导读:
我们在帮助餐饮行业应用AI 和构建机器学习平台的项目经验中应用了OpenMLDB, 实现了线下调研结果和线上应用表现一致,证明了用AI帮助传统企业实际提高效益是切实可行的,不只是炼丹师自嗨。在此过程,我们也收获了机器学习平台的正确构建姿势,大幅降低了交付成本,缩短了交付周期。在此把过程经验和好用的工具分享给大家~~
使用场景:
某餐饮巨头(此处因为商业因素无限模糊,但各位都可以参透,对,就是那家有白胡子老头的)有大量线下门店,现在开始尝试线上流量管理工作,与其他纯线上平台不同的是,他们的线上流量管理需要与线下门店相匹配,比如:不同门店会有不同的特色菜品、不同的餐期时段、不同的季节特色,因此需要考虑全国门店的差异性,除了“人”与“货”的考量,“场”的作用显得更加重要。
- ”人“是指用户画像,例如某个用户的年龄、交易频次、最高频商品、历史订单金额等
- ”货“是指商品套餐、优惠券、会员卡等物料的画像特征,例如某个商品的主料、配料、口味、交易时段;
- ”场“是指店铺、城市甚至市场等场地的画像特征,例如:某个店铺的热销商品、平均客流量、活跃用户年龄段等
在这种业务场景下,为了做到实时推荐,线下和线上联动,支撑越来越多的推荐场景(对,持续卖更多的,AI企业就是这么难),就亟需一套能满足特征复用和共享的特征系统来提高在AI成熟度进入“规模阶段”后推荐场景的落地效率。这套系统能同时支撑特征中心的实时部分和离线部分,在这套系统的背后,我们采用了OpenMLDB 来实现实时特征和离线特征统一管理,最终在线服务根据实时特征和离线特征进行推荐召回。
在最初进行技术选型和架构设计的过程中,我们根据之前在做推荐系统的一些经验、自己趟过的坑、以及当前项目现状(做过乙方的,都知道乙方久了膝盖都不好),尽早避开了以下几个在系统建设初期就要思考的问题,所以才能完成项目的如期交付。此处我把个人经验分享给大家,欢迎大家讨论:
一致性问题:
离线和在线过程需要降低gap,保持一致。在机器学习里,我们认为一套合格的机器学习系统应该首先保障数据的正确性,模型是通过特征数据训练出来的,特征数据的处理有其内在的业务逻辑,当我们使用模型对新的行为数据进行预测时,要保证特征的处理方式与建模时的处理方式一致。如果处理方式不一致,我们就很难评估效果的变化是否只受模型的影响。
不一致原因
那,哪些地方可能会造成了不一致呢?特征处理的过程有很多个环节,可能会涉及到不同的业务系统、数据系统,任何一个环境出错都可能会导致不一致。整体的不一致问题可以分两类:
数据不一致
- 线上请求的数据与离线建模的不一致
- 冷启动时,数仓中已有数据与线上数据不一致
- 模型的预测结果和实际给用户呈现的结果不一致,由此导致新的训练样本 label 可能不一致
- 可能出现数据泄漏与数据穿越。什么叫数据泄露呢,就是本来不应该出现在X里的、和目标Y有关的数据,出现在了X中;也可能出现数据穿越,即训练模型的中使用了一些特征,而这些特征在实际用模型去做预测时所获取不到的“未来信息”。
- 一致性检查没有统一的方法
代码不一致
- 离线特征计算和在线实时特征计算逻辑不一致,实际上这两部分很可能由系统开发人员和建模科学家分别完成,往往特征工程也会维护离线/在线两套代码,很难保证处理逻辑一致
- 学习不及时 特征穿越
这个不一致问题有多严重呢,我们之前比对过一次线上线下一致性,线下auc为0.86,符合客户科学家所述的0.87左右,但线上auc却只有0.599。当然,对于线上来讲,实际上衡量auc是个比较理想主义的事,此处暂且用相同的指标姑且来看这个问题。
解决不一致问题的思路
一致性问题产生的根源,是有线上、线下两套系统,解决的思路是尽量让两套系统使用一致的处理逻辑,同时保证相同的数据输入。
