JAVA数据处理
字符串处理
一般程序需要处理大量文本数据,Java 语言的文本数据被保存为字符或字符串类型。字符串是 Java 程序中经常处理的对象之一,字符及字符串的操作主要用到 String 类和 StringBuffer 类,如连接、修改、替换、比较和查找等。
Java定义字符串
字符串是 Java 中特殊的类,使用方法像一般的基本数据类型,被广泛应用在 Java 编程中。Java 没有内置的字符串类型,而是在标准 Java 类库中提供了一个 String 类来创建和操作字符串。
在 Java 中定义一个字符串最简单的方法是用双引号把它包围起来。这种用双引号括起来的一串字符实际上都是 String 对象,如字符串“Hello”在编译后即成为 String 对象。因此也可以通过创建 String 类的实例来定义字符串。
不论使用哪种形式创建字符串,字符串对象一旦被创建,其值是不能改变的,但可以使用其他变量重新赋值的方式进行更改。
直接定义字符串
直接定义字符串是指使用双引号表示字符串中的内容,具体方法是用字符串常量直接初始化一个 String 对象,示例如下:
String str = "Hello Java";
或者
String str;str = "Hello Java";
注意:字符串变量必须经过初始化才能使用。
使用 String 类定义
前面提到在 Java 中每个双引号定义的字符串都是一个 String 类的对象。因此,可以通过使用 String 类的构造方法来创建字符串,该类位于 java.lang 包中。
String 类的构造方法有多种重载形式,每种形式都可以定义字符串。下面介绍最常用的几种形式。
注意:具有和类名相同的名称,而且没有返回类型的方法称为构造方法。重载是指在一个类中定义多个同名的方法,但要求每个方法具有不同的参数的类型或参数的个数。
1. String()
初始化一个新创建的 String 对象,表示一个空字符序列。
2. String(String original)
初始化一个新创建的 String 对象,使其表示一个与参数相同的字符序列。换句话说,新创建的字符串是该参数字符串的副本。例如:
String str1 = new String("Hello Java");
String str2 = new String(str1);
这里 str1 和 str2 的值是相等的。
3. String(char[ ]value)
分配一个新的字符串,将参数中的字符数组元素全部变为字符串。该字符数组的内容已被复制,后续对字符数组的修改不会影响新创建的字符串。例如:
char a[] = {'H','e','l','l','0'};
String sChar = new String(a);a[1] = 's';
上述 sChar 变量的值是字符串“Hello”。 即使在创建字符串之后,对 a 数组中的第 2 个元素进行了修改,但未影响 sChar 的值。
4. String(char[] value,int offset,int count)
分配一个新的 String,它包含来自该字符数组参数一个子数组的字符。offset 参数是子数组第一个字符的索引,count 参数指定子数组的长度。该子数组的内容已被赋值,后续对字符数组的修改不会影响新创建的字符串。例如:
char a[]={'H','e','l','l','o'};
String sChar=new String(a,1,4);a[1]='s';
上述 sChar 变量的值是字符串“ello”。该构造方法使用字符数组中的部分连续元素来创建字符串对象。offset 参数指定起始索引值,count 指定截取元素的个数。创建字符串对象后,即使在后面修改了 a 数组中第 2 个元素的值,对 sChar 的值也没有任何影响
String&int相互转换
String 在编程中被广泛使用,所以掌握 String 和 int 的相互转换方法是极其重要的。
String转换为int
String 字符串转整型 int 有以下两种方式:
- Integer.parseInt(str)
- Integer.valueOf(str).intValue()
注意:Integer 是一个类,是 int 基本数据类型的封装类。
在 String 转换 int 时,String 的值一定是整数,否则会报数字转换异常(java.lang.NumberFormatException)。
int转换为String
整型 int 转 String 字符串类型有以下 3 种方法:
- String s = String.valueOf(i);
- String s = Integer.toString(i);
- String s = "" + i;
在使用 valueOf() 方法时,注意 valueOf 括号中的值不能为空,否则会报空指针异常(NullPointerException)。
valueOf() 、parse()和toString()
valueOf()
valueOf() 方法将数据的内部格式转换为可读的形式。它是一种静态方法,对于所有 Java 内置的类型,在字符串内被重载,以便每一种类型都能被转换成字符串。valueOf() 方法还被类型 Object 重载,所以创建的任何形式类的对象也可被用作一个参数。这里是它的几种形式:
static String valueOf(double num)
static String valueOf(long num)
static String valueOf(Object ob)
static String valueOf(char chars[])
与前面的讨论一样,调用 valueOf() 方法可以得到其他类型数据的字符串形式。
例如在进行连接操作时。对各种数据类型,可以直接调用这种方法得到合理的字符串形式。所有的简单类型数据转换成相应于它们的普通字符串形式。任何传递给 valueOf() 方法的对象都将返回对象的 toString() 方法调用的结果。事实上,也可以通过直接调用 toString() 方法而得到相同的结果。
对大多数数组,valueOf() 方法返回一个相当晦涩的字符串,这说明它是一个某种类型的数组。然而对于字符数组,它创建一个包含了字符数组中的字符的字符串对象。valueOf() 方法有一种特定形式允许指定字符数组的一个子集。
它具有如下的一般形式:
static String valueOf(char chars[ ], int startIndex, int numChars)
这里 chars 是存放字符的数组,startIndex 是字符数组中期望得到的子字符串的首字符下标,numChars 指定子字符串的长度。
parse()
parseXxx(String) 这种形式,是指把字符串转换为数值型,其中 Xxx 对应不同的数据类型,然后转换为 Xxx 指定的类型,如 int 型和 float 型。
toString()
toString() 可以把一个引用类型转换为 String 字符串类型,是 sun 公司开发 Java 的时候为了方便所有类的字符串操作而特意加入的一个方法。
字符串的拼接
对于已经定义的字符串,可以对其进行各种操作。连接多个字符串是字符串操作中最简单的一种。通过字符串连接,可以将两个或多个字符串、字符、整数和浮点数等类型的数据连成一个更大的字符串。
String 字符串虽然是不可变字符串,但也可以进行拼接只是会产生一个新的对象。String 字符串拼接可以使用“+”运算符或 String 的 concat(String str) 方法。“+”运算符优势是可以连接任何类型数据拼接成为字符串,而 concat 方法只能拼接 String 类型字符串。
使用连接运算符“+”
与绝大多数的程序设计语言一样,Java 语言允许使用“+”号连接(拼接)两个字符串。“+”运算符是最简单、最快捷,也是使用最多的字符串连接方式。在使用“+”运算符连接字符串和 int 型(或 double 型)数据时,“+”将 int(或 double)型数据自动转换成 String 类型。
使用 concat() 方法
在 Java 中,String 类的 concat() 方法实现了将一个字符串连接到另一个字符串的后面。concat() 方法语法格式如下:
字符串 1.concat(字符串 2);
执行结果是字符串 2 被连接到字符串 1 后面,形成新的字符串。
如 concat() 方法的语法所示,concat() 方法一次只能连接两个字符串,如果需要连接多个字符串,需要调用多次 concat() 方法。
连接其他类型数据
前面介绍的例子都是字符串与字符串进行连接,其实字符串也可同其他基本数据类型进行连接。
如果将字符串同这些数据类型数据进行连接,此时会将这些数据直接转换成字符串。
编写一个 Java 程序,实现将字符串与整型、浮点型变量相连并输出结果。实现代码如下:
public static void main(String[] args) {
String book = "三国演义"; // 字符串
int price = 59; // 整型变量
float readtime = 2.5f; // 浮点型变量
System.out.println("我买了一本图书,名字是:" + book + "\n价格是:" + price + "\n我每天阅读" + readtime + "小时");
}
上述代码实现的是将字符串变量 book 与整型变量 price 和浮点型变量 readtime 相连后将结果输出。在这里定义的 price 和 readtime 都不是字符串,当它们与字符串相连时会自动调用自身的 toString() 方法将其转换成字符串形式,然后再参与连接运算。因此,程序运行后的结果如下所示:
我买了一本图书,名字是:三国演义
价格是:59
我每天阅读2.5小时
假设将本例中的输出语句修改为如下形式:
System.out.println("我买了一本图书,名字是:"+book+"\n 价格是:"+price+"\n我每天阅读"+(price+readtime)+"小时");
因为运算符具有优先级,而圆括号的优先级最高,所以先计算 price 与 readtime 的和,再将结果转换成字符串进行连接。此时的运行结果如下所示:
我买了一本图书,名字是:三国演义
价格是:59
我每天阅读61.5小时
注意:只要“+”运算符的一个操作数是字符串,编译器就会将另一个操作数转换成字符串形式,所以应该谨慎地将其他数据类型与字符串相连,以免出现意想不到的结果。
常用的字符串处理方法
字符串获取长度
在 Java中,要获取字符串的长度,可以使用 String 类的 length() 方法,其语法形式如下:
字符串名.length();
如:在学生信息管理系统中对管理员密码有这样的规定,即密码长度必须大于 6 位且小于 12 位。因为密码太短容易被破解,太长的话又不容易记住。这就需要首先获取用户输入的密码字符串,然后调用 length() 方法获取长度,再做进一步的长度判断,最终实现代码如下所示:
public static void main(String[] args) {
String sys = "学生信息管理";// 字义一个字符串表示系统名称
System.out.println("欢迎进入《" + sys + "》系统");// 输出系统名称
System.out.println("请设置一个管理员密码:");
Scanner input = new Scanner(System.in);
String pass = input.next();// 获取用户输入的密码
int length = pass.length();// 获取密码的长度
if (length > 6 && length < 12) {
System.out.println("密码长度符合规定。");
System.out.println("已生效,请牢记密码:" + pass);
} else if (length >= 12) {
System.out.println("密码过长。");
} else {
System.out.println("密码过短。");
}
}
上述代码将用户输入的密码保存到字符串变量 pass 中,再调用 pass.length() 方法将长度保存到 length 变量,然后使用 if 语句根据长度给出提示。
字符串转小写
String 类的 toLowerCase() 方法可以将字符串中的所有字符全部转换成小写,而非字母的字符不受影响。语法格式如下:
字符串名.toLowerCase() // 将字符串中的字母全部转换为小写,非字母不受影响
例如:
String str="abcdef 我 ghijklmn";
System.out.println(str.toLowerCase()); // 输出:abcdef 我 ghijklmn
字符串转大写
String 类的toUpperCase() 则将字符串中的所有字符全部转换成大写,而非字母的字符不受影响。语法格式如下:
字符串名.toUpperCase() // 将字符串中的字母全部转换为大写,非字母不受影响
例如:
String str="abcdef 我 ghijklmn";
System.out.println(str.toUpperCase()); // 输出:ABCDEF 我 GHIJKLMN
字符串去空格
字符串中存在的首尾空格一般情况下都没有任何意义,如字符串“ Hello ”,但是这些空格会影响到字符串的操作,如连接字符串或比较字符串等,所以应该去掉字符串中的首尾空格,这需要使用 String 类提供的 trim() 方法。
trim() 方法的语法形式如下:
字符串名.trim()
使用 trim() 方法的示例如下:
String str = " hello ";System.out.println(str.length()); // 输出 7System.out.println(str.trim().length()); // 输出 5
从该示例中可以看出,字符串中的每个空格占一个位置,直接影响了计算字符串的长度。
如果不确定要操作的字符串首尾是否有空格,最好在操作之前调用该字符串的 trim() 方法去除首尾空格,然后再对其进行操作。
