Ⅰ、生成器与迭代器
生成器generator
python中有时会需要定义变量,他的值是一个很大的可迭代(Iterable)数据——【可迭代数就是指可以循环遍历的数据python中就是字符串,元组,列表,集合,字典,生成器等】例如在爬虫实战中需要爬取2000家公司的所有招聘信息,这两千家公司的名字就是一个庞大的列表,如果直接导入会在内存空间中开辟一个很大的内存保存数据,而这时我们还没有使用这个数据就占用了大量的内存,降低了处理效率,使用生成器就可以将这个数据暂时定义出来而不开辟储存,在迭代生成器时才会一个一个开辟储存,大大提高了运行效率
定义生成器的方法一
我们生成一个列表通常使用python自带的列表推倒式(这里也介绍下python3中新加入的字典推倒式)
ls = [i for i in range(10)] #列表推倒式
dic = {k:v for (k,v) in dict.items()} #字典推倒式
#输出结果
>>>[0,1,2,3,4,5,6,7,8,9]
#将推倒式的中括号变成小括号,就可以生成一个列表生成器
ls = (i for i in range(10))
type(ls)
# 这时如果我们需要获取生成器中的数据可以使用next()方法,.__next__()
next(ls)
ls.__next__()
#输出结果
>>> at 0x025265D0>
>>>
>>>0
>>>1
定义生成器的方法二
当我们需要的数据比较复杂无法使用方法一时,就可以使用这个方法,使用yeild关键字,引用一个早就被玩烂的斐波那契数列(除了前两个数以外,后面的数字都是前两个数字的和)
def fib(cont):
n, a, b = 0, 0, 1
while n < cont:
yield b
a, b = b, a + b
n = n + 1
return 'ok'
函数使用了yeild关键字,在执行到yeild时停止,并记录位置,当调用next()方法时就会继续从yeild向下执行,直到第二次遇到yeild再次停下
# 运行结果
>>> gen = fib(5)
>>> type(gen)
>>> next(gen)
1
>>> gen.__next__()
1
迭代器Iterator
区分可迭代对象Iterrable和迭代器Iterator
可迭代对象:凡是可作用于 for 循环的对象都是 Iterable 类型;
迭代器:凡是可作用于 next() 函数的对象都是 Iterator 类型【例如生成器】;
Iterable并不是迭代器 ,不过可以通过 iter() 函数获得一个 Iterator 对象;
迭代器的作用:迭代时记录位置,减少内存的占用;
isinstance()方法可以判断一个对象是不是迭代器;
from collections import Iterator
isinstance((i for i in range(10)),Iterator)
>>>True
isinstance([i for i in range(10)],Iterator)
>>>False
Ⅱ、yeild关键字实现协程
协程的定义
函数在所有语言中都是层级调用,比如A调用B,B在执行过程中又调用了C,C执行完毕返回,B执行完毕返回,最后是A执行完毕。
协程看上去也是函数,但执行过程中,在函数内部可中断,然后转而执行别的函数,在适当的时候再返回来接着执行。
这里函数的中断停止,去执行其他函数,不是函数调用。而是程序由上而下在停止一个函数后,向下解析才执行了别的函数,在适当的时候跳回
协程的优势
⑴、最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
⑵、第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
⑶、当在多核CPU中使用多进程+协程方式,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。后面的数据爬取实战和scrapy框架,会大量用到多进程+协程
协程的实现
⒈ 协程的实现首先我们要了解一下生成器的send()方法
def gen():
i = 0
while i <5:
temp = yield i
print(temp)
