性地址address中的PGD索引部分
② pgd_offset根据内存描述符mm和线性地址的PGD索引部分,计算出该线性地址对应的PGD表项的线性地址(也是该宏表达式的值)
③ 根据打印结果,对应的PGD表项值为0x1945001,所以下一级PUD表的物理页框地址为0x01945000
5.5.3.3 pud_offset宏
static inline pud_t * pud_offset(pgd_t * pgd, unsigned long address)
{
return (pud_t *)pgd;
}① pud_offset宏应该根据pgd_offset返回的pgd表项的线性地址和address中的pud索引,计算出对应的pud表项的线性地址(这里的关键词是线性地址,在使能MMU的软件层面是无法直接操作物理地址的)
② 由于当前的实验环境中使用三级分页模式,取消了PUD,所以此处直接对pgd的线性地址进行了类型转换
③ 此处就可以理解很多教材中针对实际分页级数小于Linux分页模型级数情况的描述,
a. 线性地址中PUD占用的位数为0
b. PUD中仅包含一个目录项
c. PUD的这一个目录项被映射到PGD中一个适当的目录项中
即对PUD目录项的访问,被映射到与线性地址对应的PGD目录项(对"适当的目录项"的理解)
再补充一点对"PUD被折叠到PGD的理解"
逻辑上PUD的表项指向一张PMD页表,但物理上是PGD的表项指向一张PMD页表,所以此时逻辑上的PUD和PGD是同一个表项
再推进一步,对于使用两级分页的处理器,PMD也被取消,此时逻辑上的PMD、PUD和PGD是同一个表项
所以这里的"折叠"就是实现了一种映射关系
5.5.3.4 pmd_offset
如下为使用PMD的情况,
#define pud_page(pud) \
((struct page *) __va(pud_val(pud) & PAGE_MASK))
#define pmd_index(address) \
(((address) >> PMD_SHIFT) & (PTRS_PER_PMD-1))
#define pmd_offset(pud, address) ((pmd_t *) pud_page(*(pud)) + \
pmd_index(address))① pud_page宏用于获取pud表项指向的pmd页表的线性地址(只有内核态normal zone的内存可以通过__va计算出物理地址对应的线性地址),这其实也说明pud均分配在normal zone(80386中其实是pgd)
② pmd_index宏分解出线性地址address中的pmd索引部分
③ pmd_offset根据pud表项和线性地址的pmd索引部分,计算出该线性地址对应的pmd表项的线性地址
说明:对于使用两级分页的处理器,PMD也被取消,此时pmd_offset直接对pud的线性地址进行类型转换并返回,也就是pmd又被"折叠"到了pud中
static inline pmd_t * pmd_offset(pud_t * pud, unsigned long address)
{
return (pmd_t *)pud;
}5.5.3.5 pte_offset_kernel宏
#define pte_index(address) \
(((address) >> PAGE_SHIFT) & (PTRS_PER_PTE - 1))
#define pmd_page_kernel(pmd) \
((unsigned long) __va(pmd_val(pmd) & PAGE_MASK))
#define pte_offset_kernel(dir, address) \
((pte_t *) pmd_page_kernel(*(dir)) + pte_index(address))① pte_index宏分解出线性地址address中的pt索引部分
② pmd_page_kernel宏用于获取pmd表项指向的pt页表的线性地址(也是通过__va宏进行计算)
③ pte_offset_kernel宏根据pmd表项和线性地址address的pt索引部分,计算出该线性地址对应的pt表项的线性地址
说明1:pte_offset_kernel宏只能查找主内核页表,因为从上文可知他使用了__va宏计算物理地址对应的线性地址,但是只有内核才具有这种简单的线性映射特性(查找进程页表需要使用pte_offset_map函数)
本质上说查找内核页表和进程页表的区别在于页表的存储位置,是在ZONE_NORMAL还是ZONE_HIGNMEM(准确说是其中的非连续区),对非连续区的查找是需要通过映射实现的,没有简单的线性关系
说明2:获取了pte之后,就可以获得最终物理页框的物理起始地址,再加上线性地址address中的页内偏移部分,就是实际访问的物理内存地址
小结:pgd / pud / pmd / pt各级表项中存储的都是下级页框的物理地址,但是我们在内核态访问时,都需要转换为对应的线性地址(这也就是各级xxx_offset & xxx_page宏的作用)
补充:pte_offset_kernel & pte_offset_map宏分析
pte_offset_kernel & pte_offset_map宏的参数均是一个指向pmd页目录项的指针,从该页目录项的指针可以得到该页目录项的值,而该值指向页表(PT)的物理地址。这两个宏的作用就是根据address中PT的索引值,返回对应pte的指针
从实现上说,只要得到PT的内核态线性地址,加上pte_index(address)就齐活儿了。因此这里的核心问题,就是如何从PT的物理地址得到PT的内核态线性地址
至此,问题就很清晰了,根据PT所在的物理内存是低端内存还是高端内存,就有了不同的地址转换方式
① pte_offset_kernel用于PT所在物理内存为低端内存的场景
#define pte_offset_kernel(dir, address) \
((pte_t *) pmd_page_kernel(*(dir)) + pte_index(address))
#define pmd_page_kernel(pmd) \
((unsigned long) __va(pmd_val(pmd) & PAGE_MASK))此时可以直接用__va宏计算PT对应的内核线性地址
② pte_offset_kernel用于PT所在物理内存为高端内存的场景
注:内核的CONFIG_HIGHPTE宏可以控制分配PT的位置,如果分配在低端内存,效果和pte_offset_kernel类似,也是通过__va计算虚拟地址
我们此处着重讨论PT分配在高端内存的情况
#define pte_offset_map(dir, address) \
((pte_t *)kmap_atomic(pmd_page(*(dir)),KM_PTE0) + pte_index(address))
// pmd_val(PT物理地址) --> PT物理页面号 --> pfn_to_page(PT物理页描述符)
#define pmd_page(pmd) (pfn_to_page(pmd_val(pmd) >> PAGE_SHIFT))
#define kmap_atomic(page, idx) page_address(page)
void *kmap_atomic(struct page *page, enum km_type type)
{
enum fixed_addresses idx;
unsigned long vaddr;
/* even !CONFIG_PREEMPT needs this, for in_atomic in do_page_fault */
// 由于此处增加了内核抢占计数,所以pte_offset_map要和pte_unmap配对使用
inc_preempt_count();
// 如果当前page不是高端内存,直接走page_address流程
if (!PageHighMem(page))
return page_address(page);
idx = type + KM_TYPE_NR*smp_processor_id();
vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx);
// 将PT物理地址进行固定映射
set_pte(kmap_pte-idx, mk_pte(page, kmap_prot));
__flush_tlb_one(vaddr);
return (void*) vaddr;
}高端内存的物理地址和线性地址之间是没有简单的线性映射关系的,所以此处通过固定映射区建立临时映射,进而获得PT所在内存的线性地址,访问完成后需要调用pte_unmap来及时解除映射
③ 对应上面的分析,内核中使用pte_alloc_kernel为内核主页表分配PT,位于低端内存;使用pte_alloc_map为用户页表分配PT,可能位于高端内存(根据内核配置项确定)
5.6 物理内存布局
5.6.1 保留页框
在初始化阶段,内核必须建立一个物理地址映射来指定哪些物理地址可用,哪些地址不可用,内核将下列页框标记为保留,
① 在不可用的物理地址范围内的页框
② 含有内核代码和已初始化的数据结构的页框
说明:保留页框中的页绝不能被动态分配或交换到磁盘上
5.6.2 实际物理内存布局
启动过程中,BIOS会提供物理地址的映射,下面给出一款总内存128MB的示例,


