本文源地址:http://www.fullstackyang.com/archives/538.html,转发请注明该地址或地址,谢谢!
微信公众号发布的文章和一般门户网站的新闻文本类型有所不同,通常不能用现有的文本分类器直接对这些文章进行分类,不过文本分类的原理是相通的,本文以微信公众号文章为对象,介绍朴素贝叶斯分类器的实现过程。
文本分类的科学原理和数学证明在网上有很多,这里就不做赘述,本文尽量使用通熟易懂的表述方式,简明扼要地梳理一下文本分类器的各个知识点。
参考了一下Github,发现少有Java 8风格的实现,所以这里的实现尽量利用Java 8的特性,相比之前优势有很多,例如stream在统计聚合等运算上比较方便,代码不仅简洁,而且更加语义化,另外在多线程并行控制上也省去不少的工作。
本项目的地址:https://github.com/fullstackyang/article-classifier
一、文本分类器的概述
文本分类器可以看作是一个预测函数,在给定的文本时,在预定的类别集合中,判断该文本最可能属于哪个类。
这里需要注意两个问题:
- 在文本中含有比较多的标点符号和停用词(的,是,了等),直接使用整段文本处理肯定会产生很多不必要的计算,而且计算量也非常大,因此需要把给定的文本有效地进行表示,也就是选择一系列的特征词来代表这篇文本,这些特征词既可以比较好地反应所属文本的内容,又可以对不同文本有比较好的区分能力。
- 在进行文本表示之后,如何对这些特征词进行预测,这就是分类器的算法设计问题了,比较常见的模型有朴素贝叶斯,基于支持向量机(SVM),K-近邻(KNN),决策树等分类算法。这里我们选择简单易懂的朴素贝叶斯算法。在机器学习中,朴素贝叶斯建模属于有监督学习,因此需要收集大量的文本作为训练语料,并标注分类结果
综上,实现一个分类器通常分为以下几个步骤:
- 收集并处理训练语料,以及最后测试用的测试语料
- 在训练集上进行特征选择,得到一系列的特征项(词),这些特征项组成了所谓的特征空间
- 为了表示某个特征项在不同文档中的重要程度,计算该特征项的权重,常用的计算方法有TF-IDF,本文采用的是“经典”朴素贝叶斯模型,这里不考虑特征项的权重(当然,一定要做也可以)
- 训练模型,对于朴素贝叶斯模型来说,主要的是计算每个特征项在不同类别中的条件概率,这点下面再做解释。
- 预测文本,模型训练完成之后可以保存到文件中,在预测时直接读入模型的数据进行计算。
二、准备训练语料
这里需要的语料就是微信公众号的文章,我们可以抓取搜狗微信搜索网站(http://weixin.sogou.com/)首页上已经分类好的文章,直接采用其分类结果,这样也省去了标注的工作。至于如何开发爬虫去抓取文章,这里就不再讨论了。

“热门”这类别下的文章不具有一般性,因此不把它当作一个类别。剔除“热门”类别之后,最终我们抓取了30410篇文章,总共20个类别,每个类别的文章数并不均衡,其中最多 的是“养生堂”类别,有2569篇文章,最少的是“军事”类别,有654篇,大体符合微信上文章的分布情况。在保存时,我们保留了文章的标题,公众号名称,文章正文。
三、特征选择
如前文所述,特征选择的目的是降低特征空间的维度,避免维度灾难。简单地说,假设我们选择了2万个特征词,也就是说计算机通过学习,得到了一张有2万个词的“单词表”,以后它遇到的所有文本可以够用这张单词表中的词去表示其内容大意。这些特征词针对不同的类别有一定的区分能力,举例来说,“歼击机”可能来自“军事”,“越位”可能来自“体育”,“涨停”可能来自“财经”等等,而通常中文词汇量要比这个数字大得多,一本常见的汉语词典收录的词条数可达数十万。
常见的特征选择方法有两个,信息增益法和卡方检验法。
3.1 信息增益
信息增益法的衡量标准是,这个特征项可以为分类系统带来多少信息量,所谓的信息增益就是该特征项包含的能够帮预测类别的信息量,这里所说的信息量可以用熵来衡量,计算信息增益时还需要引入条件熵的概念,公式如下
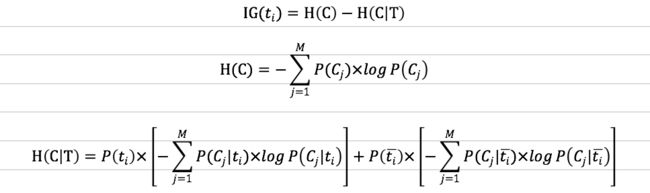
可能有些见到公式就头大的小伙伴不太友好,不过这个公式虽然看起来有点复杂,其实在计算中还是比较简单的,解释一下:
P(Cj):Cj类文档在整个语料中出现的概率;
P(ti):语料中包含特征项ti的文档的概率,取反就是不包含特征项ti的文档的概率;
P(Cj|ti):文档包含特征项ti且属于Cj类的条件概率,取反就是文档不包含特征项ti且属于Cj类的条件概率
上面几个概率值,都可以比较方便地从训练语料上统计得到。若还有不明白的小伙伴,推荐阅读这篇博客:文本分类入门(十一)特征选择方法之信息增益
3.2 卡方检验
卡方检验,基于χ2统计量(CHI)来衡量特征项ti和类别Cj之间的相关联程度,CHI统计值越高,该特征项与该类的相关性越大,如果两者相互独立,则CHI统计值接近零。计算时需要根据一张相依表(contingency table),公式也比较简单:

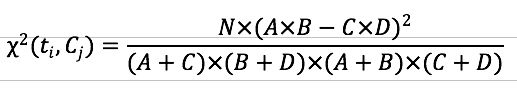
其中N就是文档总数,如果想继续讨论这个公式,推荐阅读这篇博客:特征选择(3)-卡方检验
3.3 算法实现
不论何种方式都需要对每个特征项进行估算,然后根据所得的数值进行筛选,通常可以设定一个阈值,低于阈值的特征项可以直接从特征空间中移除,另外也可以按照数值从高到低排序,并指定选择前N个。这里我们采用后者,总共截取前2万个特征项。
特征选择实现类的代码如下,其中,不同特征选择方法需实现Strategy接口,以获得不同方法计算得到的估值,这里在截取特征项时为了避免不必要的麻烦,剔除了字符串长度为1的词。
Doc对象表示一篇文档,其中包含了该文档的所属分类,以及分词结果(已经滤掉了停用词等),即Term集合;
Term对象主要包含3个字段,词本身的字符串,词性(用于过滤),词频TF;
Feature表示特征项,一个特征项对应一个Term对象,还包含两个hashmap,一个用来统计不同类别下该特征项出现的文档数量(categoryDocCounter),另一个用来统计不同类别下该特征项出现的频度(categoryTermCounter)(对应朴素贝叶斯两种不同模型,下文详述)
统计时引入FeatureCounter对象,使用stream的reduce方法进行归约。主要的思想就是把每一个文档中的Term集合,映射为Term和Feature的键值对,然后再和已有的Map进行合并,合并时如果遇到相同的Term,则调用Feature的Merge方法,该方法会将双方term的词频,以及categoryDocCounter和categoryTermCounter中的统计结果进行累加。最终将所有文档全部统计完成返回Feature集合。
@AllArgsConstructor
public class FeatureSelection {
interface Strategy {
Feature estimate(Feature feature);
}
private final Strategy strategy;
private final static int FEATURE_SIZE = 20000;
public List select(List docs) {
return createFeatureSpace(docs.stream())
.stream()
.map(strategy::estimate)
.filter(f -> f.getTerm().getWord().length() > 1)
.sorted(comparing(Feature::getScore).reversed())
.limit(FEATURE_SIZE)
.collect(toList());
}
private Collection createFeatureSpace(Stream docs) {
@AllArgsConstructor
class FeatureCounter {
private final Map featureMap;
private FeatureCounter accumulate(Doc doc) {
Map temp = doc.getTerms().parallelStream()
.map(t -> new Feature(t, doc.getCategory()))
.collect(toMap(Feature::getTerm, Function.identity()));
if (!featureMap.isEmpty())
featureMap.values().forEach(f -> temp.merge(f.getTerm(), f, Feature::merge));
return new FeatureCounter(temp);
}
private FeatureCounter combine(FeatureCounter featureCounter) {
Map temp = Maps.newHashMap(featureMap);
featureCounter.featureMap.values().forEach(f -> temp.merge(f.getTerm(), f, Feature::merge));
return new FeatureCounter(temp);
}
}
FeatureCounter counter = docs.parallel()
.reduce(new FeatureCounter(Maps.newHashMap()),
FeatureCounter::accumulate,
FeatureCounter::combine);
return counter.featureMap.values();
}
}
public class Feature {
...
