ACL 2021|美团提出基于对比学习的文本表示模型,效果提升8%

总第455篇
2021年 第025篇

尽管基于BERT的模型在NLP诸多下游任务中取得了成功,直接从BERT导出的句向量表示往往被约束在一个很小的区域内,表现出很高的相似度,因而难以直接用于文本语义匹配。
为解决BERT原生句子表示这种“坍缩”现象,美团NLP中心知识图谱团队提出了基于对比学习的句子表示迁移方法——ConSERT,通过在目标领域的无监督语料上Fine-tune,使模型生成的句子表示与下游任务的数据分布更加适配。在句子语义匹配(STS)任务的实验结果显示,同等设置下ConSERT相比此前的SOTA大幅提升了8%,并且在少样本场景下仍表现出较强的性能提升。
1. 背景
2. 研究现状和相关工作
-
2.1 句子表征学习
2.2 对比学习
3. 模型介绍
-
3.1 问题定义
3.2 基于对比学习的句子表示迁移框架
3.3 用于文本领域的数据增强方法探索
3.4 进一步融合监督信号
4. 实验分析
-
4.1 无监督实验
4.2 有监督实验
4.3 不同的数据增强方法分析
4.4 少样本设置下的实验分析
4.5 Temperature超参的实验分析
4.6 Batch size超参的实验分析
5. 总结
参考文献
作者简介
| 论文:《ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer》
| 会议:ACL 2021
| 下载链接:https://arxiv.org/abs/2105.11741
| 开源代码:https://github.com/yym6472/ConSERT
1. 背景
句向量表示学习在自然语言处理(NLP)领域占据重要地位,许多NLP任务的成功离不开训练优质的句子表示向量。特别是在文本语义匹配(Semantic Textual Similarity)、文本向量检索(Dense Text Retrieval)等任务上,模型通过计算两个句子编码后的Embedding在表示空间的相似度来衡量这两个句子语义上的相关程度,从而决定其匹配分数。
尽管基于BERT的模型在诸多NLP任务上取得了不错的性能(通过有监督的Fine-tune),但其自身导出的句向量(不经过Fine-tune,对所有词向量求平均)质量较低,甚至比不上Glove的结果,因而难以反映出两个句子的语义相似度 。我们在研究的过程中进一步分析了BERT导出的句向量所具有的特性,证实了以下两点:
BERT对所有的句子都倾向于编码到一个较小的空间区域内,这使得大多数的句子对都具有较高的相似度分数,即使是那些语义上完全无关的句子对(如图1a所示)。我们将此称为BERT句子表示的“坍缩(Collapse)”现象。

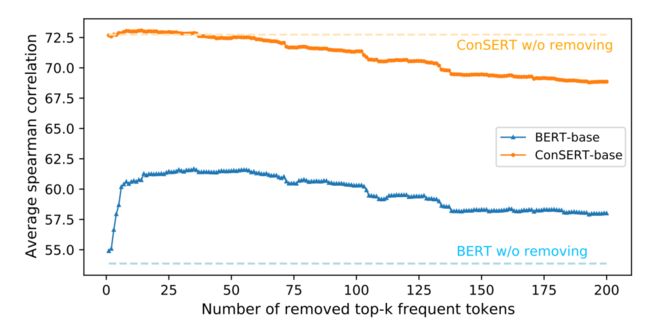
BERT句向量表示的坍缩和句子中的高频词有关。具体来说,当通过平均词向量的方式计算句向量时,那些高频词的词向量将会主导句向量,使之难以体现其原本的语义。当计算句向量时去除若干高频词时,坍缩现象可以在一定程度上得到缓解(如图2蓝色曲线所示)。
BERT导出的句向量难以直接用于下游的语义匹配任务,而用于Fine-tune的监督语料又是昂贵的。因此我们希望寻找一种自监督的方法,只需要收集少量来自于下游任务无标注的文本用于Fine-tune,就能解决BERT句向量的“坍缩”问题,同时让其表征更适用于下游任务。
