Java集合总结
今天复习Java的集合类,又有了许多收获
进入正题,首先是要搞清Collection和Collections,Collection是List,set和Queue接口的父接口,而Collections是一个操作集合的工具类。
集合体系知识如下:
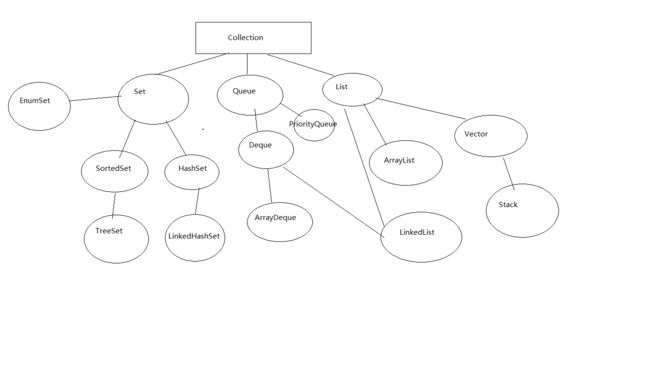
首先说Set集合:无序不重复。Set集合类似于一个蜜罐,可以把多个对象丢进去,而Set不能够记住添加元素的顺序。Set集合与Collection基本相同,没有提供额外的方法,也可以说Set就是Collection。如果add()相同的元素,会返回flase,添加失败。
HashSet:HashSet按照Hash算法来存储集合中的元素,因此具有良好的存取和查找的性能。简单的说,HashMap的底层实现是“基于拉链法的散列表”。
LinkedHashSet:使用连表来维护元素,因为需要维护元素的插入顺序,所以性能略低,低于HashSet。
TreeSet:采用红黑树的数据结构来存储集合元素,并且支持两种排序方法,自然排序和定制排序。注意:使用TreeSet时,保证添加的对象全都实现了Comparable接口,否则会添加失败,并且抛出ClassCastExecption异常。简单一句话,如果想要TreeSet正常运行,只能添加同一种类型的对象。
EnumSet:为枚举类设计的集合类。内部以向量的形式存储,存储形式非常紧凑,所有Enumset在对象占用内存小,而且效率高。
各Set实现类性能分析:HashSet性能总是高于TreeSet,如果想要保持排序的set,采用TreeSet。LinkedHashSet对于普通的插入删除来说比HashSet略微慢一点,但是有了连表,遍历LinkedHashSet会更快,EnumSet是Set实现类中性能最好的,但是只能保存同一类型的元素。并且所有的set实现类都是线程不安全的。
-------------------------------------分割线-----------------------------------------------------
现在我们再来说这个List和Queue
ArrayList和Vector (包括之后的ArrayDeque)都是基于数组来实现的,封装了一个动态的,允许在分配Object[]数组。并且这个ArrayList和Vector的,Object[]数组的大小为10(ArrayDeque大小为16).
对于Vcetor,这是一个比较古老的的集合,产生于jdk1.0,那时候java还没有集合,方法名都很长。之后也做过一些更新,方法名简短了。而ArrayList一开始就作为List的主要实现类。所以比Vector优异一些,以后开发过程过可以采用。在这就是ArrayList是线程不安全的,但是可以使用Collections工具类,把ArrayList变成,线程安全的。
--
Queue集合,用于模拟队列的“先进先出的结构”,而且PriorityQueue实现类是一个比较标准的实现类,之所以说是比较标准的,是因为元素并不是按照添加的顺序来排序的,而是按照队列元素大小进行排序的。
Deque接口是Queue的子接口,他代表了一个双端队列,Deque接口的典型实现类:ArrayDeque,是基于数组来实现的,底层数组长度为16
再来说说这个LinkedList,既可以当成队列,也可以当成栈来用。
最后分析一下性能:对于常用类ArrayList(基于数组)和LinkedList(基于线性表),初学者可以不必理会性能差劣,只知道LinkedList不仅提供了List功能,还提供了双端队列,栈的功能。
抛弃插入删除性能,总体来来说ArrayList的性能优异与LinkedList,因为大多数可以考虑使用ArrayList.对于ArrayList,Vector,and LinkedList的遍历,因为ArrayList和Vector是基于数组实现的,应该使用随机访问方法get去访问,对于LinkedList应该采用迭代器。
=======================
关于Map在map的所有子接口和实现类中,最常用的就是HashMap和TreeMap,换句话来说Map 和Set有着异曲同工之妙,详解可以看API,java源码就是先是实现了HaspMap TreeMap等集合,然后通过包装一个所有value都有null的Map集合实现了Set的集合类。
用的话首先选择HaspMap,如果想要保持排序,则用TreeMap
HashMap、HashTable、ConcurrentHashMap等算是集合类中的重点,可谓“重中之重”,首先来看个问题,如面试官问你:HashMap和HashTable有什么区别,一个比较简单的回答是:
1、HashMap是非线程安全的,HashTable是线程安全的。
2、HashMap的键和值都允许有null值存在,而HashTable则不行。
3、因为线程安全的问题,HashMap效率比HashTable的要高。
能答出上面的三点,简单的面试,算是过了,但是如果再问:Java中的另一个线程安全的与HashMap及其类似的类是什么?同样是线程安全,它与HashTable在线程同步上有什么不同?能把第二个问题完整的答出来,说明你的基础算是不错的了。带着这个问题,本章开始系Java之美[从菜鸟到高手演变]系列之深入解析HashMap和HashTable类应用而生!总想在文章的开头说点儿什么,但又无从说起。从最近的一些面试说起吧,感受就是:知识是永无止境的,永远不要觉得自己已经掌握了某些东西。如果对哪一块知识感兴趣,那么,请多多的花时间,哪怕最基础的东西也要理解它的原理,尽量往深了研究,在学习的同时,记得多与大家交流沟通,因为也许某些东西,从你自己的角度,是很难发现的,因为你并没有那么多的实验环境去发现他们。只有交流的多了,才能及时找出自己的不足,才能认识到:“哦,原来我还有这么多不知道的东西!”。
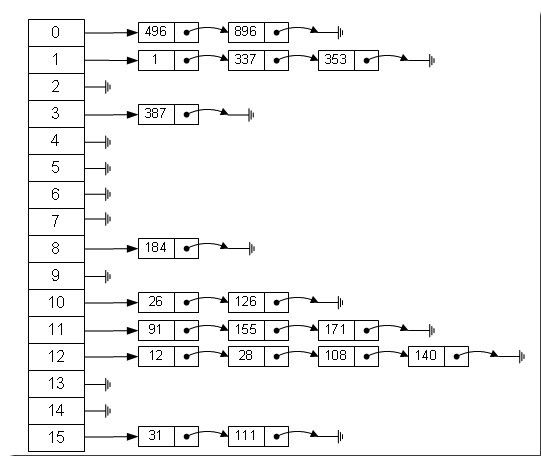
一、HashMap的内部存储结构
Java中数据存储方式最底层的两种结构,一种是数组,另一种就是链表,数组的特点:连续空间,寻址迅速,但是在删除或者添加元素的时候需要有较大幅度的移动,所以查询速度快,增删较慢。而链表正好相反,由于空间不连续,寻址困难,增删元素只需修改指针,所以查询慢、增删快。有没有一种数据结构来综合一下数组和链表,以便发挥他们各自的优势?答案是肯定的!就是:哈希表。哈希表具有较快(常量级)的查询速度,及相对较快的增删速度,所以很适合在海量数据的环境中使用。一般实现哈希表的方法采用“拉链法”,我们可以理解为“链表的数组”,