本文介绍了如何在Hive里新建一个外部分区表并加载数据
1.建表
# 使用数据库
use blog;
# 创建外部分区表
create external table external_blog_record(
host string comment "主机",
app string comment "应用",
source string comment "来源",
remote_addr string comment "访问IP",
time_iso6401 string comment "访问时间",
http_host string comment "域名",
request_method string comment "请求方式",
request_url string comment "请求地址",
request_protocol string comment "请求协议",
request_time string comment "请求耗时",
status string comment "请求状态",
body_byte_sents string comment "内容体大小",
upstream_addr string comment "转发服务器地址",
upstream_response_time string comment "转发响应耗时",
upstream_status string comment "转发状态",
http_referer string comment "来源地址",
http_user_agent string comment "浏览器类型",
res_type string comment "资源类型:首页、文章、类别、其他"
)
comment "日志原始记录外部分区表"
partitioned by (day string)
row format delimited fields terminated by '\t'
location '/log/blog';
新建一个名为external_blog_record的数据库表并制定分区参数day,数据的格式用'\t'分隔,数据的目录存放在HDFS的'/log/blog'目录下。
2.查看分区
# 查看表分区
show partitions external_blog_record;
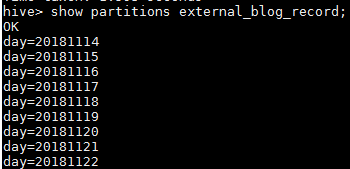
分区列表
可以看到目前表里面已经存在很多分区了,查看HDFS的目录
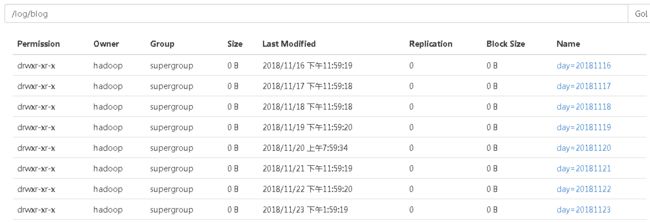
hdfs中的分区
每个分区下对应存放这日志文件。
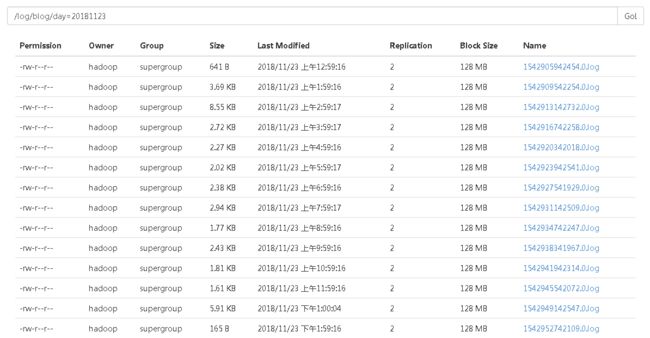
分区中的日志文件
3.新增分区
只需要在 /log/blog 下 新建day=XXX 即可,但是这样新建的分区并没有和Hive关联起来,必须运行如下命令,使分区与Hive关联起来。
msck repair table external_blog_record;
就可以用上面的查看分区的命令查看是否新建成功。
4.查询分区下的记录
hive> select count(*) from external_blog_record where day=20181122;
Query ID = hadoop_20181123144713_2b8b197a-c09b-4bf6-8ad3-b88cbd1ee4ca
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1542348923310_0146, Tracking URL = http://hadoop1:8088/proxy/application_1542348923310_0146/
Kill Command = /opt/soft/hadoop-2.7.3/bin/hadoop job -kill job_1542348923310_0146
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2018-11-23 14:47:25,697 Stage-1 map = 0%, reduce = 0%
2018-11-23 14:47:32,237 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.49 sec
2018-11-23 14:47:39,923 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.62 sec
MapReduce Total cumulative CPU time: 2 seconds 620 msec
Ended Job = job_1542348923310_0146
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.62 sec HDFS Read: 414396 HDFS Write: 5 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 620 msec
OK
1561
Time taken: 27.642 seconds, Fetched: 1 row(s)
5.附录
利用MapperReduce来定时合并小文件并加载到Hive分区表里
/**
* 合并日志文件并加载到Hive分区表
*/
public class MergeSmallFileAndLoadIntoHive {
private static final Logger LOG = LoggerFactory.getLogger(MergeSmallFileAndLoadIntoHive.class);
static class SmallFileCombinerMapper extends Mapper {
NullWritable v = NullWritable.get();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value, v);
}
}
public static void main(String[] args) throws Exception {
