Part 1:
paper
Style Transfer是AI将不同风格和内容结合在一起从而创造出新艺术作品的技术。如Figure 1所示,将相机拍摄下的街景照片分别与梵高的《星空》、蒙克的《尖叫》以及透纳的《牛头人的沉船》结合在一起,创造出对应风格的油画作品。
以梵高的《星空》为例,图c的内容和原始图像相近,除此之外天空中还呈现了《星空》中的月亮和星星,而绘画笔法上也继承了梵高的粗笔触,画面的整体色调和《星空》一致。可以看出,算法对提供绘画素材的街景图片和提供绘画风格素材的《星空》两者的处理方式是不同的,对前者着重保留画面内容,对后者则是要剔除掉其内容而保留绘画风格。
该模型出自 A Neural Algorithm of Artistic Style,是最早的关于Artistic Style Transfer的paper,也被认为是现在最有效的算法,本文就是要讲解如何实现该算法。

Figure 2是模型的核心思想,通过从输入图片中提取出内容表征(Content Representations)和风格表征(Style Resentations),并用提取出的content和style表征来生成一幅内容和风格分别与原始图片相近但又不完全相同的新图片。
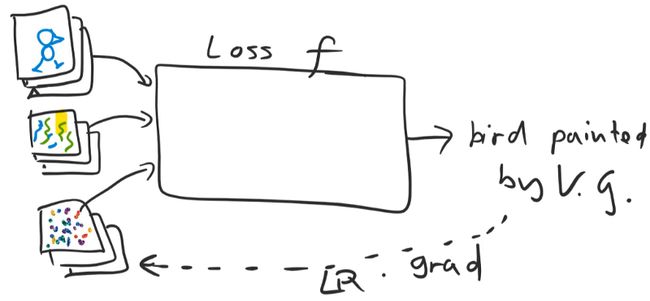
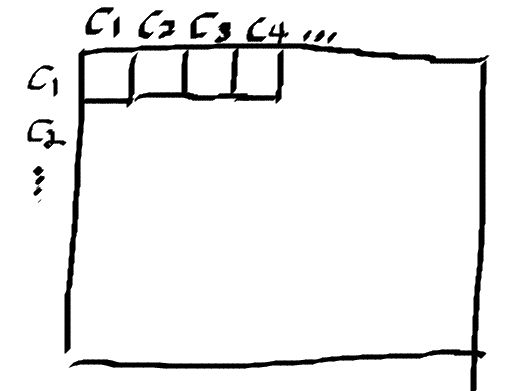
如Figure 3的草图所示,模型的Input包括:
- content image
- style image
- output image
Input通过loss function通过计算content/style和output的差异,将求导得到的梯度用于修正output image的pixels。从前文已经知道,模型对content和style的处理是不同的,所以需要两个loss function: content loss和style loss。
content loss
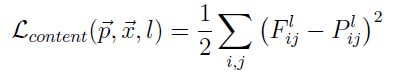
从公式可以看出,content loss function就是MSE。表示content image,则表示output image,和则分别表示和在深度卷积网络第l层的第i个feature map第j个位置的activation值。
如Figure 4所示,CNN每层的activation值就是整体图像的一个局部,output image就是将content image每层的局部activation组合在一起的结果,所以content image和的内容才会有高相似度,但又不完全相同。如果你还需要进一步了解卷积神经网络,请阅读Visualizing and Understanding Convolutional Networks。
style loss
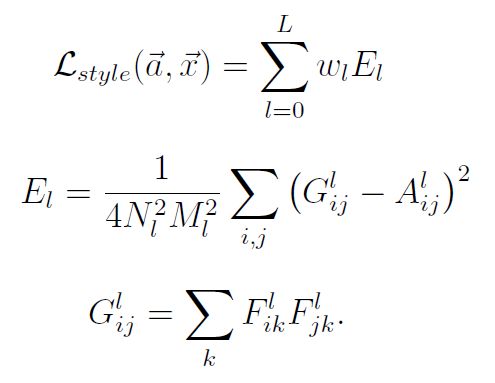
公式中的符号表示:
- , 原始的style image
- , 生成的image
- G & A, Gram matrix.
- Nl, lth层的filters个数.
- Ml, lth层的feature map size.
- , 神经网络中lth层的ith feature map向量.
- k, 向量中的element.
