Vite在去年就已经出来了,但我真正的去了解它却是在最近Vue Conf上李奎关于Vite: 下一代web工具的分享。其中他提到的几点吸引到了我。分享的开始,他简要说明了本次分享的关键点:
其中的ESM和esbuild会在下文详细说明
接下来他提到了Bundle-Based Dev Server。也就是我们一直在用的webpack的处理方式:
这里引用官网的一段话:
当我们开始构建越来越大型的应用时,需要处理的JavaScript代码量也呈指数级增长。大型项目包含数千个模块的情况并不少见。我们开始遇到性能瓶颈 —— 使用JavaScript开发的工具通常需要很长时间(甚至是几分钟!)才能启动开发服务器,即使使用HMR,文件修改后的效果也需要几秒钟才能在浏览器中反映出来。如此循环往复,迟钝的反馈会极大地影响开发者的开发效率和幸福感。
简单总结下就是,如果应用比较复杂,使用Webpack的开发过程相对没有那么丝滑:
Webpack Dev Server冷启动时间会比较长Webpack HMR热更新的反应速度比较慢
这就是Vite出现的原因,你可以把它简单理解为:No-Bundler构建方案。其实正是利用了浏览器原生ESM的能力。
但首次提出利用浏览器原生ESM能力的工具并非是Vite,而是一个叫做Snowpack的工具。当然本文不会展开去对比Vite与它的区别,想了解的可戳 Vite 与 X 的区别是?

到这里,我不禁开始去想一个问题:为什么Vite这个工具可以出现,他又是基于哪些前提条件呢?
带着这个问题,结合分享和Vite的源码以及社区的一些文章,我发现了如下几个与Vite可以出现密不可分的模块:
ES ModulesHTTP2ESBuild
这几块其实自己都听过,但是具体的细节也都没有深入去了解。今天正好去深入剖析一下。
ES Modules
在现代前端工程体系中,我们其实一直在使用ES Modules:
import a from 'xxx'
import b from 'xxx'
import c from 'xxx'可能是过于平常化,大家早已习以为常。但如果没有很深入的了解ES Modules,那么可能对于我们理解现有的一些轮子(比如本文的Vite),会有一些阻碍。
ES Modules是浏览器原生支持的模块系统。而在之前,常用的是CommonJS和基于 AMD 的其他模块系统 如 RequireJS。
来看下目前浏览器对其的支持:
主流的浏览器(IE11 除外)均已经支持,其最大的特点是在浏览器端使用 export、 import的方式导入和导出模块,在 script 标签里设置 type="module",然后使用模块内容。
上面说了这么多,毕竟也只是ES Modules的自我介绍。一直以来,他就像黑盒一样,我们并不清楚内部的执行机制。下面就让我们来一窥究竟。
我们先来看一下模块系统的作用:传统script标签的代码加载容易导致全局作用域污染,而且要维系一系列script的书写顺序,项目一大,维护起来越来越困难。模块系统通过声明式的暴露和引用模块使得各个模块之间的依赖变得明显。
当你在使用模块进行开发时,其实是在构建一张依赖关系图。不同模块之间的连线就代表了代码中的导入语句。
正是这些导入语句告诉浏览器或者Node该去加载哪些代码。
我们要做的是为依赖关系图指定一个入口文件。从这个入口文件开始,浏览器或者Node就会顺着导入语句找出所依赖的其他代码文件。
对于 ES 模块来说,这主要有三个步骤:
构造。查找、下载并解析所有文件到模块记录中。实例化。在内存中寻找一块区域来存储所有导出的变量(但还没有填充值)。然后让 export 和 import 都指向这些内存块。这个过程叫做链接(linking)。求值。运行代码,在内存块中填入变量的实际值。

构造阶段(Construction)
在构造阶段,每个模块都会经历三件事情:
Find:找出从哪里下载包含该模块的文件(也称为模块解析)Download:获取文件(从 URL 下载或从文件系统加载)Parse:将文件解析为模块记录
Find 查找
通常我们会有一个主文件main.js作为一切的开始:
然后通过import语句去引入其他模块所导出的内容:

import 语句中的一部分称为 Module Specifier。它告诉 Loader 在哪里可以找到引入的模块。
关于模块标识符有一点需要注意:它们有时需要在浏览器和Node之间进行不同的处理。每个宿主都有自己的解释模块标识符字符串的方式。
目前在浏览器中只能使用 URL 作为 Module Specifier,也就是使用 URL 去加载模块。
Download 下载
而有个问题也随之而来,浏览器在解析文件前并不知道文件依赖哪些模块,当然获取文件之前更无法解析文件。