可见其中有2段可用(Usable)的内存,
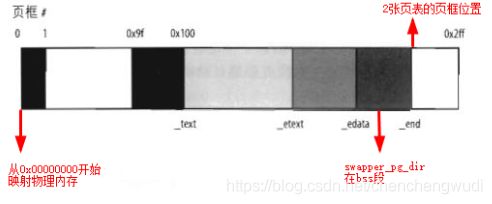
① 0x00000000 ~ 0x0009ffff(0号页框 ~ 0x9f号页框)
② 0x00100000 ~ 0x07feffff(0x100号页框 ~ 0x7fef号页框)
说明1:为安全起见,除了上表中2段可用的内存,Linux假定其余范围均不可用(后文将看到,Linux内核实际上第1MB的可用内存也未使用)
说明2:在启动过程中,内核询问BIOS并了解物理内存的布局,并调用machine_specific_memory_setup函数建立物理地址映射

改函数是设备相关的,已使用BIOS型号为BIOS-e820为例,内核最终使用struct e820map结构维护物理地址映射关系

我们来看下struct e820entry中的type字段

可见这些字段和上文中的表格是对应的,E820_RAM就是Usable类型。作为拓展的小知识点,补充说明一下ACPI data类型
这段内存存放的是BIOS加电自检(Power-On Self-Test,POST)阶段写入的系统硬件设备信息,在初始化阶段,内核将这些信息拷贝到一个合适的内核数据结构之后,这部分页框是可以使用的(只是一共只有12KB,3个页框,实在太少了)
之后的ACPI NVS和Reserved部分,都是映射到硬件设备或BIOS ROM,所以内核无法使用
5.6.3 内核使用的物理内存布局
虽然从硬件角度第1MB的内存可以使用,但是Linux内核一般不使用该区域,有如下2个原因,
① 0号页框被BIOS使用,存放加电自检期间检查到的系统硬件配置,甚至系统启动后仍将数据写到该页框
② 第1MB内的其他页框可能由特定计算机模型保留
所以Linux内核实际物理内存布局如下图所示,