从公式中可以看出,style loss取自原始image和生成的image在神经网络中的Gram matrix的MSE。
上述是WikiPedia对Gram matrix的解释,在这里,我想用一种更直观的方式告诉你,为什么要在style representation中使用Gram matrix,其背后的原理是什么。
从前文对Figure 1的分析已经知道,我们想要剔除style image中实际的内容,比如《星空》中的月亮、星星、房屋、树木等,只提取style image中的笔触、光影、色彩等绘画手法,这就需要破坏feature map matrix中的空间信息,将matrix转换为vector。
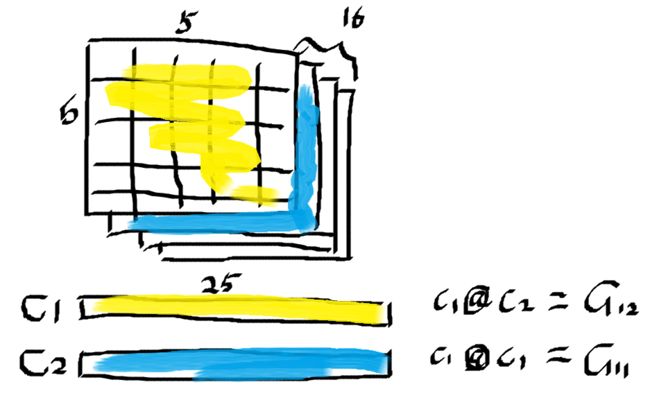
Figure 5中的matrix就是神经网络lth层的5x5x16大小的activation matrix,C1、C2分别是前两个channel的feature map转换后的结果:两个长度为25的向量。
flattening后的向量已经没有了原来的空间信息,只剩下样式信息,而C1和C2的点积会得到的一个值,这个值代表的是什么呢?我们假设C1表示的是画家作画时的笔触比较粗,C2表示的是画家作画时的笔触比较短。
C1@C2 = G12,G12表示该画作中粗笔触和短笔触的相关性(correlations)。两个向量相关性越强,则它们点积值就越大(大正数或小负数),反之,弱相关性会让两向量的点积产生相互抵消的效果(小正数或大负数)。所以,G12的值越大,表明画家越喜欢用短且粗的笔触作画(这是梵高的绘画特点之一),反之表示画家不会用短的粗笔触作画。
C1@C1 = G11,G11表示该画作中笔触的粗矿粒度以及“粗笔触”这一特性的活跃程度,和C1@C2一样,G11值越大表示粗粒程度越大、特性越明显,这就好像是卷积神经网络中max pooling layer,grid cell值越大表明其是高频特征的程度越大。
(C1, C1),(C1, C2), (C1, C3), ...... (C16, C16)所有组合的点积,就能得到Figure 6所示的图形,它实际上是16x16的矩阵的内积,就是style loss要求的Gram matrix。
total loss
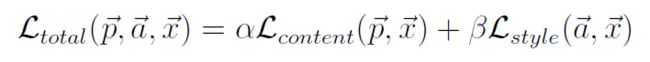
total loss就是content loss和style loss的和,通过调整和的比例来控制style transfer的比例,一般固定为1,只调节, [0, 1]。
到这里,已经分析完A Neural Algorithm of Artistic Style模型,接下来将进入part2,模型实现部分。
Part 2:
Notebook
在Part 2,我们将以白头海鹰和梵高另一幅星空作品为素材,通过style transfer创造出由梵高“画”的白头海鹰油画。
Dataset
可以看出,input images的shape是不一致,我们需要先调整他们的大小,并生成相同大小的output image。
img.shape, style_img.shape
((710, 1024, 3), (960, 1344, 3))
def scale_match(src, targ):
h,w,_ = src.shape
sh,sw,_ = targ.shape
rat = max(h/sh,w/sw); rat
res = cv2.resize(targ, (int(sw*rat), int(sh*rat)))
return res[:h,:w]
style = scale_match(img, style_img)
img.shape, style.shape
((710, 1024, 3), (710, 1024, 3))
一般来说,style image的分辨率往往比content image要高,所以通常是根据content image的shape来调整style image的大小。
output_img = np.random.uniform(0, 1, size=img.shape).astype(np.float32)
output_img = scipy.ndimage.filters.median_filter(output_img , [8,8,1])
plt.imshow(output_img);
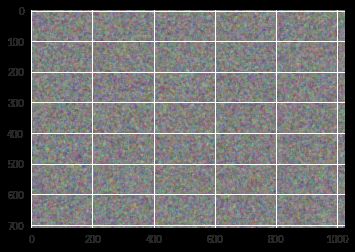
output_img是我们要生成的目标图像,模型训练过程就是利用梯度不断修正out_img和其他input images相似度的过程。之所以要对nosie image做median filter,是因为真实的图像都是平滑的,而非np.random.uniform()创建的严格均匀分布的随机数,否则它就不像是图像,而只是一堆随机数,在实际训练中很难计算出梯度。median filter起到了median pooling,让图像平滑化的作用。
trn_tfms,val_tfms = tfms_from_model(vgg16, sz)
img_tfm = val_tfms(img)
