大数据相关软件、环境(伪分布式)搭建全记
前言:
因为升级了下电脑的硬件,所以重装了下系统,重新安装软件的过程中发现还没有记录过安装的整个过程,所以来csdn记录下,以便以后安装时参考。
注:我安装的三台虚拟机的IP分别为:192.168.1.101,192.168.1.102,192.168.1.103
备注:凉了,回了学校,用的局域网,分配了IP,用不了桥接了,改成了HOST-ONLY,这部分修改就不写了
附:算了还是说下host-only的配置吧,只说修改部分,省着之后进公司后万一用到呢…
1、首先:我们想让虚拟机再host-only下也能访问网络,打开宿主机的网络与共享中心,点击你能上网的按个网卡(我的是本地连接),然后点击属性——》共享——》

2、打开vbox,设置虚拟机网络连接方式为host-only
3、管理——》全局设置——》网络

双击host-only这个网卡

记住这里的网卡ip,也就是你之后要设置的网关(建议不要设置成比较容易记的192.168.1.1,这个网段是留给wifi和路由器使用的,所以就按照默认的就好)
4、最后我们按照现在的配置重新从下面centos网络配置1走到centos网络配置2就可以了,至于配置文件里具体修改什么我就不说了,自己简单思考下应该就能明白,之后虚拟机就可以ping通网卡和外网了,然后就用xterm就可以了。
需要安装的软件及环境
top
VirtualBox
CentOs6.10-x86_64-minimal
MobaXterm
jdk7
Centos.repo
hadoop-2.7.7
HIVE-2.1.1
Zookeeper2.3.12
Scala2.11.12
Kafka2.11-0.9.0.1
slf4j-1.7.25
Spark2.3.2
注:hadoop官网声明jdk7和hadoop2.7版本较匹配,之前用hadoop2.9和jdk8出现了很多问题,centos最好用64位的,现在hadoop发行版本只支持64位linux系统,32位的也可以不过很麻烦,咳,踩过很多坑就不一一赘述了…
VirtualBox
1、下载地址:
Oracel virtualbox官网
2、选择virtualbox的原因:
查了下,virtualbox占用资源比vmware小很多,运行集群时消耗较小。而且box运行会更加稳定,vmware有时会因为休眠而挂掉的现象。综上virtualbox更加适合Hadoop集群。
3、版本选择:
我的系统是WIN7,没有选择最新的VirtualBox5.2版本,担心会出现兼容问题(据网友反应),所以下载了4.1版本,相对稳定一些,防止之后搞项目的时候集群挂掉了,重新安装倒没什么,里面的数据就凉了啊,稳一点,稳一点。
4、下载相应版本后直接安装,没什么可说的
CentOs
1、下载地址:
Oracle CentOS官网
2、选择CentOs的原因:
目前主流技术控、大牛喜欢使用的就是RedHat系列,而且RedHat虽然长相一般,但是性能强悍,如果你不喜欢那些花里胡哨的东西,只注重内涵的话,这一系列将会是你的最爱。CentOS及时RedHat系列收费版RHEL的社区免费克隆版,对于我们初学者而言很适合。
3、版本选择:
反正是搭建集群,所以选择了x86_64(64位系统)的minimal系统,很小并且没有图形化界面,但是作为集群节点足够用了。
4、过程:
在官网点击get——》old version——》x86_64——》minimal就可以了,才400多M,很适合用来搭建集群节点。
VirtualBox安装CentOS
1、打开VirtualBox,点击新建
2、创建虚拟机名称,选择linux系统和redhat版本
3、分配1024MB内存
4、创建新的虚拟硬盘
5、选择VDI
6、动态分配
7、选择虚拟硬盘位置,建议不选择在主分区内的文件夹(如果建的节点少而且主分区是固态硬盘,也可以选择主分区,这样文件读写操作会快很多。不过我初学Spark,很多都是基于内存的操作,就不选择主分区了,之后如果操作MapReduce多的话再搭建几个主分区的虚拟机就行了)
8、创建完成
9、创建完的虚拟机——》设置——》网络——》桥接网卡
10、点击启动
11、选择介质位置(系统iso,iso最好复制成三个副本,每个虚拟机用其中一个)
12、启动
13、进入安装界面,选择第一项安装系统
14、选择SKIP
15、Next——》English——》美国英语式——》yes discard any data
16、主机名——》时区——》密码——》Replace Existing Linux System(s)——》write changes to disk
17、等待安装完成
18、Reboot
CentOS节点网络配置1
1、分配IP