说明1:_text / _etext / _edata / _end都是链接器脚本中定义的变量(arch/i386/kernel/vmlinux.lds.S),其中_text就是内核代码段的首地址
说明2:内核在分析物理内存区域的同时会初始化一些变量来描述物理内存布局,如下表所示(不同内核版本会有所不同)

下面列出可在内核模块中打印的变量在试验环境中的值,其他变量没有export symbol,所以其他模块无法使用
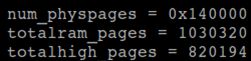
实验环境的虚拟机配置了4GB内存,所以totalram_pages的数值是合理的;但是num_physpages的数值表示最高可用页框对应的地址为5GB
根据lkml,num_physpages的值随体系结构含义有很大不同
http://lkml.iu.edu/hypermail/linux/kernel/0906.0/02536.html
补充:pfn = page frame number
5.7 进程页表
进程的线性地址空间分为两部分,
① 0 ~ 3GB(0x00000000 ~ 0xbfffffff),无论进程运行在用户态还是内核态都可以寻址
② 3 ~ 4GB(0xc0000000 ~ 0xffffffff),只有内核态的进程才能寻址
说明1:在某些情况下,内核为了检索或存放数据,必须访问用户态线性地址空间
说明2:PAGE_OFFSET宏产生的值为0xc0000000,这就是进程在线性地址空间中的偏移量
说明3:对使用两级分页的80386而言,PGD的前786项映射进程的用户线性地址空间,具体大小依赖特定进程。剩余的表项映射内核线性地址空间,对所有进程而言是相同的
5.8 内核页表
5.8.1 不同阶段使用不同内核页表
内核态持有一组自己使用的页表,驻留在主内核页全局目录(master kernel Page Global Directory)中,也就是上文介绍过的静态分配的swapper_pg_dir数组
在内核镜像刚被装入内存时,CPU仍然运行于实模式,分页功能并未开启。实际在内核启动过程中,对页表的设置是分为2个阶段进行的,
① 内核创建一个有限的地址空间,包括内核代码段、数据段、初始页表和用于存放动态数据结构的128KB
② 内核充分利用剩余RAM并适当地建立页表
5.8.2 临时内核页表
5.8.2.1 映射范围
为简单起见,假设内核使用的段、临时页表和128KB的内存范围能容纳于RAM的前8MB空间中,所以我们需要映射RAM的前8MB
5.8.2.2 映射关系
第1阶段分页的目的是允许在实模式和保护模式下都能很容易地对这8MB空间寻址,所以要建立如下2组映射关系,
① 将0x00000000 ~ 0x007fffff的线性地址空间映射到0x00000000 ~ 0x007fffff的物理地址
② 将0xc0000000 ~ 0xc07fffff的线性地址空间也映射到0x00000000 ~ 0x007fffff的物理地址
5.8.2.3 设置方式
在80386的两级分页模式中,每个PGD表项指向一个页表,共可以映射4MB内存,所以需要设置4个PGD表项,分别是第0、1、0x300(768)和0x301(769)项
虽然需要填写4个PGD表项,但是只需要2个页框就可以了,因为第0和第0x300项映射相同的物理地址;第1和第0x301项映射相同的物理地址
下面就是这2个要填写的页表(PT)存放在物理内存的什么位置 ?
在链接器脚本中,在bss段之后设置了pg0变量,该变量就是用于存放页表的位置

下面来简要分析下startup_32函数(arch/i386/kernel/head.S)如何初始化4个PGD表项 + 2张页表(每个页表1024项)

