0. 写在前面的话
本文中的内容节选自周志华的《Ensemble Methods: Foundations and Algorithms》。感觉写的非常简洁,就翻译了一下。需要说明的是,我只是按照自己的理解翻译的,对原文感兴趣可以去搜索下载本书的pdf。
1. 线性判别分析
线性分类器由权重向量和偏置组成。给定一个样例,那么相应的预测值就是
上面的分类过程包括两步。首先,通过权重向量,样例空间被映射到一个一维空间中(也就是一条线上);然后,通过这条线的上一个点,正例和负例被划分开来。
为了找到最佳的和,一个经典线性学习算法是线性判别分析(linear discriminant analysis, LDA)。简单来说,LDA的思路是令不同类别的样例尽可能远,而同一类别的样例尽可能近;也就是不同类别的中心的距离要尽可能大,而同一类别的方差要尽可能小。
给定包含两个类别的训练集,记正例的均值为,方差为;同样地,记负例的均值为,方差为。那么投影之后,两个类别中心之间的距离为
而类内的方差为
LDA结合了二者,通过最大化
得到
在得到之后,我们很容易计算偏置。最简单的方法是,让处于投影后两个中心的中点上,也就是
当两类都服从正态分布并且方差相同时,这是最优的。
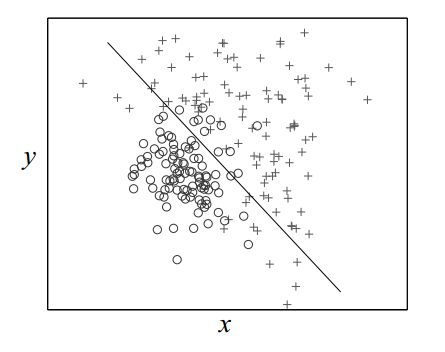
下图展示了LDA分类器的决策边界。
2. 决策树
决策树由一系列的树形结构组成,它们按照分治的思想工作。每个非叶节点都关联着一个feature test(也称为split);落在这个节点的数据将根据它们在这个特征上的值,被分成不同子集。每个叶节点则关联着一个类标记(label),这个标记将会被分配给落在这个叶节点的样例。在预测阶段,从根节点开始进行一系列的feature test,然后在叶节点处得到类别的预测结果。
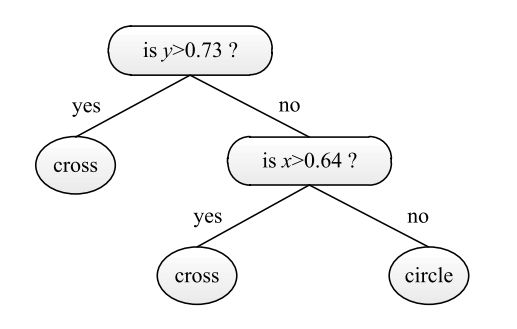
如下图,分类过程从判断y坐标的值是否大于0.73开始;如果是,那么样例被分为“cross”类,否则就判断x坐标的值是否大于0.64;如果是,样例就被分为“cross”类,否则就被归为“circle”类。
决策树的学习算法是一个递归的过程。在每一步,给定一个数据集和选择一个split,然后数据集被划分为多个子集,每个子集又重复这一步。所以说,决策树中关键的问题是如何选择splits。
ID3算法[Quinlan, 1998] 使用信息增益准则选择split。给定一个训练集,的信息熵为
如果训练集被划分为多个子集,那么信息熵会减少,减少的信息熵被称为信息增益(information gain),即
于是,可以获得最大信息增益的<特征,值>对就是split。
信息增益准则的一个问题是,那些取值较多的特征会被格外青睐,即使它们和分类的相关度不大。例如,假设在一个二分类问题中,每个样例都有一个独特的“id”,如果id被当作一个特征的话,将这个特征值作为划分属性得到的信息增益会非常之大,因此这个划分属性将把每个训练样例都划分正确;但是它不能得到泛化,因此在预测节点什么用也没有。
作为作为知名的决策树算法,C4.5 [Quinlan, 1998] 指出了信息增益准则的缺点。C4.5使用了信息增益率
这是信息增益在使用正则化之后的一个变体。实际上,使用信息增益率高的特征一般都比信息增益要好。
CART [Breiman et al., 1984] 是另一个著名的决策树算法,它使用了基尼指数(gini index)
其中
还需要提到的是,在训练阶段十分完美的决策树,会有非常糟糕的泛化能力;这被称为过拟合。过拟合可以这样理解:在训练阶段,我们学习到的是训练集本身的特性,比如收集训练集时产生的噪声,但是这些特性却被学习器认为是数据中潜在的事实。为了减少过拟合的风险,一个常用的策略就是实施剪枝(pruning)以减少由训练集的特性或者噪声带来分支。预剪枝是在建立树的时候进行剪枝,而后剪枝则是在树建立完毕之后,判断那些分支应该移除。当给定一个验证集,我们可以根据验证集上的错误率进行剪枝:在预剪枝阶段,如果新建一个分支会导致验证集上的错误率增加,那么这个分支就被取消;在后剪枝阶段,如果某个分支的移除会减少验证集上的错误率,那么就移除这个分支。
