前几天线上一个项目监控信息突然报告异常,上到机器上后查看相关资源的使用情况,发现 CPU 利用率将近 100%。通过 Java 自带的线程 Dump 工具,我们导出了出问题的堆栈信息。

我们可以看到所有的堆栈都指向了一个名为 validateUrl 的方法,这样的报错信息在堆栈中一共超过 100 处。通过排查代码,我们知道这个方法的主要功能是校验 URL 是否合法。
很奇怪,一个正则表达式怎么会导致 CPU 利用率居高不下。为了弄清楚复现问题,我们将其中的关键代码摘抄出来,做了个简单的单元测试。
public static void main(String[] args) {
String badRegex = "^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\\\\/])+$";
String bugUrl = "http://www.fapiao.com/dddp-web/pdf/download?request=6e7JGxxxxx4ILd-kExxxxxxxqJ4-CHLmqVnenXC692m74H38sdfdsazxcUmfcOH2fAfY1Vw__%5EDadIfJgiEf";
if (bugUrl.matches(badRegex)) {
System.out.println("match!!");
} else {
System.out.println("no match!!");
}
}
当我们运行上面这个例子的时候,通过资源监视器可以看到有一个名为 java 的进程 CPU 利用率直接飙升到了 91.4% 。
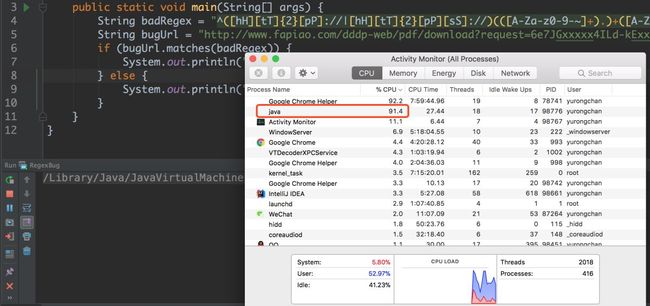
看到这里,我们基本可以推断,这个正则表达式就是导致 CPU 利用率居高不下的凶手!
于是,我们将排错的重点放在了那个正则表达式上:
^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\\/])+$
这个正则表达式看起来没什么问题,可以分为三个部分:
第一部分匹配 http 和 https 协议,第二部分匹配 www. 字符,第三部分匹配许多字符。我看着这个表达式发呆了许久,也没发现没有什么大的问题。
其实这里导致 CPU 使用率高的关键原因就是:Java 正则表达式使用的引擎实现是 NFA 自动机,这种正则表达式引擎在进行字符匹配时会发生回溯(backtracking)。而一旦发生回溯,那其消耗的时间就会变得很长,有可能是几分钟,也有可能是几个小时,时间长短取决于回溯的次数和复杂度。
看到这里,可能大家还不是很清楚什么是回溯,还有点懵。没关系,我们一点点从正则表达式的原理开始讲起。
正则表达式引擎
正则表达式是一个很方便的匹配符号,但要实现这么复杂,功能如此强大的匹配语法,就必须要有一套算法来实现,而实现这套算法的东西就叫做正则表达式引擎。简单地说,实现正则表达式引擎的有两种方式:DFA 自动机(Deterministic Final Automata 确定型有穷自动机)和 NFA 自动机(Non deterministic Finite Automaton 不确定型有穷自动机)。
对于这两种自动机,他们有各自的区别,这里并不打算深入将它们的原理。简单地说,DFA 自动机的时间复杂度是线性的,更加稳定,但是功能有限。而 NFA 的时间复杂度比较不稳定,有时候很好,有时候不怎么好,好不好取决于你写的正则表达式。但是胜在 NFA 的功能更加强大,所以包括 Java 、.NET、Perl、Python、Ruby、PHP 等语言都使用了 NFA 去实现其正则表达式。
那 NFA 自动机到底是怎么进行匹配的呢?我们以下面的字符和表达式来举例说明。
text="Today is a nice day." regex="day"
要记住一个很重要的点,即:NFA 是以正则表达式为基准去匹配的。也就是说,NFA 自动机会读取正则表达式的一个一个字符,然后拿去和目标字符串匹配,匹配成功就换正则表达式的下一个字符,否则继续和目标字符串的下一个字符比较。或许你们听不太懂,没事,接下来我们以上面的例子一步步解析。
- 首先,拿到正则表达式的第一个匹配符:d。于是那去和字符串的字符进行比较,字符串的第一个字符是 T,不匹配,换下一个。第二个是 o,也不匹配,再换下一个。第三个是 d,匹配了,那么就读取正则表达式的第二个字符:a。
- 读取到正则表达式的第二个匹配符:a。那着继续和字符串的第四个字符 a 比较,又匹配了。那么接着读取正则表达式的第三个字符:y。
- 读取到正则表达式的第三个匹配符:y。那着继续和字符串的第五个字符 y 比较,又匹配了。尝试读取正则表达式的下一个字符,发现没有了,那么匹配结束。