由于pg0位于内核代码段与数据段最后,而最终要映射的范围实际就是(pg0 + INIT_MAP_BEYONG_END[128KB]),也就是内核代码段 + 数据段 + 128KB
假设8MB空间足够的话,构造的页表如下图所示,
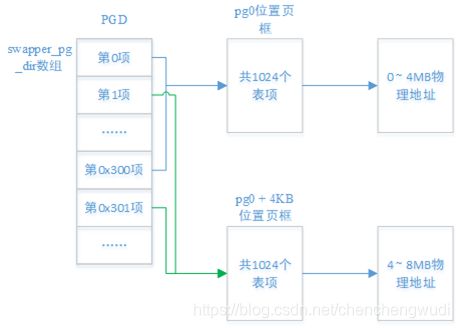
我们结合之前Linux内核物理内存的布局再来图示一下,
说明1:如何同步填写PGD页表项
根据上文分析,PGD中的一对表项指向同一个页表,代码中通过如下2行实现PGD表项的同步填写
// edx初始化时存储内核页表PGD的起始物理地址(swapper_pg_dir的物理地址)
// page_pde_offset返回的就是偏移0xc0000000对应的PGD表项地址
// 由于每个表项为4B,所以次数右移22位即可,而不是22位(即每个PGD表项可映射的大小)
movl %ecx,(%edx) /* Store identity PDE entry */
movl %ecx,page_pde_offset(%edx) /* Store kernel PDE entry */说明2:表项的权限位
此处页目录项和页表项的权限位均设置为0x007,也就是,
① Present、Read/Write、User/Supervisor标志置位
② Accessed、Dirty、PCD、PWD、Page Size标志清零
说明3:使能分页
在startup_32最后,将使能分页组件

5.8.3 最终内核页表
① 由内核页表所提供的最终映射必须把从0xc0000000开始的线性地址转换为从0开始的物理地址
② 下面的描述都是针对32位处理器
说明:进程的内核线性地址空间在地址高端,但是实际存储在地址低端
5.8.3.1 RAM小于896MB场景
① 内核对内存进行基于固定偏移量的线性映射,在线性映射的区域可以使用__pa & __va宏实现线性地址和物理地址的相互计算(注意,这里是相互"计算"而不是"转换",此处只是计算出对应的数值)
#define __pa(x) ((unsigned long)(x)-PAGE_OFFSET)
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))② 由paging_init函数建立页表

此处在内核态建立线性映射的页框上限,由max_low_pfn控制
下面简要分析下建立页表的核心函数pagetable_init,说明时对其进行了简化,需要注意的是,该函数是体系结构相关的,80386使用两级分页模式,PGD指向的就是PT
static void __init kernel_physical_mapping_init(pgd_t *pgd_base)
{
unsigned long pfn;
pgd_t *pgd;
pmd_t *pmd;
pte_t *pte;
int pgd_idx, pmd_idx, pte_ofs;
// 取出线性地址0xc0000000对应的PGD索引
pgd_idx = pgd_index(PAGE_OFFSET);
// 指向内核态首个PGD表项
pgd = pgd_base + pgd_idx;
// 已映射的页框数
pfn = 0;
for (; pgd_idx < PTRS_PER_PGD; pgd++, pgd_idx++) {
// 在80386上就是返回pmd表项,也就是pgd表项(因为只有两级分页)
pmd = one_md_table_init(pgd);
if (pfn >= max_low_pfn)
// 如果内核进行线性映射的页框超过max_low_pfn,则跳过不再映射
continue;
for (pmd_idx = 0; pmd_idx < PTRS_PER_PMD && pfn < max_low_pfn;
pmd++, pmd_idx++) {
// pfn号页框的线性地址
unsigned int address = pfn * PAGE_SIZE + PAGE_OFFSET;
// one_page_table_init函数的工作:
// 1. 分配pt页表(bootmem内存管理分配)
// 2. 设置pmd(也就是pgd)表项
// 3. 返回pt页表的线性地址首地址(pte_offset_kernel宏)
pte = one_page_table_init(pmd);
// 设置PT表项的循环(1024个)
// 但内核进行线性映射的上限位max_low_pfn
for (pte_ofs = 0; pte_ofs < PTRS_PER_PTE && pfn < max_low_pfn;
pte++, pfn++, pte_ofs++) {
// 判断是否是内核代码段,如果是则给该页表项设置可执行标志位
// 判断的标准address介于0xc0000000与__init_end之间
// 而__init_end是内核代码段 + 数据段结束位置的链接器脚本变量
if (is_kernel_text(address))
// pfn_pte根据页号生成该页框的物理地址(高20位)
// pfn_pte宏的第2个参数为页表项权限
set_pte(pte, pfn_pte(pfn, PAGE_KERNEL_EXEC));
else
set_pte(pte, pfn_pte(pfn, PAGE_KERNEL));
}
}
}
}说明1:高端地址896MB的由来
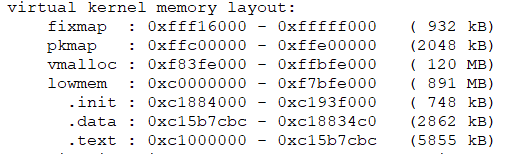
内核线性地址空间最高的128MB一般留给几种固定映射使用(后文有介绍),所以映射RAM所剩空间为1GB - 128MB = 896MB
说明2:关于max_low_pfn
从min_low_pfn到max_low_pfn是ZONE_NORMAL
从max_low_pfn到max_pfn是ZONE_HIGHMEN
说明3:撤销内核临时页表
根据之前的分析,内核临时页表即映射了进程用户地址空间,也映射了内核用户地址空间,所以在生成内核最终页表之后,临时页表的进程用户空间部分就可以撤销了
其实在建立内核最终页表的过程中,是保留了内核临时页表的进程内核地址空间部分映射的,体现在one_page_table_init函数中,当pt页表已经建立时,不再分配新的页表
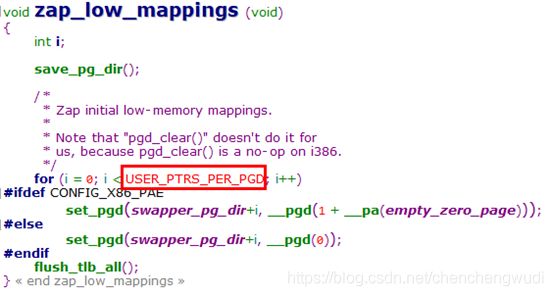
撤销内核临时页表进程用户态部分的操作由zap_low_mappings函数完成,此处TASK_SIZE为0xc0000000(即3GB),PGDIR_SIZE为1 << 22(即4MB),计算所得就是进程用户空间线性地址所需PGD表项
![]()
5.8.3.2 RAM大于896MB小于4096MB场景
① 此时内核使用和前一种情况相同的代码来初始化页全局目录,因此并不会把RAM全部映射到内核地址空间,而是把896MB的RAM映射到内核线性地址空间
② 如果一个进程需要对现有RAM的其余部分寻址,就必须把某些其他的线性地址间隔映射到所需RAM,这意味着修改某些页表项的值(详见后续内存管理笔记)
5.8.3.3 RAM大于4096MB场景
此时需要32位处理器使能PAE模式,本文不做讨论
补充:进程页表分配概述
上面说明了内核页表的生成方式,下面简要说明下进程页表的生成方式(后续进程与内存管理相关笔记还有详细说明),先看下函数调用关系
do_fork
--> copy_process
--> copy_mm
--> mm_init
--> pgd_alloc
可见pgd和pmd都是从slab上分配的,我们来看下这2个slab是如何初始化的,