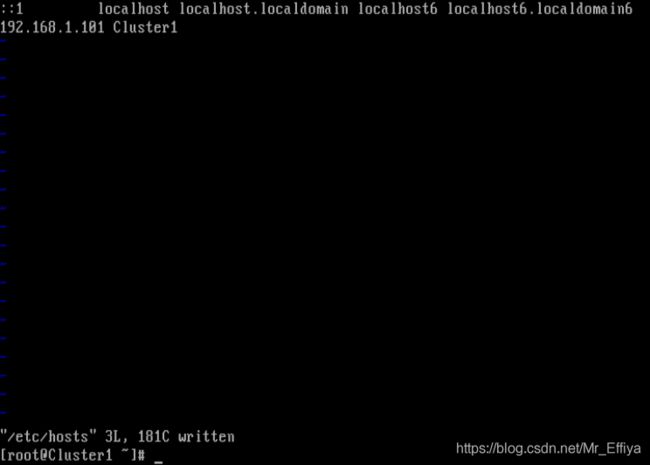
2、宿主机修改hosts文件
C:\Windows\System32\drivers\etc目录下的hosts文件

宿主机就可以ping通虚拟机了
3、登录root账户
MobaXterm
SSH客户端神器,还可以上传文件,就不要用什么CRT,Xshell,putty了,安装注册还贼麻烦,甚至还得安装winscp
MobaXterm官网
解压安装
CentOS节点网络配置2
1、修改网卡eth0配置信息
![]()
DEVICE=eth0
HWADDR=08:00:27:4C:31:E7
TYPE=Ethernet
UUID=a69ef2c3-1745-4991-9c3e-57e4b4db5a14
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.1.101
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
改为如上代码,解析如下:
DEVICE:网络接口名称
BOOTPROTO:系统启动地址协议
none:不使用启动地址协议
bootp:BOOTP协议
dhcp:DHCP动态地址协议
static:静态地址协议
ONBOOT:系统启动时是否激活
yes:系统启动时激活该网络接口
no:系统启动时不激活该网络接口
IPADDR:IP地址
NETMASK:子网掩码
GATEWAY:网关地址
2、重启网卡
![]()
3、关闭防火墙(其实也可以不开,把相应的所有端口打开就行)
宿主机再控制面板里关闭
节点机:


4、配置dns服务器
这里看下你宿主机的DNS服务器是多少,可以在cmd中ipconfig /all查看,也可以在本地连接——》属性里的IPV4中设置DNS服务器地址

nameserver xxx.xxx.xxx.xxx
测试通过

5、yum配置
下载centos-6.repo,上传到节点上的/etc/local目录下

将centos-6.repo文件内容中的所有的gpgcheck修改为0(不进行gpg校验)

运行三条命令
yum clean all(清楚yum缓存,yum 会把下载的软件包和header存储在cache中,而不自动删除。如果觉得占用磁盘空间,可以使用yum clean指令进行清除,更精确 的用法是yum clean headers清除header,yum clean packages清除下载的rpm包,yum clean all一全部清除。)
yum makecache(yum makecache就是把服务器的包信息下载到本地电脑缓存起来,配合yum -C search xxx使用,不用上网检索就能查找软件信息)
yum install telnet
选择y,下载下
6、安装jdk
下载地址:上网上找资源吧,Oracle只对购买者开放jdk7版本
选择linux64位版本jdk-7u80-linux-x64.tar.gz上传到/usr/local目录下
解压:tar -xzvf jdk-7u80-linux-x64.tar.gz(-x 从备份文件中还原文件,-z通过gzip命令处理备份文件,-v 显示指令执行过程,-f 指定备份文件)
配置jdk环境变量
mv jdk1.8.0_191 jdk
vi /root/.bashrc
#enviroment variables
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
source /root/.bashrc
测试成功:

最后rm -f /etc/udev/rules.d/70-persistent-net.rules(网卡相关信息,防止不匹配,删除,重启就ok了),记得删除上传的jdk压缩包
7、再安装两个节点就OK了
注意事项:虚拟机之间最好用不同的镜像文件,防止出现一些匪夷所思的问题。
安装完三台虚拟机节点后,修改hosts文件,添加另外两台虚拟机的ip和hostname
宿主机的hosts文件也要把这三个虚拟机节点的ip,hostname加进去
SSH免密钥登录
1、生成ssh rsa公钥私钥文件
ssh-keygen -t rsa
-t 指定密钥类型
然后一直回车就行
2、将公钥文件(默认在/root/.ssh目录下的id_rsa.pub)拷贝到authorized_keys文件中
cd /root/.ssh
cp id_rsa.pub authorized_keys
3、将拷贝的公钥文件发送给其他节点机器
ssh-copy-id -i hostname
这里需要输入其他节点机的密码
注:看到网上有遇到ssh-copy-id后还是无法免秘钥登录的问题,是因为id_rsa.pub不可读或不可执行,提升一下权限就行,或者使用root账户进行操作
4、测试ssh免密钥登录通过

5、重复上述操作在其他机器上
注:此时其他机器上已经有authorized_keys文件了,所以把自己机器密钥加入authorized_keys中时,要追加到文件末尾
cat id_rsa.pub >> authorized_keys
Hadoop集群搭建
1、Hadoop官网
2、上传到/usr/local目录下
3、解压
tar -xzvf hadoop-2.7.7.tar.gz
mv hadoop-2.7.7 hadoop
在/root/.bashrc中加入
export HADOOP_HOME=usr/local/hadoop
PATH后加入:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出后
source /root/.bashrc
4、修改配置文件
注:刚才按照教程配置到hdfs-site.xml时对配置参数作用好奇就去官网逛了一圈,发现不同版本的参数名和参数所在文件都发生了较大的改动,不能按照视频教程里的去配置了,官方教程走一波
官方节点搭建教程
1、修改core-site.xml文件

这hostname:port中的hostname一定要和namenode的主机名一致,因为他映射着ip地址
2、修改hdfs-site.xml文件

hdfs-default.xml的参数详情
3、修改mapreduce-site.xml.template文件
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml

mapreduce-default.xml参数详情
4、修改yarn-site.xml文件
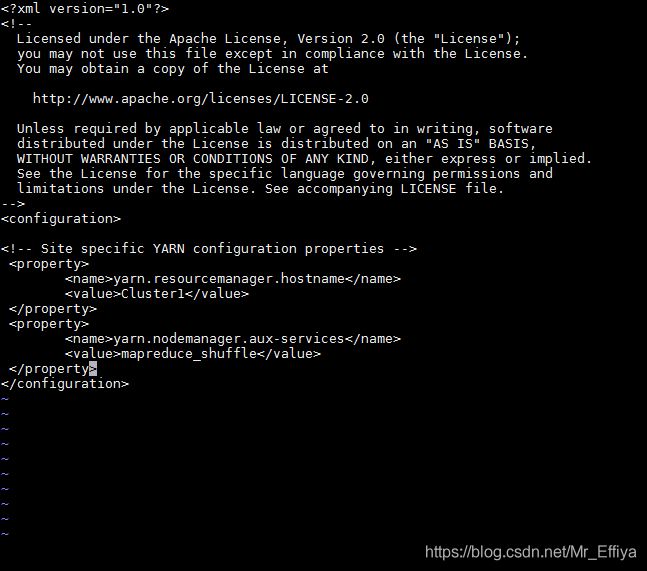
yarn-default.xml参数详情
5、修改slaves文件