注意:trim() 只能去掉字符串中前后的半角空格(英文空格),而无法去掉全角空格(中文空格)。可用以下代码将全角空格替换为半角空格再进行操作,其中替换是 String 类的 replace() 方法。
str = str.replace((char) 12288, ' '); // 将中文空格替换为英文空格
str = str.trim();
其中,12288 是中文全角空格的 unicode 编码。
字符串截取
在 String 中提供了两个截取字符串的方法,一个是从指定位置截取到字符串结尾,另一个是截取指定范围的内容。下面对这两种方法分别进行介绍。
substring(int beginIndex) 形式
此方式用于提取从索引位置开始至结尾处的字符串部分。调用时,括号中是需要提取字符串的开始位置,方法的返回值是提取的字符串。例如:
String str = "我爱 Java 编程";
String result = str.substring(3);
System.out.println(result); // 输出:Java 编程
substring(int beginIndex,int endIndex) 形式
此方法中的 beginIndex 表示截取的起始索引,截取的字符串中包括起始索引对应的字符;endIndex 表示结束索引,截取的字符串中不包括结束索引对应的字符,如果不指定 endIndex,则表示截取到目标字符串末尾。该方法用于提取位置 beginIndex 和位置 endIndex 位置之间的字符串部分。
这里需要特别注意的是, 对于开始位置 beginIndex, Java 是基于字符串的首字符索引为 0 处理的,但是对于结束位置 endIndex,Java 是基于字符串的首字符索引为 1 来处理的,如图所示。

注意:substring() 方法是按字符截取,而不是按字节截取。
例:创建一个字符串,对它使用 substring() 方法进行截取并输出结果。示例代码如下:
public static void main(String[] args) {
String day = "Today is Monday"; //原始字符串
System.out.println("substring(0)结果:"+day.substring(0));
System.out.println("substring(2)结果:"+day.substring(2));
System.out.println("substring(10)结果:"+day.substring(10));
System.out.println("substring(2,10)结果:"+day.substring(2,10));
System.out.println("substring(0,5)结果:"+day.substring(0,5));
}
输出结果如下所示:
substring(0)结果:Today is Monday
substring(2)结果:day is Monday
substring(10)结果:onday
substring(2,10)结果:day is M
substring(0,5)结果:Today
分割字符串
String 类的 split() 方法可以按指定的分割符对目标字符串进行分割,分割后的内容存放在字符串数组中。该方法主要有如下两种重载形式:
str.split(String sign)str.split(String sign,int limit)
其中它们的含义如下:
- str 为需要分割的目标字符串。
- sign 为指定的分割符,可以是任意字符串。
- limit 表示分割后生成的字符串的限制个数,如果不指定,则表示不限制,直到将整个目标字符串完全分割为止。
使用分隔符注意如下:
1)“.”和“|”都是转义字符,必须得加“\”。
- 如果用“.”作为分隔的话,必须写成
String.split("\\."),这样才能正确的分隔开,不能用String.split(".")。 - 如果用“|”作为分隔的话,必须写成
String.split("\\|"),这样才能正确的分隔开,不能用String.split("|")。
2)如果在一个字符串中有多个分隔符,可以用“|”作为连字符,比如:“acount=? and uu =? or n=?”,把三个都分隔出来,可以用String.split("and|or")。
例 :用 split() 方法对字符串进行分割的实例如下:
public static void main(String[] args) {
String Colors = "Red,Black,White,Yellow,Blue";
String[] arr1 = Colors.split(","); // 不限制元素个数
String[] arr2 = Colors.split(",", 3); // 限制元素个数为3
System.out.println("所有颜色为:");
for (int i = 0; i < arr1.length; i++) {
System.out.println(arr1[i]);
}
System.out.println("前三个颜色为:");
for (int j = 0; j < arr2.length; j++) {
System.out.println(arr2[j]);
}
}
输出结果如下:
所有颜色为:
Red
Black
White
Yellow Blue
前三个颜色为:
Red
Black
White,Yellow,Blue
从输出的结果可以看出,当指定分割字符串后组成的数组长度(大于或等于 1)时,数组的前几个元素为字符串分割后的前几个字符,而最后一个元素为字符串的剩余部分。
例如,在该实例中,指定了 arr2 的长度为 3,而字符串 Colors 分割后组成的数组长度为 5。因此会将 arr2 中的前两个元素赋值为 Colors 分割后的前两个字符,arr2 中的第 3 个元素为 Colors 字符串的后 3 个字符组成的字符串。
字符串替换
在 Java 中,String 类提供了 3 种字符串替换方法,分别是 replace()、replaceFirst() 和 replaceAll()。
replace() 方法
replace() 方法用于将目标字符串中的指定字符(串)替换成新的字符(串),其语法格式如下:
字符串.replace(String oldChar, String newChar)
其中,oldChar 表示被替换的字符串;newChar 表示用于替换的字符串。replace() 方法会将字符串中所有 oldChar 替换成 newChar。
例:创建一个字符串,对它使用 replace() 方法进行字符串替换并输出结果。代码如下:
public static void main(String[] args) {
String words = "hello java,hello php";
System.out.println("原始字符串是'"+words+"'");
System.out.println("replace(\"l\",\"D\")结果:"+words.replace("l","D"));
System.out.println("replace(\"hello\",\"你好\")结果:"+words.replace("hello","你好 "));
words = "hr's dog";
System.out.println("原始字符串是'"+words+"'");
System.out.println("replace(\"r's\",\"is\")结果:"+words.replace("r's","is"));
}
输出结果如下所示:
原始字符串是'hello java,hello php'
replace("l","D")结果:heDDo java,heDDo php
replace("hello","你好")结果:你好 java,你好 php
原始字符串是'hr's dog'
replace("r's","is")结果:his dog
replaceFirst() 方法
replaceFirst() 方法用于将目标字符串中匹配某正则表达式的第一个子字符串替换成新的字符串,其语法形式如下:
字符串.replaceFirst(String regex, String replacement)
其中,regex 表示正则表达式;replacement 表示用于替换的字符串。例如:
String words = "hello java,hello php";
String newStr = words.replaceFirst("hello","你好 ");
System.out.println(newStr); // 输出:你好 java,hello php
replaceAll() 方法
replaceAll() 方法用于将目标字符串中匹配某正则表达式的所有子字符串替换成新的字符串,其语法形式如下:
字符串.replaceAll(String regex, String replacement)
其中,regex 表示正则表达式,replacement 表示用于替换的字符串。例如:
String words = "hello java,hello php";
String newStr = words.replaceAll("hello","你好 ");
System.out.println(newStr); // 输出:你好 java,你好 php
例子
假设有一段文本里面有很多错误,如错别字。现在使用 Java 中的字符串替换方法对它进行批量修改和纠正,其中就用到了 String 类的 replace() 方法、replaceFirst() 方法和 replaceAll() 方法。
创建一个 Java 类,然后在主方法 main() 中编写代码,具体代码如下所示。
public static void main(String[] args) {
// 定义原始字符串
String intro = "今天时星其天,外面时下雨天。妈米去买菜了,漏网在家写作业。" + "语文作业时”其”写 5 行,数学使第 10 页。";
// 将文本中的所有"时"和"使"都替换为"是"
String newStrFirst = intro.replaceAll("[时使]", "是");
// 将文本中的所有"妈米"改为"妈妈"
String newStrSecond = newStrFirst.replaceAll("妈米", "妈妈");
// 将文本中的所有"漏网"改为"留我"
String newStrThird = newStrSecond.replaceAll("漏网", "留我");
// 将文本中第一次出现的"其"改为"期"
String newStrFourth = newStrThird.replaceFirst("[其]", "期");
// 输出最终字符串
System.out.println(newStrFourth);
}
运行该程序,输出的正确字符串内容如下:
今天是星期天,外面是下雨天。妈妈去买菜了,留我在家写作业。语文作业是”其”写 5 行,数学是第 10 页。
字符串比较
字符串比较是常见的操作,包括比较相等、比较大小、比较前缀和后缀串等。在 Java 中,比较字符串的常用方法有 3 个:equals() 方法、equalsIgnoreCase() 方法、 compareTo() 方法。
equals() 方法
equals() 方法将逐个地比较两个字符串的每个字符是否相同。如果两个字符串具有相同的字符和长度,它返回 true,否则返回 false。对于字符的大小写,也在检查的范围之内。equals() 方法的语法格式如下:
str1.equals(str2);
str1 和 str2 可以是字符串变量, 也可以是字符串字面量。 例如, 下列表达式是合法的:
"Hello".equals(greeting)
下面的代码说明了 equals() 方法的使用:
String str1 = "abc";
String str2 = new String("abc");
String str3 = "ABC";
System.out.println(str1.equals(str2)); // 输出 trueSystem.out.println(str1.equals(str3)); // 输出 false
例 :在第一次进入系统时要求管理员设置一个密码,出于安全考虑密码需要输入两次,如果两次输入的密码一致才生效,否则提示失败。具体实现代码如下:
public static void main(String[] args) {
String sys = "学生信息管理";
System.out.println("欢迎进入《" + sys + "》系统");
System.out.println("请设置一个管理员密码:");
Scanner input = new Scanner(System.in);
String pass = input.next(); // 设置密码
System.out.println("重复管理员密码:");
input = new Scanner(System.in);
String pass1 = input.next(); // 确认密码
if (pass.equals(pass1)) { // 比较两个密码
System.out.println("已生效,请牢记密码:" + pass);
} else {
System.out.println("两次密码不一致,请重新设置。");
}
}
运行该程序,由于 equals() 方法区分大小写,所以当两次输入的密码完全一致时,equals() 方法返回 true,输出结果如下所示:
欢迎进入《学生信息管理》系统
请设置一个管理员密码:
abcdef
重复管理员密码:
abcdef
已生效,请牢记密码:abcdef
否则输出如图下所示的结果:
欢迎进入《学生信息管理》系统
请设置一个管理员密码:
abcdef
重复管理员密码:
aBcdef
两次密码不一致,请重新设置。
equalsIgnoreCase() 方法
equalsIgnoreCase() 方法的作用和语法与 equals() 方法完全相同,唯一不同的是 equalsIgnoreCase() 比较时不区分大小写。当比较两个字符串时,它会认为 A-Z 和 a-z 是一样的。
