pytest
成熟的全功能Python测试框架
- 简单灵活,容易上手
- 支持参数化
- 测试用例的skip与xfail,自动失败重试等处理
- 能够支持简单的单元测试和复杂的功能测试,还可以用来做selenium/appium等自动化测试、接口自动化测试(pytest+requests)
- 具有很多第三方插件,并可以自定义扩展:pytest-allure,pytest-xdist(多CPU开发)等
- 支持Jenkins集成
pytest 库安装:
pip install pytest
测试用例的识别与运行
- 对于文件的命名要求:
-
- test_*.py
- *_test.py
- 对于用例的命名要求:
-
- Test 类包含的所有 test_ 的方法(测试类不能带有 _ init_ 方法)
- 不在 class 中的所有的 test_* 方法
pytest 可以执行 unittest 框架些的用例和方法
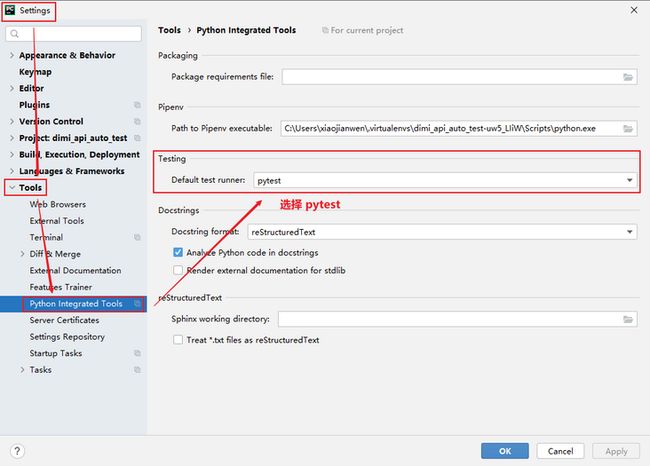
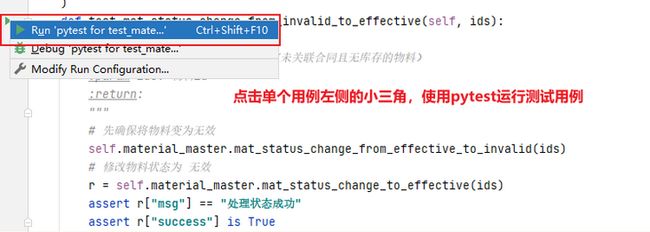
pycharm 使用 pytest 框架时,需要指定,具体操作如图所示:
命令行运行方式:
# 直接执行当前所在路径下识别到的测试用例
pytest
# 执行指定文件
pytest test_material_master.py
# 执行时打印日志
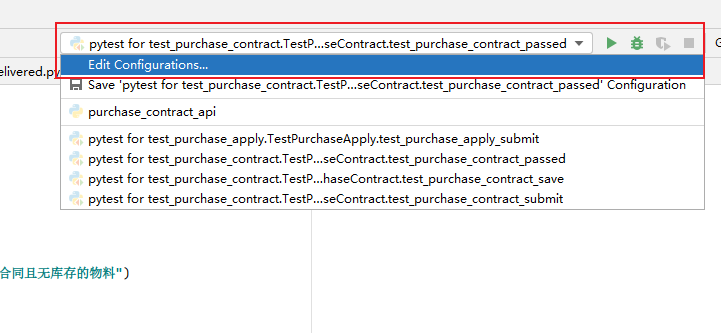
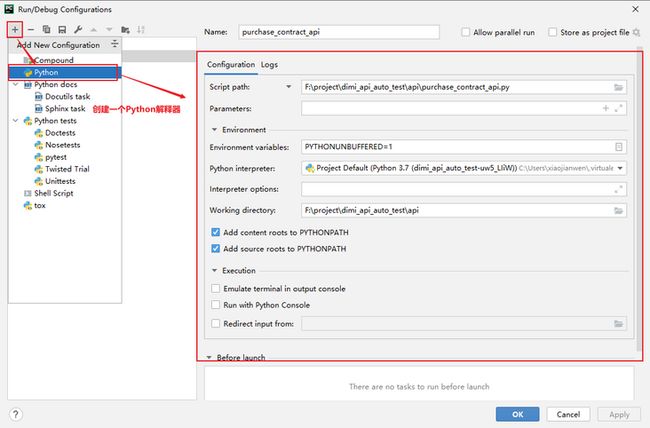
pytest -v恢复使用 Python 解释器运行的方式:
此时的运行方式为:
import pytest
if __name__ == '__main__':
pytest.main(["test_material_master.py"]) # 运行整个文件的用例
pytest.main(["test_material_master.py::TestMaterialMaster::test_mat_search_by_matCode"]) # 运行文件中指定的某条的用例参数化使用
使用方法:
# 作为装饰器
@pytest.mark.parametrize(argnames, argvalues)
# argnames:要参数化的变量;类型:可以是 str(使用逗号分割),list,tuple
# argvalues:参数化的值;类型:list,[tuple]实际应用:
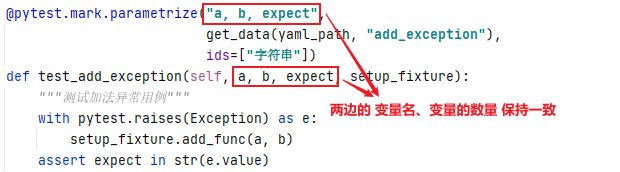
@pytest.mark.parametrize("a, b, expect",
get_data(yaml_path, "add"),
ids=["整数", "小数", "大整数"])
def test_add(self, a, b, expect, setup_fixture):
"""测试加法正向用例"""
result = setup_fixture.add_func(a, b)
assert abs(result - expect) < 0.01注意事项:
参数组合(笛卡尔积):适用于只有一个期望结果的情况
import pytest
@pytest.mark.parametrize("a", [1, 2, 3])
@pytest.mark.parametrize("b", [4, 5, 6])
def test_add(a, b):
print("参数组合 a = {}, b = {}".format(a, b))
执行结果:
PASSED [ 11%]参数组合 a = 1, b = 4
PASSED [ 22%]参数组合 a = 2, b = 4
PASSED [ 33%]参数组合 a = 3, b = 4
PASSED [ 44%]参数组合 a = 1, b = 5
PASSED [ 55%]参数组合 a = 2, b = 5
PASSED [ 66%]参数组合 a = 3, b = 5
PASSED [ 77%]参数组合 a = 1, b = 6
PASSED [ 88%]参数组合 a = 2, b = 6
PASSED [100%]参数组合 a = 3, b = 6skip
使用场景:写测试用例时,发现某个用例本身就存在 bug,而且暂时无法修复,就可以先跳过它
import pytest
@pytest.mark.skip("存在bug,先跳过")
@pytest.mark.parametrize("a", [1, 2, 3])
@pytest.mark.parametrize("b", [4, 5, 6])
def test_add(a, b):
print("参数组合 a = {}, b = {}".format(a, b))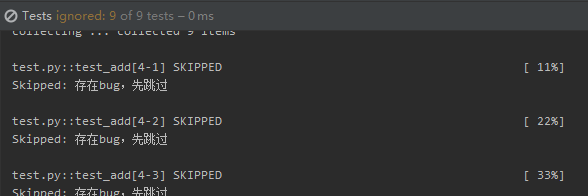
mark
使用场景: 对用例进行分类,贴标签
import pytest