public Feature merge(Feature feature) {
if (this.term.equals(feature.getTerm())) {
this.term.setTf(this.term.getTf() + feature.getTerm().getTf());
feature.getCategoryDocCounter()
.forEach((k, v) -> categoryDocCounter.merge(k, v, (oldValue, newValue) -> oldValue + newValue));
feature.getCategoryTermCounter()
.forEach((k, v) -> categoryTermCounter.merge(k, v, (oldValue, newValue) -> oldValue + newValue));
}
return this;
}
}
信息增益实现如下,在计算条件熵时,利用了stream的collect方法,将包含和不包含特征项的两种情况用一个hashmap分开再进行归约。
@AllArgsConstructor
public class IGStrategy implements FeatureSelection.Strategy {
private final Collection categories;
private final int total;
public Feature estimate(Feature feature) {
double totalEntropy = calcTotalEntropy();
double conditionalEntrogy = calcConditionEntropy(feature);
feature.setScore(totalEntropy - conditionalEntrogy);
return feature;
}
private double calcTotalEntropy() {
return Calculator.entropy(categories.stream().map(c -> (double) c.getDocCount() / total).collect(toList()));
}
private double calcConditionEntropy(Feature feature) {
int featureCount = feature.getFeatureCount();
double Pfeature = (double) featureCount / total;
Map> Pcondition = categories.parallelStream().collect(() -> new HashMap>() {{
put(true, Lists.newArrayList());
put(false, Lists.newArrayList());
}}, (map, category) -> {
int countDocWithFeature = feature.getDocCountByCategory(category);
//出现该特征词且属于类别key的文档数量/出现该特征词的文档总数量
map.get(true).add((double) countDocWithFeature / featureCount);
//未出现该特征词且属于类别key的文档数量/未出现该特征词的文档总数量
map.get(false).add((double) (category.getDocCount() - countDocWithFeature) / (total - featureCount));
},
(map1, map2) -> {
map1.get(true).addAll(map2.get(true));
map1.get(false).addAll(map2.get(false));
}
);
return Calculator.conditionalEntrogy(Pfeature, Pcondition.get(true), Pcondition.get(false));
}
}
卡方检验实现如下,每个特征项要在每个类别上分别计算CHI值,最终保留其最大值
@AllArgsConstructor
public class ChiSquaredStrategy implements Strategy {
private final Collection categories;
private final int total;
@Override
public Feature estimate(Feature feature) {
class ContingencyTable {
private final int A, B, C, D;
private ContingencyTable(Feature feature, Category category) {
A = feature.getDocCountByCategory(category);
B = feature.getFeatureCount() - A;
C = category.getDocCount() - A;
D = total - A - B - C;
}
}
Double chisquared = categories.stream()
.map(c -> new ContingencyTable(feature, c))