下面的代码说明了 equalsIgnoreCase() 的使用:
String str1 = "abc";
String str2 = "ABC";
System.out.println(str1.equalsIgnoreCase(str2)); // 输出 true
例:在会员系统中需要输入用户名和密码进行检验,使用 equalsIgnoreCase() 方法实现检验登录时不区分用户名和密码的大小写,具体的代码实现如下所示。
public static void main(String[] args) {
String sys = "学生信息管理";
System.out.println("欢迎进入《" + sys + "》系统");
System.out.println("请输入管理员名称:");
Scanner input = new Scanner(System.in);
String name = input.next(); // 获取用户输入的名称
System.out.println("请输入管理员密码:");
input = new Scanner(System.in);
String pass = input.next(); // 获取用户输入的密码
// 比较用户名与密码,注意此处忽略大小写
if (name.equalsIgnoreCase("admin") && pass.equalsIgnoreCase("somboy")) { // 验证
System.out.println("登录成功。");
} else {
System.out.println("登录失败。");
}
}
在上述代码中,由于使用 equalsIgnoreCase() 方法进行比较,所以会忽略大小写判断。因此输入 ADMIN 和 SOMBOY 也会验证通过,如下所示:
欢迎进入《学生信息管理》系统
请输入管理员名称:
ADMIN
请输入管理员密码:
SOMBOY
登录成功。
否则输出结果如下所示:
欢迎进入《学生信息管理》系统
请输入管理员名称:
admin
请输入管理员密码:
sommboy
登录失败。
==的比较
理解 equals() 方法和==运算符执行的是两个不同的操作是重要的。如同刚才解释的那样,equals() 方法比较字符串对象中的字符。而==运算符比较两个对象引用看它们是否引用相同的实例。
下面的程序说明了两个不同的字符串(String)对象是如何能够包含相同字符的,但同时这些对象引用是不相等的:
String s1 = "Hello";
String s2 = new String(s1);
System.out.println(s1.equals(s2)); // 输出trueSystem.out.println(s1 == s2); // 输出false
变量 s1 指向由“Hello”创建的字符串实例。s2 所指的的对象是以 s1 作为初始化而创建的。因此这两个字符串对象的内容是一样的。但它们是不同的对象,这就意味着 s1 和 s2 没有指向同一的对象,因此它们是不==的。
因此,千万不要使用==运算符测试字符串的相等性,以免在程序中出现糟糕的 bug。从表面上看,这种 bug 很像随机产生的间歇性错误。
compareTo() 方法
通常,仅仅知道两个字符串是否相同是不够的。对于排序应用来说,必须知道一个字符串是大于、等于还是小于另一个。一个字符串小于另一个指的是它在字典中先出现。而一个字符串大于另一个指的是它在字典中后出现。字符串(String)的 compareTo() 方法实现了这种功能。
compareTo() 方法用于按字典顺序比较两个字符串的大小,该比较是基于字符串各个字符的 Unicode 值。compareTo() 方法的语法格式如下:
str.compareTo(String otherstr);
它会按字典顺序将 str 表示的字符序列与 otherstr 参数表示的字符序列进行比较。如果按字典顺序 str 位于 otherster 参数之前,比较结果为一个负整数;如果 str 位于 otherstr 之后,比较结果为一个正整数;如果两个字符串相等,则结果为 0。
提示:如果两个字符串调用 equals() 方法返回 true,那么调用 compareTo() 方法会返回 0。
例:编写一个简单的 Java 程序,演示 compareTo() 方法比较字符串的用法,以及返回值的区别。代码如下:
public static void main(String[] args) {
String str = "A";
String str1 = "a";
System.out.println("str=" + str);
System.out.println("str1=" + str1);
System.out.println("str.compareTo(str1)的结果是:" + str.compareTo(str1));
System.out.println("str1.compareTo(str)的结果是:" + str1.compareTo(str));
System.out.println("str1.compareTo('a')的结果是:" + str1.compareTo("a"));
}
上述代码定义了两个字符串“A”和“a”,然后调用 compareTo() 方法进行相互比较。最后一行代码拿“a”与“a”进行比较,由于两个字符串相同比较结果为 0。运行后的输出结果如下:
str = A
str1 = a
str.compareTo(str1)的结果是:-32
str1.compareTo(str)的结果是:32
str1.compareTo('a')的结果是:0
字符串查找
在给定的字符串中查找字符或字符串是比较常见的操作。字符串查找分为两种形式:一种是在字符串中获取匹配字符(串)的索引值,另一种是在字符串中获取指定索引位置的字符。
根据字符查找
String 类的 indexOf() 方法和 lastlndexOf() 方法用于在字符串中获取匹配字符(串)的索引值。
indexOf() 方法
indexOf() 方法用于返回字符(串)在指定字符串中首次出现的索引位置,如果能找到,则返回索引值,否则返回 -1。该方法主要有两种重载形式:
str.indexOf(value)str.indexOf(value,int fromIndex)
其中,str 表示指定字符串;value 表示待查找的字符(串);fromIndex 表示查找时的起始索引,如果不指定 fromIndex,则默认从指定字符串中的开始位置(即 fromIndex 默认为 0)开始查找。
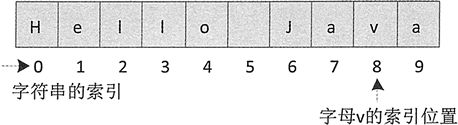
例如,下列代码在字符串“Hello Java”中查找字母 v 的索引位置。
String s = "Hello Java";
int size = s.indexOf('v'); // size的结果为8
上述代码执行后 size 的结果为 8,它的查找过程如图 1 所示。
例:编写一个简单的 Java 程序,演示 indexOf() 方法查找字符串的用法,并输出结果。代码如下:
public static void main(String[] args) {
String words = "today,monday,sunday";
System.out.println("原始字符串是'"+words+"'");
System.out.println("indexOf(\"day\")结果:"+words.indexOf("day"));
System.out.println("indexOf(\"day\",5)结果:"+words.indexOf("day",5));
System.out.println("indexOf(\"o\")结果:"+words.indexOf("o"));
System.out.println("indexOf(\"o\",6)结果:"+words.indexOf("o",6));
}
运行后的输出结果如下:
原始字符串是'today,monday,sunday'
indexOf("day")结果:2
indexOf("day",5)结果:9
indexOf("o")结果:1
indexOf("o",6)结果:7
lastlndexOf() 方法
lastIndexOf() 方法用于返回字符(串)在指定字符串中最后一次出现的索引位置,如果能找到则返回索引值,否则返回 -1。该方法也有两种重载形式:
str.lastIndexOf(value)str.lastlndexOf(value, int fromIndex)
注意:lastIndexOf() 方法的查找策略是从右往左查找,如果不指定起始索引,则默认从字符串的末尾开始查找。
例 :编写一个简单的 Java 程序,演示 lastIndexOf() 方法查找字符串的用法,并输出结果。代码如下:
public static void main(String[] args) {
String words="today,monday,Sunday";
System.out.println("原始字符串是'"+words+"'");
System.out.println("lastIndexOf(\"day\")结果:"+words.lastIndexOf("day"));
System.out.println("lastIndexOf(\"day\",5)结果:"+words.lastIndexOf("day",5));
System.out.println("lastIndexOf(\"o\")结果:"+words.lastIndexOf("o"));
System.out.println("lastlndexOf(\"o\",6)结果:"+words.lastIndexOf("o",6));
}
运行后的输出结果如下:
原始字符串是'today,monday,Sunday'
lastIndexOf("day")结果:16
lastIndexOf("day",5)结果:2
lastIndexOf("o")结果:7
lastlndexOf("o",6)结果:1
根据索引查找
String 类的 charAt() 方法可以在字符串内根据指定的索引查找字符,该方法的语法形式如下:
字符串名.charAt(索引值)
提示:字符串本质上是字符数组,因此它也有索引,索引从零开始。
charAt() 方法的使用示例如下:
String words = "today,monday,sunday";
System.out.println(words.charAt(0)); // 结果:t
System.out.println(words.charAt(1)); // 结果:o
System.out.println(words.charAt(8)); // 结果:n
StringBuffer类详解
在 Java 中,除了通过 String 类创建和处理字符串之外,还可以使用 StringBuffer 类来处理字符串。StringBuffer 类可以比 String 类更高效地处理字符串。
因为 StringBuffer 类是可变字符串类,创建 StringBuffer 类的对象后可以随意修改字符串的内容。每个 StringBuffer 类的对象都能够存储指定容量的字符串,如果字符串的长度超过了 StringBuffer 类对象的容量,则该对象的容量会自动扩大。
创建 StringBuffer 类
StringBuffer 类提供了 3 个构造方法来创建一个字符串,如下所示:
- StringBuffer() 构造一个空的字符串缓冲区,并且初始化为 16 个字符的容量。
- StringBuffer(int length) 创建一个空的字符串缓冲区,并且初始化为指定长度 length 的容量。
- StringBuffer(String str) 创建一个字符串缓冲区,并将其内容初始化为指定的字符串内容 str,字符串缓冲区的初始容量为 16 加上字符串 str 的长度。
使用 StringBuffer 类的构造函数的示例如下:
// 定义一个空的字符串缓冲区,含有16个字符的容量
StringBuffer str1 = new StringBuffer();
// 定义一个含有10个字符容量的字符串缓冲区
StringBuffer str2 = new StringBuffer(10);
// 定义一个含有(16+4)的字符串缓冲区,"青春无悔"为4个字符
StringBuffer str3 = new StringBuffer("青春无悔");
/*
*输出字符串的容量大小
*capacity()方法返回字符串的容量大小
*/
System.out.println(str1.capacity()); // 输出 16
System.out.println(str2.capacity()); // 输出 10
System.out.println(str3.capacity()); // 输出 20
上述代码声明了 3 个 StringBuffer 对象 str1、str2 和 str3,并分别对其进行初始化。str1.capacity() 用于查看 str1 的容量,接着以同样的方式对 str2 和 str3 进行容量查看的操作。
追加字符串
StringBuffer 类的 append() 方法用于向原有 StringBuffer 对象中追加字符串。该方法的语法格式如下:
StringBuffer 对象.append(String str)
该方法的作用是追加内容到当前 StringBuffer 对象的末尾,类似于字符串的连接。调用该方法以后,StringBuffer 对象的内容也发生了改变,例如:
StringBuffer buffer = new StringBuffer("hello,"); // 创建一个 StringBuffer 对象
String str = "World!";buffer.append(str); // 向 StringBuffer 对象追加 str 字符串
System.out.println(buffer.substring(0)); // 输出:Hello,World!