在本文中,我们使用了对比学习(Contrastive Learning)来达到上述目的。对比学习是目前被广泛应用的自监督任务之一,其核心思想为:人类是通过“对比”来辨别对象的,因此相似的事物在编码后的表示空间中应当相近,不同的事物则应当相距尽可能远。通过对同一样本施加不同的数据增强方法,我们能够得到一系列“自相似”的文本对作为正例,同时将同一个Batch内的其他文本作为负例,以此为监督信号去规范BERT的表示空间。在实验中,我们发现对比学习能够出色地消解高频词对句子语义表示的干扰(如图2橙色曲线所示)。在经过对比学习训练之后,模型生成的句子表示将不再由高频词主导(体现在移除前几个高频词后,性能没有出现非常明显的变化)。这是因为对比学习“辨别自身”的学习目标能够天然地识别并抑制这类高频特征,从而避免语义相差较大的句子表示过于相近(即坍缩现象)。
在对比学习中,我们进一步分析了不同的数据增强方法在其中的影响,同时验证了我们的方法在少样本情况下的性能表现。实验结果显示,即使是在非常有限的数据量情况下(如1000条无标注样本),我们的方法仍然表现出很强的鲁棒性,能够十分有效地解决BERT表示空间的坍缩问题,提升在下游语义匹配任务上的指标。
2. 研究现状和相关工作
2.1 句子表征学习
句子表征学习是一个很经典的任务,分为以下三个阶段:
有监督的句子表征学习方法:早期的工作 发现自然语言推理(Natural Language Inference,NLI)任务对语义匹配任务有较大的帮助,他们使用BiLSTM编码器,融合了两个NLI的数据集SNLI和MNLI进行训练。Universal Sentence Encoder (USE)使用了基于Transformer的架构,并使用SNLI对无监督训练进行增强。SBERT 进一步使用了一个共享的预训练的BERT编码器对两个句子进行编码,在NLI数据集上进行训练(Fine-tune)。
自监督的Sentence-level预训练:有监督数据标注成本高,研究者们开始寻找无监督的训练方式。BERT提出了NSP的任务,可以算作是一种自监督的句子级预训练目标。尽管之后的工作指出NSP相比于MLM其实没有太大帮助。Cross-Thought 、CMLM 是两种思想类似的预训练目标,他们把一段文章切成多个短句,然后通过相邻句子的编码去恢复当前句子中被Mask的Token。相比于MLM,额外添加了上下文其他句子的编码对Token恢复的帮助,因此更适合句子级别的训练。SLM 通过将原本连贯的若干个短句打乱顺序(通过改变Position Id实现),然后通过预测正确的句子顺序进行自监督预训练。
无监督的句子表示迁移:预训练模型现已被普遍使用,然而BERT的NSP任务得到的表示表现更不好,大多数同学也没有资源去进行自监督预训练,因此将预训练模型的表示迁移到任务才是更有效的方式。BERT-flow :CMU&字节AI Lab的工作,通过在BERT之上学习一个可逆的Flow变换,可以将BERT表示空间映射到规范化的标准高斯空间,然后在高斯空间进行相似度匹配。BERT-whitening :苏剑林和我们同期的工作。他们提出对BERT表征进行白化操作(均值变为0,协方差变为单位矩阵)就能在STS上达到媲美BERT-flow的效果。SimCSE :在我们2月份投稿ACL后,看到陈丹琦组在2021年4月份公开的工作。他们同样使用基于对比学习的训练框架,使用Dropout的数据增强方法,在维基百科语料上Fine-tune BERT。