.map(ct -> Calculator.chisquare(ct.A, ct.B, ct.C, ct.D))
.max(Comparator.comparingDouble(Double::valueOf)).get();
feature.setScore(chisquared);
return feature;
}
}
四、朴素贝叶斯模型
4.1 原理简介
朴素贝叶斯模型之所以称之“朴素”,是因为其假设特征之间是相互独立的,在文本分类中,也就是说,一篇文档中出现的词都是相互独立,彼此没有关联,显然文档中出现的词都是有逻辑性的,这种假设在现实中几乎是不成立的,但是这种假设却大大简化了计算,根据贝叶斯公式,文档Doc属于类别Ci的概率为:

P(Ci|Doc)是所求的后验概率,我们在判定分类时,根据每个类别计算P(Ci|Doc),最终把P(Ci|Doc)取得最大值的那个分类作为文档的类别。其中,P(Doc)对于类别Ci来说是常量,在比较大小时可以不用参与计算,而P(Ci)表示类别Ci出现的概率,我们称之为先验概率,这可以方便地从训练集中统计得出,至于P(Doc|Ci),也就是类别的条件概率,如果没有朴素贝叶斯的假设,那么计算是非常困难的。
举例来说,假设有一篇文章,内容为“王者荣耀:两款传说品质皮肤将优化,李白最新模型海报爆料”,经过特征选择,文档可以表示为Doc=(王者荣耀,传说,品质,皮肤,优化,李白,最新,模型,海报,爆料),那么在预测时需要计算P(王者荣耀,传说,品质,皮肤,优化,李白,最新,模型,海报,爆料|Ci),这样一个条件概率是不可计算的,因为第一个特征取值为“王者荣耀”,第二个特征取值“传说”……第十个特征取值“爆料”的文档很可能为没有,那么概率就为零,而基于朴素贝叶斯的假设,这个条件概率可以转化为:
P(王者荣耀,传说,品质,皮肤,优化,李白,最新,模型,海报,爆料|Ci)=P(王者荣耀|Ci)P(传说|Ci)……P(爆料|Ci)
于是我们就可以统计这些特征词在每个类别中出现的概率了,在这个例子中,游戏类别中“王者荣耀”这个特征项会频繁出现,因此P(王者荣耀|游戏)的条件概率要明显高于其他类别,这就是朴素贝叶斯模型的朴素之处,粗鲁的聪明。
4.2 多项式模型与伯努利模型
在具体实现中,朴素贝叶斯又可以分为两种模型,多项式模型(Multinomial)和伯努利模型(Bernoulli),另外还有高斯模型,主要用于处理连续型变量,在文本分类中不讨论。
多项式模型和伯努利模型的区别在于对词频的考察,在多项式模型中文档中特征项的频度是参与计算的,这对于长文本来说是比较公平的,例如上面的例子,“王者荣耀”在游戏类的文档中频度会比较高,而伯努利模型中,所有特征词都均等地对待,只要出现就记为1,未出现就记为0,两者公式如下:

在伯努利模型计算公式中,N(Doc(tj)|Ci)表示Ci类文档中特征tj出现的文档数,|D|表示类别Ci的文档数,P(Ci)可以用类别Ci的文档数/文档总数来计算,
在多项式模型计算公式中,TF(ti,Doc)是文档Doc中特征ti出现的频度,TF(ti,Ci)就表示类别Ci中特征ti出现的频度,|V|表示特征空间的大小,也就是特征选择之后,不同(即去掉重复之后)的特征项的总个数,而P(Ci)可以用类别Ci中特征词的总数/所有特征词的总数,所有特征词的总数也就是所有特征词的词频之和。
至于分子和分母都加上一定的常量,这是为了防止数据稀疏而产生结果为零的现象,这种操作称为拉普拉斯平滑,至于背后的原理,推荐阅读这篇博客:贝叶斯统计观点下的拉普拉斯平滑
4.3 算法实现
这里使用了枚举类来封装两个模型,并实现了分类器NaiveBayesClassifier和训练器NaiveBayesLearner中的两个接口,其中Pprior和Pcondition是训练器所需的方法,前者用来计算先验概率,后者用来计算不同特征项在不同类别下的条件概率;getConditionProbability是分类器所需的方法,NaiveBayesKnowledgeBase对象是模型数据的容器,它的getPconditionByWord方法就是用于查询不同特征词在不同类别下的条件概率
public enum NaiveBayesModels implements NaiveBayesClassifier.Model, NaiveBayesLearner.Model {
Bernoulli {
@Override
public double Pprior(int total, Category category) {
int Nc = category.getDocCount();
return Math.log((double) Nc / total);
}
@Override
public double Pcondition(Feature feature, Category category, double smoothing) {
int Ncf = feature.getDocCountByCategory(category);
int Nc = category.getDocCount();
return Math.log((double) (1 + Ncf) / (Nc + smoothing));
}
@Override
public List getConditionProbability(String category, List terms, final NaiveBayesKnowledgeBase knowledgeBase) {
return terms.stream().map(term -> knowledgeBase.getPconditionByWord(category, term.getWord())).collect(toList());