替换字符
StringBuffer 类的 setCharAt() 方法用于在字符串的指定索引位置替换一个字符。该方法的语法格式如下:
StringBuffer 对象.setCharAt(int index, char ch);
该方法的作用是修改对象中索引值为 index 位置的字符为新的字符 ch,例如:
StringBuffer sb = new StringBuffer("hello");
sb.setCharAt(1,'E');System.out.println(sb); // 输出:hEllosb.setCharAt(0,'H');
System.out.println(sb); // 输出:HEllosb.setCharAt(2,'p');
System.out.println(sb); // 输出:HEplo
反转字符串
StringBuffer 类中的 reverse() 方法用于将字符串序列用其反转的形式取代。该方法的语法格式如下:
StringBuffer 对象.reverse();
使用 StringBuffer 类中的 reverse() 方法对字符串进行反转的示例如下:
StringBuffer sb = new StringBuffer("java");
sb.reverse();
System.out.println(sb); // 输出:avaj
删除字符串
StringBuffer 类提供了 deleteCharAt() 和 delete() 两个删除字符串的方法。
deleteCharAt() 方法
deleteCharAt() 方法用于移除序列中指定位置的字符,该方法的语法格式如下:
StringBuffer 对象.deleteCharAt(int index);
deleteCharAt() 方法的作用是删除指定位置的字符,然后将剩余的内容形成一个新的字符串。例如:
StringBuffer sb = new StringBuffer("She");sb.deleteCharAt(2);System.out.println(sb); // 输出:Se
执行该段代码,将字符串 sb 中索引值为 2 的字符删除,剩余的内容组成一个新的字符串,因此对象 sb 的值为 Se。
delete() 方法
delete() 方法用于移除序列中子字符串的字符,该方法的语法格式如下:
StringBuffer 对象.delete(int start,int end);
其中,start 表示要删除字符的起始索引值(包括索引值所对应的字符),end 表示要删除字符串的结束索引值(不包括索引值所对应的字符)。该方法的作用是删除指定区域以内的所有字符,例如:
StringBuffer sb = new StringBuffer("hello jack");
sb.delete(2,5);System.out.println(sb); // 输出:he jack
sb.delete(2,5);System.out.println(sb); // 输出:heck
执行该段代码,将字符串“hello jack”索引值为 2(包括)到索引值为 5(不包括)之间的所有字符删除,因此输出的新的字符串的值为“he jack”。
String、StringBuffer和StringBuilder类的区别
在 Java 中字符串属于对象,Java 提供了 String 类来创建和操作字符串。String 类是不可变类,即一旦一个 String 对象被创建以后,包含在这个对象中的字符序列是不可改变的,直至这个对象被销毁。
Java 提供了两个可变字符串类 StringBuffer 和 StringBuilder,中文翻译为“字符串缓冲区”。
StringBuilder 类是 JDK 1.5 新增的类,它也代表可变字符串对象。实际上,StringBuilder 和 StringBuffer 功能基本相似,方法也差不多。不同的是,StringBuffer 是线程安全的,而 StringBuilder 则没有实现线程安全功能,所以性能略高。因此在通常情况下,如果需要创建一个内容可变的字符串对象,则应该优先考虑使用 StringBuilder 类。
StringBuffer、StringBuilder、String 中都实现了 CharSequence 接口。CharSequence 是一个定义字符串操作的接口,它只包括 length()、charAt(int index)、subSequence(int start, int end) 这几个 API。
StringBuffer、StringBuilder、String 对 CharSequence 接口的实现过程不一样,如下图 所示:
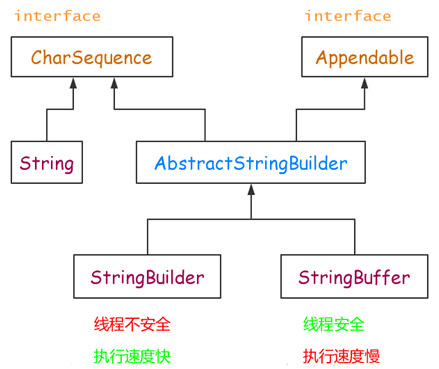
可见,String 直接实现了 CharSequence 接口,StringBuilder 和 StringBuffer 都是可变的字符序列,它们都继承于 AbstractStringBuilder,实现了 CharSequence 接口。
总结
String 是 Java 中基础且重要的类,被声明为 final class,是不可变字符串。因为它的不可变性,所以拼接字符串时候会产生很多无用的中间对象,如果频繁的进行这样的操作对性能有所影响。
StringBuffer 就是为了解决大量拼接字符串时产生很多中间对象问题而提供的一个类。它提供了 append 和 add 方法,可以将字符串添加到已有序列的末尾或指定位置,它的本质是一个线程安全的可修改的字符序列。
在很多情况下我们的字符串拼接操作不需要线程安全,所以 StringBuilder 登场了。StringBuilder 是 JDK1.5 发布的,它和 StringBuffer 本质上没什么区别,就是去掉了保证线程安全的那部分,减少了开销。
线程安全:
StringBuffer:线程安全
StringBuilder:线程不安全
速度:
一般情况下,速度从快到慢为 StringBuilder > StringBuffer > String,当然这是相对的,不是绝对的。
使用环境:
操作少量的数据使用 String。
单线程操作大量数据使用 StringBuilder。
多线程操作大量数据使用 StringBuffer。
正则表达式详解
本节了解即可
正则表达式(Regular Expression)又称正规表示法、常规表示法,在代码中常简写为 regex、regexp 或 RE,它是计算机科学的一个概念。
正则表达式是一个强大的字符串处理工具,可以对字符串进行查找、提取、分割、替换等操作,是一种可以用于模式匹配和替换的规范。一个正则表达式就是由普通的字符(如字符 a~z)以及特殊字符(元字符)组成的文字模式,它用以描述在查找文字主体时待匹配的一个或多个字符串。
String 类里也提供了如下几个特殊的方法。
- boolean matches(String regex):判断该字符串是否匹配指定的正则表达式。
- String replaceAll(String regex, String replacement):将该字符串中所有匹配 regex 的子串替换成 replacement。
- String replaceFirst(String regex, String replacement):将该字符串中第一个匹配 regex 的子串替换成 replacement。
- String[] split(String regex):以 regex 作为分隔符,把该字符串分割成多个子串。
上面这些特殊的方法都依赖于 Java 提供的正则表达式支持,除此之外,Java 还提供了 Pattern 和 Matcher 两个类专门用于提供正则表达式支持。
很多人都会觉得正则表达式是一个非常神奇、高级的知识,其实正则表达式是一种非常简单而且非常实用的工具。正则表达式是一个用于匹配字符串的模板。实际上,任意字符串都可以当成正则表达式使用。例如“abc”,它也是一个正则表达式,只是它只能匹配“abc”字符串。
如果正则表达式仅能匹配“abc”这样的字符串,那么正则表达式也就不值得学习了。正则表达式作为一个用于匹配字符串的模板,将某个字符模式与所搜索的字符串进行匹配。本文简单了解一下如何使用正则表达式来操作字符串。
正则表达式支持字符
创建正则表达式就是创建一个特殊的字符串。正则表达式所支持的合法字符如表所示。
| 字符 | 解释 |
|---|---|
| X | 字符x(x 可代表任何合法的字符) |
| \0mnn | 八进制数 0mnn 所表示的字符 |
| \xhh | 十六进制值 0xhh 所表示的字符 |
| \uhhhh | 十六进制值 0xhhhh 所表示的 Unicode 字符 |
| \t | 制表符(“\u0009”) |
| \n | 新行(换行)符(‘\u000A’) |
| \r | 回车符(‘\u000D’) |
| \f | 换页符(‘\u000C’) |
| \a | 报警(bell)符(‘\u0007’) |
| \e | Escape 符(‘\u001B’) |
| \cx | x 对应的的控制符。例如,\cM匹配 Ctrl-M。x 值必须为 A~Z 或 a~z 之一。 |
除此之外,正则表达式中有一些特殊字符,这些特殊字符在正则表达式中有其特殊的用途,比如前面介绍的反斜线\。
如果需要匹配这些特殊字符,就必须首先将这些字符转义,也就是在前面添加一个反斜线\。正则表达式中的特殊字符如表所示。
| 特殊字符 | 说明 |
|---|---|
| $ | 匹配一行的结尾。要匹配 ` |
| ^ | 匹配一行的开头。要匹配 ^ 字符本身,请使用\^ |
| () | 标记子表达式的开始和结束位置。要匹配这些字符,请使用\(和\) |
| [] | 用于确定中括号表达式的开始和结束位置。要匹配这些字符,请使用\[和\] |
| {} | 用于标记前面子表达式的出现频度。要匹配这些字符,请使用\{和\} |
| * | 指定前面子表达式可以出现零次或多次。要匹配 * 字符本身,请使用\* |
| + | 指定前面子表达式可以出现一次或多次。要匹配 + 字符本身,请使用\+ |
| ? | 指定前面子表达式可以出现零次或一次。要匹配 ?字符本身,请使用\? |
| . | 匹配除换行符\n之外的任何单字符。要匹配.字符本身,请使用\. |
| \ | 用于转义下一个字符,或指定八进制、十六进制字符。如果需匹配\字符,请用\\ |
| | | 指定两项之间任选一项。如果要匹配丨字符本身,请使用| |
将上面多个字符拼起来,就可以创建一个正则表达式。例如:
"\u0041\\" // 匹配 A
"\u0061\t" // 匹配a<制表符>
"\?\[" // 匹配?[
注意:可能大家会觉得第一个正则表达式中怎么有那么多反斜杠?这是由于 Java 字符串中反斜杠本身需要转义,因此两个反斜杠(\)实际上相当于一个(前一个用于转义)。
上面的正则表达式依然只能匹配单个字符,这是因为还未在正则表达式中使用“通配符”,“通配符”是可以匹配多个字符的特殊字符。正则表达式中的“通配符”远远超出了普通通配符的功能,它被称为预定义字符,正则表达式支持如表 3 所示的预定义字符。
| 预定义字符 | 说明 |
|---|---|
| . | 可以匹配任何字符 |
| \d | 匹配 0~9 的所有数字 |
| \D | 匹配非数字 |
| \s | 匹配所有的空白字符,包括空格、制表符、回车符、换页符、换行符等 |
| \S | 匹配所有的非空白字符 |
| \w | 匹配所有的单词字符,包括 0~9 所有数字、26 个英文字母和下画线_ |
| \W | 匹配所有的非单词字符 |
上面的 7 个预定义字符其实很容易记忆,其中:
- d 是 digit 的意思,代表数字。
- s 是 space 的意思,代表空白。
- w 是 word 的意思,代表单词。
- d、s、w 的大写形式恰好匹配与之相反的字符。
有了上面的预定义字符后,接下来就可以创建更强大的正则表达式了。例如:
c\wt // 可以匹配cat、cbt、cct、cOt、c9t等一批字符串
\d\d\d-\d\d\d-\d\d\d\d // 匹配如 000-000-0000 形式的电话号码
在一些特殊情况下,例如,若只想匹配 a~f 的字母,或者匹配除 ab 之外的所有小写字母,或者匹配中文字符,上面这些预定义字符就无能为力了,此时就需要使用方括号表达式,方括号表达式有如表 4 所示的几种形式。
| 方括号表达式 | 说明 |
|---|---|
| 表示枚举 | 例如[abc]表示 a、b、c 其中任意一个字符;[gz]表示 g、z 其中任意一个字符 |
| 表示范围:- | 例如[a-f]表示 a~f 范围内的任意字符;[\\u0041-\\u0056]表示十六进制字符 \u0041 到 \u0056 范围的字符。范围可以和枚举结合使用,如[a-cx-z],表示 ac、xz 范围内的任意字符 |
| 表示求否:^ | 例如[^abc]表示非 a、b、c 的任意字符;[^a-f]表示不是 a~f 范围内的任意字符 |
| 表示“与”运算:&& | 例如 [a-z&&[def]]是 a~z 和 [def] 的交集,表示 d、e f[a-z&&^bc]]是 a~z 范围内的所有字符,除 b 和 c 之外 [ad-z] [a-z&&[m-p]]是 a~z 范围内的所有字符,除 m~p 范围之外的字符 |
| 表示“并”运算 | 并运算与前面的枚举类似。例如[a-d[m-p]]表示 [a-dm-p] |
方括号表达式比前面的预定义字符灵活多了,几乎可以匹配任何字符。例如,若需要匹配所有的中文字符,就可以利用 [\u0041-\u0056] 形式——因为所有中文字符的 Unicode 值是连续的,只要找出所有中文字符中最小、最大的 Unicode 值,就可以利用上面形式来匹配所有的中文字符。
正则表达式还支持圆括号,用于将多个表达式组成一个子表达式,圆括号中可以使用或运算符|。例如,正则表达式“((public)|(protected)|(private))”用于匹配 Java 的三个访问控制符其中之一。
除此之外,Java 正则表达式还支持如表 5 所示的几个边界匹配符。
| 边界匹配符 | 说明 |
|---|---|
| ^ | 行的开头 |
| $ | 行的结尾 |
| \b | 单词的边界 |
| \B | 非单词的边界 |
| \A | 输入的开头 |
| \G | 前一个匹配的结尾 |
| \Z | 输入的结尾,仅用于最后的结束符 |
| \z | 输入的结尾 |
前面例子中需要建立一个匹配 000-000-0000 形式的电话号码时,使用了 \d\d\d-\d\d\d-\d\d\d\d 正则表达式,这看起来比较烦琐。实际上,正则表达式还提供了数量标识符,正则表达式支持的数量标识符有如下几种模式。
- Greedy(贪婪模式):数量表示符默认采用贪婪模式,除非另有表示。贪婪模式的表达式会一直匹配下去,直到无法匹配为止。如果你发现表达式匹配的结果与预期的不符,很有可能是因为你以为表达式只会匹配前面几个字符,而实际上它是贪婪模式,所以会一直匹配下去。
- Reluctant(勉强模式):用问号后缀(?)表示,它只会匹配最少的字符。也称为最小匹配模式。
- Possessive(占有模式):用加号后缀(+)表示,目前只有 Java 支持占有模式,通常比较少用。
三种模式的数量表示符如表 6 所示。
| 贪婪模式 | 勉强模式 | 占用模式 | 说明 |
|---|---|---|---|
| X? | X?? | X?+ | X表达式出现零次或一次 |
| X* | X*? | X*+ | X表达式出现零次或多次 |
| X+ | X+? | X++ | X表达式出现一次或多次 |
| X{n} | X{n}? | X{n}+ | X表达式出现 n 次 |
| X{n,} | X{n,}? | X{n,}+ | X表达式最少出现 n 次 |
| X{n,m} | X{n,m}? | X{n,m}+ | X表达式最少出现 n 次,最多出现 m 次 |
关于贪婪模式和勉强模式的对比,看如下代码:
String str = "hello,java!";
// 贪婪模式的正则表达式
System.out.println(str.replaceFirst("\\w*" , "■")); //输出■,java!