i+=1
f = gen()
>>> f.__next__()
0
>>> f.__next__()
None
1
>>> f.send("I'm the send method")
I'm the send method
2
>>> f.send("Always me")
Always me
3
从运行结果中我们可以看出,generator.send()可以让函数外与被中断的函数建立联系,这样就可以实现,在执行下面的函数时,重新唤醒被中断的函数
⒉ 简易协程
有了上面的send()方法理论基础,我们尝试写一个简单的协程,看看执行效果
def fun1():
i = 1
while i<5:
n = yield i
print("第%s次执行函数一" % n)
i += 1
def fun2():
n = 1
while n<5:
# 获取生成器
gen = fun1()
# 获取i
i = gen.__next__()
# 发送n的值
gen.send(n)
print("接收到函数 %s"%i)
n+=1
if __name__ == "__main__":
fun2()
#运行结果
第1次执行函数一
接收到函数 1
第2次执行函数一
接收到函数 1
第3次执行函数一
接收到函数 1
第4次执行函数一
接收到函数 1
>>>
Ⅲ、常用设计模式—装饰模式
装饰器设计模式
1、设计模式:
设计模式是经过总结、优化的,对我们经常会碰到的一些编程问题的可重用解决方案。一个设计模式并不像一个类或一个库那样能够直接作用于我们的代码。反之,设计模式更为高级,它是一种必须在特定情形下实现的一种方法模板。设计模式不会绑定具体的编程语言。一个好的设计模式应该能够用大部分编程语言实现。常见的几种设计模式:单例模式,工厂模式,装饰模式等
2、装饰模式:
写代码要遵循开放封闭原则,虽然在这个原则是用的面向对象开发,但是也适用于函数式编程,简单来说,它规定已经实现的功能代码不允许被修改,但可以被扩展,即:
封闭:已实现的功能代码块
开放:对扩展开发
闭包
1、特点:在一个函数中又定义了一个函数,这个函数使用了外函数的变量,外函数的返回值是内函数,这时由于python自带的垃圾回收机制通过引用计数的方式清除内存,当某个变量引用计数为0时就会被清除,闭包的引用始终不会为0,这样就会消耗内存,永久定义在内存中。
2、作用:闭包的使用往往需要两次调用,第一次调用是定义出一个内函数对象并且给定参数,第二次调用是执行内函数,这样的过程类似与一个类创建一个实例对象,然后执行对象的各种操作,所有闭包也有很强的代码复用性。
#用闭包定义一条直线
def outer(a,b):
def inner(x):
y = a*x + b
print(y)
return inner
res = outer(4,5) #定义一条斜率是4,距离y轴上方5个单位的一条直线
y = res(3) #当直线上某点的x坐标为3,求出y坐标
>>>17 #输出结果是17
装饰器的作用
1、装饰器:就是在运行原来功能基础上,满足开闭原则,加上一些其它功能,比如权限的验证,比如日志的记录等等。不修改原来的代码,进行功能的扩展。
2、装饰器的一般用途:
引入日志
函数执行时间统计
执行函数前预备处理
执行函数后清理功能
权限校验等场景
异常的处理
缓存
简易装饰器
这里我们做一个简易的装饰器,假设已经完成了验证用户登录的处理函数:login()并投入使用了,这时我们发现忘记对用户登录之后的各种操作进行日志的记录(用户的日志记录是很重要的,当用户需要误操作回档时,如果没有日志,我们将无法找到用户的误操作项,就无法完成用户的需求,这将是一个不合格的软件!!)一般的日志都会记录用户的ID,在什么时间,操作了什么数据。
from datetime import datetime
import json
def log(fn):
def inner(username,*args):
#获取时间戳
time = datetime.now()
#生成日志
log = {"user":username,"time":time,"根据其他传入的参数定义行为":"操作了什么"}
#日志一般是字符串,将一个字典对象字符串使用json类库
log = json.dumps(log)
#写入日志
