0. 论文相关
Zero-shot Recognition via Semantic Embeddings and Knowledge Graphs
基于语义嵌入和知识图的零样本识别
1. 简介
1.1 摘要
我们考虑零样本识别的问题:为没有训练示例的类别学习一个视觉分类器,仅使用类别的词嵌入及与其他类别的关系,来提供视觉数据。处理不熟悉或新颖类别的关键是迁移从熟悉的类中获得的知识来描述不熟悉的类。在本文中,我们基于最近引入的图卷积网络(GCN),并提出了一种使用语义嵌入和分类关系来预测分类器的方法。给定学到的知识图(KG),我们的方法将每个节点作为输入语义嵌入(表示视觉类别)。在一系列图卷积之后,我们为每个类别预测视觉分类器。在训练期间,给出几个类别的视觉分类器以学习GCN参数。在测试时,这些过滤器用于预测未见类的视觉分类器。我们证明了我们的方法对KG的噪声很鲁棒。更重要的是,与目前最先进的结果相比,我们的方法在性能方面有显著改善(从一些指标的2%~3%到少数指标高达20%)。
2.主要思想
2.1
论文提出了提取隐含知识表示(即词嵌入)和显式关系(即知识图谱)的方法来学习新类别的视觉分类器。我们构建了一个知识图谱,其中每个节点对应一个语义类别。这些节点通过关系边链接。图中每个节点的输入是向量表示(语义嵌入)每个类别的。然后,我们使用图卷积网络(GCN在不同类别之间传输信息(消息传递)。具体来说,我们训练一个6层的深度GCN,它输出区分不同类别的分类器。
我们的工作重点是图像分类。我们考虑两种测试设置:(a)最终测试类仅为零样本类(测试时没有训练类);(b)测试时,标签可以是可见或未可见类,即“通用零样本设置。我们展示了令人惊讶的强大结果,并在经典的基线上得到了巨大的提升,如DeVise、ConSe和当前最先进的方法。例如,在具有2跳设置的标准ImageNet上,由前10位中的检索的图像中43.7%是正确的。我们的方法能够正确地检索62.4%的图像。这比目前最先进的技术进步了18.7%。更有趣的是,我们证明了我们的方法具有惊人的伸缩性,并且当我们增加知识图的大小时,即使图是有噪声的,也会有显著的改进。
2.2
用于具有回归损失的零样本识别,而不是实体分类。
框架的输入是一组类别及其对应的语义嵌入向量。
对于输出,我们希望预测每个输入类别的视觉分类器。
我们假设总类中的前m个类别有足够的视觉样本(图像)来估计它们的权重向量。
对于其余的-m类别,我们希望估计它们相应的权重向量,并将它们的嵌入向量作为输入。
3.方法
我们的目标是从隐式(词嵌入,word-embeddings)和显式(知识图谱)表示中提取(distill)信息,用于零样本识别。但是,正确的信息提取方法是什么?我们在最近对图卷积网络(GCN)[22]的研究基础上,学习视觉分类器。在下面,我们将首先介绍如何将GCN应用于自然语言处理的分类任务,然后我们将详细介绍我们的方法:将带有回归损失的GCN应用于零样本学习。

3.1. 前言:图形卷积网络(Preliminaries: Graph Convolutional Network)
在[22]中引入了图卷积网络(GCN)来进行半监督实体分类。
给定对象实体(object entities),由词嵌入或文本特征表示,任务是执行分类。例如,“dog”和“cat”等实体将标记为“哺乳动物”(mammal);“椅子”(chair)和“沙发”(couch)将被标记为“家具”(furniture)。我们还假设存在一个图,其中节点是实体,边表示实体之间的关系。
形式上,给定一个带有个实体的数据集。表示实体的词嵌入,表示其标签。在半监督设置中,我们知道前m个实体的真值(ground-truth)标签。我们的目标是使用嵌入词和关系图来推断剩余没有标签的个实体的标签。在关系图中,每个节点都是一个实体,如果两个节点之间存在关系,则它们将被链接。
我们使用一个函数来表示图卷积网络。它一次将所有实体的词嵌入作为输入,并将所有实体词嵌入的Softmax分类结果输出为。为了简单起见,我们将第个实体的输出表示为,这是一个维的Softmax概率向量。在训练期间,我们将Softmax损失应用于前m个实体,其标签为:

的权重通过反向传播进行训练。在测试期间,我们使用学习的权重用获得个实体的标签。
与在图像局部区域上操作的标准卷积不同,在GCN中,卷积操作根据邻接图定义的相邻节点计算节点处的响应。在数学上(Mathematically),网络中每一层的卷积运算表示为:

其中是图的二元邻接矩阵的规范化版本(normalized version),具有个维数。是前一层输入的特征矩阵。是尺寸为的层权重矩阵,其中是输出通道数(output channel number)。因此,对卷积层的输入为,输出为的矩阵。这些卷积运算可以一个接一个地进行叠加。在每个卷积层之后,在特征被输入到下一层之前,还应用非线性运算(ReLU)。对于最后的卷积层,输出通道的数量是标签类的数量(c=C)。有关详细信息,请参阅[22]。
3.2. GCN for Zero-shot Learning
我们的模型建立在图卷积网络的基础上。然而,我们将其应用于具有回归损失(regression loss)的零样本识别,而不是实体分类。我们的框架的输入是一组类别及其对应的语义嵌入向量(semantic-embedding vectors),表示为。对于输出,我们希望预测每个输入类别的视觉分类器,由表示。
具体来说,我们希望GCN预测的视觉分类器是一个固定的预先训练的ConvNet特征的逻辑回归模型(logistic regression model)。如果视觉特征向量的维数为,则每个类的每个分类器也是一个维向量。因此,GCN中每个节点的输出是维,而不是维。在零样本设置中,我们假设总类中的前m个类别有足够的视觉样本(visual examples)来估计它们的权重向量。对于其余的个类别,我们希望估计它们相应的权重向量,并将它们的嵌入向量作为输入。
一种方法是训练神经网络(多层感知器,multi-layer perceptron),将作为输入,并学习将预测作为输出。利用个训练对可以估计网络的参数。然而,通常情况下是很小的(按几百个顺序排列),因此,我们希望使用视觉世界的显式结构或类别之间的关系来约束问题。我们将这些关系表示为知识图谱(KG)。KG中的每个节点表示一个语义类别。因为我们总共有个类别,所以图中有个节点。如果两个节点之间存在关系,则它们彼此链接。图的结构由邻接矩阵表示。我们用无向边代替KG中的所有有向边,从而得到对称邻接矩阵,而不是用[22,52]建立二部图。
如图2所示,我们使用一个6层的GCN,其中每个层将上一层的特征表示作为输入,并输出一个新的特征表示()。对于第一层,输入是,它是一个矩阵(是word-embedding vector的维数)。对于最后一层,输出特征向量为,其大小为;是分类器或视觉特征向量的维数。
3.2.1 损失函数
对于前m个类,我们预测了从训练图像中获得的分类器权重和真值分类器权重。我们使用均方误差作为预测和真值分类器之间的损失函数:
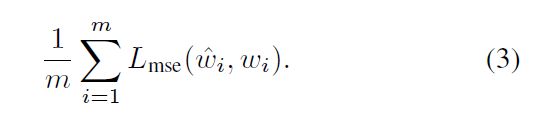
在训练过程中,我们使用所见个类别的损失来估计GCN的参数。利用估计的参数,得到了零样本分类的分类器权重。在测试时,我们首先通过预先训练的ConvNet提取图像特征表示,并使用这些生成的分类器对提取的特征进行分类。
3.3. 实现细节(Implementation Details)
我们的GCN由6个卷积层组成,输出通道数为2048→2048→1024→1024→512→D,其中表示目标分类器的维度。与[22]中介绍的2层网络不同,我们的网络要深得多。如烧蚀性研究(ablative studies)所示,我们发现在生成分类器权重时,使网络深度非常重要。对于激活函数,我们不使用每个卷积层后的ReLU,而是使用负斜率(negative slope)为0.2的LeakyReLU[27,51]。根据经验,我们发现LeakyReLU导致回归问题更快的收敛(convergence)。
在训练我们的GCN时,我们对网络和真值分类器的输出执行二级归一化(L2-Normalization)。在测试过程中,生成的不可见类(unseen classes)分类器也被二级归一化(L2-Normalization)。我们发现添加这个约束很重要,因为它将所有分类器的权重规则化为类似的大小。在实际应用中,我们还发现ImageNet预训练网络(ImageNet pre-trained networks)的最后一层分类器是自然归一化的。也就是说,如果我们在测试期间,对每个最后一层分类器执行L2标准化(L2-Normalization),ImageNet 2012 1K-class验证集的性能略有变化(<1%)。
为了获得用于GCN输入的词嵌入(word embeddings),我们使用了在维基百科数据集上训练的手套文本模型[36](GloVe text model [36] trained on the Wikipedia dataset),这将生成300维的向量。对于名称包含多个单词的类,我们匹配训练模型中的所有单词并找到它们的嵌入。通过对这些嵌入词进行平均,得到嵌入类。
4.实验
我们现在进行的实验表明,我们的方法:(a)大大提高了最先进的技术水平;(b)对不同的预先训练的ConvNets和KG中的噪声具有鲁棒性。我们在实验中使用了两个数据集。我们使用的第一个数据集是从公开的知识库构建的。数据集包括从永无止境的语言学习(Never-Ending Language Learning,NELL)[3]的关系和图和从永无止境的图像学习(Never-Ending Image Learning ,NEIL)[8]的图像。这是一个理想的数据集,用于:(a)证明我们的方法是稳健的,即使是自动学习(和噪音)KG;(b)烧蚀研究,因为在这个领域的KG是丰富的,我们可以执行KG以及烧蚀。
我们最后的实验显示在标准的ImageNet数据集上。我们使用与基线方法[13,34,4]和WordNet[32]知识图谱相同的设置。我们表明,我们的方法在很大程度上超过了目前最先进的方法。
4.1. NELL和NEIL的实验
4.1.1数据集设置
在本实验中,我们构建了一个基于Nell[3]和Neil[8]数据集的新知识图谱。具体来说,Neil中的对象节点对应于Nell中的节点。Neil数据集提供图像来源,Nell数据集提供常识性知识规则(common sense knowledge rules)。然而,Nell图非常大:它包含大约1700000类型的对象实体和大约2400000条边,代表每两个对象之间的关系。此外,由于NELL是自动构造的,因此图中存在噪声边。因此,我们为实验创建子图。
构造这个子图的过程很简单。我们从NEIL节点开始执行广度优先搜索(Breadth-first search ,BFS)。我们发现具有最大长度跃点(maximum length K hops)的路径,这样路径中的第一个和最后一个节点就是NEIL节点。我们将这些路径中的所有节点和边添加到子图中。我们在BFS期间设置为K=7,因为我们发现超过7个跃点的路径将导致两个对象之间的连接有噪音和不合理。例如,“吉普”可以在很长的路径上连接到“鹿”,但它们几乎没有语义上的关联。

