正则化的目的是稀疏神经网络中的权值,通过一些限制条件,训练使其中的一些不重要的权重为0,从而达到稀疏的目标,并且可以增强网络防止过拟合的能力。参数稀疏化一个好处是可以简化模型,避免过拟合。因为一个模型中真正重要的参数可能并不多,如果考虑所有的参数起作用,那么可以对训练数据可以预测的很好,但是对测试数据就只能呵呵了。另一个好处是参数变少可以使整个模型获得更好的可解释性。
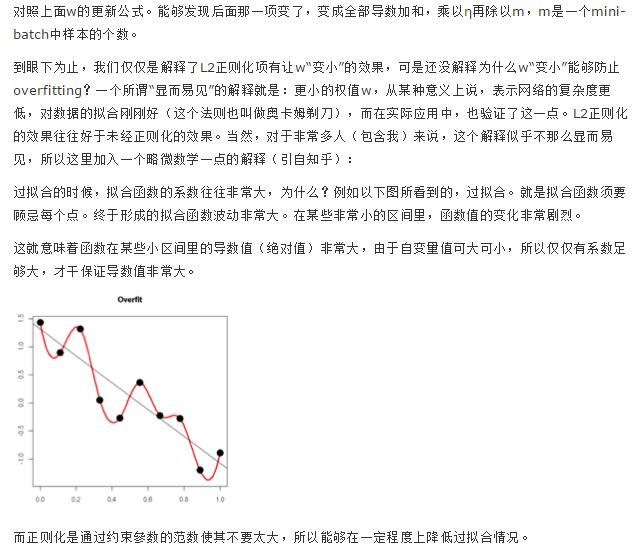
参数值越小代表模型越简单吗?是的。为什么参数越小,说明模型越简单呢,这是由于越复杂的模型,越是会尝试对所有的样本进行拟合,甚至包括少量异常样本点,这就容易造成在较小的区间里预测值产生较大的波动,这种较大的波动也反映了在这个区间里的导数很大,而只有较大的参数值才可以产生较大的导数。因而复杂的模型,其参数值会比较大。(我们可以知道权重实际上是样本的倒数,如果权值参数很大,则倒数很大,模型会很陡峭,去拟合一些异常点,当遇到新的样本时,这个较大的权重会把新样本的误差放得很大,导致泛化能力不行。)
看这幅图:可以知道稀疏掉一些参数可以使模型有更好的泛化性能

L0范数时,则是每个权值绝对值的0次方,由此可知L0是非零参数的个数。从直观上看,利用非零参数的个数,可以很好的来选择特征,实现特征稀疏的效果,具体操作时选择参数非零的特征即可。但因为L0正则化很难求解,是个NP难问题,因此一般采用L1正则化。L1正则化是L0正则化的最优凸近似,比L0容易求解,并且也可以实现稀疏的效果。
L1正则化
L1正则化在实际中往往替代L0正则化,来防止过拟合。在江湖中也人称Lasso。
L1正则化之所以可以防止过拟合,是因为L1范数就是各个参数的绝对值相加得到的,我们前面讨论了,参数值大小和模型复杂度是成正比的。因此复杂的模型,其L1范数就大,最终导致损失函数就大,说明这个模型就不够好。
L2正则化
L2正则化可以防止过拟合的原因和L1正则化一样,只是形式不太一样。L2范数是各参数的平方和再求平方根,我们让L2范数的正则项最小,可以使W的每个元素都很小,都接近于0。但与L1范数不一样的是,它不会是每个元素为0,而只是接近于0。越小的参数说明模型越简单,越简单的模型越不容易产生过拟合现象。L2正则化江湖人称Ridge,也称“岭回归”。


|w1|+|w2|+|w3|+|w4|+.....=y > 0 这里可以把y看做一个常数,可以认为这是一个关于w1,w2,w3.....的一个函数(限制函数)
L2范数时类似。
正则化方法:L1和L2 regularization、数据集扩增、dropout
根据等值线(目标函数)和限制函数,我们 容易知道满足x1*w1+x2*w2+x3*w3+....的w1,w2,w3,w4....不止一组),所以会有等值线。
同时满足目标函数和限制函数的w1,w2,w3,w4.....即为我们所要求的值,同时,为了达到稀疏化的目的,(即得到的满足有一批权重的值为0且满足目标函数和限制函数的权值组)我们选取这个限制函数的顶点。(w1,0,w3,0,.....)