早期的决策树算法,比如ID3,只能处理类别型的特征(categorical features)。后来的,比如C4.5和CART就能够处理数值型的特征了。最简单的方式是,比较数值特征上所有可能的划分点,找一个最好的。
当决策树的告诉被限制为1,那么它将做一次判断就输出预测结果,这样的树被称为decision stump。尽管决策树一般来说是非线性分类器,decision stump则是线性分类器。
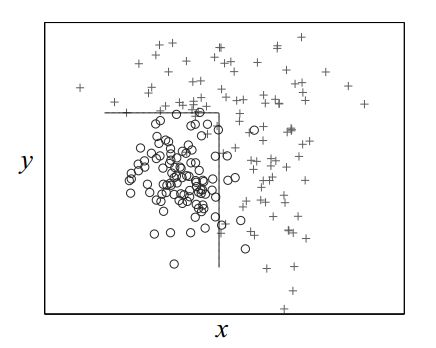
下图是一个典型决策树的决策边界。
3. 神经网络
神经网络,也被称为人工神经网络(Artificial neural networks),起源于对从生物神经网络的模拟。神经网路的函数由神经元(neuron)、神经网络的结构和学习算法决定。
神经元是神经网络的基础计算模块。最流行的神经元模型,也就是McCullochPitts模型(M-P模型),如下图(a)所示。在这个模型中,输入信号首先乘以与相应的连接权重,然后把这些信号加一起与一个阈值(也叫偏置)进行比较。如果和比偏置大,那么神经元就被激活,输出信号通过激活函数(也叫transfer function 或者 squashing function )产生。
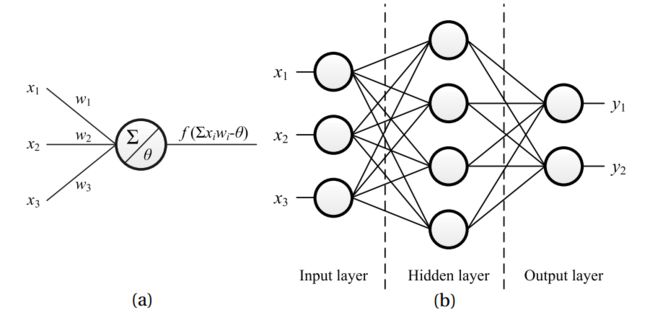
神经元通过权重连接组成一个神经网路。存在许多可能的网络结构,其中最著名的是多层前馈网络(multi-layer feed-forward network),如上图(b)所示。其中,神经元被一层一层的连接起来,没有层内连接,也没有跨层连接。网络中包含一个输入层,它接受输入的特征向量,每个神经元对应特征向量中的一个元素。输入层的激活函数通常是。网络中还存在一个输出层,它输出标记,每个神经元对应着一个可能的标记,或者一个标记向量中的元素。输入层和输出层之间的被称为隐藏层。隐藏层和输出层的神经元都是具有实际功能的神经元,它们中常用的激活函数是sigmoid函数
即使有人使用一个具有多个隐藏层的神经网络,但大部分都是使用一个或者两个隐藏层,因为一个只包含一个隐藏层的前馈神经网路足以近似所有的连续函数,并且具有多个隐藏层的网路也容易发散(divergence,就是神经网络不会收敛到一个稳定的状态)暂时还没有什么好办法去解决。
训练神经网络的目的是,为神经元得到一组合适的连接权重和偏置。一旦这些值确定了,神经网络对应的函数也就确定了。存在许多神经网络的学习算法。训练多层前馈神经网络的思想是,只要激活函数可以微分,那么整个网络就可以被视为一个可微函数,我们可以通过梯度下降来优化它。
最为成功的学习算法,反向传播(Back-Propagation, BP)[Werbos, 1974, Rumelhart et al., 1986] 是这样工作的。首先,通过输入层和隐藏层,网络的输入被前馈式的传到输出层,通过比较网络的输出和真实值,我们可以计算误差。接下来,误差将被反向传播到隐藏层和输入层,在此过程中调整连接权重和偏置以减小误差。这个过程是通过梯度调整方向来实现的。这样的过程会被重复多次,知道训练误差被最小化或者处于防止过拟合的目的,提前终止训练过程。
4. 朴素贝叶斯
为了确定测试样例的类别,一个方法是使用一个概率模型来估计不同的后验概率,然后将后验概率最大对应的作为预测值,这被称为MAP准则(maximum a posterior rule)。通过贝叶斯准则,我们可以得到
