Wu deeplearning.ai C2W1 assignment_initialization
Initialization
Welcome to the first assignment of "Improving Deep Neural Networks".
Training your neural network requires specifying an initial value of the weights. A well chosen initialization method will help learning.
If you completed the previous course of this specialization, you probably followed our instructions for weight initialization, and it has worked out so far. But how do you choose the initialization for a new neural network? In this notebook, you will see how different initializations lead to different results.
A well chosen initialization can:
- Speed up the convergence of gradient descent
- Increase the odds of gradient descent converging to a lower training (and generalization) error
To get started, run the following cell to load the packages and the planar dataset you will try to classify.
第二个单元的第一周主要是阐述了神经网络的优化,包括怎么样去处理overfitting,怎样检查反向传播的,怎样提升模型的效率。这一节主要是不同的W矩阵初始化方式对整个模型的影响,分成了全设置成0矩阵,随机初始化矩阵,"he"式初始化矩阵。
1.导入必要package和model
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
from init_utils import sigmoid, relu, compute_loss, forward_propagation, backward_propagation
from init_utils import update_parameters, predict, load_dataset, plot_decision_boundary, predict_dec
%matplotlib inline
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# load image dataset: blue/red dots in circles
train_X, train_Y, test_X, test_Y = load_dataset()
def model(X, Y, learning_rate = 0.01, num_iterations = 15000, print_cost = True, initialization = "he"):
grads = {}
costs = [] # to keep track of the loss
m = X.shape[1] # number of examples
layers_dims = [X.shape[0], 10, 5, 1]
# Initialize parameters dictionary.
if initialization == "zeros":
parameters = initialize_parameters_zeros(layers_dims)
elif initialization == "random":
parameters = initialize_parameters_random(layers_dims)
elif initialization == "he":
parameters = initialize_parameters_he(layers_dims)
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID.
a3, cache = forward_propagation(X, parameters)
# Loss
cost = compute_loss(a3, Y)
# Backward propagation.
grads = backward_propagation(X, Y, cache)
# Update parameters.
parameters = update_parameters(parameters, grads, learning_rate)
# Print the loss every 1000 iterations
if print_cost and i % 1000 == 0:
print("Cost after iteration {}: {}".format(i, cost))
costs.append(cost)
# plot the loss
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters2.采用全置0的初始化方式
# GRADED FUNCTION: initialize_parameters_zeros
def initialize_parameters_zeros(layers_dims):
parameters = {}
L = len(layers_dims) # number of layers in the network
for l in range(1, L):
parameters['W' + str(l)] = np.zeros((layers_dims[l] , layers_dims[l-1]))
parameters['b' + str(l)] = np.zeros((layers_dims[l] , 1))
return parameters
#test
parameters = model(train_X, train_Y, initialization = "zeros")
print ("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
#show result
plt.title("Model with Zeros initialization")
axes = plt.gca()
axes.set_xlim([-1.5,1.5])
axes.set_ylim([-1.5,1.5])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, np.squeeze(train_Y))result:


从结果上来看,分类的效果非常的差,而且损失函数几乎没有下降。在课程C1W3-3.11中解释过发生这一现象的原因,如果W的初始化为0矩阵,那么各层的“神经元”会呈现对称性,多个神经元的效果等于一个神经元的效果。
2.随机初始化矩阵
# GRADED FUNCTION: initialize_parameters_random
def initialize_parameters_random(layers_dims):
np.random.seed(3) # This seed makes sure your "random" numbers will be the as ours
parameters = {}
L = len(layers_dims) # integer representing the number of layers
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layers_dims[l] , layers_dims[l-1])*10
parameters['b' + str(l)] = np.zeros((layers_dims[l] , 1))
return parameters
#test
parameters = model(train_X, train_Y, initialization = "random")
print ("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
#show result
plt.title("Model with large random initialization")
axes = plt.gca()
axes.set_xlim([-1.5,1.5])
axes.set_ylim([-1.5,1.5])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, np.squeeze(train_Y))result:


从图中可以看到,损失函数一开始的数值会很高,这是因为我们初始化的时候的给予了较大的权重,糟糕的初始化会导致梯度的爆炸或者消失,从而减慢优化算法的速度。我们这里是*10,如果*到合适的数值,会优化cost function的下降曲线。我认为荷式的方法就是为了找到这个合适的数值。
3.“he”式初始化方法
# GRADED FUNCTION: initialize_parameters_he
def initialize_parameters_he(layers_dims):
np.random.seed(3)
parameters = {}
L = len(layers_dims) - 1 # integer representing the number of layers
for l in range(1, L + 1):
parameters['W' + str(l)] = np.random.randn(layers_dims[l] , layers_dims[l-1])*np.sqrt(2 / layers_dims[l-1])
parameters['b' + str(l)] = np.zeros((layers_dims[l] , 1))
return parameters
#test
parameters = model(train_X, train_Y, initialization = "he")
print ("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
#show
plt.title("Model with He initialization")
axes = plt.gca()
axes.set_xlim([-1.5,1.5])
axes.set_ylim([-1.5,1.5])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, np.squeeze(train_Y))result:

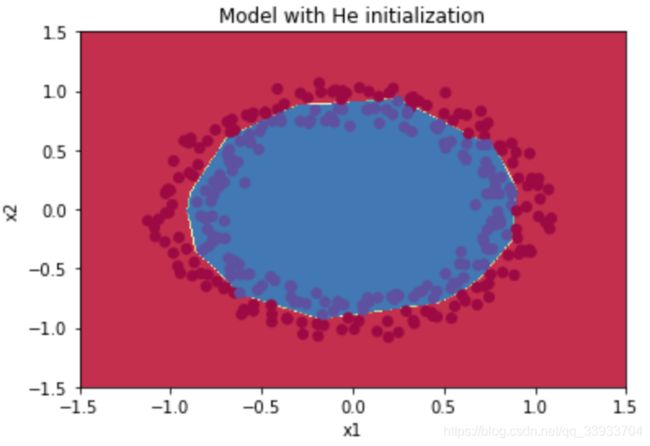
荷式就找到了这样一个合适的数值,具体来说。当我们的激活函数是采用的Relu,那么对应的就是乘上![]() ,对于其他的函数如tanh,就有
,对于其他的函数如tanh,就有 ![]() 或者
或者![]() 。又或者有更好的办法,毕竟这个方法只是15年提出的。
。又或者有更好的办法,毕竟这个方法只是15年提出的。