2.2 对比学习
对比学习是CV领域从2019年末开始兴起的预训练方法,同时最近也被广泛应用到了NLP任务中,我们简要介绍两个领域下的进展:
计算机视觉(CV)领域的对比学习:2019年年末~2020年年初,Facebook提出MoCo ,谷歌提出SimCLR ,自此对比学习开始在无监督图像表示预训练领域大放光彩。SimCLR提出了一种简单的对比学习框架,通过对同一个图像进行增强,得到两个不同版本,随后通过ResNet对图像编码,再使用一个映射层将其映射到对比学习空间,使用NT-Xent损失进行预训练。本文的框架也主要受到SimCLR的启发。
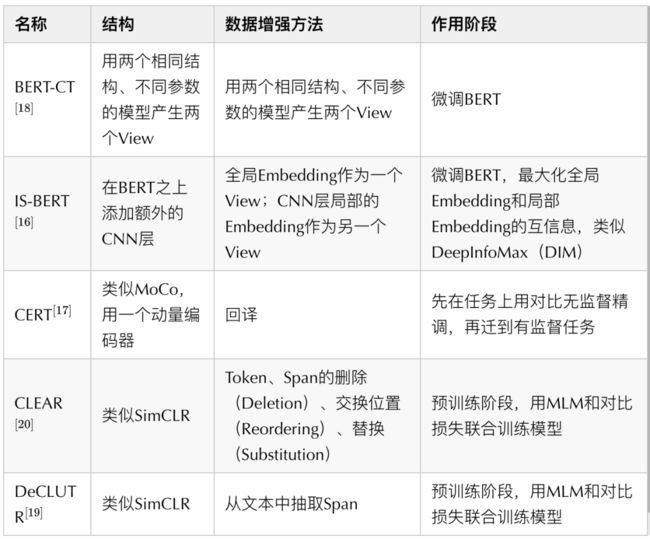
NLP领域的对比学习(用于文本表示学习):随着对比学习在CV无监督图像表示预训练任务上大获成功,许多工作也试图将对比学习引入到NLP的语言模型预训练中。下面是一些代表性的工作及其总结:
3. 模型介绍
3.1 问题定义
给定一个类似BERT的预训练语言模型 ,以及从目标领域数据分布中收集的无标签文本语料库 ,我们希望通过构建自监督任务在 上对 进行Fine-tune,使得Fine-tune后的模型能够在目标任务(文本语义匹配)上表现最好。
3.2 基于对比学习的句子表示迁移框架
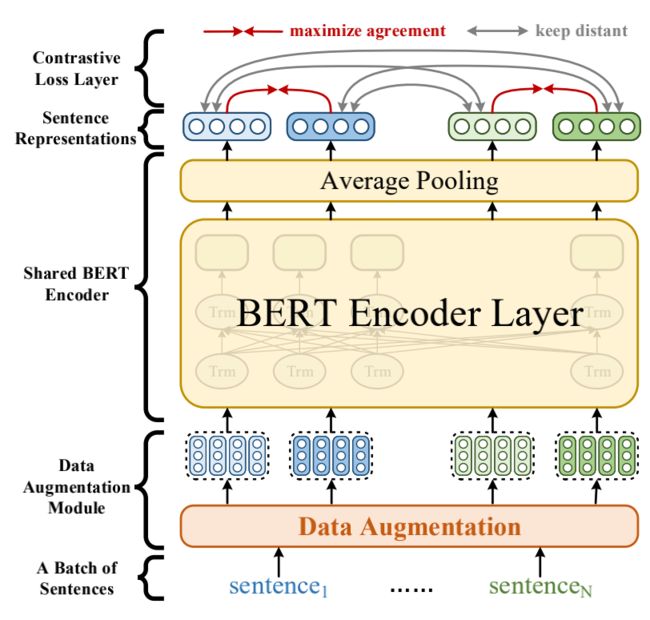
如图3所示,我们受到SimCLR的启发对BERT编码器进行了改进,提出ConSERT,主要包含三个部分:
一个数据增强模块(详见后文),作用于Embedding层,为同一个句子生成两个不同的增强版本(View)。
一个共享的BERT编码器,为输入的句子生成句向量。
一个对比损失层,用于在一个Batch的样本中计算对比损失,其思想是最大化同一个样本不同增强版本句向量的相似度,同时使得不同样本的句向量相互远离。
训练时,先从数据集 中采样一个Batch的文本,设Batch size为 。通过数据增强模块,每一个样本都通过两种预设的数据增强方法生成两个版本,得到总共 条样本。这 条样本均会通过共享的BERT编码器进行编码,然后通过一个平均池化层,得到 个句向量。我们采用和SimCLR一致的NT-Xent损失对模型进行Fine-tune:
这里的 函数为余弦相似度函数; 表示对应的句向量; 表示temperature,是一个超参数,实验中取0.1。该损失从直观上理解,是让Batch内的每个样本都找到其对应的另一个增强版本,而Batch内的其他 个样本将充当负样本。优化的结果就是让同一个样本的两个增强版本在表示空间中具有尽可能大的一致性,同时和其他的Batch内负样本相距尽可能远。
3.3 用于文本领域的数据增强方法探索

图像领域可以方便地对样本进行变换,如旋转、翻转、裁剪、去色、模糊等等,从而得到对应的增强版本。然而,由于语言天然的复杂性,很难找到高效的、同时又保留语义不变的数据增强方法。一些显式生成增强样本的方法包括:
回译:利用机器翻译模型,将文本翻译到另一个语言,再翻译回来。
CBERT :将文本的部分词替换成[MASK],然后利用BERT去恢复对应的词,生成增强句子。
意译(Paraphrase):利用训练好的Paraphrase生成模型生成同义句。