其中可以通过统计类别在训练集中的比例得到,而可以直接省略,因为我们是当相同的时,比较不同的。因此,我们需要考虑。如果我们可以准确地估计的值,我们就能够得到理论上可以从给定训练数据中得到的最优分类器,也就是贝叶斯最优分类器,它具有贝叶斯错误率,理论上的最小错误率。然而,没法直接估计,因为这涉及到指数个联合概率的估计。为了使的估计可行,需要做一些假设。
朴素贝叶斯(naive bayes)分类器假设,给定类标记时,个特征是相互独立的。因此有
这表明我们只需要估计每个特征的条件概率,而不用计算联合概率。
在训练阶段,朴素贝叶斯需要为每个类估计类先验概率,为每个特征估计条件概率。在测试阶段,一个测试样例标记的预测值将会是所有类标记中能够使下式最大的。
5. K近邻
k最近邻(nearest neighbor, kNN)算法的思路是,在输入空间中相似的样例通常在输出空间也比较相似。这是一个懒惰学习(lazy learning)方法,因为它并没有一个显式的训练过程,而是简单地将训练数据保存下来。对于一个测试样例,KNN从训练数据中找出k个与其最相似的样例。然后,对于分类任务来说,这k个样例中出现最多的类别被当作测试样例的预测结果;对于回归任务,这k个样例的平均值作为预测结果。
下图(a)展示了如何使用一个3-近邻的分类器对一个样例进行分类。图(b)展示了1-近邻分类器(也被称为最近邻分类器)的决策边界。
6. 支持向量机与核方法
支持向量机(support vector machines, SVMs)[Cristianini and Shawe-Taylor, 2000],最初是为二分类任务设计的,是large margin classifiers,这些分类器尝试通过一个具有最大间隔的超平面将不同类别的样例分隔开来。这里的间隔指的是样本集中的样例距离超平面的最小距离。
考虑一个线性分类器,或者简单表示为,我们可以使用hinge loss来评估对数据的拟合程度:
一个样例到超平面的欧几里得距离是
如果我们限制对所有训练样例有,那么到超平面的最小距离是。于是,SVMs的目标是最大化。
因此,SVMs解决的是如下的优化问题
其中C是一个参数,而是松弛变量(slack variables),引入松弛变量的目的是可以让学习器处理那些不能被完美分开的数据,比如带有噪声的数据。下图对SVMs进行了直观的阐述。

上面的式子被称为优化问题的原问题(primal form)。相应的对偶问题(dual form)如下
其中,是内积。于是,原问题的解可以表示为
并且和一个样例的内积可以这样计算
线性分类器的局限在于,当数据本来就是非线性的时候,线性分类器就没办法较好地将不同类别区分开来。在这种情况,一个常用的方法是将数据点映射到一个高维度特征空间中,这样在原本的特征空间中不可分的数据会变得线性可分。然而,学习过程也许会变得很慢,甚至不可行,因为在高维空间的内积操作会变得很难计算。
幸运的是,存在一类函数,核函数(kernel function),它能够解决这个问题。通过核函数得到特征空间被称为Reproducing Kernel Hilbert Space(RKHS)。在RKHS中的内积等价于原始低维特征空间中实例的内积的核映射。换句人话也就是,
其中,是从原始特征空间到高维度空间的映射,是核函数。因此,我们可以在对偶问题中通过核函数简化内积操作。
根据Mercer’s 定理 [Cristianini and Shawe-Taylor, 2000],每个正半对称函数都是核函数。最常见的核函数是线性核
多项式核(我个人并不能理解下面的式子,甚至认为这样写是不对的)
其中是多项式的阶,以及高斯核(也叫做RBF核)
其中是高斯宽度(Gaussian width??)的参数。
核函数的技巧,或者说,通过核函数映射数据点,然后再RKHS空间中实现学习的方法,是一个常见的策略,可以用在任何需要计算输入向量内积的学习算法中。
参考文献
- Zhou Z H. Ensemble methods: foundations and algorithms[M]. Chapman and Hall/CRC, 2012.