可见每次建立新的task_struct,都会至少分配完整的pgd,也就是4KB(80386没有PMD,如果是有PMD的处理器,预先分配的内存更多),再加上进程内核栈等资源,所以新建进程要谨慎~(而且这些内存都是在ZONE_NORMAL分配的)
下面来看一下这里引入的2个构造函数,还是很有意思的,

pmd的构造函数就是清空所有页表项
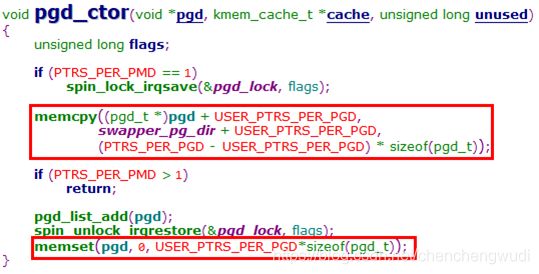
可见在分配pgd时用户线性地址空间的页表清空,内核线性地址空间则是拷贝内核页表
5.9 固定映射的线性地址
5.9.1 ZONE_HIGHMEN的用途
在32位处理器中,内核线性空间至少有128MB是留作他用的,这部分线性地址用于实现非连续内存分配(vmalloc)和固定映射,其中非连续内存分配在内存管理章节介绍
5.9.2 固定映射的概念
① 固定映射的概念类似内核线性地址空间中进行线性地址映射的部分,即ZONE_NORMAL部分,只是映射关系不是简单地减去同一个偏移量PAGE_OFFSET,而是可以以任意方式建立
② 每个固定映射的线性地址都映射一个物理内存的页框
③ 内核使用固定映射的线性地址来代替指针变量,因为这些指针变量的值从不改变
5.9.3 固定映射的实现
5.9.3.1 固定映射的索引
引入固定映射就是为了使用索引值而不是指针来间接引用一段内存,此处的索引值通过枚举类型fixed_addresses实现

