GitHub: GitHub - volcano-sh/volcano: A Kubernetes Native Batch System (Project under CNCF)
官网:Volcano
文档:Introduction | Volcano
背景:
原生k8s对高性能应用场景的支持度较差,为支持TensorFlow、Spark、MindSpore等多个领域框架,Volcano作为容器调度系统,不仅包括了作业调度,还包含了作业生命周期管理、多集群调度、命令行、数据管理、作业视图及硬件加速等功能。

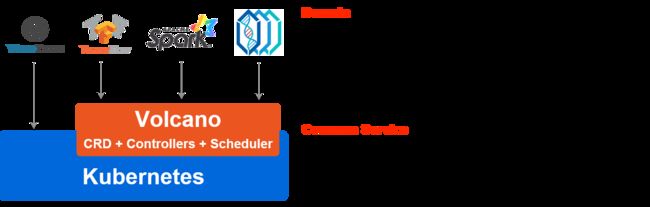
HPW 的常见调度场景 :
Batch scheduling 例如:
gang-scheduling
运行批处理作业(如Tensorflow/MPI)时,必须协调作业的所有任务才能一起启动;否则,将不会启动任何任务。如果有足够的资源并行运行作业的所有任务,则该作业将正确执行; 但是,在大多数情况下,尤其是在prem环境中,情况并非如此。在最坏的情况下,由于死锁,所有作业都挂起。其中每个作业只成功启动了部分任务,并等待其余任务启动。
job-based fair-share
当运行多个弹性作业(如流媒体)时,需要公平地为每个作业分配资源,以满足多个作业竞争附加资源时的SLA/QoS要求。在最坏的情况下,单个作业可能会启动大量的pod资源利用率低, 从而阻止其他作业由于资源不足而运行。为了避免分配过小(例如,为每个作业启动一个Pod),弹性作业可以利用协同调度来定义应该启动的Pod的最小可用数量。 超过指定的最小可用量的任何pod都将公平地与其他作业共享集群资源。
Enhanced job management, e.g. multiple pod template, job dependency, job lifecycle management
Alternative container runtime, e.g. Singularity
Enhancement for heterogeneous computing
Enhancement for high performance workload, e.g. performance, throughput
Queue 队列
队列还广泛用于共享弹性工作负载和批处理工作负载的资源。队列的主要目的是:
1 在不同的“租户”或资源池之间共享资源
2 为不同的“租户”或资源池支持不同的调度策略或算法
这些功能可以通过层次队列进一步扩展,在层次队列中,项目被赋予额外的优先级,这将允许它们比队列中的其他项目“跳转”。在kube批处理中,队列被实现为集群范围的CRD。 这允许将在不同命名空间中创建的作业放置在共享队列中。队列资源根据其队列配置(kube batch#590)按比例划分。当前不支持分层队列,但正在进行开发。
集群应该能够在不减慢任何操作的情况下处理队列中的大量作业。其他的HPC系统可以处理成百上千个作业的队列,并随着时间的推移缓慢地处理它们。如何与库伯内特斯达成这样的行为是一个悬而未决的问题。支持跨越多个集群的队列可能也很有用,在这种情况下,这是一个关于数据应该放在哪里以及etcd是否适合存储队列中的所有作业或pod的问题。
面向用户的, 跨队列的公平调度 (Namespace-based fair-share Cross Queue)
在队列中,每个作业在调度循环期间有几乎相等的调度机会,这意味着拥有更多作业的用户有更大的机会安排他们的作业,这对其他用户不公平。 例如,有一个队列包含少量资源,有10个pod属于UserA,1000个pod属于UserB。在这种情况下,UserA的pod被绑定到节点的概率较小。
为了平衡同一队列中用户之间的资源使用,需要更细粒度的策略。考虑到Kubernetes中的多用户模型,使用名称空间来区分不同的用户, 每个命名空间都将配置一个权重,作为控制其资源使用优先级的手段。
基于时间的公平调度 (Fairness over time)
对于批处理工作负载,通常不要求在某个时间点公平地分配资源,而是要求在长期内公平地分配资源。例如,如果有用户提交大作业,则允许用户(或特定队列)在一定时间内使用整个集群的一半, 这是可以接受的,但在下一轮调度(可能是作业完成后数小时)中,应惩罚此用户(或队列)而不是其他用户(或队列)。在 HTCondor 中可以看到如何实现这种行为的好例子。
面向作业的优先级调度 (Job-based priority)
Pod优先级/抢占在1.14版本中被中断,它有助于确保高优先级的pod在低优先级的pod之前绑定。不过,在job/podgroup级别的优先级上仍有一些工作要做,例如高优先级job/podgroup应该尝试以较低优先级抢占整个job/podgroup,而不是从不同job/podgroup抢占几个pod。
抢占 (Preemption & Reclaim)
通过公平分享来支持借贷模型,一些作业/队列在空闲时会过度使用资源。但是,如果有任何进一步的资源请求,资源“所有者”将“收回”。 资源可以在队列或作业之间共享:回收用于队列之间的资源平衡,抢占用于作业之间的资源平衡。
预留与回填 (Reservation & Backfill)
当一个请求大量资源的“巨大”作业提交给kubernetes时,当有许多小作业在管道中时,该作业可能会饿死,并最终根据当前的调度策略/算法被杀死。为了避免饥饿, 应该有条件地为作业保留资源,例如超时。当资源被保留时,它们可能会处于空闲和未使用状态。为了提高资源利用率,调度程序将有条件地将“较小”作业回填到那些保留资源中。 保留和回填都是根据插件的反馈触发的:volcano调度器提供了几个回调接口,供开发人员或用户决定哪些作业应该被填充或保留。
Volcano重要组件
华为云Volcano:让企业AI算力像火山一样爆发_华为云官方博客-CSDN博客_华为火山
Volcano-Scheduler
Volcano-Scheduler在Kube-Batch的基础上,又更进一步,引入了更多领域性的动作和插件,包括BinPack,GPUShare,GPUTopoAware等。
关于kube-batch,详见
Volcano-Controller
Volcano通过CRD的方式提供了通用灵活的Job抽象Volcano Job (batch.volcano.sh/jobs), Controller则负责跟Scheduler配合,管理Job的整个生命周期。主要功能包括:
①: 自定义的Job资源: 跟K8s内置的Job(作业)资源相比,Volcano Job有了更多增强配置,比如:任务配置,提交重试,最小调度资源数,作业优先级, 资源队列等。
②: Job生命周期管理: Volcano Controller会监控Job的创建,创建和管理对应的子资源(Pod, ConfigMap, Service),刷新作业的进度概要,提供CLI方便用户查看和管理作业资源等。
③: 任务执行策略: 单个Job下面往往会关联多个任务(Task),而且任务之间可能存在相互依赖关系,Volcano Controller支持配置任务策略,方便异常情况下的任务间关联性重试或终止。
④: 扩展插件: 在提交作业、创建Pod等多个阶段,Controller支持配置插件用来执行自定义的环境准备和清理的工作,比如常见的MPI作业,在提交前就需要配置SSH插件,用来完成Pod资源的SSH信息配置。
job管理
job管理的官方文档
Volcano中job管理 - 中文文档