顺便说一句,slaves文件是指定datanode节点的文件,里面存放datanode的hostname,处于安全性考虑,防止其他用户恶意的把自己设置为datanode而导致的数据泄露,解决方法为:可以在hdfs-site.xml文件中添加
dfs.hosts
/usr/local/hadoop/etc/hadoop/slaves
指定datanode的节点为该文件中的节点,而且从slaves文件中把节点删除后,namenode节点会自动拒绝那个datanode节点的数据传输,并把该datanode节点的数据备份到其他datanode节点上。
注:配置文件其他参数可能之后遇到问题时会用到,时间关系现在就不去深究到底还需要加其他的什么参数,这些基本的就够了
附:
/etc/profile、/etc/bashrc、/.bash_profile、/.bashrc很容易混淆,他们之间有什么区别?它们的作用到底是什么?
/etc/profile: 用来设置系统环境参数,比如$PATH. 这里面的环境变量是对系统内所有用户生效的。
/etc/bashrc: 这个文件设置系统bash shell相关的东西,对系统内所有用户生效。只要用户运行bash命令,那么这里面的东西就在起作用。
~/.bash_profile: 用来设置一些环境变量,功能和/etc/profile 类似,但是这个是针对用户来设定的,也就是说,你在/home/user1/.bash_profile 中设定了环境变量,那么这个环境变量只针对 user1 这个用户生效.
~/.bashrc: 作用类似于/etc/bashrc, 只是针对用户自己而言,不对其他用户生效。
另外/etc/profile中设定的变量(全局)的可以作用于任何用户,而~/.bashrc等中设定的变量(局部)只能继承/etc/profile中的变量,他们是"父子"关系.
~/.bash_profile 是交互式、login 方式进入 bash 运行的,意思是只有用户登录时才会生效。
~/.bashrc 是交互式 non-login 方式进入 bash 运行的,用户不一定登录,只要以该用户身份运行命令行就会读取该文件。
6、配置hadoop环境变量
vi /root/.bashrc
添加如下代码:
export HADOOP_HOME=/usr/local/hadoop
PATH中追加
:HADOOP_HOME/bin:HADOOP_HOME/sbin
7、在另外两台机器上修改配置文件
将Cluster1上的hadoop目录和/root/.bashrc文件复制到其他两台机器上
在配置完的Cluster1上运行
scp -r hadoop root@Cluster2:/usr/local
scp -r /root/.bashrc root@Cluster2:/root
ssh Cluster2
mkdir /usr/local/data
source /root/.bashrc
logout
scp -r hadoop root@Cluster3:/usr/local
scp -r /root/.bashrc root@Cluster3:/root
ssh Cluster3
mkdir /usr/local/data
source /root/.bashrc
logout
scp -r 递归复制整个目录
7、格式化namenode,启动集群
hdfs namenode -format
start-dfs.sh
使用jps和50070端口查看是否成功
注:在启动的时候由于编码问题,打错了几个字母,就重新format,结果发现namenode能启动nodemanager,而datanode却启动不了,查了下,有两种解决方案:
1)发现原来是因为重新format时,data目录下会产生新的namespaceid,而datanode的data目录里还保留着原来的namespaceid,所以需要把datanode目录下的文件全部删除后,重新format(若datanode和namenode)
2)更新有问题的datanode的namespaceID
1.停止datanode
2.编辑
3.重新启动datanode
我的情况是datanode的VERSION文件中没有namespaceid,我就把namenode的那么文件夹下的VERSION中的namespaceid复制过去了
8、启动yarn
start-yarn.sh
namenode:resourcemanager,nodemanager
datanode:nodemanager
HIVE安装及配置
1、下载HIVE2.1.1版本
1)HIVE2.3.4版本与HADOOP2.7版本配合相对稳定(建议下载对应版本,自己因为版本问题被坑惨了)
2)下载地址
2、安装mysql
1)在我不太了解大数据生态系统的时候我就会有这样一个疑问:为什么不用HBASE,HBASE不是在大数据处理方面比Mysql表现的更好么。安装mysql的原因是什么呢。
2)为什么安装mysql:这位博主给出了答案,看完后受益匪浅 使用了hive为什么要加mysql?
3)安装mysql server
yum install -y mysql-server
service start mysqld
chkconfig mysqld on
-y 等待用户输入时,这个选项自动提供yes的响应
4)安装mysql connector
yum install -y mysql-connector-java
5)将mysql connector拷贝到/hive/lib中
cp /usr/share/java/mysql-connector-java-5.1.17.jar /usr/local/hive/lib
6)mysql命令行里创建hive元数据库,并对hive授权
mysql
create database if not exists hive_metadata;