}
},
Multinomial {
@Override
public double Pprior(int total, Category category) {
int Nt = category.getTermCount();
return Math.log((double) Nt / total);
}
@Override
public double Pcondition(Feature feature, Category category, double smoothing) {
int Ntf = feature.getTermCountByCategory(category);
int Nt = category.getTermCount();
return Math.log((double) (1 + Ntf) / (Nt + smoothing));
}
@Override
public List getConditionProbability(String category, List terms, final NaiveBayesKnowledgeBase knowledgeBase) {
return terms.stream().map(term -> term.getTf() * knowledgeBase.getPconditionByWord(category, term.getWord())).collect(toList());
}
};
}
五、训练模型
根据朴素贝叶斯模型的定义,训练模型的过程就是计算每个类的先验概率,以及每个特征项在不同类别下的条件概率,NaiveBayesKnowledgeBase对象将训练器在训练时得到的结果都保存起来,训练完成时写入文件,启动分类时从文件中读入数据交由分类器使用,那么在分类时就可以直接参与到计算过程中。
训练器的实现如下:
public class NaiveBayesLearner {
……
……
public NaiveBayesLearner statistics() {
log.info("开始统计...");
this.total = total();
log.info("total : " + total);
this.categorySet = trainSet.getCategorySet();
featureSet.forEach(f -> f.getCategoryTermCounter().forEach((category, count) -> category.setTermCount(category.getTermCount() + count)));
return this;
}
public NaiveBayesKnowledgeBase build() {
this.knowledgeBase.setCategories(createCategorySummaries(categorySet));
this.knowledgeBase.setFeatures(createFeatureSummaries(featureSet, categorySet));
return knowledgeBase;
}
private Map createFeatureSummaries(final Set featureSet, final Set categorySet) {
return featureSet.parallelStream()
.map(f -> knowledgeBase.createFeatureSummary(f, getPconditions(f, categorySet)))
.collect(toMap(NaiveBayesKnowledgeBase.FeatureSummary::getWord, Function.identity()));
}
private Map createCategorySummaries(final Set categorySet) {
return categorySet.stream().collect(toMap(Category::getName, c -> model.Pprior(total, c)));
}
private Map getPconditions(final Feature feature, final Set categorySet) {
final double smoothing = smoothing();
return categorySet.stream()
.collect(toMap(Category::getName, c -> model.Pcondition(feature, c, smoothing)));
}
private int total() {
if (model == Multinomial)
return featureSet.parallelStream().map(Feature::getTerm).mapToInt(Term::getTf).sum();//总词频数
else if (model == Bernoulli)
return trainSet.getTotalDoc();//总文档数
return 0;
}
private double smoothing() {
if (model == Multinomial)
return this.featureSet.size();
else if (model == Bernoulli)
return 2.0;