boolean test = false;
String logPath;
String patition;
if (test) {
patition = "day=20181114";
// Linux
logPath = "/log/blog";
// Windows
logPath = "D:" + File.separator + "hadoop" + File.separator + "blog";
} else {
if (args == null || args.length < 2) {
throw new RuntimeException("\"参数的长度不正确,参考:[java -jar xxxx.jar me.jinkun.mr.merge.MergeSmallFileAndLoadIntoHive /log/blog day=20181116]\"");
}
logPath = args[0];
patition = args[1];
}
String tempInPath = logPath + File.separator + "temp" + File.separator + patition + File.separator + "in";
String tempOutPath = logPath + File.separator + "temp" + File.separator + patition + File.separator + "out";
//权限问题
System.setProperty("HADOOP_USER_NAME", "hadoop");
Configuration conf = new Configuration();
if (!test) {
conf.set("fs.defaultFS", "hdfs://hadoop1:9000");
}
// 1.获取当天临时保存的日志
List paths = new ArrayList<>();
long currentTimeMillis = System.currentTimeMillis();
FileSystem fs = FileSystem.get(conf);
FileStatus[] fileStatuses = fs.listStatus(new Path(tempInPath));
for (FileStatus fileStatus : fileStatuses) {
if (fileStatus.isDirectory()) {
Path path = fileStatus.getPath();
String name = fileStatus.getPath().getName();
if (!name.startsWith("delete") &&
name.compareTo(String.valueOf(currentTimeMillis)) < 0) {
paths.add(path);
}
LOG.info("文件夹名为:" + name);
}
}
if (paths.size() == 0) {
LOG.info("暂无可以合并的文件夹!不提交JOB");
System.exit(0);
}
Job job = Job.getInstance(conf);
job.setJarByClass(MergeSmallFileAndLoadIntoHive.class);
job.setMapperClass(SmallFileCombinerMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 2.合并小文件到临时文件夹
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job, 1024 * 1024 * 128);//128M
CombineTextInputFormat.setInputPaths(job, paths.toArray(new Path[paths.size()]));
Path tempResultPath = new Path(tempOutPath);
FileOutputFormat.setOutputPath(job, tempResultPath);
job.setNumReduceTasks(0);
boolean flag = job.waitForCompletion(true);
// 如果成功
if (flag) {
// 3.将合并后的文件移动到Hive的分区表
int index = 0;
FileStatus[] resultStatus = fs.listStatus(tempResultPath);
for (FileStatus fileStatus : resultStatus) {
Path path = fileStatus.getPath();
if (path.getName().startsWith("part")) {
fs.rename(path, new Path(logPath + File.separator + patition + File.separator + currentTimeMillis + "." + index + ".log"));
index++;
}
}
fs.delete(tempResultPath, true);
// 4.标记合并过的文件夹为已经删除
for (Path path : paths) {
fs.rename(path, new Path(path.getParent(), "delete_" + path.getName()));
}
fs.close();
}
}
}
执行脚本
#!/bin/sh
day=`date '+%Y%m%d'`
echo "提交合并任务 $day"
nohup /opt/soft/hadoop-2.7.3/bin/hadoop jar /opt/soft-install/schedule/mapreduce-1.0.jar me.jinkun.mr.merge.MergeSmallFileAndLoadIntoHive /log/blog day=$day > nohup.log 2>&1 &