我们用上一节读取tfrecord文件得到的数据来建立一个简单的二分类神经网络。进而介绍模型的保存和导入方法
# 简单的二分类神经网络:单隐藏层
# 每个样本有5个features
# 隐藏层有10个神经元,一个输出
# -*- coding: UTF-8 -*-
#!/usr/bin/python3
# Env: python3.6
import tensorflow as tf
import numpy as np
import os
# path
data_filename = 'data/data_train.txt'
size = (10000, 5)
tfrecord_path = 'data/test_data.tfrecord'
# tfrecord_path2 = 'data/test_data2.tfrecord'
# generate data 10000*5, label: 0 or 1
# generate tfrecord named test_data.tfrecord.
def generate_data(data_filename = data_filename, size=size):
if not os.path.exists(data_filename):
np.random.seed(9)
x_data = np.random.randint(0, 10, size = size)
y1_data = np.ones((size[0]//2, 1), int)
y2_data = np.zeros((size[0]//2, 1), int)
y_data = np.append(y1_data, y2_data)
np.random.shuffle(y_data)
# stitching together x and y in one file
xy_data = str('')
for xy_row in range(len(x_data)):
x_str = str('')
for xy_col in range(len(x_data[0])):
if not xy_col == (len(x_data[0])-1):
x_str =x_str+str(x_data[xy_row, xy_col])+' '
else:
x_str = x_str + str(x_data[xy_row, xy_col])
y_str = str(y_data[xy_row])
xy_data = xy_data+(x_str+'/'+y_str + '\n')
#print(xy_data[1])
# write to txt
write_txt = open(data_filename, 'w')
write_txt.write(xy_data)
write_txt.close()
return
# obtain data from txt
# every line of data is just as follow: 1 2 3 4 5/1. train data: 1 2 3 4 5, label: 1
def txt_to_tfrecord(txt_filename = data_filename, tfrecord_path = tfrecord_path):
# 第一步:生成TFRecord Writer
writer = tf.python_io.TFRecordWriter(tfrecord_path)
# 第二步:读取TXT数据,并分割出样本数据和标签
file = open(txt_filename)
for data_line in file.readlines(): # 每一行
data_line = data_line.strip('\n') # 去掉换行符
sample = []
spls = data_line.split('/', 1)[0]# 样本
for m in spls.split(' '):
sample.append(int(m))
label = data_line.split('/', 1)[1]# 标签
label = int(label)
print('sample:', sample, 'labels:', label)
# 第三步: 建立feature字典,tf.train.Feature()对单一数据编码成feature
feature = {'sample': tf.train.Feature(int64_list=tf.train.Int64List(value=sample)),
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))}
# 第四步:可以理解为将内层多个feature的字典数据再编码,集成为features
features = tf.train.Features(feature = feature)
# 第五步:将features数据封装成特定的协议格式
example = tf.train.Example(features=features)
# 第六步:将example数据序列化为字符串
Serialized = example.SerializeToString()
# 第七步:将序列化的字符串数据写入协议缓冲区
writer.write(Serialized)
# 记得关闭writer和open file的操作
writer.close()
file.close()
return
#txt_to_tfrecord(data_filename, tfrecord_path2)
# read tfrecord
def _parse_function(example_proto):
dics = { # 这里没用default_value,随后的都是None
'sample': tf.FixedLenFeature([5], tf.int64), # 如果不是标量,一定要在这里说明数组的长度
'label': tf.FixedLenFeature([], tf.int64)}
# 把序列化样本和解析字典送入函数里得到解析的样本
parsed_example = tf.parse_single_example(example_proto, dics)
parsed_example['sample'] = tf.cast(parsed_example['sample'], tf.float32)
parsed_example['label'] = tf.cast(parsed_example['label'], tf.float32)
# 返回所有feature
return parsed_example
def read_dataset(tfrecord_path = tfrecord_path):
# 声明阅读器
dataset = tf.data.TFRecordDataset(tfrecord_path)
# 建立解析函数
new_dataset = dataset.map(_parse_function)
# 打乱样本顺序
shuffle_dataset = new_dataset.shuffle(buffer_size=20000)
# batch输出
batch_dataset = shuffle_dataset.batch(2)
# 建立迭代器
iterator = batch_dataset.make_one_shot_iterator()
# 获得下一个样本
next_element = iterator.get_next()
x_samples = next_element['sample']
y_labels = next_element['label']
return x_samples, y_labels
def weight_bias_variable(weight_shape, bias_shape):
weight = tf.get_variable('weight', weight_shape, initializer=tf.random_normal_initializer(mean=0, stddev=1))
