https://github.com/datawhalechina/joyful-pandas
基于自己的日常工作,整理必备的一些知识点,覆盖95%+的使用场景。
第一章 基础
1.1 文件读取与写入
df = pd.read_csv('data/table.csv')
df_excel = pd.read_excel('data/table.xlsx')
df.to_csv('data/new_table.csv')
df.to_excel('data/new_table2.xlsx', sheet_name='Sheet1')
1.2 基本数据结构
Series
-
查看Series自带的额方法
 image.png
image.png
Dataframe
- 新增列的方法
常规方法
df['B']=list('abc')
df.assign(B=pd.Series(list('abc)))
df.merge(pd.Dataframe({'B':['abc']}, how='left', left_index=True, right_index=True))
一般用的都是第一种和第三种方法,实际上第二种方法和第三种方法是等效的,都是讲究索引对齐性(left_jone,index),在索引未严格对其的情况下就是缺失值。用第二种方法其实更简便,但用三种方法更普遍。。
转换
s.to_frame()
s.to_fame().T
1.3 常用基本函数
df.head()
df.tail()
df.unique()
df.nunique()
df.count() #各列的非空值个数
df.value_counts()
df.info()
df.describe()
df.describe(percentiles=[.05, .25, .75, .95]) # 可以自行选择分位数
df['Math'].idxmax()
df['Math'].nlargest(3)
如果要返回最大几个值的index,可以用nlargest再返回index,也可以sort_values再返回index。和numpy里面的np.argsort()可以起到一样的效果
df['Math'].clip(33,80) #截断,最小值和最大值进行限制
df.replace({'Address':{'street_1':'one','street_2':'two'}}) #字典替换,这里是限定支队Address列进行替换
df.apply(lambda x : x.apply(lambda x:str(x)+'new')) #单列apply和全局apply的应用,相当于applymap
1.4 排序
df.sort_index()
df.sort_values()
第二章 索引
2.1 单级索引
- loc
包括单列/行,多列/行,行列联合,函数索引和布尔索引(函数索引和布尔索引本质上无区别)
df.loc[:,'Height':'Math'] #这样的多列索引也是可以的
df.loc[[True if i[-1]=='4' or i[-1]=='7' else False for i in df['Address'].values]].head() #这样的布尔索引可能略绕,不如直接把需要提取的index提取出来
- iloc
- []操作符
严格来说,[]索引只适合布尔索引和列索引,对行索引要用loc和iloc,不然很容易造成困扰。
df[df>80]
df['math']
- 布尔索引
广泛使用的布尔符号:&, |, ~, isin
df[(df['Gender']=='F')&(df['Address']=='street_2')].head()
-
快速标量索引
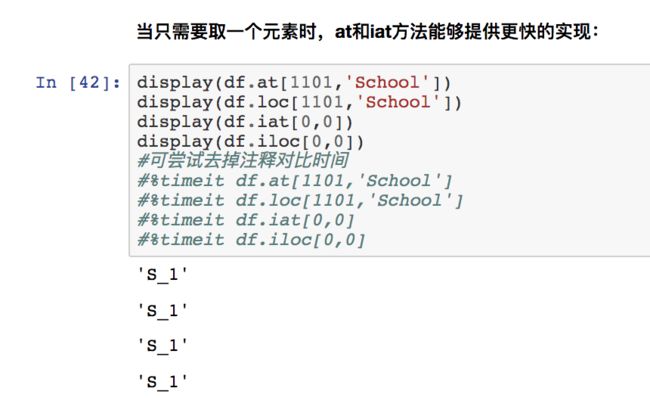 image.png
image.png
看需求使用吧,在数据量大的时候特别需要用到
区间索引
-
interval_range可以创造区间(注意调节左右开闭性)
 image.png
image.png -
pd.cut可以将数值进行区间统计
 image.png
image.png
当然也而已利用interval_range确定区间,而不是自己输入bins
df['bins'] = pd.cut(df['math'],pd.interval_range(start=0,end=100,freq=20,closed='left'))
- 区间索引
df.set_index('bins').loc[[30,50]] #只要区间和30、50有交叉就会被选中
区间索引虽然用得少,但是一旦需要用的时候如果掌握不好就很麻烦。总的来说,pd.interval_range基本只在生成df的时候使用,对已有的数据,一般采用pd.cut和loc的方法来进行索引!!