return 0.0;
}
public static void main(String[] args) {
TrainSet trainSet = new TrainSet(System.getProperty("user.dir") + "/trainset/");
log.info("特征选择开始...");
FeatureSelection featureSelection = new FeatureSelection(new ChiSquaredStrategy(trainSet.getCategorySet(), trainSet.getTotalDoc()));
List features = featureSelection.select(trainSet.getDocs());
log.info("特征选择完成,特征数:[" + features.size() + "]");
NaiveBayesModels model = NaiveBayesModels.Multinomial;
NaiveBayesLearner learner = new NaiveBayesLearner(model, trainSet, Sets.newHashSet(features));
learner.statistics().build().write(model.getModelPath());
log.info("模型文件写入完成,路径:" + model.getModelPath());
}
}
在main函数中执行整个训练过程,首先执行特征选择,这里使用卡方检验法,然后将得到特征空间,朴素贝叶斯模型(多项式模型),以及训练集TrainSet对象作为参数,初始化训练器,接着训练器开始进行统计的工作,事实上有一部分的统计工作,在初始化训练集对象时,就已经完成了,例如总文档数,每个类别下的文档数等,这些可以直接拿过来使用,最终将数据都装载到NaiveBayesKnowledgeBase对象当中去,并写入文件,格式为第一行是不同类别的先验概率,余下每一行对应一个特征项,每一列对应不同类别的条件概率值。
六,测试模型
分类器预测过程就相对于比较简单了,通过NaiveBayesKnowledgeBase�读入数据,然后将指定的文本进行分词,匹配特征项,然后计算在不同类别下的后验概率,返回取得最大值对应的那个类别。
public class NaiveBayesClassifier {
……
private final Model model;
private final NaiveBayesKnowledgeBase knowledgeBase;
public NaiveBayesClassifier(Model model) {
this.model = model;
this.knowledgeBase = new NaiveBayesKnowledgeBase(model.getModelPath());
}
public String predict(String content) {
Set allFeatures = knowledgeBase.getFeatures().keySet();
List terms = NLPTools.instance().segment(content).stream()
.filter(t -> allFeatures.contains(t.getWord())).distinct().collect(toList());
@AllArgsConstructor
class Result {
final String category;
final double probability;
}
Result result = knowledgeBase.getCategories().keySet().stream()
.map(c -> new Result(c, Calculator.Ppost(knowledgeBase.getCategoryProbability(c),
model.getConditionProbability(c, terms, knowledgeBase))))
.max(Comparator.comparingDouble(r -> r.probability)).get();
return result.category;
}
}
在实际测试时,我们又单独抓取了搜狗微信搜索网站上的文章,按照100篇一组,一共30组进行分类的测试,最终结果每一组的准确率均在90%以上,最高达98%,效果良好。当然正规的评测需要同时评估准确率和召回率,这里就偷懒不做了。
另外还需要说明一点的是,由于训练集是来源于搜狗微信搜索网站的文章,类别仅限于这20个,这不足以覆盖所有微信公众号文章的类别,因此在测试其他来源的微信文章准确率一定会有所影响。当然如果有更加丰富的微信文章训练集的话,也可以利用这个模型重新训练,那么效果也会越来越好。
七、参考文献与引用
- 宗成庆. 统计自然语言处理[M]. 清华大学出版社, 2013.
- T.M.Mitchell. 机器学习[M]. 机械工业出版社, 2003.
- 吴军. 数学之美[M]. 人民邮电出版社, 2012.
- Raoul-Gabriel Urma, Mario Fusco, Alan Mycroft. Java 8 实战[M]. 人民邮电出版社, 2016.
- Ansj中文分词器,https://github.com/NLPchina/ansj_seg
- HanLP中文分词器,https://github.com/hankcs/HanLP