with open(log.text,"w") as f:
f.write(log)
#要定义的添加日志方法已经完成,调用外函数的参数,即要装饰的方法
fn(username,*args)
#返回内函数,形成一个闭包,防止在没有使用装饰器时,被gc认为是垃圾清除掉
return inner
# 使用装饰器,只需要使用python中的注解方式就可以在执行login()之前调用注解里的方法
@log
def login(username,password):
pass
使用装饰器的注意事项
装饰器方法必须定义在要调用的方法之前,这样python解释器自上而下执行时会先将装饰器方法开辟内存并储存,注解才能调用到装饰器;
装饰器也可以在类的方法中添加,只需要多传入一个参数self;
装饰器也可以定义成闭包嵌套闭包,让装饰器携带我们自定义的新的参数;
当一个方法有多个装饰器注解时,按照执行顺序,先执行第一个注解,再执行第二个注解
Ⅳ、动态语言类方法与静态方法
动态语言的属性
在面向对象的学习时,我们知道python可以在通过类定义一个对象时,可以非常简单的、动态的给这个对象添加属性,即使这个对象的类中没有这个属性
class User(object):
def __init__(self,name):
self.name = name
u = User("tom")
u.age = 18
print(u.name,u.age)
#输出结果
>>>tom 18
#也可以直接给类添加新的属性,不仅仅是实例对象
User.age = 17
#这样新生成的对象就会自带age属性,且age有默认值17
u2 = User("jerry")
print(u2.name,u2.age)
#输出结果
>>>jerry 17
这样表面上看上去方便了很多,不需要麻烦的操作就可以新增属性,但是其实这样也会让人随心所欲的定义属性,让代码越来越难以阅读和管理,这里可以使用__slots__ = (属性1,属性2,属性3,...),限制类只能添加某几种属性
class User(object):
__slots__ = ("name")
u = User()
u.name = "tom"
print(u.name)
>>>"tom"
u.age = 12
>>>Traceback (most recent call last):
>>> File "", line 1, in
>>>AttributeError: 'User' object has no attribute 'age'
#我们发现age属性不能被添加了
注意:__slots__变量所限定的属性仅对当前类实例起作用,对继承的子类是不起作用的。
类方法与静态方法
Python其实有3个方法,即静态方法(staticmethod),类方法(classmethod)和实例方法,这三种方法存在的前提是,必须要有一个类存在!在逻辑上类方法只能由类调用,静态方法类和实例都可以调用,不过python进行了优化,使得类方法和静态方法类和实例都可以调用了。
#定义一个类
class User:
def __init__(self,name):
self.name = name
#定义一个方法(这个方法也就是实例方法,只有生成实例对象才能调用,作为类本身User无法调用)
def eat(self,food):
print(self.name + "-eat-" + food)
#定义一个类方法,类方法前要加上注解@classmethod
@classmethod
def add(cls,food):
print(cls.__name__ + "-add-" + food)
#定义一个静态方法,静态方法前要加上注解@staticmethod
@staticmethod
def delete(food):
print("delete-" + food)
u = User("tom")
u.eat("dinner")
u.add("dinner")
u.delete("dinner")
User.add("dinner")
User.delete("dinner")
#输出结果
>>>tom-eat-dinner
>>>User-add-dinner
>>>delete-dinner