2.2 多级索引
- 创建多级索引的方式
tuple\array等等都可以,掌握两种就可以了
from_tuples(虽然是from_tuples,但其实tuples,arrays都可以自动转换)
arrays = [['A','a'],['A','b'],['B','a'],['B','b']]
mul_index = pd.MultiIndex.from_tuples(arrays, names=('Upper', 'Lower'))
pd.DataFrame({'Score':['perfect','good','fair','bad']},index=mul_index)
names不是必须的,看自己需要,我觉得没啥实际意义。。
from_product(from_tuples是完全匹配,from_product是两两相乘的方式)

- 切片索引
display(df.loc[[('A','a'),('B','a')]])
display(df.loc[['A','B']])
df.loc[[('A'),('B','a')]] #会报错,所以对mul_index必须统一level进行loc索引
差不多可以知道对mul_index进行loc索引很复杂,要不然就用布尔索引,要不然就转换成单一index后进行索引。。
2.3 索引设定
- reindex\reset_index\set_index
reindex相当于loc的功能,原始没有的index可以选择填充(默认为空值填充)
reset_index会将当前index生成为新的一列
set_index删除当前index并将另一列设置为index,利用append参数可以将当前索引维持不变

set_index是最灵活的,可以覆盖reindex的功能
- rename_axis和rename
rename_axis是修改index名和columns名,rename是修改里面的label。。。而且rename_axis有点绕,理论上index_name和columns_name都没有存在的必要,所以这种情况下用rename来直接修改label就可以了。对于mul_index的情况
arrays = [['A','a'],['A','b'],['B','a'],['B','b']]
mul_index = pd.MultiIndex.from_tuples(arrays, names=('Upper', 'Lower'))
df = pd.DataFrame({'Score':['perfect','good','fair','bad']},index=mul_index)
df.rename_axis(index=['A','B']) #可以
df.rename_axis(index={'Upper':'A','Lower':'B'}) #可以
df.rename_axis({'Upper':'A','Lower':'B'},aixs=0) #不可以
df.rename_axis(['A','B'],axis=0) #可以
所以不是mul_index基本都不会用到
2.4 索引型函数
-
where和mask
where类似于布尔索引,但布尔索引是只显示符合条件的行列,where是显示全部行列,而不符合的行全部显示为空值
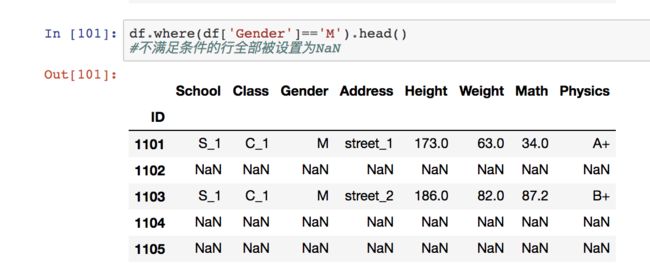 image.png
image.png
mask则是符合的行全部显示为空值
2.5 重复项处理
- duplicated和drop_duplicates
duplicated返回布尔Series,drop_duplicates保留经过删除重复项之后的行。
可以自行设置是以某一列去除重复行还是以全部列去除重复行。
2.5 抽样
df.sample(n=5) #随机抽样5行
df.sample(n=5,axis=1) #随机抽样5列
df.sample(frac=0.5) #随机比例抽样
df.sample(n=5,inplace=True) #有放回抽样
df.sample(n=5, weights = df['math']) #设置权重,这里是以某一列的数值为权重来决定该行被抽中的概率,自动归一化
第三章 分组
3.2 groupby
- 分组
df_grouped = df.groupby('col') #以某列分组可以,每个组的Dataframe的index仍然是原始的index,而不是col
df_grouped = df.groupby(level=0) #以index进行分组,level都是针对index而言的,一个单索引的level只能等于0!!