// 勉强模式的正则表达式
System.out.println(str.replaceFirst("\\w*?" , "■"")); //输出■hello, java!
当从“hello java!”字符串中查找匹配\\w*子串时,因为\w*使用了贪婪模式,数量表示符*会一直匹配下去,所以该字符串前面的所有单词字符都被它匹配到,直到遇到空格,所以替换后的效果是“■,Java!”;如果使用勉强模式,数量表示符*会尽量匹配最少字符,即匹配 0 个字符,所以替换后的结果是“■hello,java!”。
Pattern类和Matcher类的使用
java.util.regex 是一个用正则表达式所订制的模式来对字符串进行匹配工作的类库包。它包括两个类:Pattern 和 Matcher。
Pattern 对象是正则表达式编译后在内存中的表示形式,因此,正则表达式字符串必须先被编译为 Pattern 对象,然后再利用该 Pattern 对象创建对应的 Matcher 对象。执行匹配所涉及的状态保留在 Matcher 对象中,多个 Matcher 对象可共享同一个 Pattern 对象。
因此,典型的调用顺序如下:
// 将一个字符串编译成 Pattern 对象
Pattern p = Pattern.compile("a*b");
// 使用 Pattern 对象创建 Matcher 对象
Matcher m = p.matcher("aaaaab");
boolean b = m.matches(); // 返回 true
上面定义的 Pattern 对象可以多次重复使用。如果某个正则表达式仅需一次使用,则可直接使用 Pattern 类的静态 matches() 方法,此方法自动把指定字符串编译成匿名的 Pattern 对象,并执行匹配,如下所示。
boolean b = Pattern.matches ("a*b","aaaaab"); // 返回 true
上面语句等效于前面的三条语句。但采用这种语句每次都需要重新编译新的 Pattern 对象,不能重复利用已编译的 Pattern 对象,所以效率不高。Pattern 是不可变类,可供多个并发线程安全使用。
Matcher 类提供了几个常用方法,如表所示。
| 名称 | 说明 |
|---|---|
| find() | 返回目标字符串中是否包含与 Pattern 匹配的子串 |
| group() | 返回上一次与 Pattern 匹配的子串 |
| start() | 返回上一次与 Pattern 匹配的子串在目标字符串中的开始位置 |
| end() | 返回上一次与 Pattern 匹配的子串在目标字符串中的结束位置加 1 |
| lookingAt() | 返回目标字符串前面部分与 Pattern 是否匹配 |
| matches() | 返回整个目标字符串与 Pattern 是否匹配 |
| reset() | 将现有的 Matcher 对象应用于一个新的字符序列。 |
在 Pattern、Matcher 类的介绍中经常会看到一个 CharSequence 接口,该接口代表一个字符序列,其中 CharBuffer、String、StringBuffer、StringBuilder 都是它的实现类。简单地说,CharSequence 代表一个各种表示形式的字符串。
通过 Matcher 类的 find() 和 group() 方法可以从目标字符串中依次取出特定子串(匹配正则表达式的子串),例如互联网的网络爬虫,它们可以自动从网页中识别出所有的电话号码。下面程序示范了如何从大段的字符串中找出电话号码。
public class FindGroup {
public static void main(String[] args) {
// 使用字符串模拟从网络上得到的网页源码
String str = "我想找一套适合自己的JAVA教程,尽快联系我13500006666" + "交朋友,电话号码是13611125565" + "出售二手电脑,联系方式15899903312";
// 创建一个Pattern对象,并用它建立一个Matcher对象
// 该正则表达式只抓取13X和15X段的手机号
// 实际要抓取哪些电话号码,只要修改正则表达式即可
Matcher m = Pattern.compile("((13\\d)|(15\\d))\\d{8}").matcher(str);
// 将所有符合正则表达式的子串(电话号码)全部输出
while (m.find()) {
System.out.println(m.group());
}
}
}
运行上面程序,看到如下运行结果:
13500006666
13611125565
15899903312
从上面运行结果可以看出,find() 方法依次查找字符串中与 Pattern 匹配的子串,一旦找到对应的子串,下次调用 find() 方法时将接着向下查找。
提示:通过程序运行结果可以看出,使用正则表达式可以提取网页上的电话号码,也可以提取邮件地址等信息。如果程序再进一步,可以从网页上提取超链接信息,再根据超链接打开其他网页,然后在其他网页上重复这个过程就可以实现简单的网络爬虫了。
find() 方法还可以传入一个 int 类型的参数,带 int 参数的 find() 方法将从该 int 索引处向下搜索。start() 和 end() 方法主要用于确定子串在目标字符串中的位置,如下程序所示。
public class StartEnd {
public static void main(String[] args) {
// 创建一个Pattern对象,并用它建立一个Matcher对象
String regStr = "Java is very easy!";
System.out.println("目标字符串是:" + regStr);
Matcher m = Pattern.compile("\\w+").matcher(regStr);
while (m.find()) {
System.out.println(m.group() + "子串的起始位置:" + m.start() + ",其结束位置:" + m.end());
}
}
}
上面程序使用 find()、group() 方法逐项取出目标字符串中与指定正则表达式匹配的子串,并使用 start()、end() 方法返回子串在目标字符串中的位置。运行上面程序,看到如下运行结果:
目标字符串是:Java is very easy!
Java子串的起始位置:0,其结束位置:4
is子串的起始位置:5,其结束位置:7
very子串的起始位置:8,其结束位置:12
easy子串的起始位置:13,其结束位置:17
matches() 和 lookingAt() 方法有点相似,只是 matches() 方法要求整个字符串和 Pattern 完全匹配时才返回 true,而 lookingAt() 只要字符串以 Pattern 开头就会返回 true。reset() 方法可将现有的 Matcher 对象应用于新的字符序列。看如下例子程序。
public class MatchesTest {
public static void main(String[] args) {
String[] mails = { "[email protected]", "[email protected]", "[email protected]", "[email protected]" };
String mailRegEx = "\\w{3,20}@\\w+\\.(com|org|cn|net|gov)";
Pattern mailPattern = Pattern.compile(mailRegEx);
Matcher matcher = null;
for (String mail : mails) {
if (matcher == null) {
matcher = mailPattern.matcher(mail);
} else {
matcher.reset(mail);
}
String result = mail + (matcher.matches() ? "是" : "不是") + "一个有效的邮件地址!";
System.out.println(result);
}
}
}
上面程序创建了一个邮件地址的 Pattern,接着用这个 Pattern 与多个邮件地址进行匹配。当程序中的 Matcher 为 null 时,程序调用 matcher() 方法来创建一个 Matcher 对象,一旦 Matcher 对象被创建,程序就调用 Matcher 的 reset() 方法将该 Matcher 应用于新的字符序列。
从某个角度来看,Matcher 的 matches()、lookingAt() 和 String 类的 equals() 有点相似。区别是 String 类的 equals() 都是与字符串进行比较,而 Matcher 的 matches() 和 lookingAt() 则是与正则表达式进行匹配。
事实上,String 类里也提供了 matches() 方法,该方法返回该字符串是否匹配指定的正则表达式。例如:
"[email protected]".matches("\\w{3,20}@\\w+\\.(com|org|cn|net|gov)"); // 返回 true
除此之外,还可以利用正则表达式对目标字符串进行分割、查找、替换等操作,看如下例子程序。
public class ReplaceTest {
public static void main(String[] args) {
String[] msgs = { "Java has regular expressions in 1.4", "regular expressions now expressing in Java",
"Java represses oracular expressions" };
Pattern p = Pattern.compile("re\\w*");
Matcher matcher = null;
for (int i = 0; i < msgs.length; i++) {
if (matcher == null) {
matcher = p.matcher(msgs[i]);
} else {
matcher.reset(msgs[i]);
}
System.out.println(matcher.replaceAll("哈哈:)"));
}
}
}
上面程序使用了 Matcher 类提供的 replaceAll() 把字符串中所有与正则表达式匹配的子串替换成“哈哈:)”,实际上,Matcher 类还提供了一个 replaceFirst(),该方法只替换第一个匹配的子串。运行上面程序,会看到字符串中所有以“re”开头的单词都会被替换成“哈哈:)”。
实际上,String 类中也提供了 replaceAll()、replaceFirst()、split() 等方法。下面的例子程序直接使用 String 类提供的正则表达式功能来进行替换和分割。
public class StringReg {
public static void main(String[] args) {
String[] msgs = { "Java has regular expressions in 1.4", "regular expressions now expressing in Java",
"Java represses oracular expressions" };
for (String msg : msgs) {
System.out.println(msg.replaceFirst("re\\w*", "哈哈:)"));
System.out.println(Arrays.toString(msg.split(" ")));
}
}
}
上面程序只使用 String 类的 replaceFirst() 和 split() 方法对目标字符串进行了一次替换和分割。运行上面程序,会看到如下所示的输出结果。
Java has 哈哈:) expressions in 1.4
[Java, has, regular, expressions, in, 1.4]
哈哈:) expressions now expressing in Java
[regular, expressions, now, expressing, in, Java]
Java 哈哈:) oracular expressions
[Java, represses, oracular, expressions]
正则表达式是一个功能非常灵活的文本处理工具,增加了正则表达式支持后的 Java,可以不再使用 StringTokenizer 类(也是一个处理字符串的工具,但功能远不如正则表达式强大)即可进行复杂的字符串处理。
数字处理
Math类的常用方法
Java 中的 +、-、*、/ 和 % 等基本算术运算符不能进行更复杂的数学运算,例如,三角函数、对数运算、指数运算等。于是 Java 提供了 Math 工具类来完成这些复杂的运算。
在 Java 中 Math 类封装了常用的数学运算,提供了基本的数学操作,如指数、对数、平方根和三角函数等。Math 类位于 java.lang 包,它的构造方法是 private 的,因此无法创建 Math 类的对象,并且 Math 类中的所有方法都是类方法,可以直接通过类名来调用它们。
下面详细介绍该类的常量及数学处理方法。
静态常量
Math 类中包含 E 和 PI 两个静态常量,正如它们名字所暗示的,它们的值分别等于 e(自然对数)和 π(圆周率)。
例:调用 Math 类的 E 和 PI 两个常量,并将结果输出。代码如下:
System.out.println("E 常量的值:" + Math.E);
System.out.println("PI 常量的值:" + Math.PI);
执行上述代码,输出结果如下:
E 常量的值:2.718281828459045
PI 常量的值:3.141592653589793
求最大值、最小值和绝对值
在程序中常见的就是求最大值、最小值和绝对值问题,如果使用 Math 类提供的方法可以很容易实现。这些方法的说明如表 1 所示。
| 方法 | 说明 |
|---|---|
| static int abs(int a) | 返回 a 的绝对值 |
| static long abs(long a) | 返回 a 的绝对值 |
| static float abs(float a) | 返回 a 的绝对值 |
| static double abs(double a) | 返回 a 的绝对值 |
| static int max(int x,int y) | 返回 x 和 y 中的最大值 |
| static double max(double x,double y) | 返回 x 和 y 中的最大值 |
| static long max(long x,long y) | 返回 x 和 y 中的最大值 |
| static float max(float x,float y) | 返回 x 和 y 中的最大值 |