说明1:有些枚举值是为了计算所需索引值而设置的,比如FIX_IO_APIC_BASE_0和FIX_BTMAP_END,他们并不用于索引固定映射
之所以索引的枚举值需要计算,是因为索引值和固定映射的内存区域大小有关
说明2:使用固定映射的优势
通过指针变量间接访问内存比通过索引值间接访问内存要多一次内存访问,使用指针变量时需要先访问内存读取指针变量的值;而使用索引值时,可以直接计算出要访问内存的值(索引用的枚举值在编译时就确定,无需通过访问内存获取)
5.9.3.2 固定映射的核心宏定义
#define __FIXADDR_TOP 0xfffff000
#define FIXADDR_TOP ((unsigned long)__FIXADDR_TOP)
#define __FIXADDR_SIZE (__end_of_permanent_fixed_addresses << PAGE_SHIFT)
#define FIXADDR_START (FIXADDR_TOP - __FIXADDR_SIZE)
#define __fix_to_virt(x) (FIXADDR_TOP - ((x) << PAGE_SHIFT))
#define __virt_to_fix(x) ((FIXADDR_TOP - ((x)&PAGE_MASK)) >> PAGE_SHIFT)说明1:调用__fix_to_virt宏的参数为fixed_addresses中指定的枚举值,返回对应的线性地址(一定要记住,在软件层面,只有返回线性地址才能操作)
调用__virt_to_fix宏的参数为线性地址,返回对应的索引值(这种用法很少内核中只有一处)
说明2:固定映射线性地址的布局
描述一段内存区域,就是需要这段地址的起始 & 终止地址,此处通过一组宏定义来进行计算实现
① 首先确定的是固定映射区的终止地址,因为固定映射区的大小是随fixed_addresses的设置而变动的,所以先设定终止地址,再根据实际大小计算出起始地址
终止地址为FIXADDR_TOP ,即0xfffff000,也就是4GB线性地址空间中的最后一个页的起始地址
② 起始地址通过终止地址减去固定映射区大小计算得来,而固定映射区的大小就是__end_of_permanent_fixed枚举值计算得出的页数
此处可得出2点结论,
a. 对固定映射区的使用以页为单位
b. 如果某个固定映射区需要多余1个页的内存,设置枚举值即可,连续2个枚举值之差就是后一个枚举值索引的固定映射区页数
下面给出一个固定映射的布局示例,从中可以发现内核处处有玄机
// index1索引的固定映射区为1页
// index2索引的固定映射区为2页(2 - 0)
enum fixed_addresses {
index1,
index2 = 2,
__end_of_permanent_fixed_addresses, // 枚举值为3
};针对上面给出的设置,可得内存布局如下图所示,
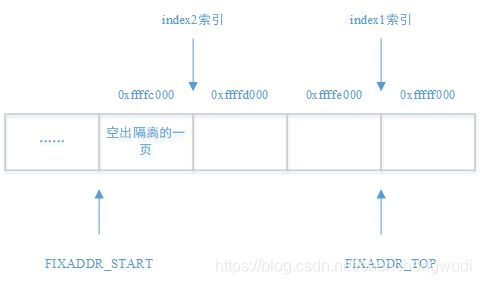
这里就可以解释为什么终止地址从0xfffff000而不是0xffffffff开始,如此设置之后,目的是空出固定映射区最前面的一页,用于和其他区域隔离(比如vmalloc使用的非连续存储区,vmalloc的每个非连续存储区之间也是有1页的隔离)
注意:即使索引值不是从0开始,上述分析依然成立,只是该索引值对应的内存页数为索引值 + 1。比如将index1设置为2,那么index1索引的固定映射区就是3页
5.3.3.3 固定映射的设置
#define set_fixmap(idx, phys) \
__set_fixmap(idx, phys, PAGE_KERNEL)
/*
* Some hardware wants to get fixmapped without caching.
*/
#define set_fixmap_nocache(idx, phys) \
__set_fixmap(idx, phys, PAGE_KERNEL_NOCACHE)
void __set_fixmap (enum fixed_addresses idx, unsigned long phys,
pgprot_t flags)
{
// 计算出索引对应的线性地址
unsigned long address = __fix_to_virt(idx);
// 判断索引值合法性
if (idx >= __end_of_fixed_addresses) {
BUG();
return;
}
set_pte_pfn(address, phys >> PAGE_SHIFT, flags);
}可见设置页表项的核心是set_pte_pfn函数,传递给该函数的参数为线性地址、物理地址页号、页表项权限
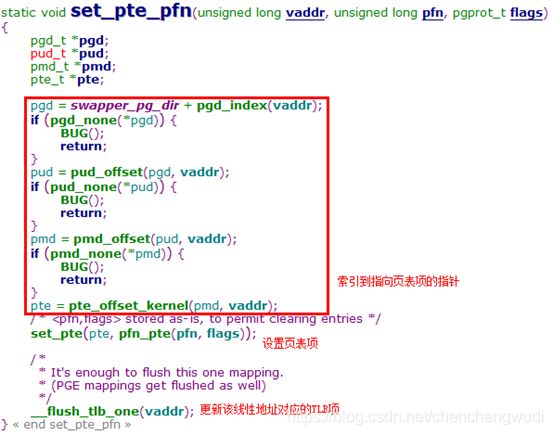
特别注意:调用set_fixmap & set_fixmap_noncache只是设置一页的页表项,如果索引的固定映射区有多个页,需要逐个设置页表项,如下图示例(从低地址页向高地址页建立),