df_grouped = df.set_index('col').groupby('col') #也是以index进行分组,不过这个时候不等同于df.groupby('col'),每个组的Dataframe的index是col

实际上分组的方式特别灵活,可以参见下面的连续性变量分组
- 组的容量和组数
df_grouped.size() #各个组的行数
df_grouped.ngroups #组的数目
df_grouped.groups #各个组的详情
df_grouped.get_group('a') # 获取特定组,dataframe格式
其实size是最方便的,相当于value_counts的功能,能够直接简单的知道有多少分组
- 组的遍历
for name,group in df_grouped:
print(name)
display(group)
-
连续型变量分组
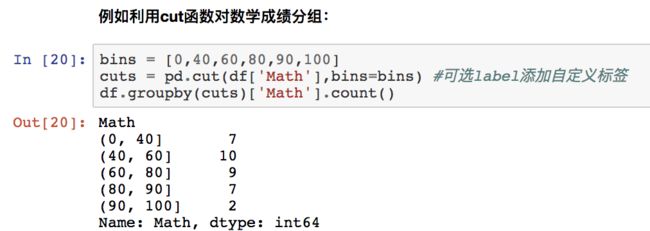 image.png
image.png
也可以先加入一列interval_range后以该列进行分组
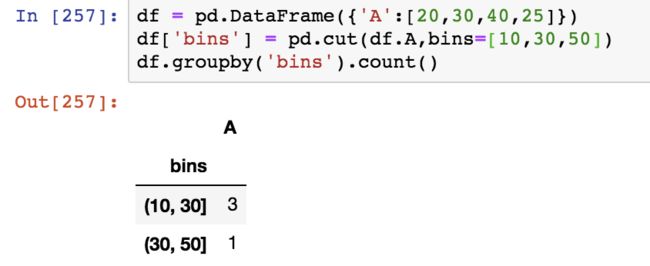 image.png
image.png
3.3 SAC
统一讲一下agg,transform,apply的区别
- 在不做groupby的情况下,没有agg的事。。。然后transform和apply本质上无区别,都是对列进行运算,但是不是聚合运算
-
在做了groupby的情况下,agg内置函数最快,transform针对非groupby列进行聚合运算,apply针对包括groupby列进行聚合运算。。当然如果限定了对某列进行运算的话,transform和apply无本质区别。。
 image.png
image.png - 还有就是applymap是针对所有值进行运算。
总结:在内置函数聚合运算的时候用agg,其他时候用apply是基本完全可以替代transform的,transform和apply只有一点是否要对groupby列进行聚合运算的差异。
第四章 变形
4.1 透视表
- pivot_table
透视的核心四要素是:index(行)、columns(列)、value(值)和运算方式(aggfunc),如果不选aggfunc就是默认mean
pd.pivot_table(df,index='School',columns='Gender',values='Height',aggfunc=['mean','sum'],margins=True).head()
margin可以汇总状态,相当于不再细分value。。

如果是要计数的话,必须选定一列,然后进行count:
pd.pivot(df, index=A,columns=B,values=‘C’,aggfunc=['count'])
- crosstab
貌似属于简化版的pivot_table,不支持多级index和多级columns
4.3 stack 和 unstack
- stack
stack是把原来的列作为行进行展开
df.stack(0) #如果是mul_col,则将最外层列展开为行,
df.stack(1) #至少得是mul_col才能展开
- unstack
stack的逆函数,把行变为列,实际上就是pivot_tabel
4.3 dummy
pd.get_dummies(df)
one-hot编码
第五章 合并
5.1 append 和 assign
append
按序列添加行,和pd.concat axis=0功能一样,但是这个要求是按序列进行拼接,pd.concat 并不会去检查序列,好像是顺序匹配assign
按序列添加列,和pd.concat axis=1功能一样,同理也是要求按序列拼接
5.2 combine 和 update
combine是按条件用一个新的df去更新原df的列值,update是不管条件用新的df去覆盖原df的列值。。但是两者的应用场景应该是比较少,不如直接用apply的方式比较通用。
5.3 concat
最常用的拼接之一
5.4 merge和join
merge自然是最常用的拼接(之二),join和merge似乎没有区别,只是默认的连接方式不一致罢了。
第六章 缺失数据
6.1 缺失类型
- isnull 和 notnull来确定缺失值
df.isnull().sum()
df.isnull().all()
df.isnull().any()
all()是所有值都是True值(设定axis)才会返回True,any()是只要有一个是True就会返回True.