grant all privileges on hive_metadata.* to 'hive'@'%' identified by 'hive';
grant all privileges on hive_metadata.* to 'hive'@'localhost' identified by 'hive';
grant all privileges on hive_metadata.* to 'hive'@'spark1' identified by 'hive';
flush privileges;
use hive_metadata;
Grant可以把指定的权限分配给特定的用户,如果这个用户不存在,则会创建一个用户
命令格式
grant 权限 on 数据库名.表名 to 用户名@登陆方式 identified by ‘password1’;
grant select,insert,update,delete on auth.* to user1@localhost identified by ‘password’;
权 限:select,insert,update,delete,drop,index,all,privileges(表示赋予用户全部权限跟all一样)
数据库 :当数据库名称.表名称被*.*代替,表示用户拥有操作mysql上所有数据库所有表的权限
登陆方式:即用户地址,可以是localhost,也可以是ip地址、机器名字、域名.也可以用’%'表示从任何地址连接
‘password’:可以为空,但是为空这表示只能从本地登陆,建议不能为空
FLUSH PRIVILEGES 每当重新赋权后,为了以防万一,让新权限立即生效,一般都执行一把,目地是从数据库授权表中重新装载权限到缓存中。
USE 语句用于选取当前数据库架构中存在的任一数据库
3、修改配置文件
这里我要说一个大坑,困扰了我一个下午,网上还查不到原因,后来突然猜到了错误的原因,大家注意一下,下面修改hive-site.xml文件的时候不要直接把修改内容直接敲到文件里,而是使用vi的查找命令/pattern查找对应参数项,然后修改对应的value,还是不够仔细,沉下心沉下心,问题总会被解决的
1)hdfs中创建目录
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir -p /user/hive/tmp
hdfs dfs -mkdir -p /user/hive/log
hdfs dfs -chmod -R 777 /user/hive/warehouse
hdfs dfs -chmod -R 777 /user/hive/tmp
hdfs dfs -chmod -R 777 /user/hive/log
hdfs dfs -mkdir -p 根据路径逐层递归创建目录
hdfs dfs -chmod -R 递归更改文件权限
2)hive-site.xml
cp hive-default.xml.template hive-site.xml
vi hive-site.xml
使用vi的查找命令:/pattern修改一下参数的value
javax.jdo.option.ConnectionURL
jdbc://mysql://Cluster1:3306/hive_metadata?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
hive
javax.jdo.option.ConnectionPassword
hive
hive.exec.scratchdir
/user/hive/tmp
hive.metastore.warehouse.dir
/user/hive/warehouse
hive.querylog.location
/user/hive/log
3 )hive-env.sh
cp hive-env.sh.template hive-env.sh
4)
cp hive-log4j2.properties.template hive-log4j2.properties
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
5)初始化
schematool -initSchema -dbType mysql
6)测试是否安装成功
hive
hive>show databases;
hive>create table t1(id int);
hive>select * from t1;
hive>drop table t1;
hive>quit;
Zookeeper安装及配置
1、下载地址
下载稳定版本即可
2、将压缩包上传到Cluster1节点的/usr/local目录下
3、解压并配置环境变量
tar -xzvf zookeeper-3.4.12.tar.gz
rm -rf zookeeper-3.4.12.tar.gz
mv zookeeper-3.4.12/ zk
vi /root/.bashrc
export ZOOKEEPER_HOME=/usr/local/zk
export PATH=$PATH:$ZOOKEEPER_HOME/bin
4、修改配置文件
cd /usr/local/zk/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
修改并加入如下代码
dataDir=/usr/local/zk/data
dataLogDir=/usr/local/zk/logs
server.0=Cluster1:2888:3888
server.1=Cluster2:2888:3888
server.2=Cluster3:2888:3888
dataDir:数据目录