说明:这里其实有一个问题,之前的介绍中,内核线性地址只映射到了max_low_pfn指定的页框,剩余部分并未建立页表
此处既然直接索引到pte并且设置了页表项,说明之前一定进行了初始化,该初始化就是由page_table_range_init函数完成
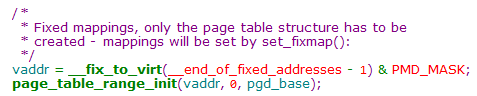
我们简单梳理一下此处的函数调用关系,
start_kernel
--> setup_arch
--> paging_init
--> pagetable_init
--> kernel_physical_mapping_init // 映射ZONE_NORMAL区域
page_table_range_init // 建立固定映射区页表
permanent_kmaps_init // 建立永久内存映射区页表(共4MB)
对照上面的内核线性地址空间分布图,pagetable_init函数将该建立内核页表都建立了
下面看下page_table_range_init函数的实现,

此处还有一个小知识点,就是给固定映射区建立页表时,end指定的是0,因为终止地址的类型为unsigned long,所以全部映射完之后发生绕回,到达地址0
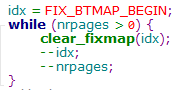
5.3.3.4 固定映射的解除
#define clear_fixmap(idx) \
__set_fixmap(idx, 0, __pgprot(0))解除固定映射就是将对应的页表项置为0,此处也是只解除一页的映射关系,如果索引的固定映射区有多个页,页需要在循环中逐页解除,如下图示例(从低地址页向高地址页解除),
5.3.3.5 固定映射的使用
static __always_inline unsigned long fix_to_virt(const unsigned int idx)
{
if (idx >= __end_of_fixed_addresses)
__this_fixmap_does_not_exist();
return __fix_to_virt(idx);
}
static inline unsigned long virt_to_fix(const unsigned long vaddr)
{
BUG_ON(vaddr >= FIXADDR_TOP || vaddr < FIXADDR_START);
return __virt_to_fix(vaddr);
}对固定映射的使用就是在索引值和线性地址之间相互转换,比较简单,此处不再赘述。这里需要特别说明的是__this_fixmap_does_not_exist函数,这个函数实际上是没有定义的,所以当idx值超限时在编译阶段就会链接失败了,把错误扼杀在萌芽状态
附件:固定映射布局示例
5.10 对cache的处理
注:对cache处理的目的是减少miss的次数
5.10.1 cache line大小
cache通过cache line寻址,cache line的大小由L1_CACHE_BYTES宏指定,Pentium 4上该值为128
5.10.2 内核对cache的优化使用
① 一个数据结构中最常用的字段放在该数据结构的低地址部分,以便他们能够处于同一个cache line
② 当为一个大的数据结构分配空间时,内核试图把他们都放在内存中,以便所有cache line按同一方式使用
说明:80x86处理器可以自动处理cache的同步,所以Linux内核可以不处理cache刷新;但同时内核为不能同步cache的处理器提供了刷新cache的接口,这些接口在includ/asm-i386/cacheflush.h文件中,是体系结构相关的操作
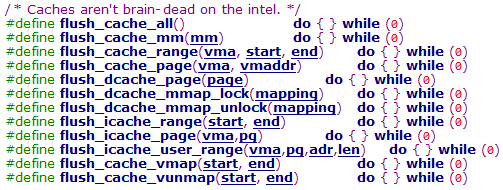
在ARM体系结构中在arch/arm/mm/cache-vxx.S文件中实现
5.11 对TLB的处理
注:对TLB处理的目的是减少miss的次数
5.11.1 内核确定刷新时机
处理器不能自动刷新TLB,因为是内核而不是处理器决定线性地址和物理地址之间的映射是否还有效
说明:向cr3寄存器写入值时,所有Pentium处理器自动刷新相对于非全局页的TLB表项(因为向cr3寄存去写入值,是在切换进程时切换线性地址空间,所以原先的线性地址空间无效)
但是内核在下列情况下避免TLB被刷新,
① 当两个使用相同页表集的普通进程之间执行进程切换时(两个进程使用相同的页表集,其实就是进程中的多个线程)
② 当一个普通进程和一个内核线程间执行进程切换时(内核线程没有自己用户空间页表集,所以直接使用刚在CPU上执行过的普通进程的页表集)
5.11.2 TLB刷新函数与调用时机