这将导致整个解析依赖关系的流程是阻塞的。
像这样阻塞主线程会让采用了模块的应用程序速度太慢而无法使用。这是 ES 模块规范将算法分为多个阶段的原因之一。将构造过程单独分离出来,使得浏览器在执行同步的初始化过程前可以自行下载文件并建立自己对于模块图的理解。
对于 ES 模块,在进行任何求值之前,你需要事先构建整个模块图。这意味着你的模块标识符中不能有变量,因为这些变量还没有值。
但有时候在模块路径使用变量确实非常有用。例如,你可能需要根据代码的运行情况或运行环境来切换加载某个模块。
为了让 ES 模块支持这个,有一个名为 动态导入 的提案。有了它,你可以像 import(${path} /foo.js 这样使用 import 语句。
它的原理是,任何通过 import() 加载的的文件都会被作为一个独立的依赖图的入口。动态导入的模块开启一个新的依赖图,并单独处理。
Parse 解析
实际上解析文件是有助于浏览器了解模块内的构成,而我们把它解析出来的模块构成表 称为 Module Record 模块记录。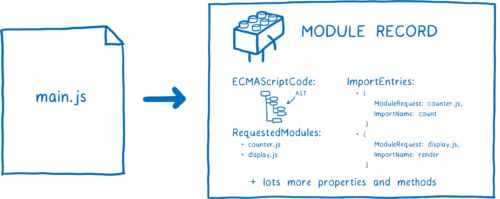
模块记录包含了当前模块的 AST,引用了哪些模块的变量,以前一些特定属性和方法。
一旦模块记录被创建,它会被记录在模块映射Module Ma中。被记录后,如果再有对相同 URL 的请求,Loader 将直接采用 Module Map 中 URL 对应的Module Record。

解析中有一个细节可能看起来微不足道,但实际上有很大的影响。所有的模块都被当作在顶部使用了 "use strict" 来解析。还有一些其他细微差别。例如,关键字 await 保留在模块的顶层代码中,this 的值是 undefined。
这种不同的解析方式被称为解析目标。如果你使用不同的目标解析相同的文件,你会得到不同的结果。所以在开始解析前你要知道正在解析的文件的类型:它是否是一个模块?
在浏览器中这很容易。你只需在 script 标记中设置 type="module"。这告诉浏览器此文件应该被解析为一个模块。
但在 Node 中,是没有 HTML 标签的,所以需要其他的方式来辨别,社区目前的主流解决方式是修改文件的后缀为 .mjs,来告诉 Node 这将是一个模块。不过还没有标准化,而且还存在很多兼容问题。
到这里,在加载过程结束时,从普通的主入口文件变成了一堆模块记录Module Record。
下一步是实例化此模块并将所有实例链接在一起。
实例化阶段
为了实例化 Module Record,引擎将采用 Depth First Post-order Traversal(深度优先后序)进行遍历,JS引擎将会为每一个 Module Record 创建一个 Module Environment Record 模块环境记录,它将管理 Module Record 对应的变量,并为所有 export 分配内存空间。
ES Modules 的这种连接方式被称为 Live Bindings(动态绑定)。
之所以 ES Modules 采用 Live Bindings,是因为这将有助于做静态分析以及规避一些问题,如循环依赖。
而 CommonJS 导出的是 copy 后的 export 对象,这意味着如果导出模块稍后更改该值,则导入模块并不会看到该更改。
这也就是通常所见到的结论:CommonJS 模块导出是值的拷贝,而 ES Modules 是值的引用。
求值阶段(evaluate)
最后一步是在内存中填值。还记得我们通过内存连接好了所有 export 和 import吗,但内存还尚未有值。
JS 引擎通过执行顶层代码(函数之外的代码),来向这些内存区添值。
至此ES Modules的黑盒我就大致分析完了。
当然这部分我是参考了 es-modules-a-cartoon-deep-dive,然后结合自己的理解得出的分析,想更深入了解其背后实现,可狠狠戳上面的链接。
ES Modules在Vite中的体现我们可以打开一个运行中的Vite项目:
从上图可以看到:
import { createApp } from "/node_modules/.vite/vue.js?v=2122042e";与以往的import { createApp } from "vue"不同,这里对引入的模块路径进行了重写: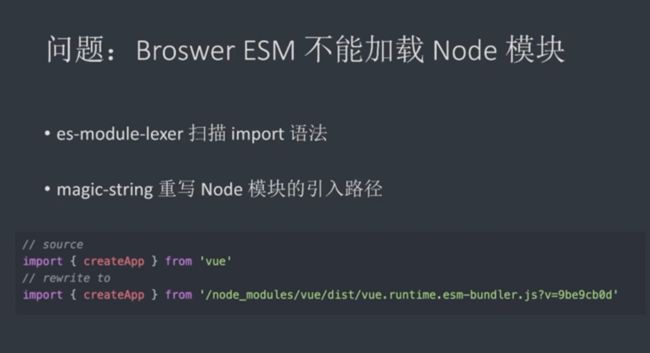
Vite利用现代浏览器原生支持ESM特性,省略了对模块的打包。(这也是开发环境下项目启动和热更新比较快的很重要的原因)
HTTP2
来看HTTP2前,我们先来了解一下HTTP的发展史。
我们知道 HTTP 是浏览器中最重要且使用最多的协议,是浏览器和服务器之间的通信语言。随着浏览器的发展,HTTP为了能适应新的形式也在持续进化。