dataLogDir:日志目录,不设置将使用dataDir作为dataLogDir
创建/usr/local/zk/data目录mkdir /usr/local/zk/data
cd /usr/local/zk/data
vi myid
0
myid:server的标识,应与zoo.cfg文件中的相对应
5、将zk文件夹和.bashrc文件递归复制到其他两台节点
scp -r zk root@Cluster2:/usr/local
scp -r zk root@Cluster3:/usr/local
scp -r /root/.bashrc root@Cluster2:/root
scp -r /root/.bashrc root@Cluster3:/root
ssh Cluster2
source /root/.bashrc
logout
ssh Cluster3
source /root/.bashrc
logout
分别修改Cluster2和Cluster3中的myid文件为1,2
6、zookeeper在3.4.0之后支持自动清理日志和快照功能
在zoo.cfg中添加两个参数配置:
autopurge.purgeInterval 这个参数指定了清理频率,单位是小时,需要填写一个1或更大的整数,默认是0,表示不开启自己清理功能。
autopurge.snapRetainCount 这个参数和上面的参数搭配使用,这个参数指定了需要保留的文件数目。默认是保留3个。
建议每8小时清理一次,保留66个文件,当然也可以不用设置。
7、启动zookeeper
在三台机器上运行zkServer.sh start
查看状态zkServer.sh status
进入zookeeper命令行
zkCli.sh
Scala安装及配置
1、下载地址
2、将压缩包上传到/usr/local目录下
3、解压并配置环境变量
tar -xzvf scala-2.11.12.tgz
rm -rf scala-2.11.12.tgz
mv scala-2.11.12/ scala
vi /root/.bashrc
添加并修改如下代码
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
source /root/.bashrc
4、分别在Cluster2,Cluster3上执行上述步骤,并将Cluster1上的.bashrc文件拷到另外两台机器上
Kafka安装及配置1
1、下载地址
2、上传到/usr/local目录下
3、解压kafka压缩包
4、修改/usr/local/config/server.properties
broker.id:从0开始的集群中broker的唯一id
zookeeper.connect=192.168.137.101,192.168.137.102,192.168.137.103
log.dirs=/usr/local/logs
创建logs文件夹
cd /usr/local/kafka
mkdir logs
slf4j安装
1、下载地址
2、压缩包上传到/usr/local目录下
3、解压
unzip slf4j-1.7.25.zip
4、把slf4j中的slf4j-nop-1.7.25.jar复制到kafka的libs目录下
cp slf4j-nop-1.7.25.jar /usr/local/kafka/libs
Kafka安装及配置2
1、将kafka拷贝到另外两台机器上
2、修改server.properties文件
将broker.id分别修改为1,2
3、分别在三台机器上启动kafka
cd /usr/local/kafka
nohup bin/kafka-server-start.sh config/server.properties &
本人测试以上版本匹配是不会出现因为版本不兼容而导致的kafka启动错误
4、jps检查是否启动成功
5、启动kafka并测试
nohup bin/kafka-server-start.sh config/server.properties
nohup command & 不断在后台运行
挂起kafka进程
创建topic
bin/kafka-topic.sh --zookeeper 192.168.137.101:==2181==,192.168.137.102:==2181==,192.168.137.103:==2181== -topic TestTopic --replication-factor 1 --partitions 1 --create
replication-fator:副本数
partitions:分区数
topic:topic name
开启producer
bin/kafka-console-producer.sh --broker-list 192.168.137.101:==9092==,192.168.137.102:==9092==,192.168.137.103:==9092== -topic TestTopic
在其他两台机器或者该机器的克隆终端内开启消费者
bin/kafka-console-consumer.sh --zookeeper 192.168.137.101:==2181==,192.168.137.102:==2181==,192.168.137.103:==2181== -topic TestTopic --from-beginning
这里注意一下,producer使用的是2181端口,consumer使用的是9092端口
在producer终端中键入字符,会发现在consumer终端中出现相应字符,证明环境搭建成功
Spark安装及配置
1、下载地址
2、版本选择问题
Spark2.3.2和hadoop2.7 and later以及Scala2.11版本相兼容
3、
未完待续。。。。。。。。。。。。。。。