一 java 对数据库的支持
java.sql 包的支持,一般使用显示编程的方式。 connection接口、statment接口、ResultSet接口、DriverManager类。
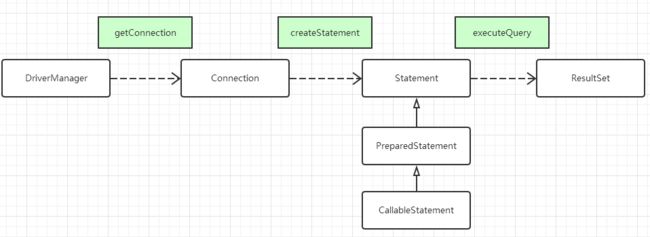
JDBC例子
Connection con = null; //表示数据库的连接对象
PreparedStatement pstmt = null; //表示数据库更新操作
ResultSet result = null;
String like_name ="Tom1";
intlike_age = 12;
String sql = "select name,age,birthday from java_study.person where name like ? or age = ?";
Class.forName(DBDRIVER); //1、使用CLASS 类加载驱动程序
System.out.println(sql);
con = DriverManager.getConnection(DBURL,DBUSER,DBPASS); //2、连接数据库
pstmt = con.prepareStatement(sql); //使用预处理的方式创建对象
pstmt.setString(1, "%"+like_name+"%");
pstmt.setInt(2, like_age);
result = pstmt.executeQuery(); //执行SQL 语句,更新数据库
while(result.next()){
String name = result.getString("name");
intage = result.getInt("age");
Date date = result.getDate("birthday");
System.out.println(name+","+age+","+date);
}
result.close();
pstmt.close();
con.close(); // 4、关闭数据库
JDBC事务例子
public void JdbcTransfer() {
java.sql.Connection conn = null;
try{
conn = conn =DriverManager.getConnection("jdbc:oracle:thin:@host:1521:SID","username","userpwd");
// 将自动提交设置为 false,
//若设置为 true 则数据库将会把每一次数据更新认定为一个事务并自动提交
conn.setAutoCommit(false);
stmt = conn.createStatement();
// 将 A 账户中的金额减少 500
stmt.execute("\
update t_account set amount = amount - 500 where account_id = 'A'");
// 将 B 账户中的金额增加 500
stmt.execute("\
update t_account set amount = amount + 500 where account_id = 'B'");
// 提交事务
conn.commit();
// 事务提交:转账的两步操作同时成功
} catch(SQLException sqle){
try{
// 发生异常,回滚在本事务中的操做
conn.rollback();
// 事务回滚:转账的两步操作完全撤销
stmt.close();
conn.close();
}catch(Exception ignore){
}
sqle.printStackTrace();
}
}
javax.sql包的支持
Java.sql.*
包含的接口和类采用传统的C/S体系结构设计思想.主要功能针对基本数据库编程服务,如生成连接,执行语句以及准备语句和运行批处理语句.也有一些高级功能如批处理更新,可滚动结果集,事务隔离以及SQL数据类型.
javax.sql.*
引入了JDBC编程方面一些主要的体系结构改变,并且为连接管理,分布式事务处理和老式连接提供了更好的抽象.这个包也引入了容器管理的连接缓冲池,分布式事务以及行集(rowset).
java.sql.是jdbc2.0之前的东西
javax.sql.包括了jdbc3.0的特性
javax.sql.提供了很多新特性,是对java.sql的补充,具体提供了一下方面的功能
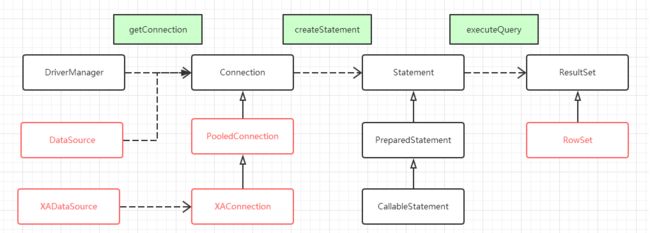
(1)Datasource接口提供了一种可选择性的方式去建立连接
(2)提供了连接池的支持
(3)增加了分布式的事务处理机制
(4)增加了rowset
(注意javax.sql.并不是包含java.sql.*,它俩一起组成了访问数据的类)
在javax中我们一般要关注的点是:数据源对象、连接池技术、分布式事务,在java只定义了接口,没有实际的应用,所以业内有很多的对javax.sql的实现。
DataSrouce接口(数据源对象)、PooledConnection接口(池技术)、XAConnection(分布式事务),这三个接口是jdbc的新特性新规范。
所以一般来说在各个厂商的实现来看,pooled一般指连接池,XAxxxx的只分布式。
如果要分析一个数据源的源码的话,从这三个方面来看:
2 druid源码分析
1 druid是由数组实现的
一个数据库连接池的开源软件。所以connection连接池的初始化、创建、回收、收缩、获取,都是关键点。