| static int min(int x,int y) | 返回 x 和 y 中的最小值 |
| static long min(long x,long y) | 返回 x 和 y 中的最小值 |
| static double min(double x,double y) | 返回 x 和 y 中的最小值 |
| static float min(float x,float y) | 返回 x 和 y 中的最小值 |
例 :求 10 和 20 的较大值、15.6 和 15 的较小值、-12 的绝对值,代码如下:
public class Test02 {
public static void main(String[] args) {
System.out.println("10 和 20 的较大值:" + Math.max(10, 20));
System.out.println("15.6 和 15 的较小值:" + Math.min(15.6, 15));
System.out.println("-12 的绝对值:" + Math.abs(-12));
}
}
该程序的运行结果如下:
10和20的较大值:20
15.6和15的较小值:15.0
-12的绝对值:12
求整运算
Math 类的求整方法有很多,详细说明如表 2 所示。
| 方法 | 说明 |
|---|---|
| static double ceil(double a) | 返回大于或等于 a 的最小整数 |
| static double floor(double a) | 返回小于或等于 a 的最大整数 |
| static double rint(double a) | 返回最接近 a 的整数值,如果有两个同样接近的整数,则结果取偶数 |
| static int round(float a) | 将参数加上 1/2 后返回与参数最近的整数 |
| static long round(double a) | 将参数加上 1/2 后返回与参数最近的整数,然后强制转换为长整型 |
例:下面的实例演示了 Math 类中取整函数方法的应用:
import java.util.Scanner;
public class Test03 {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
System.outprintln("请输入一个数字:");
double num = input.nextDouble();
System.out.println("大于或等于 "+ num +" 的最小整数:" + Math.ceil(num));
System.out.println("小于或等于 "+ num +" 的最大整数:" + Math.floor(num));
System.out.println("将 "+ num +" 加上 0.5 之后最接近的整数:" + Math.round(num));
System.out.println("最接近 "+num+" 的整数:" + Math.rint(num));
}
}
执行结果如下:
请输入一个数字:
99.01
大于或等于 99.01 的最小整数:100.0
小于或等于 99.01 的最大整数:99.0
将 99.01 加上 0.5 之后最接近的整数:100
最接近 99.01 的整数:99.0
三角函数运算
Math 类中包含的三角函数方法及其说明如表所示。
| 方法 | 说明 |
|---|---|
| static double sin(double a) | 返回角的三角正弦值,参数以孤度为单位 |
| static double cos(double a) | 返回角的三角余弦值,参数以孤度为单位 |
| static double asin(double a) | 返回一个值的反正弦值,参数域在 [-1,1],值域在 [-PI/2,PI/2] |
| static double acos(double a) | 返回一个值的反余弦值,参数域在 [-1,1],值域在 [0.0,PI] |
| static double tan(double a) | 返回角的三角正切值,参数以弧度为单位 |
| static double atan(double a) | 返回一个值的反正切值,值域在 [-PI/2,PI/2] |
| static double toDegrees(double angrad) | 将用孤度表示的角转换为近似相等的用角度表示的角 |
| staticdouble toRadians(double angdeg) | 将用角度表示的角转换为近似相等的用弧度表示的角 |
在表 3 中,每个方法的参数和返回值都是 double 类型,参数以弧度代替角度来实现,其中 1 度等于 π/180 弧度,因此平角就是 π 弧度。
例:计算 90 度的正弦值、0 度的余弦值、1 的反正切值、120 度的弧度值,代码如下:
public class Test04 {
public static void main(String[] args) {
System.out.println{"90 度的正弦值:" + Math.sin(Math.PI/2));
System.out.println("0 度的余弦值:" + Math.cos(0));
System.out.println("1 的反正切值:" + Math.atan(l));
System.out.println("120 度的弧度值:" + Math.toRadians(120.0));
}
}
在上述代码中,因为 Math.sin() 中的参数的单位是弧度,而 90 度表示的是角度,因此需要将 90 度转换为弧度,即 Math.PI/180*90,故转换后的弧度为 Math.PI/2,然后调用 Math 类中的 sin() 方法计算其正弦值。
该程序的运行结果如下:
90 度的正弦值:1.0
0 的余弦值:1.0
1 的反正切值:0.7853981633974483
120 度的弧度值:2.0943951023931953
指数运算
指数的运算包括求方根、取对数及其求 n 次方的运算。在 Math 类中定义的指数运算方法及其说明如表 4 所示。
| 方法 | 说明 |
|---|---|
| static double exp(double a) | 返回 e 的 a 次幂 |
| static double pow(double a,double b) | 返回以 a 为底数,以 b 为指数的幂值 |
| static double sqrt(double a) | 返回 a 的平方根 |
| static double cbrt(double a) | 返回 a 的立方根 |
| static double log(double a) | 返回 a 的自然对数,即 lna 的值 |
| static double log10(double a) | 返回以 10 为底 a 的对数 |
例:使用 Math 类中的方法实现指数的运算,main() 方法中的代码如下:
public class Test05 {
public static void main(String[] args) {
System.out.println("4 的立方值:" + Math.pow(4, 3));
System.out.println("16 的平方根:" + Math.sqrt(16));
System.out.println("10 为底 2 的对数:" + Math.log1O(2));
}
}
该程序的运行结果如下:
4 的立方值:64.0
16 的平方根:4.0
10 为底 2 的对数:0.3010299956639812
生成随机数
在 Java 中要生成一个指定范围之内的随机数字有两种方法:一种是调用 Math 类的 random() 方法,一种是使用 Random 类。
Random 类提供了丰富的随机数生成方法,可以产生 boolean、int、long、float、byte 数组以及 double 类型的随机数,这是它与 random() 方法最大的不同之处。random() 方法只能产生 double 类型的 0~1 的随机数。
Random 类位于 java.util 包中,该类常用的有如下两个构造方法。
- Random():该构造方法使用一个和当前系统时间对应的数字作为种子数,然后使用这个种子数构造 Random 对象。
- Random(long seed):使用单个 long 类型的参数创建一个新的随机数生成器。
Random 类提供的所有方法生成的随机数字都是均匀分布的,也就是说区间内部的数字生成的概率是均等的,在表 1 中列出了 Random 类中常用的方法。
| 方法 | 说明 |
|---|---|
| boolean nextBoolean() | 生成一个随机的 boolean 值,生成 true 和 false 的值概率相等 |
| double nextDouble() | 生成一个随机的 double 值,数值介于 [0,1.0),含 0 而不包含 1.0 |
| int nextlnt() | 生成一个随机的 int 值,该值介于 int 的区间,也就是 -231~231-1。如果 需要生成指定区间的 int 值,则需要进行一定的数学变换 |
| int nextlnt(int n) | 生成一个随机的 int 值,该值介于 [0,n),包含 0 而不包含 n。如果想生成 指定区间的 int 值,也需要进行一定的数学变换 |
| void setSeed(long seed) | 重新设置 Random 对象中的种子数。设置完种子数以后的 Random 对象 和相同种子数使用 new 关键字创建出的 Random 对象相同 |
| long nextLong() | 返回一个随机长整型数字 |
| boolean nextBoolean() | 返回一个随机布尔型值 |
| float nextFloat() | 返回一个随机浮点型数字 |
| double nextDouble() | 返回一个随机双精度值 |
例 :下面编写一个 Java 程序,演示如何使用 Random 类提供的方法来生成随机数。具体代码如下:
import java.util.Random;
public class Test06 {
public static void main(String[] args) {
Random r = new Random();
double d1 = r.nextDouble(); // 生成[0,1.0]区间的小数
double d2 = r.nextDouble() * 7; // 生成[0,7.0]区间的小数
int i1 = r.nextInt(10); // 生成[0,10]区间的整数
int i2 = r.nextInt(18) - 3; // 生成[-3,15]区间的整数
long l1 = r.nextLong(); // 生成一个随机长整型值
boolean b1 = r.nextBoolean(); // 生成一个随机布尔型值
float f1 = r.nextFloat(); // 生成一个随机浮点型值
System.out.println("生成的[0,1.0]区间的小数是:" + d1);
System.out.println("生成的[0,7.0]区间的小数是:" + d2);
System.out.println("生成的[0,10]区间的整数是:" + i1);
System.out.println("生成的[-3,15]区间的整数是:" + i2);
System.out.println("生成一个随机长整型值:" + l1);
System.out.println("生成一个随机布尔型值:" + b1);
System.out.println("生成一个随机浮点型值:" + f1);
System.out.print("下期七星彩开奖号码预测:");
for (int i = 1; i < 8; i++) {
int num = r.nextInt(9); // 生成[0,9]区间的整数
System.out.print(num);
}
}
}
本实例每次运行时结果都不相同,这就实现了随机产生数据的功能。该程序的运行结果如下:
生成的[0,1.0]区间的小数是:0.8773165855918825
生成的[0,7.0]区间的小数是:6.407083074782282
生成的[0,10]区间的整数是:5
生成的[-3,15]区间的整数是:4
生成一个随机长整型值:-8462847591661221914
生成一个随机布尔型值:false
生成一个随机浮点型值:0.6397003
下期七星彩开奖号码预测:0227168
例:Math 类的 random() 方法没有参数,它默认会返回大于等于 0.0、小于 1.0 的 double 类型随机数,即 0<=随机数<1.0。对 random() 方法返回的数字稍加处理,即可实现产生任意范围随机数的功能。
下面使用 random() 方法实现随机生成一个 2~100 偶数的功能。具体代码如下:
public class Test07 {
public static void main(String[] args) {
int min = 2; // 定义随机数的最小值
int max = 102; // 定义随机数的最大值
// 产生一个2~100的数
int s = (int) min + (int) (Math.random() * (max - min));
if (s % 2 == 0) {
// 如果是偶数就输出
System.out.println("随机数是:" + s);
} else {
// 如果是奇数就加1后输出
System.out.println("随机数是:" + (s + 1));
}
}
}
由于 m+(int)(Math.random()n) 语句可以获取 m~m+n 的随机数,所以 2+(int)(Math. random()(102-2)) 表达式可以求出 2~100 的随机数。在产生这个区间的随机数后还需要判断是否为偶数,这里使用了对 2 取余数,如果余数不是零,说明随机数是奇数,此时将随机数加 1 后再输出。
该程序的运行结果如下:
随机数是:20
数字格式化
数字的格式在解决实际问题时使用非常普遍,这时可以使用 DedmalFormat 类对结果进行格式化处理。例如,将小数位统一成 2 位,不足 2 位的以 0 补齐。
DecimalFormat 是 NumberFormat 的一个子类,用于格式化十进制数字。DecimalFormat 类包含一个模式和一组符号,常用符号的说明如表 1 所示。
| 符号 | 说明 |
|---|---|
| 0 | 显示数字,如果位数不够则补 0 |
| # | 显示数字,如果位数不够不发生变化 |
| . | 小数分隔符 |
| - | 减号 |
| , | 组分隔符 |
| E | 分隔科学记数法中的尾数和小数 |
| % | 前缀或后缀,乘以 100 后作为百分比显示 |
| ? | 乘以 1000 后作为千进制货币符显示。用货币符号代替。如果双写,用国际货币符号代替; 如果出现在一个模式中,用货币十进制分隔符代替十进制分隔符 |