img_tfm.shape
(3, 710, 710)
output_img = val_tfms(output_img)/2
output_img_v= V(output_img[None], requires_grad=True)
output_img_v.shape
torch.Size([1, 3, 710, 710])
作为神经网络的dataset,需要将input images的shape从rank 3转换为rank 4 [batch_size, num_channel, height, width],这里通过None生成batch为1的维度,同时还要将height、width设定为相同长度。val_tfms是不做data augumentation的transform,其原因会在讲解model部分时作说明。
Model
Artistic Style基于vgg神经网络模型,和其他项目不同,style transfer不需要训练神经网络中的权值,而是通过梯度来修正output image的像素。和paper一样,我使用pretrained vgg16,并disable更新权值的功能以减少多余的计算和内存消耗。
m_vgg = to_gpu(vgg16(True)).eval()
set_trainable(m_vgg, False)
从content和style的loss function公式可以看出,和其他CNN不同,我们需要导出每一层的activation值,对于pytorch,可以用forward hook来实现的。
Forward Hook
Pytorch的nn.Module有一个callable方法: forward,从名字上你就可以知道,它是神经网络做前向传播的方法,例如:
class Xnet(nn.Module):
def __init__(self, nin, nf):
......
def forward(self, x):
......
xnet = Xnet()
xnet(dataset)
Xnet继承于nn.Module,xnet(dataset)会调用Xnet.forward方法来进行前向传播计算,如果Xnet注册了forward hook方法,它会在Xnet.forward结束后触发。
Style transfer中,我们需要获取的是feature map grid size改变前的activation值,即通过给maxpooling或stride convolution层(stride == 2)的上一层注册forward hook。
class SaveFeatures():
features=None
def __init__(self, m): self.hook = m.register_forward_hook(self.hook_fn)
def hook_fn(self, module, input, output): self.features = output
def close(self): self.hook.remove()
block_ends = [i-1 for i,o in enumerate(children(m_vgg))
if isinstance(o,nn.MaxPool2d)]
block_ends
[5, 12, 22, 32, 42]
SaveFeatures用于注册forward hook,block_ends中存放着feature map grid size发生改变之前的层号。
Training
def get_opt():
output_img = np.random.uniform(0, 1, size=img.shape).astype(np.float32)
output_img = scipy.ndimage.filters.median_filter(output_img, [8,8,1])
output_img_v = V(val_tfms(output_img/2)[None], requires_grad=True)
return output_img_v, optim.LBFGS([output_img_v])
def step(loss_fn):
global n_iter
optimizer.zero_grad()
loss = loss_fn(output_img_v)
loss.backward()
n_iter+=1
if n_iter%show_iter==0: print(f'Iteration: n_iter, loss: {loss.data[0]}')
return loss
n_iter=0
max_iter = 1000
show_iter = 100
output_img_v, optimizer = get_opt()
while n_iter <= max_iter: optimizer.step(partial(step,actn_loss))
我们知道,神经网络通过优化器(optimizer),在循环迭代的过程中,利用loss function计算出梯度,找到神经网络参数的调整方向,通过对参数的调整以达到降低loss值。换句话说,降低loss值的过程就是拟合神经网络模型的过程。