然而这些方法一方面不一定能保证语义一致,另一方面每一次数据增强都需要做一次模型Inference,开销会很大。鉴于此,我们考虑了在Embedding层隐式生成增强样本的方法,如图4所示:
对抗攻击(Adversarial Attack):这一方法通过梯度反传生成对抗扰动,将该扰动加到原本的Embedding矩阵上,就能得到增强后的样本。由于生成对抗扰动需要梯度反传,因此这一数据增强方法仅适用于有监督训练的场景。
打乱词序(Token Shuffling):这一方法扰乱输入样本的词序。由于Transformer结构没有“位置”的概念,模型对Token位置的感知全靠Embedding中的Position Ids得到。因此在实现上,我们只需要将Position Ids进行Shuffle即可。
裁剪(Cutoff):又可以进一步分为两种:
-
Token Cutoff:随机选取Token,将对应Token的Embedding整行置为零。
Feature Cutoff:随机选取Embedding的Feature,将选取的Feature维度整列置为零。
Dropout:Embedding中的每一个元素都以一定概率置为零,与Cutoff不同的是,该方法并没有按行或者按列的约束。
这四种方法均可以方便地通过对Embedding矩阵(或是BERT的Position Encoding)进行修改得到,因此相比显式生成增强文本的方法更为高效。
3.4 进一步融合监督信号
除了无监督训练以外,我们还提出了几种进一步融合监督信号的策略:
联合训练(joint):有监督的损失和无监督的损失通过加权联合训练模型。
先有监督再无监督(sup-unsup):先使用有监督损失训练模型,再使用无监督的方法进行表示迁移。
联合训练再无监督(joint-unsup):先使用联合损失训练模型,再使用无监督的方法进行表示迁移。
4. 实验分析
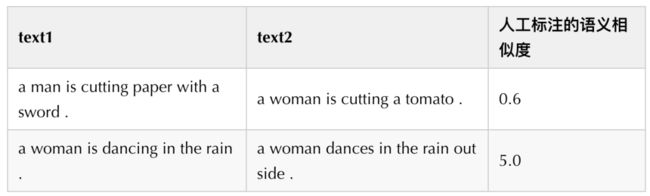
我们主要在文本语义匹配(Semantic Textual Similarity,STS)任务上进行了实验,包括七个数据集:STS12、STS13、STS14、STS15、STS16、STSb、SICK-R。其中STS12-16为SemEval2012 ~ 2016评测比赛放出的数据集;STSb为STS benchmark,来自于SemEval2017评测赛;SICK-R 表示 SICK-Relatedness,是SICK(Sentences Involving ComPositional Knowledge)数据集中的一个子任务,目标是推断两个句子时间的语义相关性(即Relatedness)。这些数据集中的样本均包含两个短文本text1和text2,以及人工标注的位于0~5之间的分数,代表text1和text2语义上的匹配程度(5表示最匹配,即“两句话表达的是同一个语义”;0表示最不匹配,即“两句话表达的语义完全不相关”)。下面给出了两条样本作为示例:
在测试时,我们根据此前的工作 选择了斯皮尔曼相关系数(Spearman correlation)作为评测指标,它将用于衡量两组值(模型预测的余弦相似度和人工标注的语义相似度)之间的相关性,结果将位于[-1, 1]之间,仅当两组值完全正相关时取到1。对于每个数据集,我们将其测试样本全部融合计算该指标,并且报告了七个数据集的平均结果。考虑到简洁性,会在表格中报告乘以100倍的结果。
4.1 无监督实验