通过继承树可以看到继承了好的类和接口,其中主要的有两个线,DruidAbstractDataSource和CommonDataSource。说明DruidDataSrouce是一个DataSource,可以getConnection获取连接。
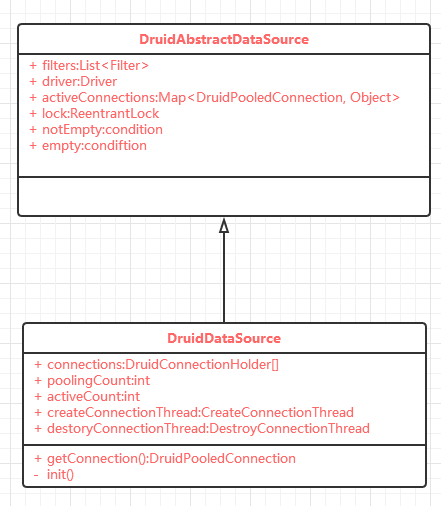
初始化时在获取连接的时候进行的,如果没有手动init的话。

二 锁、condition、创建\销毁线程
在druidDataSource中有一个重入锁,衍生两个condition,一个监控连接池是否为空,一个监控连接池不为空。
在该类中有两个线程,一个生成连接,一个回收连接。在创建、获取、回收的时候都会使用这些锁和condition。

由于数据连接数组是公共资源,所以在多线程并行的情况下,要加锁使用。
而在用户线程发现连接池中没有资源之后就会与创建连接的线程进行通信。
druid底层是使用数组实现的。
获取连接逻辑:
private DruidPooledConnection getConnectionInternal(long maxWait) throws SQLException {
if (closed) {
connectErrorCount.incrementAndGet();
throw new DataSourceClosedException("dataSource already closed at " + new Date(closeTimeMillis));
}
if (!enable) {
connectErrorCount.incrementAndGet();
throw new DataSourceDisableException();
}
final long nanos = TimeUnit.MILLISECONDS.toNanos(maxWait);
final int maxWaitThreadCount = getMaxWaitThreadCount();
DruidConnectionHolder holder;
try {
lock.lockInterruptibly(); // 获取锁,所有对数组可能的操作都要进行加锁
} catch (InterruptedException e) {
connectErrorCount.incrementAndGet();
throw new SQLException("interrupt", e);
}
try {
if (maxWaitThreadCount > 0) {
if (notEmptyWaitThreadCount >= maxWaitThreadCount) {
connectErrorCount.incrementAndGet();
throw new SQLException("maxWaitThreadCount " + maxWaitThreadCount + ", current wait Thread count "
+ lock.getQueueLength());
}
}
connectCount++;
if (maxWait > 0) {
holder = pollLast(nanos);
} else {
holder = takeLast();
}
if (holder != null) {
activeCount++;
if (activeCount > activePeak) {
activePeak = activeCount;
activePeakTime = System.currentTimeMillis();
}
}
} catch (InterruptedException e) {
connectErrorCount.incrementAndGet();
throw new SQLException(e.getMessage(), e);
} catch (SQLException e) {
connectErrorCount.incrementAndGet();
throw e;
} finally {
lock.unlock();
}
if (holder == null) {
long waitNanos = waitNanosLocal.get();
StringBuilder buf = new StringBuilder();
buf.append("wait millis ")//
.append(waitNanos / (1000 * 1000))//
.append(", active " + activeCount)//
;
List sqlList = this.getDataSourceStat().getRuningSqlList();
for (int i = 0; i < sqlList.size(); ++i) {
if (i != 0) {
buf.append('\n');
} else {
buf.append(", ");
}
JdbcSqlStatValue sql = sqlList.get(i);
buf.append("runningSqlCount ");
buf.append(sql.getRunningCount());
buf.append(" : ");
buf.append(sql.getSql());
}
String errorMessage = buf.toString();
if (this.createError != null) {
throw new GetConnectionTimeoutException(errorMessage, createError);
} else {
throw new GetConnectionTimeoutException(errorMessage);
}
}
holder.incrementUseCount();
DruidPooledConnection poolalbeConnection = new DruidPooledConnection(holder);
return poolalbeConnection;
}
创建线程逻辑:
lock.lock();
try {
connections[poolingCount++] = holder;
if (poolingCount > poolingPeak) {
poolingPeak = poolingCount;
poolingPeakTime = System.currentTimeMillis();
}
errorCount = 0; // reset errorCount
notEmpty.signal();
notEmptySignalCount++;
} finally {
lock.unlock();
}
回收逻辑:
// 回收方法是在DruidPooledConnection中的close方法中调用的,DruidPooledConnection是connection的子类,所以调用方使用框架时,使用close方法就是回收操作。
lock.lockInterruptibly();
try {
activeCount--;
closeCount++;
putLast(holder, lastActiveTimeMillis);
recycleCount++;
} finally {
lock.unlock();
}
收缩逻辑:
public void shrink(boolean checkTime) {
final List evictList = new ArrayList();
try {
lock.lockInterruptibly();
} catch (InterruptedException e) {
return;
}
try {
final int checkCount = poolingCount - minIdle;
final long currentTimeMillis = System.currentTimeMillis();
for (int i = 0; i < checkCount; ++i) {
DruidConnectionHolder connection = connections[i];
if (checkTime) {
long idleMillis = currentTimeMillis - connection.getLastActiveTimeMillis(); // 根据timeBetweenEvictionRunsMillis进行判断
if (idleMillis >= minEvictableIdleTimeMillis) {
evictList.add(connection);
} else {
break;
}
} else {
evictList.add(connection);
}
}
int removeCount = evictList.size();
if (removeCount > 0) {// 挪移数组,删除引用
System.arraycopy(connections, removeCount, connections, 0, poolingCount - removeCount);
Arrays.fill(connections, poolingCount - removeCount, poolingCount, null);
poolingCount -= removeCount;
}
} finally {
lock.unlock();
}
for (DruidConnectionHolder item : evictList) { // 关闭真实连接
Connection connection = item.getConnection();
JdbcUtils.close(connection);
destroyCount.incrementAndGet();
}
}
3 数据源的配置
略
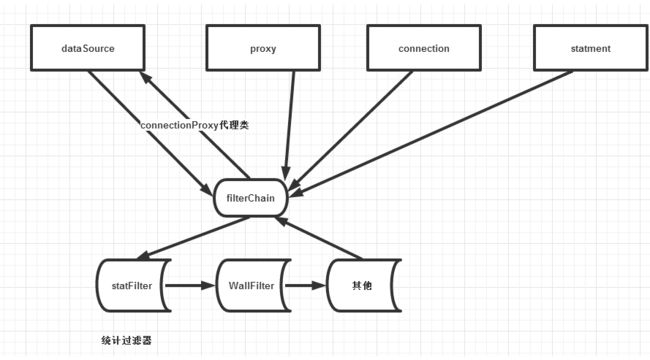
4 druid的代理与责任链