回顾Figure 3,style transfer的训练过程就是通过优化content/style loss来调整output image的像素,让它和content image和style image相互match的过程。
我们在这个项目使用的优化器是L-BFGS,它被
Image Style Transfer Using Convolutional Neural Networks认为是在图像合成中表现最优的优化器。
L-BFGS中的"BFGS"是四位算法发明者(Broyden–Fletcher–Goldfarb–Shanno)名字的简写,"L"则代表limited memory。和SGD、Adam不同的是,LBFGS在深度神经网络中的表现往往都很糟糕。之所以它在神经网络中的表现不好,在于它除了会根据loss值计算梯度,还会计算梯度的梯度(Hessian ),结果不仅需要更多的计算量,还需要使用大量的内存来track梯度变量,这也是它不如SGD和Adam使用如此之广的原因。
如果说loss值计算梯度,是为调整参数找到方向,那么计算Hessian则是计算梯度变化的速度,是为得到参数调整的步长。虽然LBFGS相比SGD的momentum可以更精确地调整参数,但其计算量也相比SGD要更大,对于有着成百上千万个参数的深度神经网络,LBFGS显然不是好的选择。但对于不需要调整网络参数的style transfer来说,LBFGS就能发挥出它的优势,这也是为什么会在这个项目中使用这个冷门优化器的原因。
Content Restruct
block_ends[3]
32
sf = SaveFeatures(children(m_vgg)[block_ends[3]])
def content_loss(x):
m_vgg(x)
out = V(sf.features)
return F.mse_loss(out, targ_v)*1000
output_img_v, optimizer = get_opt()
m_vgg(VV(img_tfm[None]))
targ_v = V(sf.features.clone())
n_iter=0
while n_iter <= max_iter: optimizer.step(partial(step, content_loss))
Iteration: n_iter, loss: 0.14002405107021332
Iteration: n_iter, loss: 0.05928822606801987
Iteration: n_iter, loss: 0.037577468901872635
Iteration: n_iter, loss: 0.027887802571058273
Iteration: n_iter, loss: 0.02253057062625885
Iteration: n_iter, loss: 0.01918598636984825
Iteration: n_iter, loss: 0.016832195222377777
Iteration: n_iter, loss: 0.015042142942547798
Iteration: n_iter, loss: 0.013666849583387375
Iteration: n_iter, loss: 0.01256621815264225
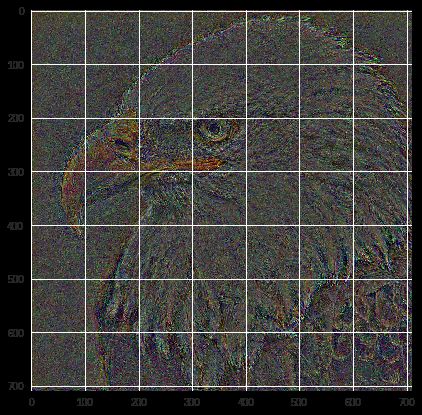
回顾Part 1中的content loss,我们在这里选择content image和output image的第32层的activation做MSE。之所以选择block_ends[3](32)而不是block_ends[2]或block_ends[4],是由最终结果决定的。之所以要对mse_loss的结果乘以1000,是因为原loss值非常小,通过对其做scale处理可以有利于模型训练。最终,我们得到了一张白头海鹰但又不是原图中白头海鹰的图像,这正是我们所需要的。
Style Restruct
m_vgg(VV(img_tfm[None]))
sfs = [SaveFeatures(children(m_vgg)[idx]) for idx in block_ends]
targ_vs = [V(o.features.clone()) for o in sfs]
[o.shape for o in targ_vs]
[torch.Size([1, 64, 710, 710]),
torch.Size([1, 128, 355, 355]),
torch.Size([1, 256, 177, 177]),
torch.Size([1, 512, 88, 88]),
torch.Size([1, 512, 44, 44])]
def gram(input):
b,c,h,w = input.size()
x = input.view(b*c, -1)
return torch.mm(x, x.t())/input.numel()*1e6