@pytest.mark.test1
def test_01():
print("标记为冒烟测试用例")
@pytest.mark.test2
def test_02():
print("标记为回归测试用例")
# 只执行标记了 test1 的用例,命令行:
# pytest -s test.py -m test1
# 反选 pytest -s test.py -m "not test1"前置与后置
用例运行级别
- 模块级:开始与模块始末,全局有效;
setup_module / teardown_module - 函数级:只对函数用例生效(不在类中使用);
setup_function / teardown_function - 类级:只在类的前后运行一次(在类中使用);
setup_class / teardown_class - 方法级:开始与方法始末(在类中使用);
setup_method / teardown_method - 类中使用,运行在调用方法的前后;
setup / teardown最为常用**
fixture:自定义前置/后置
@pytest.fixture() 的优势:
- 命名方式灵活,不局限于setup / teardown
- 通过 conftest.py 配置可以实现数据共享,不需要 import 就能自动识别
scope="module"可以实现多个 .py 跨文件共享前置,每个 .py 文件调用一次scope="session"可以实现多个 .py 跨文件使用一个 session 来完成多个用例
import pytest
@pytest.fixture(scope="function") # 通过配置装饰器定义
def login_fixture():
"""登陆前置"""
print("提前登陆")
def test_01(login_fixture): # login_fixture 作为参数传入
print("测试用例 01")
def test_02():
print("测试用例 02")
执行结果:
test.py::test_01 提前登陆 PASSED [ 50%]测试用例 01
test.py::test_02 PASSED [100%]测试用例 02fixture 参数
scope:作用范围
- function:每个test都运行,默认是function的scope
- class:每个class的所有test只运行一次
- module:每个module的所有test只运行一次
- session:每个session只运行一次
autouse: 谨慎使用
- 默认为 False
- 当为 True,每个测试用例会自动调用该 fixture,无需传入 fixture 函数名
fixture中使用参数
fixture函数可以参数化,在这种情况下,它们将被多次调用,每次执行一组相关测试,即依赖于这个fixture的测试,测试函数通常不需要知道它们的重新运行
import pytest
@pytest.fixture(params=["参数1","参数2"])
def myfixture(request):
print("执行testPytest里的前置函数,%s" % request.param)fixture中返回参数
import pytest
@pytest.fixture(params=["参数1","参数2"])
def myfixture(request):
return request.param
def test_print_param(myfixture):
print("执行test_two")
print(myfixture)
assert 1==1
# 输出
PASSED [ 50%]执行test_two
参数1
PASSED [100%]执行test_two
参数2conftest.py
应用场景:
- 每个接口需共用到的token
- 每个接口需共用到的测试用例数据
- 每个接口需共用到的配置信息
使用的注意事项:
- 文件名 conftest.py 是固定的,不能修改为其他文件名
- conftest.py 文件与运行的用例要在同一个 pakage 下,并且有 __init__.py 文件
- 不需要通过 import 导入,pytest 的用例会自动识别
- 所有同目录测试文件运行前都会执行conftest.py文件
# conftest.py 文件
import pytest
@pytest.fixture()
def login():
print("登陆前置")后置操作-yield
@pytest.fixture(scope="function")
def demo_fix():
print("测试用例的前置准备操作")
yield
print("测试用例的后置操作")
def test_1(demo_fix):
print("开始执行测试用例1")
def test_2():
print("开始执行测试用例2")