例:下面编写一个 Java 程序,演示如何使用 DecimalFormat 类将数字转换成各种格式,实现代码如下。
import java.text.DecimalFormat;
import java.util.Scanner;
public class Test08 {
public static void main(String[] args) {
// 实例化DecimalFormat类的对象,并指定格式
DecimalFormat df1 = new DecimalFormat("0.0");
DecimalFormat df2 = new DecimalFormat("#.#");
DecimalFormat df3 = new DecimalFormat("000.000");
DecimalFormat df4 = new DecimalFormat("###.###");
Scanner scan = new Scanner(System.in);
System.out.print("请输入一个float类型的数字:");
float f = scan.nextFloat();
// 对输入的数字应用格式,并输出结果
System.out.println("0.0 格式:" + df1.format(f));
System.out.println("#.# 格式:" + df2.format(f));
System.out.println("000.000 格式:" + df3.format(f));
System.out.println("###.### 格式:" + df4.format(f));
}
}
执行上述代码,输出结果如下所示:
请输入一个float类型的数字:5487.45697
0.0 格式:5487.5
#.# 格式:5487.5
000.000 格式:5487.457
###.### 格式:5487.457
请输入一个float类型的数字:5.0
0.0 格式:5.0
#.# 格式:5
000.000 格式:005.000
###.### 格式:5
大数字运算
在 Java 中提供了用于大数字运算的类,即 java.math.BigInteger 类和 java.math.BigDecimal 类。这两个类用于高精度计算,其中 BigInteger 类是针对整型大数字的处理类,而 BigDecimal 类是针对大小数的处理类。
BigInteger 类
如果要存储比 Integer 更大的数字,Integer 数据类型就无能为力了。因此,Java 中提供 BigInteger 类来处理更大的数字。
BigInteger 类型的数字范围较 Integer 类型的数字范围要大得多。BigInteger 支持任意精度的整数,也就是说在运算中 BigInteger 类型可以准确地表示任何大小的整数值。
除了基本的加、减、乘、除操作之外,BigInteger 类还封装了很多操作,像求绝对值、相反数、最大公约数以及判断是否为质数等。
要使用 BigInteger 类,首先要创建一个 BigInteger 对象。BigInteger 类提供了很多种构造方法,其中最直接的一种是参数以字符串形式代表要处理的数字。这个方法语法格式如下:
BigInteger(String val)
这里的 val 是数字十进制的字符串。例如,要将数字 5 转换为 BigInteger 对象,语句如下:
BigInteger bi = new BigInteger("5")
注意:这里数字 5 的双引号是必需的,因为 BigInteger 类构造方法要求参数是字符串类型。
创建 BigInteger 对象之后,便可以调用 BigInteger 类提供的方法进行各种数学运算操作,表 1 列出了 BigInteger 类的常用运算方法。
| 方法名称 | 说明 |
|---|---|
| add(BigInteger val) | 做加法运算 |
| subtract(BigInteger val) | 做减法运算 |
| multiply(BigInteger val) | 做乘法运算 |
| divide(BigInteger val) | 做除法运算 |
| remainder(BigInteger val) | 做取余数运算 |
| divideAndRemainder(BigInteger val) | 做除法运算,返回数组的第一个值为商,第二个值为余数 |
| pow(int exponent) | 做参数的 exponent 次方运算 |
| negate() | 取相反数 |
| shiftLeft(int n) | 将数字左移 n 位,如果 n 为负数,则做右移操作 |
| shiftRight(int n) | 将数字右移 n 位,如果 n 为负数,则做左移操作 |
| and(BigInteger val) | 做与运算 |
| or(BigInteger val) | 做或运算 |
| compareTo(BigInteger val) | 做数字的比较运算 |
| equals(Object obj) | 当参数 obj 是 Biglnteger 类型的数字并且数值相等时返回 true, 其他返回 false |
| min(BigInteger val) | 返回较小的数值 |
| max(BigInteger val) | 返回较大的数值 |
BigDecimal 类
BigInteger 和 BigDecimal 都能实现大数字的运算,不同的是 BigDecimal 加入了小数的概念。一般的 float 和 double 类型数据只能用来做科学计算或工程计算,但由于在商业计算中要求数字精度比较高,所以要用到 BigDecimal 类。BigDecimal 类支持任何精度的浮点数,可以用来精确计算货币值。
BigDecimal 常用的构造方法如下。
- BigDecimal(double val):实例化时将双精度型转换为 BigDecimal 类型。
- BigDecimal(String val):实例化时将字符串形式转换为 BigDecimal 类型。
BigDecimal 类的方法可以用来做超大浮点数的运算,像加、减、乘和除等。在所有运算中,除法运算是最复杂的,因为在除不尽的情况下,末位小数的处理方式是需要考虑的。
下面列出了 BigDecimal 类用于实现加、减、乘和除运算的方法。
BigDecimal add(BigDecimal augend) // 加法操作
BigDecimal subtract(BigDecimal subtrahend) // 减法操作
BigDecimal multiply(BigDecimal multiplieand) // 乘法操作
BigDecimal divide(BigDecimal divisor,int scale,int roundingMode ) // 除法操作
其中,divide() 方法的 3 个参数分别表示除数、商的小数点后的位数和近似值处理模式。
表列出了 roundingMode 参数支持的处理模式。
| 模式名称 | 说明 |
|---|---|
| BigDecimal.ROUND_UP | 商的最后一位如果大于 0,则向前进位,正负数都如此 |
| BigDecimal.ROUND_DOWN | 商的最后一位无论是什么数字都省略 |
| BigDecimal.ROUND_CEILING | 商如果是正数,按照 ROUND_UP 模式处理;如果是负数,按照 ROUND_DOWN 模式处理 |
| BigDecimal.ROUND_FLOOR | 与 ROUND_CELING 模式相反,商如果是正数,按照 ROUND_DOWN 模式处理; 如果是负数,按照 ROUND_UP 模式处理 |
| BigDecimal.ROUND_HALF_ DOWN | 对商进行五舍六入操作。如果商最后一位小于等于 5,则做舍弃操作,否则对最后 一位进行进位操作 |
| BigDecimal.ROUND_HALF_UP | 对商进行四舍五入操作。如果商最后一位小于 5,则做舍弃操作,否则对最后一位 进行进位操作 |
| BigDecimal.ROUND_HALF_EVEN | 如果商的倒数第二位是奇数,则按照 ROUND_HALF_UP 处理;如果是偶数,则按 照 ROUND_HALF_DOWN 处理 |
日期&时间处理
在 Java 中获取当前时间,可以使用 java.util.Date 类和 java.util.Calendar 类完成。其中,Date 类主要封装了系统的日期和时间的信息,Calendar 类则会根据系统的日历来解释 Date 对象。
Date 类
Date 类表示系统特定的时间戳,可以精确到毫秒。Date 对象表示时间的默认顺序是星期、月、日、小时、分、秒、年。
构造方法
Date 类有如下两个构造方法。
- Date():此种形式表示分配 Date 对象并初始化此对象,以表示分配它的时间(精确到毫秒),使用该构造方法创建的对象可以获取本地的当前时间。
- Date(long date):此种形式表示从 GMT 时间(格林尼治时间)1970 年 1 月 1 日 0 时 0 分 0 秒开始经过参数 date 指定的毫秒数。
这两个构造方法的使用示例如下:
Date date1 = new Date(); // 调用无参数构造函数
System.out.println(date1.toString()); // 输出:Wed May 18 21:24:40 CST 2016
Date date2 = new Date(60000); // 调用含有一个long类型参数的构造函数
System.out.println(date2); // 输出:Thu Jan 0108:01:00 CST 1970
Date 类的无参数构造方法获取的是系统当前的时间,显示的顺序为星期、月、日、小时、分、秒、年。
Date 类带 long 类型参数的构造方法获取的是距离 GMT 指定毫秒数的时间,60000 毫秒是一分钟,而 GMT(格林尼治标准时间)与 CST(中央标准时间)相差 8 小时,也就是说 1970 年 1 月 1 日 00:00:00 GMT 与 1970 年 1 月 1 日 08:00:00 CST 表示的是同一时间。 因此距离 1970 年 1 月 1 日 00:00:00 CST 一分钟的时间为 1970 年 1 月 1 日 00:01:00 CST,即使用 Date 对象表示为 Thu Jan 01 08:01:00 CST 1970。
常用方法
Date 类提供了许多与日期和事件相关的方法,其中常见的方法如表所示。
| 方法 | 描述 |
|---|---|
| boolean after(Date when) | 判断此日期是否在指定日期之后 |
| boolean before(Date when) | 判断此日期是否在指定日期之前 |
| int compareTo(Date anotherDate) | 比较两个日期的顺序 |
| boolean equals(Object obj) | 比较两个日期的相等性 |
| long getTime() | 返回自 1970 年 1 月 1 日 00:00:00 GMT 以来,此 Date 对象表示的毫秒数 |
| String toString() | 把此 Date 对象转换为以下形式的 String: dow mon dd hh:mm:ss zzz yyyy。 其中 dow 是一周中的某一天(Sun、Mon、Tue、Wed、Thu、Fri 及 Sat) |
例:下面使用一个实例来具体演示 Date 类的使用。假设,某一天特定时间要去做一件事,而且那个时间已经过去一分钟之后才想起来这件事还没有办,这时系统将会提示已经过去了多 长时间。具体的代码如下:
import java.util.Date;
import java.util.Scanner;
public class Test11 {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
System.out.println("请输入要做的事情:");
String title = input.next();
Date date1 = new Date(); // 获取当前日期
System.out.println("[" + title + "] 这件事发生时间为:" + date1);
try {
Thread.sleep(60000);// 暂停 1 分钟
} catch (InterruptedException e) {
e.printStackTrace();
}
Date date2 = new Date();
System.out.println("现在时间为:" + date2);
if (date2.before(date1)) {
System.out.println("你还有 " + (date2.getTime() - date1.getTime()) / 1000 + " 秒需要去完成【" + title + "】这件事!");
} else {
System.out.println("【" + title + "】事情已经过去了 " + (date2.getTime() - date1.getTime()) / 1000 + " 秒");
}
}
}
在该程序中,分别使用 Date 类的无参数构造方法创建了两个 Date 对象。在创建完第一个 Date 对象后,使用 Thread.sleep() 方法让程序休眠 60 秒,然后再创建第二个 Date 对象,这样第二个 Date 对象所表示的时间将会在第一个 Date 对象所表示时间之后,因此“date2.before(date1)”条件表达式不成立,从而执行 else 块中的代码,表示事情已经发生过。
运行该程序,执行结果如下所示。
请输入要做的事情:
收快递
【收快递】这件事发生时间为:Fri Oct 12 11:11:07 CST 2018
现在时间为:Fri Oct 12 11:12:07 CST 2018
【收快递】事情已经过去了 60 秒
Calendar 类
Calendar 类是一个抽象类,它为特定瞬间与 YEAR、MONTH、DAY_OF—MONTH、HOUR 等日历字段之间的转换提供了一些方法,并为操作日历字段(如获得下星期的日期) 提供了一些方法。
创建 Calendar 对象不能使用 new 关键字,因为 Calendar 类是一个抽象类,但是它提供了一个 getInstance() 方法来获得 Calendar类的对象。getInstance() 方法返回一个 Calendar 对象,其日历字段已由当前日期和时间初始化。
Calendar c = Calendar.getInstance();
当创建了一个 Calendar 对象后,就可以通过 Calendar 对象中的一些方法来处理日期、时间。Calendar 类的常用方法如表 所示。
| 方法 | 描述 |
|---|---|
| void add(int field, int amount) | 根据日历的规则,为给定的日历字段 field 添加或减去指定的时间量 amount |