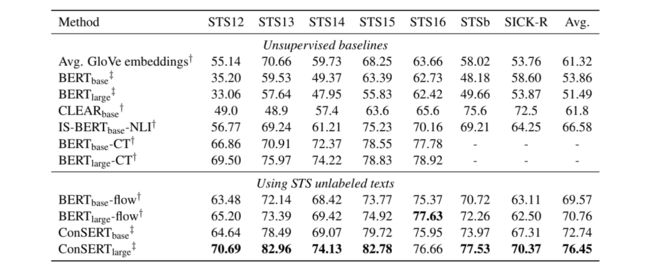
在无监督实验中,我们直接基于预训练的BERT在无标注的STS数据上进行Fine-tune。结果显示,我们的方法在完全一致的设置下大幅度超过之前的SOTA—BERT-flow,达到了8%的相对性能提升。
4.2 有监督实验
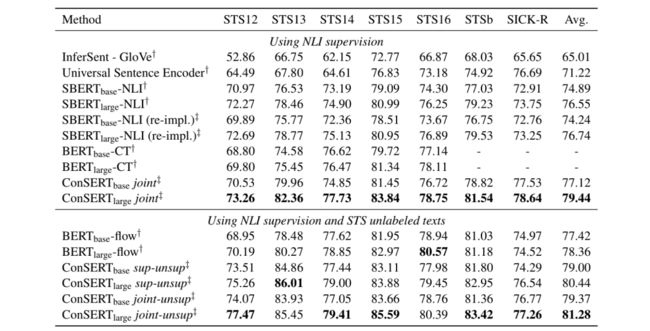
在有监督实验中,我们额外使用了来自SNLI和MNLI的训练数据,使用上面提到的融合额外监督信号的三种方法进行了实验。实验结果显示,我们的方法在“仅使用NLI有标注数据”和“使用NLI有标注数据 + STS无标注数据”的两种实验设置下均超过了基线。在三种融合监督信号的实验设置中,我们发现joint-unsup方法取得了最好的效果。
4.3 不同的数据增强方法分析
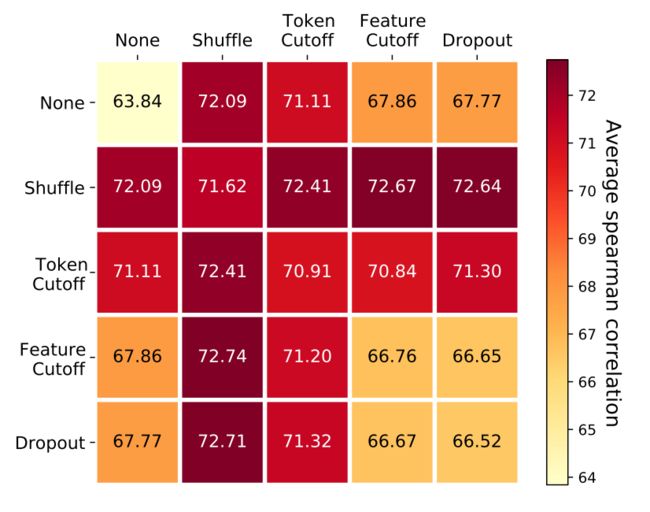
我们对不同的数据增强组合方法进行了消融分析,结果如图7所示。我们发现Token Shuffle和Feature Cutoff的组合取得了最优性能(72.74)。此外,就单种数据增强方法而言,Token Shuffle > Token Cutoff >> Feature Cutoff ≈ Dropout >> None。
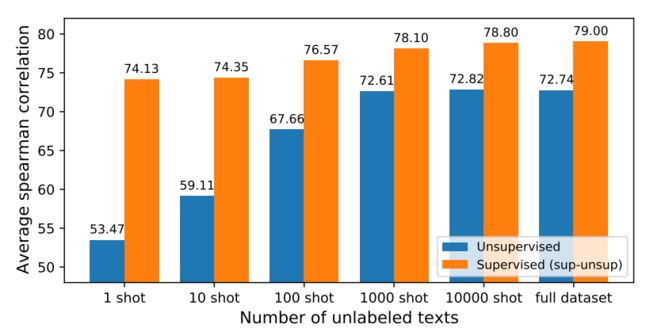
4.4 少样本设置下的实验分析
我们进一步分析了数据量(无标注文本的数目)对效果的影响,结果如图8所示。结果显示,我们的方法仅需较少的样本就能近似达到全数据量的效果;同时,在样本量很少的情况下(如100条文本的情况下)仍相比于Baseline表现出不错的性能提升。
4.5 Temperature超参的实验分析
在实验中,我们发现对比学习损失函数中的温度超参数( )对于结果有很大影响。从图9的分析实验中可以看到,当 值在0.08到0.12之间时会得到最优结果。这个现象再次证明了BERT表示的塌缩问题,因为在句子表示都很接近的情况下, 过大会使句子间相似度更平滑,编码器很难学到知识。而 如果过小,任务就太过简单,所以需要调整到一个合适的范围内。

4.6 Batch size超参的实验分析
在图像领域的对比学习中,Batch size会对结果有很大影响,因此我们也对比了不同Batch size下模型的表现。从图10可以看到两者基本是成正比的,但提升很有限。

5. 总结
在此工作中,我们分析了BERT句向量表示空间坍缩的原因,并提出了一种基于对比学习的句子表示迁移框架ConSERT。ConSERT在无监督Fine-tune和进一步融合监督信号的实验中均表现出了不错的性能;同时当收集到的样本数较少时,仍能有不错的性能提升,表现出较强的鲁棒性。
同时,在美团的业务场景下,有大量不同领域的短文本相关性计算需求,目前ConSERT已经在知识图谱构建、KBQA、搜索召回等业务场景使用。未来将会在美团更多业务上进行探索落地。目前,相关代码已经在GitHub上开源,欢迎大家使用。
参考文献
[1] Reimers, Nils, and Iryna Gurevych. "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks." Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019.