def test_3(demo_fix):
print("开始执行测试用例3")如果测试用例中的代码出现异常或者断言失败,并不会影响他的固件中 yield 后的代码执行;
但是如果 fixture 中的 yield 之前的代码也就是相当于setup部分的带代码, 出现错误或断言失败,那么 yield 后的代码将不会再执行, 当然测试用例中的代码也不会执行
终结函数-addfinalizer
相当于 try...except 中的 finally
即使 setup 出现问题了,addfinalizer 仍会执行 teardown 的操作
@pytest.fixture(scope="session")
def login_xadmin_fix(request):
s = requests.session()
login_xadmin(s)
def close_s():
s.close() # 关闭s 用例完成后最后的清理
request.addfinalizer(close_s)
return s常用参数说明
- -v:可以输出用例执行的详细信息;如用例坐在的文件及用例名称
- -s:输入用例的调试信息;如 print 的打印信息
- -x:遇到失败的用例时立即停止
- -maxfail:用例失败达到一定数量时,停止运行;
pytest -maxfail=num - -m:运行含有
@pytest.mark.标记名的测试用例 - -k:执行符合匹配的测试用例测试;如
pytest -k "raises and not delete"运行所有包含 raises 但不包含 delete 的测试
pytest实用插件介绍
pytest-rerunfailures: 用例失败后自动重新运行
安装方法:
pip install pytest-rerunfailures使用方法:
pytest test_x.py --reruns=n #失败后重运行的次数同时也可以在脚本中指定定义重跑的次数,这个时候在运行的时候,就无需加上 --reruns 这个参数
@pytest.mark.flaky(reruns=6, reruns_delay=2)
def test_example(self):
print(3)
assert random.choice([True, False])pytest-assume:多重校验
pytest中的 python 的 assert 断言,也可以写多个断言,但一个失败,后面的断言将不再执行
而 pytest-assume ,即使前面的断言失败了,后续的断言也会继续执行
安装方法:
pip install pytest-assume使用方法:
def test_simple_assume(x, y):
pytest.assume(x == y)
pytest.assume(True)
pytest.assume(False)pytest-xdist:分布式并发执行
pytest-xdist 可以让自动化测试用例可以分布式执行,从而节省自动化测试时间
分布式执行用例的设计原则:
- 用例之间是独立的,用例之间没有依赖关系,用例可以完全独立运行【独立运行】
- 用例执行没有顺序,随机顺序都能正常执行【随机执行】
- 每个用例都能重复运行,运行结果不会影响其他用例【不影响其他用例】
安装方法:
pip install pytest-xdist使用方法:
多 CPU 并行执行用例,直接加个 -n 参数即可,后面 num 参数就是并行数量,比如 num 设置为 3
pytest -n 3pytest-ordering:控制用例的执行顺序
安装方法:
pip install pytest-ordering使用方法:
import pytest
@pytest.mark.run(order=2)
def test_foo():
assert True
@pytest.mark.run(order=1)
def test_bar():
assert TruePS: 尽量不要让测试用例有顺序,尽量不要让测试用例有依赖!
hook(钩子)函数定制和扩展插件
Pytest在收集完所有测试用例后调用该钩子方法。我们可以定制化功能实现:
- 自定义用例执行顺序
- 解决编码问题(中文测试用例名称)
- 自动添加标签
建议将 hook 函数的代码写在 conftest.py 文件中
# conftest.py
from typing import List
def pytest_collection_modifyitems(
session: "Session", config: "Config", items: List["Item"]
) -> None:
for item in items:
item.name = item.name.encode("utf-8").decode("unicode-escape")
item._nodeid = item.nodeid.encode("utf-8").decode("unicode-escape")