说明:这些函数的实现都是体系相关的
5.11.3 lazy TLB简介
5.11.3.1 基本思想
① 引入lasy TLB模式的目的是避免多处理器系统上无用的TLB刷新
② 如果几个CPU正在使用相同的页表,而且必须对这些CPU上的一个TLB表项刷新,那么在某些情况下,正在运行内核线程的那些CPU上的刷新就可以延迟
5.11.3.2 运行过程
① 当某个CPU开始运行一个内核线程时,内核将他置为lazy TLB模式
② 当接收到刷新TLB表项的请求时,处于lazy TLB模式的每个CPU并不刷新相应的TLB表项,但是CPU记住他的当前进程正运行在一组页表上,而这组页表的TLB表项对用户态地址是无效的
③ 当处于lazy TLB模式的CPU用一个不同的页表集切换到另一个普通进程,硬件就会自动刷新TLB表项,同时将CPU置为非lazy TLB模式
5.11.3.3 实现方式简介
① 实现SMP上的lazy TLB需要使用tlb_state结构,并且定义per-cpu变量

其中,
active_mm:指向当前进程的内存描述符
state:标识当前TLB的状态(TLBSTATE_OK / LAZY)
② 在mm_struct结构中有一个cpu_vm_mask字段,该字段存放的是CPU下标(这些CPU将要接收与TLB刷新相关的处理器间中断),只有当mm_struct属于当前运行的一个进程时该字段才有意义
③ 发送TLB相关核间中断
活动(active)内存描述符的cpu_vm_mask字段存放系统中所有CPU下标(包括进入lazy TLB模式的CPU),对于与给定页表集相关的所有CPU的TLB表项,当另外一个CPU想让这些表项无效时,该CPU就把一个核间中断发送给下标处于对应mm_struct的cpu_vm_mask字段中的那些CPU
④ 进入lazy TLB模式
当一个CPU开始执行内核线程时,内核就将该CPU的cpu_tlbstate变量的state字段置为TLBSTATE_LAZY
设置lazy TLB模式由enter_lazy_tlb函数实现

⑤ 进入lazy TLB模式的CPU对核间中断的处理
当CPU接收到一个与TLB刷新相关的核间中断时,该CPU检查他的cpu_tlbstate元素的state字段,如果是TLBSTATE_LAZY,内核就拒绝使TLB表项无效,并从cpu_vm_mask字段删除该CPU下标,这就导致两种结果,
a. 只要CPU还处于lazy TLB模式,他将不接受其他与TLB刷新相关的核间中断

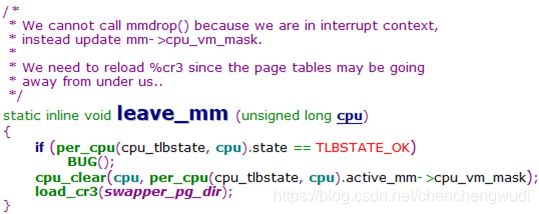
可见当CPU处于lazy TLB模式时,会调用leave_mm函数,该函数会从active_mm->cpu_vm_mask字段删除该CPU
根据注释,leave_mm函数将disable与TLB刷新相关的核间中断(leave_mm disabled tlb flush IPI delivery)
b. 如果CPU切换到另一个进程,而这个进程与刚被替换的内核线程使用相同的页表集,那么内核调用__flush_tlb使该CPU的所有非全局TLB表项无效


先说明一下相关函数的调用关系,
schedule
--> context_switch
--> switch_mm当后一进程为普通用户进程时才会调用contex_switch,用于实现用户进程空间的切换。在switch_mm函数中,如果prev == next,说明要切换到的用户进程和刚被替换的内核线程使用相同的页表,此时要返回用户态,可以使本地TLB表项无效
写到这里,都是书中的原话,但是大家是不是感觉到了一点疑问,那就是进程中的多个线程是共享mm_struct的,所以prev == next的情况还有可能是切换前后是同一个进程内的不同线程。所以代码中通过cpu_test_and_set判断cpu_vm_mask的值来区分,因为多进程中的线程是不会让CPU进入lazy TLB模式的,也就不会将cpu_vm_mask字段的某一位清零