| boolean after(Object when) | 判断此 Calendar 表示的时间是否在指定时间 when 之后,并返回判断结果 |
| boolean before(Object when) | 判断此 Calendar 表示的时间是否在指定时间 when 之前,并返回判断结果 |
| void clear() | 清空 Calendar 中的日期时间值 |
| int compareTo(Calendar anotherCalendar) | 比较两个 Calendar 对象表示的时间值(从格林威治时间 1970 年 01 月 01 日 00 时 00 分 00 秒至现在的毫秒偏移量),大则返回 1,小则返回 -1,相等返回 0 |
| int get(int field) | 返回指定日历字段的值 |
| int getActualMaximum(int field) | 返回指定日历字段可能拥有的最大值 |
| int getActualMinimum(int field) | 返回指定日历字段可能拥有的最小值 |
| int getFirstDayOfWeek() | 获取一星期的第一天。根据不同的国家地区,返回不同的值 |
| static Calendar getInstance() | 使用默认时区和语言坏境获得一个日历 |
| static Calendar getInstance(TimeZone zone) | 使用指定时区和默认语言环境获得一个日历 |
| static Calendar getInstance(TimeZone zone, Locale aLocale) | 使用指定时区和语言环境获得一个日历 |
| Date getTime() | 返回一个表示此 Calendar 时间值(从格林威治时间 1970 年 01 月 01 日 00 时 00 分 00 秒至现在的毫秒偏移量)的 Date 对象 |
| long getTimeInMillis() | 返回此 Calendar 的时间值,以毫秒为单位 |
| void set(int field, int value) | 为指定的日历字段设置给定值 |
| void set(int year, int month, int date) | 设置日历字段 YEAR、MONTH 和 DAY_OF_MONTH 的值 |
| void set(int year, int month, int date, int hourOfDay, int minute, int second) | 设置字段 YEAR、MONTH、DAY_OF_MONTH、HOUR、 MINUTE 和 SECOND 的值 |
| void setFirstDayOfWeek(int value) | 设置一星期的第一天是哪一天 |
| void setTimeInMillis(long millis) | 用给定的 long 值设置此 Calendar 的当前时间值 |
Calendar 对象可以调用 set() 方法将日历翻到任何一个时间,当参数 year 取负数时表示公元前。Calendar 对象调用 get() 方法可以获取有关年、月、日等时间信息,参数 field 的有效值由 Calendar 静态常量指定。
Calendar 类中定义了许多常量,分别表示不同的意义。
- Calendar.YEAR:年份。
- Calendar.MONTH:月份。
- Calendar.DATE:日期。
- Calendar.DAY_OF_MONTH:日期,和上面的字段意义完全相同。
- Calendar.HOUR:12小时制的小时。
- Calendar.HOUR_OF_DAY:24 小时制的小时。
- Calendar.MINUTE:分钟。
- Calendar.SECOND:秒。
- Calendar.DAY_OF_WEEK:星期几。
例如,要获取当前月份可用如下代码:
int month = Calendar.getInstance().get(Calendar.MONTH);
如果整型变量 month 的值是 0,表示当前日历是在 1 月份;如果值是 11,则表示当前日历在 12 月份。
日期格式化
格式化日期表示将日期/时间格式转换为预先定义的日期/时间格式。例如将日期“Fri May 18 15:46:24 CST2016” 格式转换为 “2016-5-18 15:46:24 星期五”的格式。
在 Java 中,可以使用 DateFormat 类和 SimpleDateFormat 类来格式化日期。
DateFormat 类
DateFormat 是日期/时间格式化子类的抽象类,它以与语言无关的方式格式化并解析日期或时间。日期/时间格式化子类(如 SimpleDateFormat)允许进行格式化(也就是日期→文本)、解析(文本→日期)和标准化日期。
在创建 DateFormat 对象时不能使用 new 关键字,而应该使用 DateFormat 类中的静态方法 getDateInstance(),示例代码如下:
DateFormat df = DateFormat.getDatelnstance();
在创建了一个 DateFormat 对象后,可以调用该对象中的方法来对日期/时间进行格式化。DateFormat 类中常用方法如表所示。
| 方法 | 描述 |
|---|---|
| String format(Date date) | 将 Date 格式化日期/时间字符串 |
| Calendar getCalendar() | 获取与此日期/时间格式相关联的日历 |
| static DateFormat getDateInstance() | 获取具有默认格式化风格和默认语言环境的日期格式 |
| static DateFormat getDateInstance(int style) | 获取具有指定格式化风格和默认语言环境的日期格式 |
| static DateFormat getDateInstance(int style, Locale locale) | 获取具有指定格式化风格和指定语言环境的日期格式 |
| static DateFormat getDateTimeInstance() | 获取具有默认格式化风格和默认语言环境的日期/时间 格式 |
| static DateFormat getDateTimeInstance(int dateStyle,int timeStyle) | 获取具有指定日期/时间格式化风格和默认语言环境的 日期/时间格式 |
| static DateFormat getDateTimeInstance(int dateStyle,int timeStyle,Locale locale) | 获取具有指定日期/时间格式化风格和指定语言环境的 日期/时间格式 |
| static DateFormat getTimeInstance() | 获取具有默认格式化风格和默认语言环境的时间格式 |
| static DateFormat getTimeInstance(int style) | 获取具有指定格式化风格和默认语言环境的时间格式 |
| static DateFormat getTimeInstance(int style, Locale locale) | 获取具有指定格式化风格和指定语言环境的时间格式 |
| void setCalendar(Calendar newCalendar) | 为此格式设置日历 |
| Date parse(String source) | 将给定的字符串解析成日期/时间 |
格式化样式主要通过 DateFormat 常量设置。将不同的常量传入到表所示的方法中,以控制结果的长度。DateFormat 类的常量如下。
- SHORT:完全为数字,如 12.5.10 或 5:30pm。
- MEDIUM:较长,如 May 10,2016。
- LONG:更长,如 May 12,2016 或 11:15:32am。
- FULL:是完全指定,如 Tuesday、May 10、2012 AD 或 11:l5:42am CST。
使用 DateFormat 类格式化曰期/时间的示例如下:
// 获取不同格式化风格和中国环境的日期
DateFormat df1 = DateFormat.getDateInstance(DateFormat.SHORT, Locale.CHINA);
DateFormat df2 = DateFormat.getDateInstance(DateFormat.FULL, Locale.CHINA);
DateFormat df3 = DateFormat.getDateInstance(DateFormat.MEDIUM, Locale.CHINA);
DateFormat df4 = DateFormat.getDateInstance(DateFormat.LONG, Locale.CHINA);
// 获取不同格式化风格和中国环境的时间
DateFormat df5 = DateFormat.getTimeInstance(DateFormat.SHORT, Locale.CHINA);
DateFormat df6 = DateFormat.getTimeInstance(DateFormat.FULL, Locale.CHINA);
DateFormat df7 = DateFormat.getTimeInstance(DateFormat.MEDIUM, Locale.CHINA);
DateFormat df8 = DateFormat.getTimeInstance(DateFormat.LONG, Locale.CHINA);
// 将不同格式化风格的日期格式化为日期字符串
String date1 = df1.format(new Date());
String date2 = df2.format(new Date());
String date3 = df3.format(new Date());
String date4 = df4.format(new Date());
// 将不同格式化风格的时间格式化为时间字符串
String time1 = df5.format(new Date());
String time2 = df6.format(new Date());
String time3 = df7.format(new Date());
String time4 = df8.format(new Date());
// 输出日期
System.out.println("SHORT:" + date1 + " " + time1);
System.out.println("FULL:" + date2 + " " + time2);
System.out.println("MEDIUM:" + date3 + " " + time3);
System.out.println("LONG:" + date4 + " " + time4);
运行该段代码,输出的结果如下:
SHORT:18-10-15 上午9:30
FULL:2018年10月15日 星期一 上午09时30分43秒 CST
MEDIUM:2018-10-15 9:30:43
LONG:2018年10月15日 上午09时30分43秒
SimpleDateFormat 类
如果使用 DateFormat 类格式化日期/时间并不能满足要求,那么就需要使用 DateFormat 类的子类——SimpleDateFormat。
SimpleDateFormat 是一个以与语言环境有关的方式来格式化和解析日期的具体类,它允许进行格式化(日期→文本)、解析(文本→日期)和规范化。SimpleDateFormat 使得可以选择任何用户定义的日期/时间格式的模式。
SimpleDateFormat 类主要有如下 3 种构造方法。
- SimpleDateFormat():用默认的格式和默认的语言环境构造 SimpleDateFormat。
- SimpleDateFormat(String pattern):用指定的格式和默认的语言环境构造 SimpleDateF ormat。
- SimpleDateFormat(String pattern,Locale locale):用指定的格式和指定的语言环境构造 SimpleDateF ormat。
SimpleDateFormat 自定义格式中常用的字母及含义如表所示。
| 字母 | 含义 | 示例 |
|---|---|---|
| y | 年份。一般用 yy 表示两位年份,yyyy 表示 4 位年份 | 使用 yy 表示的年扮,如 11; 使用 yyyy 表示的年份,如 2011 |
| M | 月份。一般用 MM 表示月份,如果使用 MMM,则会 根据语言环境显示不同语言的月份 | 使用 MM 表示的月份,如 05; 使用 MMM 表示月份,在 Locale.CHINA 语言环境下,如“十月”;在 Locale.US 语言环境下,如 Oct |
| d | 月份中的天数。一般用 dd 表示天数 | 使用 dd 表示的天数,如 10 |
| D | 年份中的天数。表示当天是当年的第几天, 用 D 表示 | 使用 D 表示的年份中的天数,如 295 |
| E | 星期几。用 E 表示,会根据语言环境的不同, 显示不 同语言的星期几 | 使用 E 表示星期几,在 Locale.CHINA 语 言环境下,如“星期四”;在 Locale.US 语 言环境下,如 Thu |
| H | 一天中的小时数(0~23)。一般用 HH 表示小时数 | 使用 HH 表示的小时数,如 18 |
| h | 一天中的小时数(1~12)。一般使用 hh 表示小时数 | 使用 hh 表示的小时数,如 10 (注意 10 有 可能是 10 点,也可能是 22 点) |
| m | 分钟数。一般使用 mm 表示分钟数 | 使用 mm 表示的分钟数,如 29 |
| s | 秒数。一般使用 ss 表示秒数 | 使用 ss 表示的秒数,如 38 |
| S | 毫秒数。一般使用 SSS 表示毫秒数 | 使用 SSS 表示的毫秒数,如 156 |
例 :编写 Java 程序,使用 SimpleDateFormat 类格式化当前日期并打印,日期格式为“xxxx 年 xx 月 xx 日星期 xxx 点 xx 分 xx 秒”,具体的实现代码如下:
import java.text.SimpleDateFormat;
import java.util.Date;
public class Test13 {
public static void main(String[] args) {
Date now = new Date(); // 创建一个Date对象,获取当前时间
// 指定格式化格式
SimpleDateFormat f = new SimpleDateFormat("今天是 " + "yyyy 年 MM 月 dd 日 E HH 点 mm 分 ss 秒");
System.out.println(f.format(now)); // 将当前时间袼式化为指定的格式
}
}
该程序的运行结果如下:
今天是 2018 年 10 月 15 日 星期一 09 点 26 分 23 秒