参考文献:https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
1.Downloader Middleware调用
1.1Downloader Middleware调用方法
DOWNLOADER_MIDDLEWARES设置中,以字典的形式进行,key是Middleware的路径,value是代表Middleware的优先级的数字。例:
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomDownloaderMiddleware': 543,
}
1.2优先级顺序介绍
process_request()是根据优先级的升序(从小到大)进行调用。
process_response()是根据优先级的降序(从大到小)进行调用。
2.Downloader Middleware内置方法
1.1process_request(request, spider)
• 返回值:None,则继续处理该request,并按顺序执行其他Middleware中的process_request()方法,直到返回response。
• 返回值:Request,停止后续(优先级更低的)Middleware中的process_request()对request进行处理,并把Request作为全新的Request返回调度队列。
• 返回值:Response,停止后续的process_request()和process_exception(),并按序调用process_response(),直到将Response返回给Spider处理。
• 返回值:IgnoreRequest,调用process_exception()处理,如果没有process_exception()处理将会调用errback()函数,若无errback()处理,则忽略。
1.2process_response(request, response, spider)
• 返回值:Response,继续处理该response,并按序执行其他Middleware中的process_response()方法.
• 返回值:Request,停止后续Middleware中的process_process()对response进行处理,并把Request作为全新的Request返回调度队列。
• 返回值:IgnoreRequest,调用errback()函数,若无errback()处理,则忽略。
1.3process_exception(request, exception, spider)
• 返回值:None,则继续处理该exception,并按顺序执行其他Middleware中的process_exception()方法。
• 返回值:Response,停止后续Middleware中的process_exception()对exception进行处理,并按序调用process_response()。
• 返回值:Request,停止后续Middleware中的process_exception()对exception进行处理,并把Request作为全新的Request返回调度队列。
3.CookiesMiddleware
3.1CookiesMiddleware介绍
保持同一次会话,类似requests包中的requests.session()方法。
3.2CookiesMiddleware使用
def parse(self, response):
for i, url in enumerate(urls):
yield scrapy.Request(url, meta={'cookiejar': i},callback=self.parse_page)
def parse_page(self, response):
# do some processing
return scrapy.Request("http://www.example.com/otherpage",
meta={'cookiejar': response.meta['cookiejar']},
callback=self.parse_other_page)
解释:抛出请求时通过给meta中的cookiejar赋值,一种标识一种会话保持,默认为一种。
4.DownloadTimeoutMiddleware
从Spider对象中获取DownloadTimeout属性,并对request.meta赋值。
5.HttpAuthMiddleware
从Spider对象中获取username和password,并检查request.headers["Authorization"]是否存在,若不存在则对其赋值。
request.headers["Authorization"] = “{}:{}”.format(username, password)
6.DefaultHeadersMiddleware
添加scrapy默认请求头
7.HttpProxyMiddleware
• 通过request.meta["proxy"]添加代理。
• 通过request.meta["Proxy-Authorization"]进行Basic认证。
8.RedirectMiddleware
• handle_httpstatus_list = [301, 302] 忽略状态码为301,302的重定向
• 可以通过request.meta查看重定向的原因。
9.MetaRefreshMiddleware
从网页中获取http-equiv属性中的重定向链接以及重定向延时,自动进行重定向。
10.RetryMiddleware
• 设置需要重试的状态码:RETRY_HTTP_CODES=[500, 502, 503, 504, 522, 524, 408]
• 默认为重试次数为retry_times=2。
• 可以通过request.meta["max_retry_times"]设置某个请求的最大重试次数。
11.RobotsTxtMiddleware
• 过滤robots协议,作用类似于setting文件中的ROBOTSTXT_OBEY
• 使用方法:request.meta["dont_obey_robotstxt"]
12.UserAgentMiddleware
给request.headers['User-Agent']属性进行赋值,通过采用random.choice()方法获取随机值。
13.HttpCompressionMiddleware
很多网站会对资源进行压缩,以加快网页响应速率。
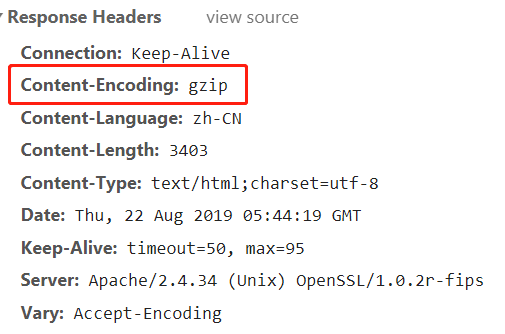
HttpCompressionMiddleware不需要在开发时进行任务操作,其底层已经封装好了,会自动获取网页压缩方式,并对其进行解压。
如果关闭HttpCompressionMiddleware,会出现乱码。

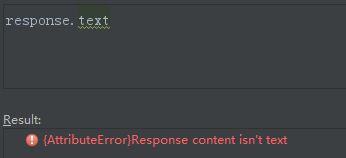
通过response.body可以看见,返回的内容是乱码。再使用response.text可以看见已经报错。