注意,NELL中的每个边都有一个通常大于0.9的置信值(confidence value)。为了我们的实验,我们创造了两个不同版本的子图。第一个较小的版本是一个具有高值边(大于0.999)的图,第二个版本使用所有边,而不管它们的置信值如何。这两个子图的统计汇总在表1中。对于较大的子图,我们有14k个对象节点。在这些节点中,704个节点在Neil数据库中有相应的图像。我们用616个类来训练我们的GCN,留下88个类来测试。请注意,这88个测试类是随机选择的,与标准ImageNet分类数据集中的1000个类没有重叠的类。较小的知识图大约是较大知识图的一半大小。我们在两个设置中使用相同的88个测试类。
4.1.2 训练细节
为了在Neil 图像上训练ConvNet,我们使用与616训练类相关联的310K图像。对与88个测试类相关的随机选择的12K图像进行评估,即测试期间排除训练类中的所有图像。我们对ImageNet预训练的VGGM(ImageNet pre-trained VGGM)[7]网络结构进行了微调,相对较小的fc7输出(128维)。因此,对象分类器fc8的维度是128。为了训练我们的GCN,我们使用学习率为0.001、权重衰减为0.0005的Adam[21]优化器。我们为每一个实验训练了300个周期的GCN。
4.1.3 基线方法
我们将我们的方法与最先进的方法之一ConSE[34]进行了比较,后者在ImageNet中的性能略好于DeViSE[13]。作一个简短的介绍,ConSE首先将测试图像前馈到一个只在训练类上进行训练的ConvNe中。根据输出概率,ConSE选择Top-T个预测和这些类的词嵌入。然后它通过加权平均T个带概率的嵌入生成一个新的词嵌入:
这个新的嵌入应用于在测试类的词嵌入中执行最近邻查找。检索到的最高的类将被选作最终结果。我们列举了T个不同的评估值。
4.1.4 定量结果(Quantitative Results)
我们对88个不可见类的任务进行评估。我们的度量是基于给定零样本类的正确检索测试数据(非top k检索)的百分比。结果如表2所示。我们在两个不同大小的知识图谱上评估我们的方法。我们使用“高值边”来表示基于高置信边构造的知识图谱。“所有边”表示用所有边构造的图。我们将基线[34]表示为“ConSE(T)”,我们设定T为5、10和训练类的数量。

