零、介绍
最近在刷MIT 6.851,记录下笔记。
What
可持久化数据结构就是能存储、查询数据的历史版本的数据结构。
参考资料
Videos
MIT 6.851 Advanced Data Structures
后面就听不懂了,就前面讲概念(persistent分为4类blabla)能听懂。没有很好的结合图讲,讲得不好。反正听不懂的就是讲得不好:)Text
https://www.geeksforgeeks.org/persistent-data-structures/?ref=lbp
可持久化数据结构简介
MIT 6.854j-advanced-algorithms
很赞!!可惜没video。
Making Data Structures Persistent
太长没看
一、应用(能解决什么问题)
总结了下大致包括如下领域应用:
并发领域
并发事务的原子性(便于Rollback)、隔离性。

https://io-meter.com/2016/09/03/Functional-Go-persist-datastructure-intro/

函数式编程
同上。
版本控制功能
便于实现diff,rollback

js有个专门的库 最新immutable.js持久化数据结构
看起来是配合前端框架React(React + Flux + ImmutableJS )写函数式编程用的。

计算几何
字符串处理

参考资料
可持久化数据结构简介
自己轮一个.net可持久化库Persistent Data Structures下面有讨论use case
中文翻译见可持久化数据结构
Functional Go: 持久化数据结构简介
二、分类

这部分可以看6.851视频
三、通用的实现方法:如何将链式数据结构改造成(partial/full)可持久化
6.851把链式数据结构的模型叫pointer machine model。对于基于pointer machine model的数据结构,有没有通用的方法将他们改造成persistent?
3.1. 先考虑怎么改造成partial persistence
a. fat nodes
add a modification history to every node. Thus, each node knows what its value was at any previous point in time. (For a fully persistent structure, each node would hold a version tree, not just a version history.)
O(1)写,读时对于每个点都要执行O(logm)的查询
看到这里有个问题:每个点的history放hashmap里不就行了?读时也只需要O(1)的查找
但这样做的话,hashmap不支持ceil操作,因此要支持ceil没办法只能用有序结构、log级别查询
个人理解,想做可持久化key/value Map的话即可按这种方法,每个key对应的entry存放所有历史值,这也可以看成是邻接表。
b. path copying
说白了就是写时分裂节点,从root开始分裂到要写的点。将所有version的root存到字典里
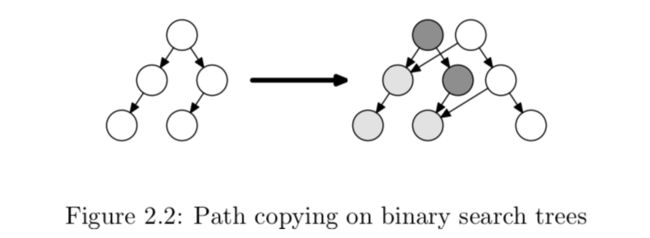
修改时放box,满了就分裂出来一个新节点,分裂时自动apply log
算法竞赛中的可持久化线段树就属于用这种方法实现的partial persistent线段树,读时需要花O(1)或者O(logm)查找root,之后的查询无需额外时间;写时要分裂O(d),d代表树高,平衡树O(logN),非平衡比如链表就是O(N)
c. modification box


难以置信,说白了就是给path copying方法中每个node加一个log cache,最后算出来的写时amortized time complexity就是O(1)了。
What about non-tree data structures?

平衡树怎么处理?
平衡树要旋转,想想就感觉很难改造成持久化。6.854课件讲的很粗没懂。算法竞赛中常用的可持久化平衡树一般就是 可持久化无旋转 Treap,省去了旋转可持久化的复杂。
3.2. 如何改造成full persistence
a. fat nodes
每个点存的log从version queue变成version tree,查询每个点时要从树中找到最近祖先
b. path copying
没区别
c. modification box
怎么找根节点?
i. pointer per version,可能多个pointer指向一个root
ii.存root tree,查询时先找最近祖先
怎么修改old version
i. 修改时放box,满了就分裂出来一个新节点
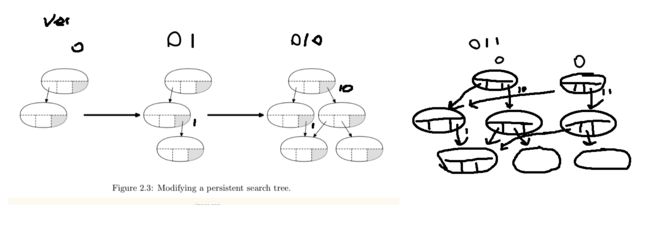
但这样有问题:分裂出来的还是满的,如果整条链都是满的,每次修改复制全部,下次修改还得复制全部。而且这样还不好存root,比如最右边图,代表0的root有俩
ii. 修改时放box,满了就分裂出来一个新节点,但分裂时自动apply有用的log、丢弃没用的log
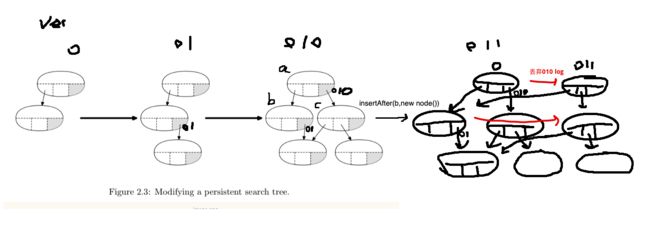
What about non-tree data structures?
6.851有讲,分裂成两个节点,log分成两部分,新节点拿一个子树的log,新节点apply log直到自己的子树,每部分丢弃自己用不到的。
四、通用的实现方法:将链式数据结构改造成confluent/functional persistence
6.851讲了 太复杂没听懂。
五、具体实现
网上关于可持久化数据结构的优质资料都是算法竞赛的,因此收集总结了下竞赛常用的。看了下基本都是partial persistent,有的是fully persistent,都没用到modification box技术。
可持久化线段树
https://www.bilibili.com/video/BV1C4411u7rK?p=1
可持久化字典树
https://www.geeksforgeeks.org/persistent-trie-set-1-introduction/
和可持久化线段树类似的方法,基于path copy实现partial persistence。
问题是每个点在拷贝时都要复制O(R)个指针,插入的时间复杂度为O(len*R)
查询时先从字典(数组/哈希表)里找到指定version的root,然后访问,O(len)
在竞赛中常用的是可持久化01字典树,比如xor问题,见https://oi-wiki.org/ds/persistent-trie/,没看懂
可持久化平衡树
算法竞赛中常用的可持久化平衡树一般就是 可持久化无旋转 Treap,省去了旋转可持久化的复杂。
fully persistent array
【AgOHの数据结构】可持久化数组
https://www.luogu.com.cn/problem/P3919
方案:
a. fat nodes
每个节点放所有历史,查询时在所有历史版本中找最近祖先版本
b. path copying
存到可持久化线段树里。
为什么好好的线性结构要树化?直觉上理解,是为了分裂新版本时减少指针复制。
如果是稀疏数组,朴素方法太浪费空间了,可以基于动态开点来优化空间存储,见https://io-meter.com/2016/11/06/functional-go-intro-to-hamt/
可持久化并查集
【AgOHの数据结构】可持久化并查集
并查集基于数组,可持久化并查集就基于可持久化数组。可持久化数组用可持久化线段树实现,因此可持久化并查集用可持久化线段树实现
可持久化块状链表
《 可持久化数据结构研究 》
不过文中写的太简略了,个人推测的维护方法为:

每次写操作的时间复杂度O(根号N)
ADT:Persistent List/Stack
https://io-meter.com/2016/09/03/Functional-Go-persist-datastructure-intro/
讨论支持如下操作的抽象数据结构(ADT)如何可持久化:

a. 基于普通数组
只能copy on write
b. 基于可持久化数组/可持久化线段树
问题是怎么处理新增节点、删除节点?得想办法魔改线段树
c. 可持久化链表
d. 可持久化块状链表
e. 可持久化平衡树
f. 文中提到的vector trie
名字挺骚的没反应过来,看了一会发现:这玩意就是可持久化数组(可持久化线段树),只不过是多叉树,叫“可持久化多叉线段树”比较形象。文章也没提怎么处理新增节点、删除节点。
ADT:Persistent key-value map
persistent-hash-table-implementation
a. 可持久化平衡树
b. 还用hashmap,但是每个entry改造成fat node(存放所有log),查询时先找到entry,再在所有log 中找最近祖先版本
c. 可持久化数组。
考虑到HashMap本来就能只用一个数组实现(解决冲突时用open addressing方法,不用Chaining),那么实现了可持久化数组就相当于实现了可持久化HashMap
d. Hash_trie
hash(key)的值存在trie里,value放到trie的叶子节点。优化版本包括Hash array mapped tries and Ctries
HAMT这名字起的很奇怪。原理就是块状hash trie(所谓块状是我自己起的名,指每个节点区分儿子时不是单纯的比较某1位,而是比较某2位甚至多位)(或者理解成hash trie+动态开点多叉线段树也行)(反正就是bitwise hash trie加上一堆优化,懒得记就记hash trie就行了,真要自己实现的时候这些优化trick也能想到)
文中讲hamt的碰撞处理有点扯,个人理解可以chaining,可以open addressing。细节没深究,可以看论文和讨论。按作者的意思AMT是之前他提出的一种Trie的优化,比Tenary search trie要好。
Array Mapped Tries(AMT), first described in Fast and
Space Efficient Trie Searches, Bagwell [2000],
git的数据结构?
// TOOD
六、思考
最优的二维range minimum query数据结构是什么?
朴素的方法是线段树套线段树,以便支持二维RMQ,时间复杂度O(logN*logN)。
个人理解,最优的二维RMQ数据结构应该是用modification box实现的可持久化值域线段树,O(N)的构造时间、空间,O(logN)的查询。
二维统计问题的通用数据结构
如果统计操作具有“区间可加性”、“区间可减性”,那么该操作二维统计问题可以使用可持久化线段树。
range minimum query中的min()操作其实不具有区间可减性,但是range minimum query问题可以归约成range select query问题,进而可以归约成range count query问题,而count()操作具有区间可加减性,因此也能用可持久化线段树。
所以我们得到了一类二维统计问题的通用数据结构:对于可归约成具有“区间可加性”、“区间可减性”统计操作的二维统计问题,可以使用可持久化线段树存储,以便支持快速查询(统计)。
[ ] 高维统计问题的归约?
能否找到一类高维统计问题,具有通用的logN级别解?个人理解可以借鉴代数的思想,只要有区间可加减性的都能归约成K维RMQ问题,用modification box实现的可持久化值域线段树解决。
// TOOD 只是个人畅想,没细想。
外存模型下的可持久化数据结构
可持久化Map
bigtable(hbase)可以看成外存模型下的可持久化map:

但需要注意的是删除操作会真的删掉之前的老版本数据:

其实任何支持前缀匹配的db都能作为可持久化map,你只需要把rowkey设计成"key@@timestamp"即可
http://hbase.apache.org/book.html#reverse.timestamp