对于 AI 应用,线上系统的成功运行与持续的试验迭代,比短期的效果提升要重要的多,我们需要保证线上系统的数据流能够正常工作,并基于线上的数据流来设计建模的特征处理流程。模型效果可以持续再优化和提升。
工程成本激增:
其次,场景随着项目推进在持续增加,项目交付的过程,我们不仅会搭建一套AI数据中台,而且会involve科学家的持续投入,科学家专注于发现更有效的特征,构建更复杂的模型,提升效果;但工程人员会专注让系统更稳定,更高效。随着海量特征增加,如何让双方采用统一一套语言沟通,明确互相交付边界,是项目持续发展的根基。大家title也许都有一个工程师,但各自关注的不太一样。
如上所示,不一致的语言,导致了我们上线系统中涉及到太多步骤和人员,大家各自关注点不一样,思考方式不一样,特别是在一个乙方的项目中,人员的问题也导致了成本高企,交付周期加长。例如,我们之前曾经组建过一个队伍,大家各自的角色和职责如下所示:
葫芦娃1:推荐排序算法工程师
点亮技能:Python/TensorFlow
工作职责:(除了做出好使的算法外)
和IT沟通,推动模型上线和部署
为线上推荐效果评估指标负责
葫芦娃2:数据开发工程师
点亮技能:SQL/Java
葫芦娃3:大数据开发工程师
点亮技能:Java/Spark/Hive/Spark/Kafka
葫芦娃4:后端服务器研发工程师
点亮技能:Redis/MongoDB/MySQL/Oracle/SQL Server
葫芦娃5:后端开发工程师
点亮技能:Java
葫芦娃6:运维开发工程师
点亮技能:Linux
大家从人员配置中可以猜出,整个过程中
- 工程量非常大
- 八成是需要重建客户的多个子系统,投入工程人员要多于建模人员
- 运维监控难度大
- 沟通成本激增,当人员来自多个部门时跨多部门协作,包括算法部门/业务开发部门/IT部门/运维部门,岗位职责不清晰
针对如上所叙述的两个问题,我们今天在这个项目中一早就选用了OpenMLDB来及早应对如上两个问题。下面我和大家介绍下OpenMLDB如何解决一致性问题,以及起到降低系统复杂度的。
保持数据一致和代码一致:
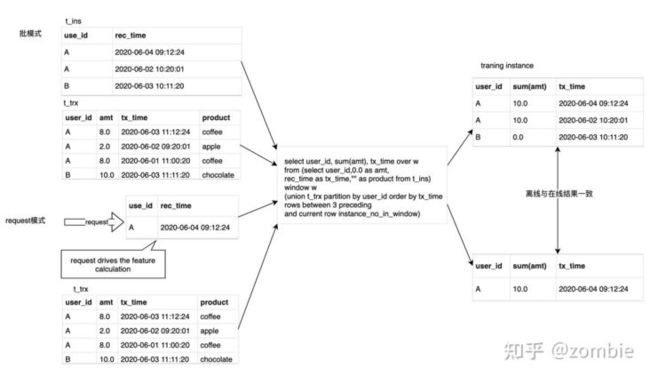
OpenMLDB通过离线在线都保持采用一套统一的SQL描述语言,但同时支持离线和在线的两种执行模式来实现数据和代码在此过程都能保持一致。两种执行模式包括:
- 批量模式,针对训练过程产生样本,类似传统数据库执行SQL
- Request模式,针对推理过程实时产生样本,只会计算与请求相关的特征
降低交付成本:
- 降低了工程人员的比例: 数据科学家的SQL特征处理逻辑能够直接丢到系统里直接使用,把sql 扔到OpenMLDB里面即可执行拿到结果做模型推理。在这个过程省去了SQL转写的步骤,降低了系统的复杂度
- 沟通成本降低:工程人员无需再理解业务,不需要细究这段SQL到底表达的是什么逻辑,在Java等语言里是如何表达的,两者逻辑是否一致,是否是业务想要的。线上效果=线下效果,这样一来,由相对较懂业务的算法同学为业务效果最终负责,工作边界变得清晰。
- 同时,由于系统复杂度降低,后端开发成本和运维成本也降低了很多。
由于以上所述原因,上面所说的七个葫芦娃,最终只剩下3个。
关于OpenMLDB
OpenMLDB是一个面向机器学习应用提供正确、高效数据供给的开源数据库。除了超过10倍的机器学习数据开发效率的提升,OpenMLDB也提供了统一的计算与存储引擎减少开发运维的复杂性与总体成本。整体架构如下

欢迎大家参与到https://github.com/4paradigm/... 社区中