我们的方法在很大程度上优于ConSE基线。在“所有边”数据集中,我们的方法在Top-1的准确性上优于ConSE3.6%。更令人印象深刻的是,我们的方法的准确度几乎是top-2度量标准的2倍,甚至是top-5和top-10精度的2倍以上。这些结果表明,在我们的方法中,将知识图谱与词嵌入结合使用,可以得到比仅嵌入词效果更好的结果。
4.1.4 从小到大的图(From small to larger graph.)
除了提高零样本识别的性能外,随着图尺寸的增大,我们的方法获得了更多的性能增益。如表2所示,我们的方法通过从小图切换到大图来实现更好的效果。我们的方法在所有指标上都取得了2~3%的改进。另一方面,在ConSE性能方面几乎没有改善。它还表明,KG不需要手工制作或清洗。我们的方法能够可靠地处理图结构中的错误。
4.1.5 对于缺失边缘的恢复力(Resilience to Missing Edges)
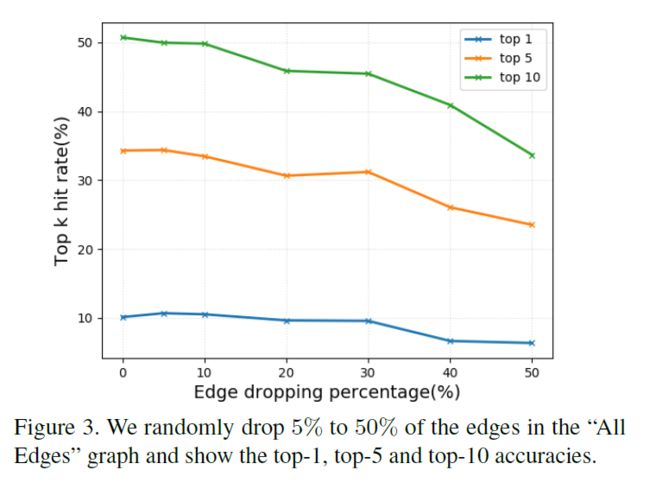
我们将探讨如果我们在“所有边”图中随机减少5%到50%的边,模型的性能将如何变化。如图3所示,通过从5%下降到10%的边缘,我们的模型的性能变化是可以忽略的。这主要是因为知识图谱可以有14K节点和97K边连接的冗余信息。这再次意味着我们的模型对于图中的小的噪声变化是健壮的。当我们开始删除超过30%的边缘时,精度急剧下降。这表明模型的性能与知识图的大小高度相关。
4.1.5 随机图?(Random Graph?)
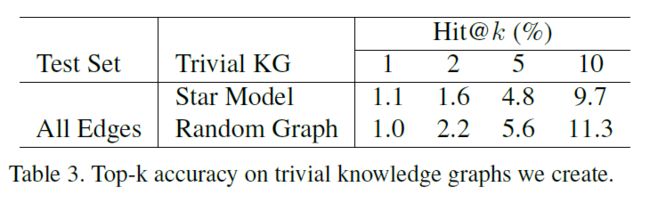
很明显,我们的方法可以处理图中的噪声。但是任何随机图都起作用吗?为了证明图的结构仍然是关键的,我们还创建了一些琐碎的图:(i)星型模型:我们创建了一个只有一个根节点的图,并且只有边将对象节点连接到根节点;(ii)随机图:图中的所有节点都是随机连接的。结果如表3所示。很明显,所有的数字都接近随机猜测,这意味着一个合理的图起着重要的作用,一个随机图可能对模型产生负面影响。
4.1.6 GCN的深度有多重要?(How important is the depth of GCN?)
我们证明,使图卷积网络变深是解决这个问题的关键。我们在表4所示的“所有边”知识图上展示了为模型使用不同层数的性能。对于2层模型,我们使用512个隐藏神经元,4层模型的输出通道数为2048→1024→512→128。我们表明,随着模型从2层深化到6层,性能不断提高。原因是增加卷积次数实质上是增加了图中节点之间的消息传递次数。但是,通过在6层模型上面添加更多层,我们并没有观察到太多的增益。一个潜在的原因可能是随着网络的深入,优化变得更加困难。