涉及到什么值是True,基本上,只有0、''、False才是False,其余都是True,包括np.nan值。。None值也是True。。所以为了避免误区,建议只针对bool值用any和all
- 其余缺失符号
np.nan None 和NaT(时间的nan)
基本上没有太大必要去单独掌握。。
- 所有类型
重点说一下,目前包括的类型为:
- float
- int
- bool
- datetime64[ns]
- datetime64[ns, tz]
- timedelta[ns]
- category
- object
默认的数据类型是int64,float64,object和str也是等价,会自动转换为object
6.2 缺失值的运算
基本上针对缺失值基本就是直接略过处理

6.3 填充与剔除
- 填充
df.fillna('value')
df.fillna(method='ffill')
df.fillna(method='backfill')
df.fillna(df.mean()) #自动对齐特性
- 剔除
df.dropna(axis=1) #默认就是部分缺失则去除
df.dropna(axis=0) #默认就是部分缺失则去除
df.dropna(axis=1,how='all') #全缺失去除
df.dropna(axis=1,how='any') #部分缺失去除
df.dropna(axis=0,subset=['B','C']) #对特定列进行缺失搜索
6.4 插值
- 线性插值
# s是series
s.interpolate() # 与index无关的插值,只考虑index的顺序而不是值
s.interpolate(method='index') # 与index有关的插值,需要考虑idnex的值
s.interpolate(method='time') #与index有关,并且index是时间格式
- 高级插值
多项式差值、样条插值等等。。也是可以通过设定method实现
第七章 文本数据
7.2 拆分与拼接
- 拆分split
s = pd.Series(['a_b_c', 'c_d_e', np.nan, 'f_g_h'], dtype="str")
s.str.split('_') #拆分后成为list
s.str.split('_').str[0] # 列表的第0项
s.str[0] #str的第0项
s.str.split('_',expand=True,n=1) #expand控制是否需要展开为多列,n控制展开的列数
str的相关方法都是针对series(或者index的list)操作
- 拼接cat
s = pd.Series(['ab',None,'d'],dtype='string')
s.str.cat(sep=',',na_rep='*') #sep控制拼接符、na_rep控制对缺失值的替代处理
str.cat只能对series操作,拼接之后是一个str
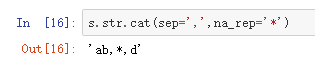
s.str.cat(s2,sep=',',na_rep='*') #两个series合并,则按序列进行拼接,默认left_join
s.str.cat([s+'0',s*2]) #也可以进行series和df/多个series的拼接
s.str.cat(df) #也可以进行series和df/多个series的拼接
如果要对df的所有列进行拼接,可以采用以下方法
df.iloc[:,0].str.cat(df.iloc[:,1:]) #必须以series作为引导
4.3 替换
- replace
支持正则匹配替换,用r开头
s.str.replace(r'^[AB]','***')
s.str.replace(r'([ABC])(\w+)',lambda x:x.group(2)[1:]+'*') #允许匿名进行group的操作,0返回字符本身,从1开始才是子组
s.str.replace(r'(?P[ABC])(?P\w+)',lambda x:x.group('two')[1:]+'*') #利用?P<....>表达式可以对子组命名调用
df的replace是全局替换(好像如果采用regex参数也可以实现正则匹配),str.replace是允许正则匹配的
4.4 子串匹配与提取
- str.extract
str.extract是综合split和replace的功能,实现更加灵活的匹配
#下面两种情况结果是一样的
pd.Series(['10-87', '10-88', '10-89'],dtype="string").str.extract(r'([\d]{2})-([\d]{2})')
pd.Series(['10-87', '10-88', '10-89'],dtype="string").str.split('_', expand=True)
replace只能返回某一个group的值,extract能把所有符合要求的group都返回,以及实现拆分
str.extractall
会全匹配,如果可以匹配多个结果,则建立多级索引str.contains
同样支持正则匹配
pd.Series(['1', None, '3a', '3b', '03c'], dtype="string").str.contains(r'[0-9][a-z]')
- str.match
str.match与其区别在于,match依赖于python的re.match,检测内容为是否从头开始包含该正则模式
4.3 其他常用方法
- str.strip
- str.lower和str.upper
- str.swapcase和str.capitalize
分别表示交换字母大小写和大写首字母 - str.isnumeric()
判断是否是数值
第八章
整体来说分类category应该用到得很少
pd.Categorical(["a", "b", "c", "a"], categories=['a','b','c']) #这是类似于list的categrical数据
s = pd.Series(cat) #这是dtype为category的series

这个就是catgorical数据,形似list
一些最基本的方法
s.cat.categories #查看分类情况
s.cat.ordered #查看是否排序,虽然一般用不到
还有一些修改categories的方法,一般用不到,如果需要用的时候,可以用pd.cut或者pd.Categorical来生成新列