[2] Li, Bohan, et al. "On the Sentence Embeddings from Pre-trained Language Models." Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020.
[3] Gao, Jun, et al. "Representation Degeneration Problem in Training Natural Language Generation Models." International Conference on Learning Representations. 2018.
[4] Wang, Lingxiao, et al. "Improving Neural Language Generation with Spectrum Control." International Conference on Learning Representations. 2019.
[5] Conneau, Alexis, et al. "Supervised Learning of Universal Sentence Representations from Natural Language Inference Data." Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017.
[6] Cer, Daniel, et al. "Universal Sentence Encoder for English." Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2018.
[7] Wang, Shuohang, et al. "Cross-Thought for Sentence Encoder Pre-training." Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020.
[8] Yang, Ziyi, et al. "Universal Sentence Representation Learning with Conditional Masked Language Model." arXiv preprint arXiv:2012.14388 (2020).
[9] Lee, Haejun, et al. "SLM: Learning a Discourse Language Representation with Sentence Unshuffling." Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020.
[10] Su, Jianlin, et al. "Whitening sentence representations for better semantics and faster retrieval." arXiv preprint arXiv:2103.15316 (2021).
[11] Gao, Tianyu, Xingcheng Yao, and Danqi Chen. "SimCSE: Simple Contrastive Learning of Sentence Embeddings." arXiv preprint arXiv:2104.08821 (2021).
[12] Wu, Xing, et al. "Conditional bert contextual augmentation." International Conference on Computational Science. Springer, Cham, 2019.
[13] Zhou, Wangchunshu, et al. "BERT-based lexical substitution." Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019.
[14] He, Kaiming, et al. "Momentum contrast for unsupervised visual representation learning." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
[15] Chen, Ting, et al. "A simple framework for contrastive learning of visual representations." International conference on machine learning. PMLR, 2020.
[16] Zhang, Yan, et al. "An Unsupervised Sentence Embedding Method by Mutual Information Maximization." Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020.
[17] Fang, Hongchao, et al. "Cert: Contrastive self-supervised learning for language understanding." arXiv preprint arXiv:2005.12766 (2020).
[18] Carlsson, Fredrik, et al. "Semantic re-tuning with contrastive tension." International Conference on Learning Representations. 2021.
[19] Giorgi, John M., et al. "Declutr: Deep contrastive learning for unsupervised textual representations." arXiv preprint arXiv:2006.03659 (2020).
[20] Wu, Zhuofeng, et al. "CLEAR: Contrastive Learning for Sentence Representation." arXiv preprint arXiv:2012.15466(2020).
本文作者
渊蒙、如寐、思睿、富峥、武威等,美团平台/搜索与NLP部。
徐蔚然,北京邮电大学人工智能学院,模式识别实验室,副教授,博士生导师。
活动推荐

6月5日(本周六)下午14:00-17:00,美团技术沙龙《聊聊美团无人车配送的实践与挑战》,将与大家分享无人车配送团队在自动驾驶相关技术方向所遇到的挑战和研发进展。期待你的参与,点击这里报名~
阅读更多
---
前端 | 算法 | 后端 | 数据
安全 | Android | iOS | 运维 | 测试
---------- END ----------
招聘信息
美团搜索与NLP部,长期招聘算法工程师,坐标北京。欢迎感兴趣的同学发送简历至:[email protected](邮件标题注明:搜索与NLP部)
也许你还想看
| MT-BERT在文本检索任务中的实践
| BERT在美团搜索核心排序的探索和实践
| 美团BERT的探索和实践