在DruidDataSource中创建的connection是druid自己实现connection接口的connectionProxyImpl类。是个代理类,代理的是connection的实现类,有各个开发商实现的具体的类。

一个使用driver生成真实的连接,一个对真实的连接进行封装成connectionProxy。
而在ds中会把这个代理类包装到holder中,在使用连接池的时候,获取holder,从holder中获取代理连接,在proxy中获取statment,从而执行sql,处理返回数据。

实际上,druid的对各个sql的接口都进行了代理,进行实现统计或者功能。通过源码可以看到,如果配置了责任链的节点就会使用代理类,如果没有使用则不会使用代理。
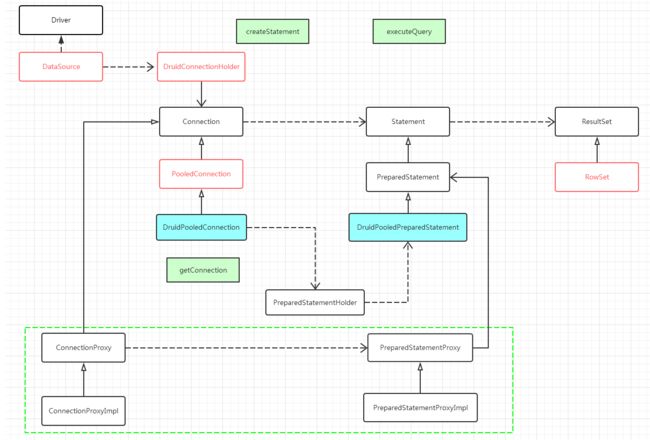
可以看出,druid的监控统计是使用责任链模式与代理模式实现的。代理类的作用是调用过滤责任链。