最开始出现的HTTP/0.9实现相对较为简单:采用了基于请求响应的模式,从客户端发出请求,服务器返回数据。
从图中可以看出其只有一个请求行且服务器也没有返回头信息。
万维网的高速发展带来了很多新的需求,而 HTTP/0.9 已经不能适用新兴网络的发展,所以这时就需要一个新的协议来支撑新兴网络,这就是 HTTP/1.0 诞生的原因。
并且在浏览器中展示的不单是 HTML 文件了,还包括了 JavaScript、CSS、图片、音频、视频等不同类型的文件。因此支持多种类型的文件下载是 HTTP/1.0 的一个核心诉求。
为了让客户端和服务器能更深入地交流,HTTP/1.0 引入了请求头和响应头,它们都是以 Key-Value 形式保存的,在 HTTP 发送请求时,会带上请求头信息,服务器返回数据时,会先返回响应头信息。HTTP/1.0 具体的请求流程可以参考下图:
HTTP/1.0 每进行一次 HTTP 通信,都需要经历建立 TCP 连接、传输 HTTP 数据和断开 TCP 连接三个阶段。在当时,由于通信的文件比较小,而且每个页面的引用也不多,所以这种传输形式没什么大问题。但是随着浏览器普及,单个页面中的图片文件越来越多,有时候一个页面可能包含了几百个外部引用的资源文件,如果在下载每个文件的时候,都需要经历建立 TCP连接、传输数据和断开连接这样的步骤,无疑会增加大量无谓的开销。
为了解决这个问题,HTTP/1.1 中增加了持久连接的方法,它的特点是在一个 TCP 连接上可以传输多个 HTTP 请求,只要浏览器或者服务器没有明确断开连接,那么该 TCP 连接会一直保持。并且浏览器中对于同一个域名,默认允许同时建立 6 个 TCP 持久连接。
通过这些方式在某种程度上大幅度提高了页面的下载速度。
之前我们使用Webpack打包应用代码,使之成为一个bundle.js,有一个很重要的原因是:零散的模块文件会产生大量的HTTP请求。而大量的HTTP请求在浏览器端就会产生并发请求资源的问题:
如上图所示,红色圈起来的部分的请求就是并发请求,但是后面的请求就因为域名连接数已超过限制,而被挂起等待了一段时间。
在HTTP1.1的标准下,每次请求都需要单独建立TCP连接,经过完整的通讯过程,非常耗时。之所以会出现这个问题,主要是由以下三个原因导致的:
TCP的慢启动TCP连接之间相互竞争带宽- 队头阻塞
前两个问题是由于TCP本身的机制导致的,而队头阻塞是由于HTTP/1.1的机制导致的。
为了解决这些已知问题,HTTP/2的思路就是一个域名只使用一个 TCP 长连接来传输数据,这样整个页面资源的下载过程只需要一次慢启动,同时也避免了多个 TCP 连接竞争带宽所带来的问题。
也就是常说的多路复用,它能实现资源的并行传输。
上文中也提到了Vite使用 ESM 在浏览器里使用模块,就是使用 HTTP 请求拿到模块。这样就会产生大量的HTTP 请求,但由于HTTP/2的多路复用机制的出现,很好的解决了传输耗时久的问题。
ESBuild
esbuild官方的介绍:它是一个JavaScript Bundler 打包和压缩工具,它可以将JavaScript和TypeScript代码打包分发在网页上运行。
esbuild底层使用的golang进行编写的,在对比传统web构建工具的打包速度上,具有明显的优势。编译Typescript的速度远超官方的tsc。
对于JSX、或者TS 等需要编译的文件,Vite是用esbuild来进行编译的,不同于Webpack的整体编译,Vite是在浏览器请求时,才对文件进行编译,然后提供给浏览器。因为esbuild编译够快,这种每次页面加载都进行编译的其实是不会影响加速速度的。
Vite 实现原理
结合上面的分析和源码,可以用一句话来简述Vite的原理:Static Server + Compile + HMR:
- 将当前项目目录作为静态文件服务器的根目录
拦截部分文件请求
- 处理代码中
import node_modules中的模块 - 处理
vue单文件组件(SFC)的编译
- 处理代码中
- 通过
WebSocket实现HMR
当然关于类似手写Vite实现的文章社区已经有很多了,这里就不赘述了,大致原理都是一样的。
总结
本文写完带给我更多的是一些思考。从一次分享去发掘其背后庞大的生态体系以及那些我们一直在用却并未深入了解的技术黑盒。
更多的是,感叹大佬们的想法,站在技术的制高点,拥有较高的深度和广度,开发一些对于提高生产力极其有用的轮子。
所以,文章写完了,学习的步伐任在前进~
参考
- https://hacks.mozilla.org/201...
- https://github.com/evanw/esbuild
- 极客时间/罗剑锋/透视HTTP协议