上面这个匹配过程就是 NFA 自动机的匹配过程,但实际上的匹配过程会比这个复杂非常多,但其原理是不变的。
文章首发于【博客园-陈树义】,点击跳转到原文《藏在正则表达式里的陷阱》
NFA自动机的回溯
了解了 NFA 是如何进行字符串匹配的,接下来我们就可以讲讲这篇文章的重点了:回溯。为了更好地解释回溯,我们同样以下面的例子来讲解。
text="abbc"
regex="ab{1,3}c"
上面的这个例子的目的比较简单,匹配以 a 开头,以 c 结尾,中间有 1-3 个 b 字符的字符串。NFA 对其解析的过程是这样子的:
- 首先,读取正则表达式第一个匹配符 a 和 字符串第一个字符 a 比较,匹配了。于是读取正则表达式第二个字符。
- 读取正则表达式第二个匹配符 b{1,3} 和字符串的第二个字符 b 比较,匹配了。但因为 b{1,3} 表示 1-3 个 b 字符串,以及 NFA 自动机的贪婪特性(也就是说要尽可能多地匹配),所以此时并不会再去读取下一个正则表达式的匹配符,而是依旧使用 b{1,3} 和字符串的第三个字符 b 比较,发现还是匹配。于是继续使用 b{1,3} 和字符串的第四个字符 c 比较,发现不匹配了。此时就会发生回溯。
- 发生回溯是怎么操作呢?发生回溯后,我们已经读取的字符串第四个字符 c 将被吐出去,指针回到第三个字符串的位置。之后,程序读取正则表达式的下一个操作符 c,读取当前指针的下一个字符 c 进行对比,发现匹配。于是读取下一个操作符,但这里已经结束了。
下面我们回过头来看看前面的那个校验 URL 的正则表达式:
^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\\/])+$
出现问题的 URL 是:
http://www.fapiao.com/dzfp-web/pdf/download?request=6e7JGm38jfjghVrv4ILd-kEn64HcUX4qL4a4qJ4-CHLmqVnenXC692m74H5oxkjgdsYazxcUmfcOH2fAfY1Vw__%5EDadIfJgiEf
我们把这个正则表达式分为三个部分:
- 第一部分:校验协议。
^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)。 - 第二部分:校验域名。
(([A-Za-z0-9-~]+).)+。 - 第三部分:校验参数。
([A-Za-z0-9-~\\/])+$。
我们可以发现正则表达式校验协议 http:// 这部分是没有问题的,但是在校验 www.fapiao.com 的时候,其使用了 xxxx. 这种方式去校验。那么其实匹配过程是这样的:
- 匹配到 www.
- 匹配到 fapiao.
- 匹配到
com/dzfp-web/pdf/download?request=6e7JGm38jf.....,你会发现因为贪婪匹配的原因,所以程序会一直读后面的字符串进行匹配,最后发现没有点号,于是就一个个字符回溯回去了。
这是这个正则表达式存在的第一个问题。
另外一个问题是在正则表达式的第三部分,我们发现出现问题的 URL 是有下划线(_)和百分号(%)的,但是对应第三部分的正则表达式里面却没有。这样就会导致前面匹配了一长串的字符之后,发现不匹配,最后回溯回去。
这是这个正则表达式存在的第二个问题。
解决方案
明白了回溯是导致问题的原因之后,其实就是减少这种回溯,你会发现如果我在第三部分加上下划线和百分号之后,程序就正常了。
public static void main(String[] args) {
String badRegex = "^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~_%\\\\/])+$";
String bugUrl = "http://www.fapiao.com/dddp-web/pdf/download?request=6e7JGxxxxx4ILd-kExxxxxxxqJ4-CHLmqVnenXC692m74H38sdfdsazxcUmfcOH2fAfY1Vw__%5EDadIfJgiEf";
if (bugUrl.matches(badRegex)) {
System.out.println("match!!");
} else {
System.out.println("no match!!");
}
}
运行上面的程序,立刻就会打印出match!!。
但这是不够的,如果以后还有其他 URL 包含了乱七八糟的字符呢,我们难不成还再修改一遍。肯定不现实嘛!
