前言
这篇文章解决了什么问题:
系统的开始使用一个 ceph 集群。
整体介绍:
本文将系统的介绍如何使用一个 ceph 集群。
涉及:crush、osd、pool、cache
环境
ceph 版本:nautilus
ceph-deploy 版本:2.0.1
正文
在基本使用需求下,一般需要存储集群提供高性能存储(SSD)和普通存储(hdd)。
在 ceph 中,具体表现为某些池使用高性能存储,某些池使用普通存储。而这种需求在 ceph 中由 crush 规则实现。
ceph 提供了缓存的概念。在普通的存储池之上架设一层高性能的缓存池,外部访问首先到达缓存池,如果发生未命中等情况再去访问存储池。这里需要提一点,并不是任何情况都需要缓存。
针对不同的场景,ceph 的使用方式多种多样,这里的介绍只能一切从简,但是会尽量全面。
一个标准的场景:一个存储池加一个缓存池,存储池使用普通设备,缓存池使用高性能设备。
构建一个带缓存的存储池
首先添加一块高性能硬盘(我这里是虚拟环境,只能用普通硬盘充数)
然后需要利用 crush 让不同池使用不同的存储设备
向集群添加两块高性能硬盘
这里只能拿普通的虚拟硬盘来做测试。
在 ceph02 虚拟机上增加一块 30G 的虚拟硬盘。
在 ceph03 虚拟机上增加一块 30G 的虚拟硬盘。
现在到部署节点进行操作:
ceph-deploy osd create --data /dev/sdd ceph02
ceph-deploy osd create --data /dev/sdd ceph03
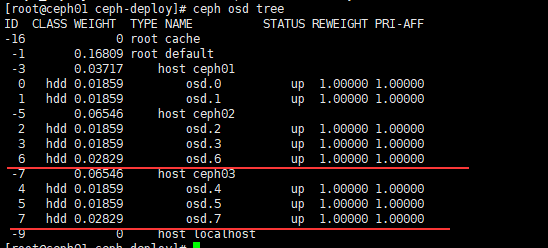
如图 ceph02 出现了 osd.6,ceph03 出现了 osd.7。
这里涉及到 root (根)的概念,在文章末尾【扩展】中会介绍。这里可以直接先使用。
将 osd.6 osd.7 加入名称为 cache 的根中(根名称会自动创建,注意,由于默认情况下 osd 在启动时读取的是 hostname,因此该方法只是临时生效,在文章末尾【扩展】中会介绍永久生效办法)
# 权重为 1.0
ceph osd crush set 6 1.0 root=cache host=ceph02-cache
ceph osd crush set 7 1.0 root=cache host=ceph03-cache
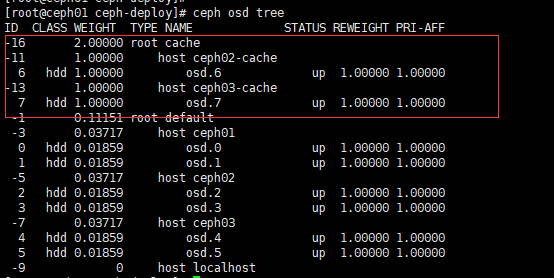
“高性能”存储盘现在已经有了,并且将其置于 cache 根下,这么做的意义在下一步中有体现。
现在可以进行下一步了。
crush 使用
当前环境下已经有一个默认的 crush 规则。
# 查看 crush 规则列表:
ceph osd crush rule ls
# 列出 crush 规则详情:
ceph osd crush rule dump
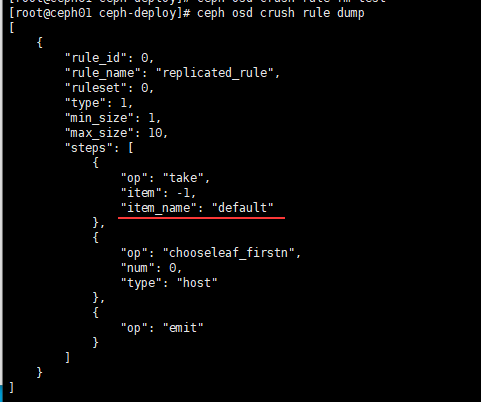
具体属性解释参考:
https://docs.ceph.com/docs/mimic/rados/operations/crush-map-edits/#crush-map-rules
如上图划线处,当前规则只会使用 default 根的 osd。
前面创建高性能设备时,将其设置根为 cache。我们现在就可以创建一个只使用 cache 根中的 osd 的规则,从而实现缓存池和存储池使用不同的设备。
创建缓存池使用的规则:
ceph osd crush rule create-replicated replicated_cache cache host
其中:
replicated_cache 指该规则的名字。
cache 指该规则使用的根。
host 指故障域级别。
再次查看所有规则:
ceph osd crush rule dump

现在我们有了一个只使用高性能存储设备的规则了。接下来就可以开始创建使用不同规则的池了。
创建存储池
创建存储池:
# 创建存储池 pg 为 80,规则指定为 replicated_rule
ceph osd pool create test_storage 80 replicated_rule
# 初始化这个池为 rgw 使用的池
ceph osd pool application enable test_storage rgw
查看池:
ceph osd lspools

查看该池的规则:
ceph osd pool get test_storage crush_rule
存储池至此已经好了。
创建缓存池
缓存池在 ceph 中常以 hot 标识。
普通存储池在 ceph 中常以 cold 标识。
缓存有多种形式(官方文档列出以下几种,实际更多):
- writeback :回写模式,这是 ceph 中最常用的一种模式。写入操作到达缓存盘时立即返回,随后异步的将缓存盘中的内容同步到存储盘中,过一段时间这条数据会自动的从缓存池中清除。当读取数据时,缓存代理首先将数据从存储池复制到缓存池中,然后返回给客户端,下一次直接从缓存池中读取该条数据,同样的,这条数据在一段时间内没被再次读取会从缓存池中清除掉。
- readproxy :读代理模式,只会使用在缓存中已存在的对象,常用于禁用 writeback 模式时的一个过渡阶段。
- readonly :只读模式,读取对象时首先读取缓存池,如果不存在再去访问存储池。该模式常用于对一致性要求不高的环境,因为刷新缓存池中的对象有一定的滞后性。
- none :无,指禁用缓存。
缓存参考:
https://docs.ceph.com/docs/master/rados/operations/cache-tiering/
创建缓存池
# 创建缓存池 pg 为 80,规则指定为 replicated_cache
ceph osd pool create test_cache 80 replicated_cache
# 目前用于缓存的主机只有2台,所以将缓存池的副本数调为2
ceph osd pool set test_cache size 2
ceph osd pool set test_cache min_size 2
# 初始化这个池为 rgw 使用的池
ceph osd pool application enable test_cache rgw
缓存池创建好以后,要将这个缓存池与对应存储池联系起来。这个联系的概念叫做 cache tiering,可以称之为缓存层,缓存代理。
参考:
https://docs.ceph.com/docs/master/rados/operations/cache-tiering/
- 创建缓存代理
ceph osd tier add test_storage test_cache
- 设置缓存模式
ceph osd tier cache-mode test_cache writeback
- 重定向流量到缓存池
ceph osd tier set-overlay test_storage test_cache
- 简单配置缓存池(基础使用不具体介绍)
# 以下两条命令配置缓存池的绝对大小
# 这两条配置十分重要,影响 crush 什么时候清洗数据
# 一条配置缓存池的空间大小,一条配置缓存池的对象数量。
# 当拥有多个缓存池时,注意缓存池的总大小不能超过物理大小。缓存池也有副本的概念。
ceph osd pool set test_cache target_max_bytes 26843545600
ceph osd pool set test_cache target_max_objects 1000000
ceph osd pool set test_cache hit_set_type bloom
ceph osd pool set test_cache hit_set_count 12
ceph osd pool set test_cache hit_set_period 14400
ceph osd pool set test_cache cache_target_dirty_ratio 0.4
ceph osd pool set test_cache cache_target_dirty_high_ratio 0.6
ceph osd pool set test_cache cache_target_full_ratio 0.8
ceph osd pool set test_cache cache_min_flush_age 600
ceph osd pool set test_cache cache_min_evict_age 1800
测试缓存