>>>User-add-dinner
>>>delete-dinner
动态添加方法【我也只是了解QAQ】
在类外定义出实例方法,类方法,静态方法的方法同上面的代码一样,就当我们在类外定义了以上的三个方法,这里我们给实例添加实例方法eat,给类绑定类方法add和静态方法delete
#绑定实例方法
u.eat = types.MethodType(eat,u)
#绑定类方法
User.add = add
#绑定静态方法
User.delete = delete
Ⅴ、常用设计模式—单例模式
意图:
保证一个类仅有一个实例,并提供一个访问它的全局访问点。
适用性:
当类只能有一个实例而且客户可以从一个众所周知的访问点访问它时。
当这个唯一实例应该是通过子类化可扩展的,并且客户应该无需更改代码就能使用一个扩展的实例时。
# 定义一个类
class Single(object):
def __init__(self):
self.port = "API"
# 我们每一次生成实例的时候只需要使用这同一个API就可以了这里就可以使用单例模式
@classmethod
def instance(cls):
# 创建实例时使用Single.instance()类方法
# 判断该类是否有属性_instance,没有则创建一个instance
if not hasattr(cls,"_instance"):
cls._instance = cls()
# 如果有,则直接将该实例返回即可,这样我们拿到的实例永远只是同一个
return cls._instance
def use(self):
print("正在使用接口:",self.port)
a = Single.instance()
a.use()
>>>正在使用接口:API
Ⅵ、数据库常用之时间戳和数据加密
时间戳标准库time
以下是常用的time库方法,获取时间戳在数据入库和日志记录时都非常重要,所以对于time标准库必须熟练掌握。
import time
sleep() -- 延迟一个时间段,接受整型、浮点型。
gmtime() -- 将时间戳转换为UTC时间元组格式。接受一个浮点型时间戳参数,其默认值为当前时间戳。
localtime() -- 将时间戳转换为本地时间元组格式。接受一个浮点型时间戳参数,其默认值为当前时间戳。
ctime() -- 将时间戳转换为字符串。接受一个时间戳,其默认值为当前时间戳。等价于asctime(localtime(seconds))
数据加密
1、base64编码简单加密
import base64
>>> s = base64.b64encode("hello world".encode("utf-8"))
>>> s
b'aGVsbG8gd29ybGQ='
>>> b = base64.b64decode(s)
>>> b
b'hello world'
2、扩展库hashlib使用md5加密
md5加密只可加密不可解密,但是同样的字符串加密后的结果是不会变化的,这就使可以通过撞库强行破解md5密文,不过我们可以通过md5密文多次掺杂和多次加密,来大大加大密文的安全性
import hashlib
pwd = "123456"
pwdd = "password%s" % pwd #掺杂
password = hashlib.md5(pwdd.encode("utf-8")).hexdigest() #加密并生成16进制的字符
#循环多次掺杂多次加密
pwd = "123456"
i = 0
while i <5:
pwd = hashlib.md5(("password" + pwd).encode("utf-8")).hexdigest()
i += 1
Ⅵ、常用标准库与扩展库
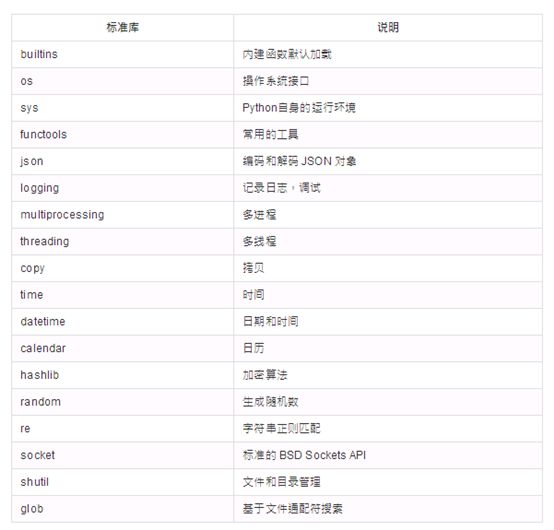
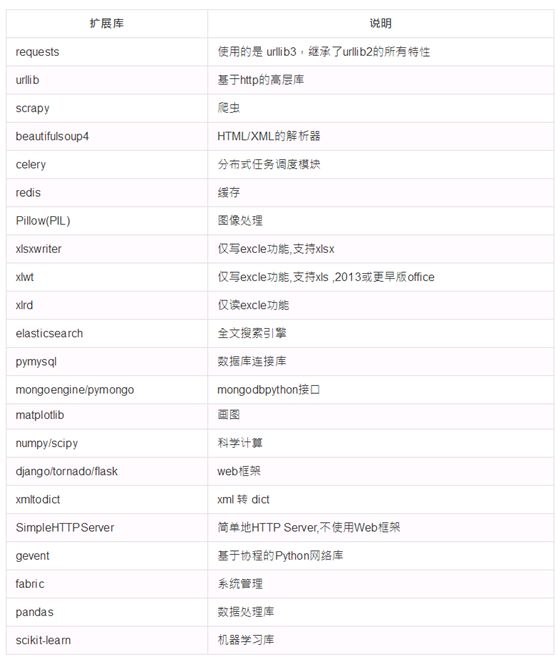
在常用扩展库中基本都是python攻城狮必须要熟练使用的,python的web框架——Django的快速开发,和Tornado的高性能开发,是web开发中的利剑。从数据爬取-->数据处理库-->数据保存入库-->画图分析数据甚至连接到机器学习,都是在大数据时代掌控雷电的不二法宝。祝自己武运昌隆!