4.1.7 我们的网络只是复制分类器作为输出吗?(Is our network just copying classifiers as outputs?)
即使我们证明我们的方法优于ConSE基线,它是否可能学会选择性地复制附近的分类器?为了证明我们的方法不是学习这个平凡的解,我们计算了生成的分类器和训练分类器之间的欧几里得距离。更具体地说,对于一个生成的分类器,我们将其与训练类的分类器进行比较,训练类离分类器的距离最多为3个跃点。我们计算每个生成的分类器与其邻居之间的最小距离。我们对所有88个分类器的距离进行排序,并绘制图4。作为参考,“木勺”与“汤匙”分类器在训练集中的距离为0.26,“木勺”与“擎天柱”的距离为0.78。我们可以看到我们的预测分类器和它的邻居很不一样。

4.1.8 输出是否仅依赖于词嵌入?(Are the outputs only relying on the word embeddings?)
我们执行t-SNE[28]可视化以显示我们的输出分类器不仅仅是从词嵌入派生出来的。我们展示了词嵌入的t-SNE[28]图,以及“所有边”数据集中可见和不可见类的分类器。如图5所示,词嵌入和对象分类器之间的聚类结果非常不同,这表明我们的GCN不仅仅学习从词嵌入到分类器的直接映射。

4.2. WordNet和ImageNet实验
我们现在在一个大得多的ImageNet[42]数据集上执行实验。我们采用与[13,34]相同的训练/测试划分设置。更具体地说,我们报告(report)了3个不同测试数据集的结果:“2-hops”、“3-hops”和整个“all”Imagenet集。这些数据集是根据类与ImageNet 2012 1K数据集中的类的相似程度构建的。例如,“2-hops”数据集(大约1.5K类)包括来自ImageNet 2011 21K集的类,这些类在语义上非常类似于ImageNet 2012 1K类。“3-hops”数据集(大约7.8k类)包括ImageNet 2012 1K类的3个跃点内的类,“all”数据集包括ImageNet 2011 21K中的所有标签。“ImageNet 1K”类与这些3-dataset中的类之间没有通用标签。很明显,随着类数量的增加,任务变得更具挑战性。
对于知识图谱,我们使用WordNet[32]的子图,其中包含大约30k个对象节点。
4.2.1 训练细节(Training details)
注意,要在3个不同的测试集上执行测试,我们只需要训练一组ConvNet和GCN。我们使用两种不同类型的ConvNet作为计算视觉特征的基础网络:inception-v1[46]和resnet-50[17]。两个网络都使用ImageNet 2012 1K数据集进行了预先训练,不需要进行微调。对于inception-v1,第二层到最后一层的输出特征有1024个维度,这导致最后一层中的对象分类器为D=1024个。对于resnet-50,我们有D=2048。除了输出目标的变化外,训练GCN的其他设置与之前对Nell和Neil的实验相同。值得注意的是,我们的GCN模型对不同大小的输出具有鲁棒性。当表示(特征能)从Inception-v1(imagenet 1K VAL集合中的68.7%的Top-1精度)提高到resnet-50(75.3%)时,该模型始终显示出更好的结果。
我们用与之前实验相同的指标来评估我们的方法:在Top-k预测中达到真值标签的百分比。然而,正如[13,34]所建议的那样,在测试过程中,我们不只是用看不见的对象分类器进行测试,而是同时包括训练和预测分类器。注意,在这两个实验设置中,我们仍然对同一组图像进行测试,这些图像只与不可见类相关。
4.2.2 不考虑训练标签的测试(Testing without considering the training labels)
在测试期间,我们首先进行实验,排除属于训练类的分类器。我们将结果报告在表5a。我们将我们的结果与最近最先进的方法SYNC [4] 和 EXEM [5]进行了比较。我们展示了与[4,5]相同的预训练ConvNets (Inception-v1)的实验。由于KG中所有节点的词嵌入都不可用,因此我们使用不同的词嵌入集(GloVe)。