def gram_mse_loss(input, target): return F.mse_loss(gram(input), gram(target))
def style_loss(x):
m_vgg(output_img_v)
outs = [V(o.features) for o in sfs]
losses = [gram_mse_loss(o, s) for o,s in zip(outs, targ_styles)]
return sum(losses)
n_iter=0
while n_iter <= max_iter: optimizer.step(partial(step,style_loss))
Iteration: n_iter, loss: 52.1091423034668
Iteration: n_iter, loss: 4.63181209564209
Iteration: n_iter, loss: 0.9747222661972046
Iteration: n_iter, loss: 0.4136861264705658
Iteration: n_iter, loss: 0.2491530179977417
Iteration: n_iter, loss: 0.1806013584136963
Iteration: n_iter, loss: 0.14466366171836853
Iteration: n_iter, loss: 0.12279225140810013
Iteration: n_iter, loss: 0.10791991651058197
Iteration: n_iter, loss: 0.09749597311019897
和content match类似的,通过计算block_ends中所有层的activation值的MSE的总和可以得到style loss值。Gram matrix == flattened vectors * 它们的转置 / (b * c * h * w),input.numel()就是(b * c * h * w)的封装,1e6在这里也是起到scale Gram matrix values的作用。Figure 8就是从style image中提取出来的样式特征。
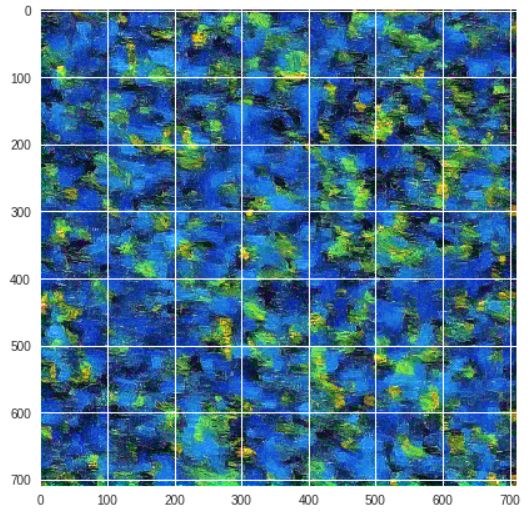
Style Transfer
def comb_loss(x):
m_vgg(output_img_v)
outs = [V(o.features) for o in sfs]
losses = [gram_mse_loss(o, s) for o,s in zip(outs, targ_styles)]
cnt_loss = F.mse_loss(outs[3], targ_vs[3])*1e+6
style_loss = sum(losses)
return cnt_loss + style_loss
n_iter=0
while n_iter <= max_iter: optimizer.step(partial(step,comb_loss))
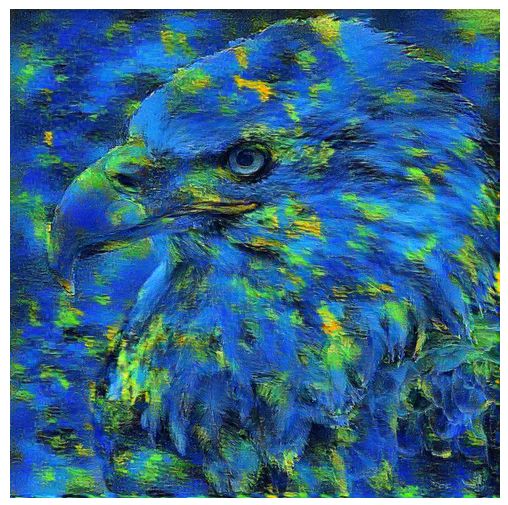
Figure 9就是最终style transfer呈现出来的效果,用油画的形式,结合《夜港》中蓝色和黄色交织的样式,生成出不同于原图中的白头海鹰,从呈像效果来看,A Neural Algorithm of Artistic Style还是很惊艳的。
小结
Content Restruct + Style Restruct = Style Transfer。Restruct是通过深度神经网络来实现的,optimizer会根据content loss和style loss来调整output
image的像素。Style restruct通过flattening feature map matrix来剔除style image中空间信息(原图中的内容),flattened matrix就是Gram matrix。
References
- A Neural Algorithm of Artistic Style
- Visualizing and Understanding Convolutional Networks
- https://en.wikipedia.org/wiki/Gramian_matrix
- Image Style Transfer Using Convolutional Neural Networks
- LBFGS
- https://github.com/fastai/fastai/blob/master/courses/dl2/style-transfer.ipynb
- https://medium.com/@hiromi_suenaga/deep-learning-2-part-2-lesson-13-43454b21a5d0
更多精彩文章,欢迎扫码关注下方的公众号, 并访问我的博客:https://www.jianshu.com/u/c0fe8671254e
欢迎转发至朋友圈,工作号转载请后台留言申请授权~