bias = tf.get_variable('bias', bias_shape, initializer=tf.random_normal_initializer(mean=0, stddev=1))
return weight, bias
# neural network:
# input layer: 5 features with on sample
# one hidden layer: 10 neuron
# output: y_out
################ fetch data ####################
with tf.variable_scope('input_data'):
x_samples, y_labels = read_dataset()
with tf.variable_scope('hidden_layer1', reuse=tf.AUTO_REUSE):
w1, b1 = weight_bias_variable(weight_shape=[5, 10], bias_shape=[10])
y_hidden = tf.nn.relu(tf.matmul(x_samples, w1) + b1)
tf.summary.histogram('w1', w1)
tf.summary.histogram('b1', b1)
with tf.variable_scope('output_layer', reuse=tf.AUTO_REUSE):
w2, b2 = weight_bias_variable(weight_shape=[10, 1], bias_shape=[1])
y_out = tf.matmul(y_hidden, w2) + b2
y_out = tf.reshape(y_out, [-1])
tf.summary.histogram('w2', w2)
tf.summary.histogram('b2', b2)
with tf.variable_scope('loss_function'):
# ################ Loss Function
# 这里的sigmoid是对y_out的激活函数
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=y_out, labels=y_labels, name=None)
loss_mean = tf.reduce_mean(loss, 0)
tf.summary.scalar('loss_mean', loss_mean)
################## BackPropagation
# 创建基于梯度下降算法的Optimizer
optimizer = tf.train.GradientDescentOptimizer(0.01)
# 添加操作节点,用于最小化loss,并更新var_list
# 该函数是简单的合并了compute_gradients()与apply_gradients()函数
# 返回为一个优化更新后的var_list
train = optimizer.minimize(loss_mean)
save_path = 'data/save/b2.txt'
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
# 建立tensorbord
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('data/tfboard', sess.graph)
saver = tf.train.Saver()
for i in range(2000):
sess.run(train)
summary = sess.run(merged)
writer.add_summary(summary, i)
if i % 1000 == 0:
print(' ############### step = %d ############ ' %i)
print('b2: ', sess.run(b2))
# 用官网介绍的checkpoint方式保存模型
# 创建saver对象,默认max_to_keep=5,保存最近5次的模型。
saver.save(sess, 'data/tmp/model', global_step=1000) # 保存第1000步的模型
# 将变量保存到文件(这里也可以创建字典,将所有变量写成tfrecord文件
# 用sess.run就是将tensor数据转为python数据,然后进行保存
b2_save = sess.run(b2)
print('TXT b2 save:', b2_save)
np.savetxt(save_path, b2_save)
writer.close()
coord.request_stop()
coord.join(threads)
##### checkpoint 恢复模型
# 为了区分,我们再建立一个session
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
# 恢复模型,这是一个 protocol buffer保存了完整的Tensorflow图,即所有变量、操作和集合等。拥有一个.meta
last_ckpt = saver.last_checkpoints # 得到保存模型的路径
saver_restore = tf.train.import_meta_graph(os.path.join(last_ckpt[0] + '.meta'))
# 用 checkpoint 恢复模型参数
saver_restore.restore(sess, last_ckpt[0]) # method 1
print('methond1:ckpt: ', sess.run(b2)) # 要知道参数名
saver.restore(sess, last_ckpt[0]) # method 2
print('methond2:ckpt: ', sess.run(b2)) # 要知道参数名
# 读取TXT文档恢复参数 # method 3
b2_restore = np.loadtxt(save_path)
b2_restore = tf.cast(b2_restore, tf.float32) # numpy默认float64而不是float32,而TF中默认时float32,才能用TF.RESHAPE()
b2_restore = tf.reshape(b2_restore, [-1]) # b2是标量,shape为[]。要求tensor时必须给标量扩维度
print('TXT b2_restore:', sess.run(b2.assign(b2_restore)))
# 或者 写成:
# print('TXT b2_restore:', sess.run(tf.assign(b2, b2_restore)))
print(sess.run(b2))
tf.summary()可以利用Tensorboard将网络可视化,在终端输入summary的路径:
$ tensorboard --logdir=/Users/username/PycharmProjects/firsttensorflow/readtf/data/tfboard
终端输出为:TensorBoard 1.9.0 at http://pc-171-10-100-190.cm.vtr.net:6006 (Press CTRL+C to quit)
我们需要在网页中输入:http://localhost:6006
tensorboard默认是在scalars(标量)界面:
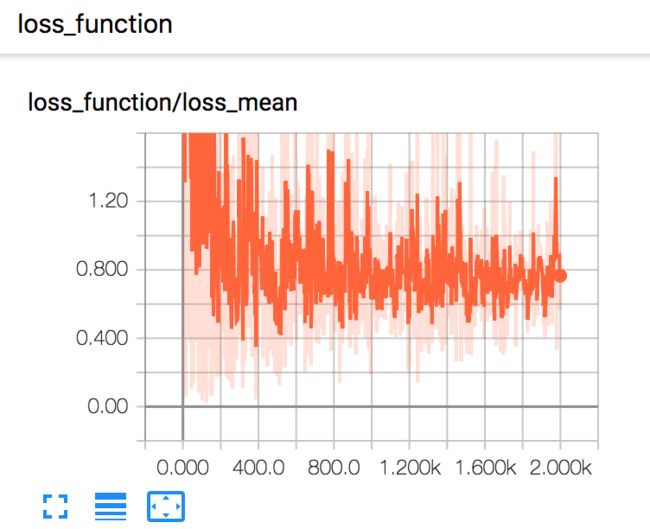
这里显示的是损失函数在2000次训练过程中的变化趋势。(因为是随机生成的数据,这里网络性能并没有考虑) 切换到GRAPHS界面,可以看到网络结构:
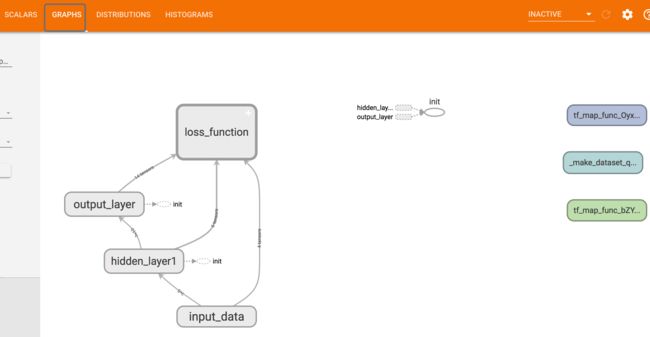
可以双击每个scope查看里面的tensor flow和operation。
传送:
- 神经网络激活函数
- tensorflow中常用的神将网络函数
- 梯度下降算法
- checkpoint方法保存加载模型的Blog