因此,我们首先研究词嵌入的变化是否至关重要。我们通过ConSE基线显示这一点。我们对ConSE的重新实现,在表中显示为“ConSE(us)”,使用GloVe,而在[4,5]中实现的ConSE方法使用自己的词嵌入。我们看到两种方法都有相似的性能。我们的精度在top-1中稍好,而在[4,5]中的精度在top-20中稍好。因此,对于零样本学习,两个词嵌入看起来同样强大。
然后,我们将结果与SYNC [4] 和EXEM [5]进行比较。使用相同的预先训练的ConvNet Inceptionv1,我们的方法在所有数据集和度量上几乎优于所有其他方法。在“2-hops”数据集上,我们的方法比所有方法都有很大的优势:在top-1精度上约有6%,在top-5精度上约有17%。“3跳”数据集,我们的方法始终优于Exem[5],从top-5到top-20大约2~3%。
通过用resnet-50替换Inception-v1,我们在所有度量中获得了另一个性能提升。对于top-5度量,我们的最终模型在“2-hops”数据集中以20.9%、在“3-hops”数据集中以3.5%和在“全部”数据集中以1%的优势超越了最先进的方法Exem[5]。请注意,由于任务难度随着不可见类的数量的增加而增加,因此增益会减小(diminishing)。
4.2.3 对单词嵌入的敏感度(Sensitivity to word embeddings)
我们的方法对词嵌入敏感吗?如果我们使用不同的单词嵌入作为输入,会发生什么?我们研究了3种不同的嵌入词,包括GloVe[36](本文中其他实验中使用的)、FastText[20]和用GoogleNews训练的word2vec[31]。在比较方面,我们还实现了[53]中的方法,它训练了从词嵌入到不带知识图谱的视觉特征的直接映射。我们使用Inception-v1 ConvNet提取视觉特征。我们在ImageNet上显示结果(2跳设置与表5a相同)。我们可以看到[53]高度依赖于词嵌入的质量(top-5结果的范围从17.2%到33.5%)。另一方面,我们的top-5结果稳定在50%左右,远高于[53]。使用GloVe词嵌入,我们的方法比[53]有近200%的相对改进。这再次显示了与知识图谱的图卷积在提高零样本识别率方面发挥了重要作用。

4.2.4 使用训练分类器进行测试(Testing with the training classifiers)
根据[13,34]中的建议,零样本识别的一个更实际的设置是在测试过程中同时包含可见和不可见类分类器。我们在这个广义设置中检验我们的方法。由于此实验设置的可用基线很少,因此我们只能将结果与ConSE 和DeViSE进行比较。我们还重新实现了Inception-v1和 ResNet-50预培训网络的ConSE基线。如表5b所示,与每个度量和所有3个数据集的基线相比,我们的方法的性能几乎翻了一番。此外,我们还可以看到,通过将经过预先训练的Inception-v1网络切换到 ResNet-50,性能得到了提升。
4.2.5 可视化(Visualizations)
最后,我们使用我们的模型和ConSE(图6中T=10)执行可视化(Top-5预测结果)。我们可以看到,在这些例子中,我们的方法明显优于ConSE(10)。尽管在大多数情况下,ConSE(10)仍然给出了合理的结果,但输出标签偏向于在训练标签内。另一方面,我们的方法也输出不可见类。

5. 结论
我们提出了一种零样本识别的方法,利用类别的语义嵌入和知识图谱对新类别与熟悉类别的关系进行编码。我们的工作还表明,知识图谱提供了在语义嵌入之上学习有意义分类器的监督。我们的研究结果表明,与目前最先进的技术相比,有了显著的改进。
6. 启发点
(1)具体来说,将文本映射到可视分类器的问题非常有趣。mapping text to visual
classifiers
参考资料
[1] 【零样本学习】Zero-shot Recognition via Semantic Embeddings and Knowledge Graphs
代码
[1] # JudyYe/zero-shot-gcn