hash是以空间换时间的结构,现在空间越来越大,而且对性能要求越来越高的年代,这绝对是值得的。
hash含义就是散列,就是把我们本来想查找的一大群结构体数据分散开,更容易查找。一个好的hash函数应该做到对所有元素平均分散排列,尽量避免或者降低他们之间的冲突(Collision)。hash函数的选择必须慎重,如果不幸所有的元素之间都产生了冲突,那么hash表将退化为链表,其性能会大打折扣,时间复杂度迅速降为O(n),绝对不要存在任何侥幸心理,因为那是相当危险的。历史上就出现过利用Linux内核hash函数的漏洞,成功构造出大量使hash表发生碰撞的元素,导致系统被DoS,所以目前内核的大部分hash函数都有一个随机数作为参数进行掺杂,以使其最后的值不能或者是不易被预测。这又对 hash函数提出了第二点安全方面的要求:hash函数最好是单向的,并且要用随机数进行掺杂。提到单向,你也许会想到单向散列函数md4和md5,很不幸地告诉你,他们是不适合的,因为hash函数需要有相当好的性能。
散列函数: 将字符串等传入我们的散列函数,而散列函数的职责就是给我们返回一个value值,我们通过这个值引做hash表下标去访问我们想要查找的数据;例如这样的函数:
int Hash(char *key, int TableSize)
{
unsigned int HashVal = 0;
while(*key != '\0')
HashVal += *key++;
return HashVal % TableSize;
}
这就是一个简单的hash函数,就是把我们传入过来的key(由我们的数据中一个或者多个结构体成员的成员来作为key)来得到一个返回值,这个返回值就是我们的value值。
一个好的hash函数就是把我们的说有数据尽可能均匀的分散在我们预设的TableSize大小的hash表中。哈希表的几种方法:
1、直接定址法:取关键字key的某个线性函数为散列地址,如Hash(key) = key 或 Hash(key) = A*key+B;A,B为常数
2、除留取余法:关键值除以比散列表长度小的素数所得的余数作为散列地址。Hash(key) = key % p;
3、平均取中法:先计算构成关键码的标识符的内码的平方,然后按照散列表的大小取中间的若干位作为散列地址。
4、折叠法:把关键码自左到右分为位数相等的几部分,每一部分的位数应与散列表地址位数相同,只有最后一部分的位数可以短一些。把这些部分的数据叠加起来,就可以得到具有关键码的记录的散列地址。分为移位法和分界法。
5、随机数法:选择一个随机函数,取关键字的随机函数作为它的哈希地址。
6、数学分析法:设有N个d位数,每一位可能有r种不同的符号。这r种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布均匀些,每种符号出现的机会均等;在某些位上分布不均匀,只有某几种符号经常出现。可根据散列表的大小,选取其中各种符号分布均匀的若干位作为散列地址。
但是无论我们怎么样去选择这个函数,都不可能完全避免不同key值的hash[value]指向会映射到同一散列地址上。这样就会造成哈希冲突/哈希碰撞。所以我们需要找到处理这种冲突的方法,大概分为这两种:分离链接法和开放定址法。
分离链接法:其实就是我们说的hash桶的含义了。哈希桶就是盛放不同key链表的容器(即是哈希表),在这里我们可以把每个key的位置看作是一个桶,桶里放了一个链表
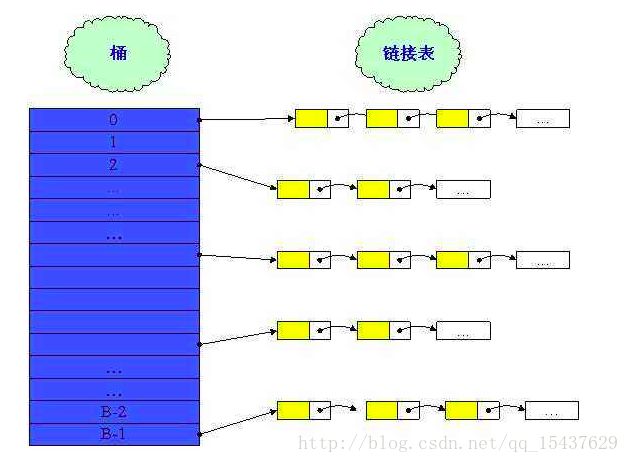
相信大家可以看出来,使用一个数组来存放记录方法的哈希冲突太多,基于载荷因子的束缚,空间利用率不高,在需要节省空间的情况下,我们可以用哈希桶来处理哈希冲突。
哈希桶是使用一个顺序表来存放具有相同哈希值的key的链表的头节点,利用这个头节点可以找到其它的key。
下面把完整的一套函数分开讲:
1、首先是创建我们需要的结构体:
数据的结构体(也就是我们表中需要存放的数据):
typedef struct node_s
{
int key; //这个值是我们得到我们的value值的依据,当然也可以能使字符串等,看你的数据类型了;
struct node *next;
}NODE;
hash表的节点:
typedef struct hash_s
{
NODE **list; //这个就是我们所有的hash桶的首个节点了,我们用它来查找到我们的桶的位置,为什么是**类型呢 ,因为这是地址的地址,例如某个桶 i 的位置*list[i];这样就找到我们的桶了;然后再在桶下面看看有没有我们要查找的NODE节点了
}HASH;
2、初始化hash表:
HashTable InitializeTable(int TableSize)
{
Hash H;
int i = 0;
H = calloc(1, sizeof(HASH));
if (H == NULL)
return -1;
H->TableSize = NextPrime(); //就是和TableSize最近的下一个素数;
H->hlist = calloc(1, sizeof(&NODE) * H->TableSize);
if (H->hlist == NULL)
return -1;
for (i = 0; i < H->TableSize; i ++)
{
*(H->hlist[i)] = calloc(1, sizeof(NODE));
if (*hlist[i] == NULL)
return -1;
else
*(H->hlist[i])->next = NULL;
}
}
3、查找NODE:
NODE *Find(int key, HASH H)
{
NODE *p;
NODE *list;
list = H->hlist[Hash(key, H->TableSize)];
p = list->next;
while(p != NULL && p->key != key)
p = p->next;
return p;
} //先找到这个桶的头结点list,然后再往后面遍历查找,这时候基本是链表查找操作了;
4、插入NODE:
void Insert(int key, HASH H)
{
NODE *p;
NODE *list;
NODE *tmp;
if (Find(key, H) == NULL)
{
tmp = calloc(1, sizeof(NODE));
if (tmp == NULL)
return -1;
list = H->hlist[Hash(key, H->TableSize)];
tmp->key = key;
tmp->next = list->next;//这里是直接把我们的节点插入到桶的首节点;
list->next = tmp;
}
return;
}
以上基本完成以hash桶为处理冲突的hash表的实现