对于 test_storage 池,我们有一个只读的缓存池了。只要我们读取 test_storage 中的某个对象,这个对象就应该自动的置于缓存池中一段时间。
- 上传对象到缓存池(不再赘述,在部署文档中有写)
echo 1234 > /tmp/testfile.txt
rados put obj1 /tmp/testfile.txt --pool=test_cache
- 查看存储池
rados ls -p test_storage

可以发现,将对象上传回写模式的缓存池,存储池中也出现了对应的数据。
扩展
关于权重
osd 的大小可能不相同,因此其上的数据量也不应该相同,因此引入权重来影响数据分布。
比如100G的 osd 权重为1,则200G的 osd 权重就应设置为2。
关于 osd 存储结构
ceph osd tree 命令可以看到存储结构。可以结合自己机器执行的结果往下阅读。
一张官方图:

这是描述 ceph 存储结构的一张图。
首先这是一个树形结构。
其中最上层的 root default :root 是根的意思,default 就是这个根的名字。
中间 host foo:host 是主机的意思,foo 就是这个主机的名字。这里的主机名仅仅是个别称,不代表实际的主机,可以随意更改。
最下面的就是叶子节点了,具体指向 osd。
划分这三层结构的意义(不完全):
- 影响数据的分布,比如故障域的概念,让数据分布在不同的 osd 上,或者让数据分布在不同的 host 上,或者让数据分布在不同的 root 上。(一般故障域级别为 host)
- 影响 pool 的数据分布,pool 可以指定在哪个 root 上。根据这个特性,可能让缓存池使用高性能设备,普通池使用普通设备。
关于添加 osd
本文使用 ceph-deploy 添加 osd 时,并没有直接将其设置到最终根下,后续还需要手动配置。这么操作是不合理的,暂时未找到 ceph-deploy 指定根的参数。
关于缓存
当前文章配置的缓存池是2副本的。
某些时候,缓存数据是允许丢失的,比如只读的缓存。这种缓存池单副本即可,但是经测试,单副本池在 ceph 中似乎困难重重。
关于 osd 在重启后 hostname 重置的解决方案
1. 当一个机器中的 osd 的 host 名称都为同一个:
可以通过修改该机器的 hostname ,一劳永逸
2. 当一个机器中的 osd 的 host 名称不相同:
这个时候,当机器重启后,该机器的所有 osd 的 host 名称都一样了,导致 osd tree 混乱。这个时候可以在 ceph.conf 中具体配置某块盘的信息。
当前环境配置参考:
- 编写配置
去部署节点上:
cd /opt/ceph-deploy
vim ceph.conf
增加如下内容:
[osd.6]
host = ceph02-cache
[osd.7]
host = ceph03-cache
- 同步配置
ceph-deploy --overwrite-conf admin ceph01 ceph02 ceph03
重启后,一切正常。
通用解决方案
在 osd 的启动上做文章。
比如,配置 osd 的启动方式,容器化 osd,容器会记住某些信息,因此可以实现永久生效 hostname。
常见问题
1. 创建池时提示 pg 数过多
osd 上的 pg 数量会对整体集群性能造成影响,并不是越多越好,也不是越少越好。
由于池有副本的概念,因此产生了如下的计算方式:
池的 pg 数 * 该池副本数 = 该池使用的 pg 数
官方建议每个 osd 上的 pg 数为 100。实际测试每个 osd 上的 pg 数到达 250 时开始告警,因此该集群的总 pg 数不应超过:
总 pg 数 = 总 osd 数量 * 250
因此出现此问题的原因:
所有池的 pg 数加起来超过了设定的 总 pg 数 。但集群依然可正常使用,因此只是一个警告。
解决该问题的手段:
- 增加总 pg 数:一般通过加 osd 的方式。(尽量不要试图去修改阈值,除非你知道结果是什么)
- 削减当前集群使用的 pg 数:降低池的副本数(不要降到单副本),降低池的 pg 数(不建议)。
2. 单副本,导致 pg 状态 unknown
目前个人经验来说,不要使用单副本。
参考
crush 规则参考:
https://docs.ceph.com/docs/master/rados/operations/crush-map/