字节AI实习生搞出这个玩意儿,撩到了图灵奖大神,我用了用结果画风逐渐鬼畜起来……...
梦晨 鱼羊 发自 凹非寺
量子位 报道 | 公众号 QbitAI

这样的于和伟老师,还是你熟悉的那个“接着奏乐接着舞”的feel吗?
而如果容嬷嬷也进入到这个次元,画风竟然……

啊,是世外高人的感觉没错了,容嬷嬷不愧是童年真神!
那如果把互联网大佬们变成这样的画风,又会是怎样一种场面?
先看看雷军,端的是剑眉星目,风流倜傥。

再看BAT的三位大佬……

好家伙,感觉可以直接看图写作,去橙光游戏整一个《互联网风云录之三雄争霸》了。
(万字腹稿已就位……)
连歪果仁,也能被这个次元统一画风。
看图灵奖得主、深度学习三巨头,Bengio狷狂,Hinton坚毅,LeCun冷傲,绝世高手的feel直接拉满,随时可以华山论剑走一波。

△Hinton大佬小说男主脸实锤
连LeCun本人看了,都忍不住转发:


想必你也看出来了,这确实又是GAN的杰作。
不过这个来自字节跳动的GAN届新秀,可不止是能当橙光游戏立绘带师。
卡通风:

油画风:

甚至是特朗普风……

只要男女各100张照片作为训练样本,让AgileGAN看上1个小时,它就都能信手拈来。
即使照片上的人戴了口罩,也能把脸补全:

还会自动把帽子转换成头发。戴的帽子越多头发就越密,如果戴5层帽子,就是这样了:

甚至还能开发出一些鬼畜玩法,比如把生成的图像再喂回去……
△LeCun变美女
而培养出这么一个文能绘图、武能鬼畜的GAN的,是字节跳动和南洋理工大学。一作宋果鲜,目前在字节跳动担任研究实习生。
并且,AgileGAN的相关论文已经入选SIGGRAPH 2021。

只需100对样本训练1小时
之所以命名为AgileGAN (敏捷GAN),是因为它在一块V100上训练时间只需要1小时,训练数据集也只需要大概100对样本(男女各100张)。
这么强,怎么做到的?
要知道风格迁移的一大难点,就是如照片到卡通这种面部几何形状变化较大的迁移。
如果过于强调保留几何形状特征,会造成不符合审美的扭曲与瑕疵。
但是保留的少了迁移完就和输入的照片不像了。

△以前的算法不是脸发绿就是五官扭曲
这是因为,风格迁移算法如StyleGAN2,通把照片的特征编码成向量,逆映射(Inversion Mapping)到隐空间 (Latent Space)。
在此基础上对向量进行变换,再映射回图像,就能产生加减年龄,转换性别的效果。
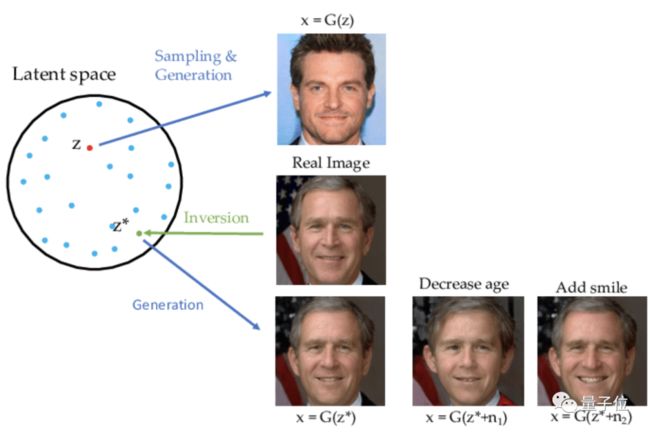
△图源 GAN Inversion: A Survey
但是AgileGAN团队发现,像StyleGAN2那样寻找最佳的隐空间映射是行不通的,因为适用于真实照片的映射并不一定适用于其他风格。
AgileGAN以StyleGAN2为基础进行改进,解决办法分为两部分。
第一个是层级变分自编码器 (hierarchical Variational Eutoencoder,简称hVaE)。
在确保映射隐空间分布符合原始高斯分布的同时,将原来的一个隐空间分成不同分辨率的多个隐空间,可以更好地编码图像中不同层次的细节。
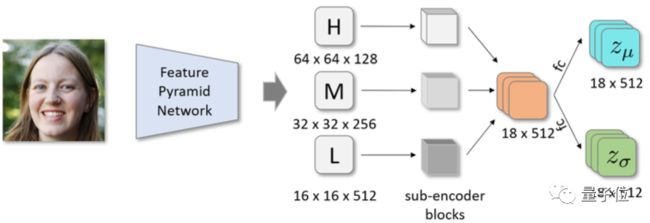
第二个是从StyleGAN2的预训练权重开始,重新微调出一个属性感知的生成器。
包括不同属性(如性别、年龄)的多个生成路径和多个判别器,以更好地实现依赖属性的风格迁移。
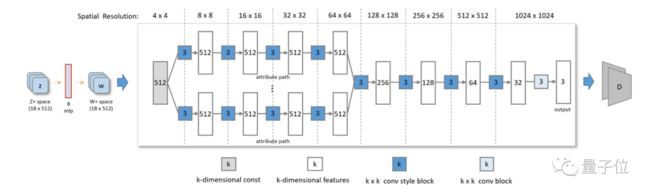
StyleGAN2生成器和属性感知的生成器这两个训练阶段是独立执行的,可以并行训练。

这样分开操作不仅减少了需要的训练数据集大小,还使风格迁移拥有更大的灵活性。
不过使用小数据集时判别器容易过拟合。解决办法是加入一个早期停止策略,一旦风格化效果达到预期,就停止训练。
这还没完,如果用上一阶运动技术(First Order Motion),AgileGAN还可以完成视频的风格迁移。
字节跳动实习生一作
另外,AgileGAN还是个“实习生作品”,成型于一作宋果鲜在字节跳动实习期间。
宋果鲜,本科毕业于中科大数学专业,目前正在南洋理工大学攻读计算机科学博士学位。同时,他也是字节跳动美国AI实验室的实习生。
他的研究方向主要是计算机视觉和计算机图形学,包括基于图像的3D人脸重建/分析、VR/AR应用等等。
所以,在AgileGAN眼里,宋同学又是什么样的呢?

发量和发质,真的很优秀了。
说起来,没准以后就能在抖音直接玩上这样的GAN了。
要是等不及,作者已经放出了试玩版:
http://www.agilegan.com/
论文地址:
https://guoxiansong.github.io/homepage/paper/AgileGAN.pdf
项目地址:
https://guoxiansong.github.io/homepage/agilegan_cn.html
参考资料:
[1]https://www.researchgate.net/publication/348487325_GAN_Inversion_A_Survey
[2]https://mp.weixin.qq.com/s/ayt6g-5KoSV14s6a5mp9pg