其实在正则表达式中有这么三种模式:贪婪模式、懒惰模式、独占模式。
在关于数量的匹配中,有 + ? * {min,max} 四种两次,如果只是单独使用,那么它们就是贪婪模式。
如果在他们之后加多一个 ? 符号,那么原先的贪婪模式就会变成懒惰模式,即尽可能少地匹配。但是懒惰模式还是会发生回溯现象的。例如下面这个例子:
text="abbc"
regex="ab{1,3}?c"
正则表达式的第一个操作符 a 与 字符串第一个字符 a 匹配,匹配成功。于是正则表达式的第二个操作符 b{1,3}? 和 字符串第二个字符 b 匹配,匹配成功。因为最小匹配原则,所以拿正则表达式第三个操作符 c 与字符串第三个字符 b 匹配,发现不匹配。于是回溯回去,拿正则表达式第二个操作符 b{1,3}? 和字符串第三个字符 b 匹配,匹配成功。于是再拿正则表达式第三个操作符 c 与字符串第四个字符 c 匹配,匹配成功。于是结束。
如果在他们之后加多一个 + 符号,那么原先的贪婪模式就会变成独占模式,即尽可能多地匹配,但是不回溯。
于是乎,如果要彻底解决问题,就要在保证功能的同时确保不发生回溯。我将上面校验 URL 的正则表达式的第二部分后面加多了个 + 号,即变成这样:
^([hH][tT]{2}[pP]:\/\/|[hH][tT]{2}[pP][sS]:\/\/)
(([A-Za-z0-9-~]+).)++ --->>> (这里加了个+号)
([A-Za-z0-9-~_%\\\/])+$
这样之后,运行原有的程序就没有问题了。
最后推荐一个网站,这个网站可以检查你写的正则表达式和对应的字符串匹配时会不会有问题。
Online regex tester and debugger: PHP, PCRE, Python, Golang and JavaScript
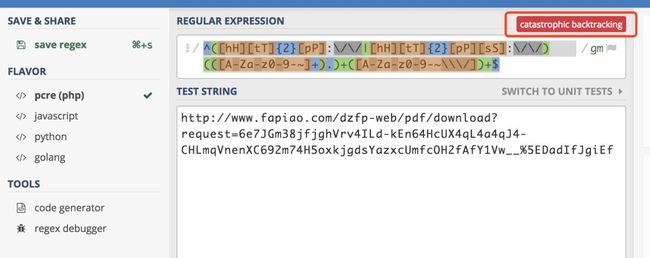
例如我本文中存在问题的那个 URL 使用该网站检查后会提示:catastrophic backgracking(灾难性回溯)。
当你点击左下角的「regex debugger」时,它会告诉你一共经过多少步检查完毕,并且会将所有步骤都列出来,并标明发生回溯的位置。
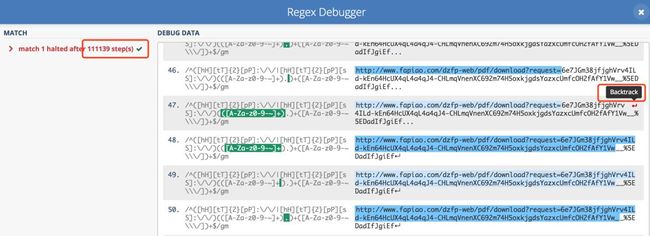
本文中的这个正则表达式在进行了 11 万步尝试之后,自动停止了。这说明这个正则表达式确实存在问题,需要改进。
但是当我用我们修改过的正则表达式进行测试,即下面这个正则表达式。
^([hH][tT]{2}[pP]:\/\/|[hH][tT]{2}[pP][sS]:\/\/)(([A-Za-z0-9-~]+).)++([A-Za-z0-9-~\\\/])+$
工具提示只用了 58 步就完成了检查。
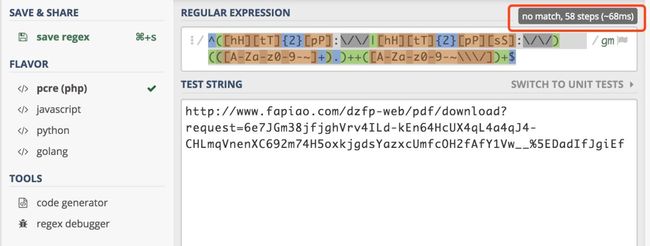
一个字符的差别,性能就差距了好几万倍。
树义有话说
一个小小的正则表达式竟然能够把 CPU 拖垮,也是很神奇了。这也给平时写程序的我们一个警醒,遇到正则表达式的时候要注意贪婪模式和回溯问题,否则我们每写的一个表达式都是一个雷。
通过查阅网上资料,我发现深圳阿里中心 LAZADA 的同学也在 17 年遇到了这个问题。他们同样也是在测试环境没有发现问题,但是一到线上的时候就发生了 CPU 100% 的问题,他们遇到的问题几乎跟我们的一模一样。有兴趣的朋友可以点击阅读python中使用正则表达式将所有符合条件的字段全部提取出来
虽然把这篇文章写完了,但是关于 NFA 自动机的原理方面,特别是关于懒惰模式、独占模式的解释方面还是没有解释得足够深入。因为 NFA 自动机确实不是那么容易理解,所以在这方面还需要不断学习加强。欢迎有懂行的朋友来学习交流,互相促进。
以上就是Java正则表达式里隐藏的陷阱的详细内容,更多关于Java正则表达式的资料请关注脚本之家其它相关文章!