协程是更轻量的用户态线程,是Go语言的核心。那么如何去调度这些协程何时去执行、如何更合理的分配操作系统资源,需要一个设计良好的调度器来支持。
什么才是一个好的调度器?能在适当的时机将合适的协程分配到合适的位置,保证公平和效率。
从go func说起
func main() {
for i := 0; i < 10; i++ {
go func() {
fmt.Println(i)
}()
}
time.Sleep(1 * time.Second)
}这段代码中,我们开启了10个协程,每个协程打印去打印i这个变量。由于这10个协程的调度时机并不固定,所以等到协程被调度执行的时候才会去取循环中变量i的值。
我们写的这段代码,每个我们开启的协程都是一个计算任务,这些任务会被提交给go的runtime。如果计算任务非常多,有成千上万个,那么这些任务是不可能同时被立刻执行的,所以这个计算任务一定会被先暂存起来,一般的做法是放到内存的队列中等待被执行。
而消费端则是一个go runtime维护的一个调度循环。调度循环简单来说,就是不断从队列中消费计算任务并执行。这里本质上就是一个生产者-消费者模型,实现了用户任务与调度器的解耦。
这里图中的G就代表我们的一个goroutine计算任务,M就代表操作系统线程
调度策略
接下来我们详细讲解一下调度策略。
生产端
生产端1.0
接上面的例子,我们生产了10个计算任务,我们一定是要在内存中先把它存起来等待调度器去消费的。那么很显然,最合适的数据结构就是队列,先来先服务。但是这样做是有问题的。现在我们都是多核多线程模型,消费者肯定不止有一个,所以如果多个消费者去消费同一个队列,会出现线程安全的问题,必须加锁。所有计算任务G都必须在M上来执行。
生产端2.0
在Go中,为了解决加锁的问题,将全局队列拆成了多个本地队列,而这个本地队列由一个叫做P的结构来管理。
这样一来,每个M只需要去先找到一个P结构,和P结构绑定,然后执行P本地队列里的G即可,完美的解决了加锁的问题。
但是每个P的本地队列长度不可能无限长(目前为256),想象一下有成千上万个go routine的场景,这样很可能导致本地队列无法容纳这么多的Goroutine,所以Go保留了全局队列,用以处理上述情况。
那么为什么本地队列是数组,而全局队列是链表呢?由于全局队列是本地队列的兜底策略,所以全局队列大小必须是无限的,所以必须是一个链表。
全局队列被分配在全局的调度器结构上,只有一份:
type schedt struct {
...
// Global runnable queue.
runq gQueue // 全局队列
runqsize int32 // 全局队列大小
...
}那么本地队列为什么做成数组而不是链表呢?因为操作系统内存管理会将连续的存储空间提前读入缓存(局部性原理),所以数组往往会被都读入到缓存中,对缓存友好,效率较高;而链表由于在内存中分布是分散的,往往不会都读入到缓存中,效率较低。所以本地队列综合考虑性能与扩展性,还是选择了数组作为最终实现。
而Go又为了实现局部性原理,在P中又加了一个runnext的结构,这个结构大小为1,在runnext中的G永远会被最先调度执行。接下来会讲为什么需要这个runnext结构。完整的生产端数据结构如下:
P结构的定义:
type p struct {
...
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32 // 本地队列队头
runqtail uint32 // 本地队列队尾
runq [256]guintptr // 本地队列,大小256
runnext guintptr // runnext,大小为1
...
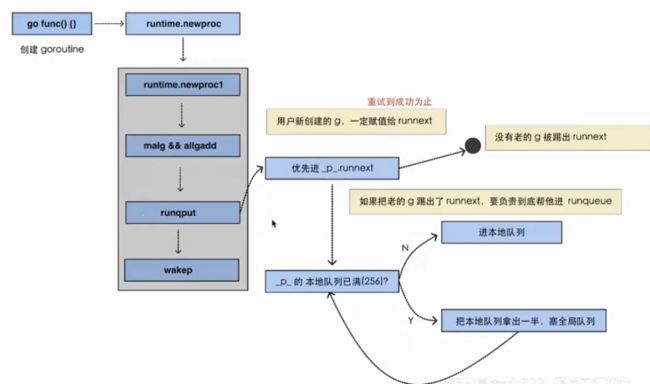
}完整的生产流程
- 我们执行go func的时候,主线程m0会调用newproc()生成一个G结构体,这里会先选定当前m0上的P结构
- 每个协程G都会被尝试先放到P中的runnext,若runnext为空则放到runnext中,生产结束
- 若runnext满,则将原来runnext中的G踢到本地队列中,将当前G放到runnext中。生产结束
- 若本地队列也满了,则将本地队列中的G拿出一半,加上当前协程G,这个拼成的结构在源码中叫batch,会将batch一起放到全局队列中,生产结束。这样一来本地队列的空间就不会满了,接下来的生产流程不会被本地队列满而阻塞
所以我们看到,最终runnext中的G一定是最后生产出来的G,也会被优先被调度去执行。这里是考虑到局部性原理,最近创建出来的协程一定会被最先执行,优先级是最高的。
runqput的逻辑:
func runqput(_p_ *p, gp *g, next bool) {
// 先尝试放到runnext中
if randomizeScheduler && next && fastrand()%2 == 0 {
next = false
}
if next {
retryNext:
// 拿到老的runnext值。
oldnext := _p_.runnext
// 交换当前runnext的老的G和当前G的地址,相当于将当前G放入了runnext
if !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
// 老的runnext为空,生产结束
if oldnext == 0 {
return
}
// 老的runnext不空,则将被替换掉的runnext赋值给gp,然后下面会set到本地队列的尾部
gp = oldnext.ptr()
}
retry:
// 尝试放到本地队列
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumers
t := _p_.runqtail
// 本地队列没有满,那么set进去
if t-h < uint32(len(_p_.runq)) {
_p_.runq[t%uint32(len(_p_.runq))].set(gp)
atomic.StoreRel(&_p_.runqtail, t+1) // store-release, makes the item available for consumption
return
}
// 如果本地队列不满刚才会直接return;若已满会走到这里,会将本地队列的一半G放到全局队列中
if runqputslow(_p_, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
goto retry
}消费端
消费端就是一个调度循环,不断的从本地队列和全局队列消费G、给G绑定一个M、执行G,然后再次消费G、给G绑定一个M、执行G...那么执行这个调度循环的人是谁呢?答案是g0,每个M上,都有一个g0,控制自己线程上面的调度循环:
type m struct {
g0 *g // goroutine with scheduling stack
...
}g0是一个特殊的协程。为了给接下来M执行计算任务G做准备,g0需要先帮忙获取一个线程M,根据随机算法给M绑定一个P,让P上的计算任务G得到执行,然后正式进入调度循环。整体的调度循环分为四个步骤:
- schedule:g0来执行,处理具体的调度策略,如从P的runnext/本地或者全局队列中获取一个G,然后会调用execute()
- execute:把G和M绑定,初始化一些字段,调用gogo()
- gogo:和操作系统架构相关,会将待执行的G调度到线程M上来执行,完成栈的切换
- goexit:执行一些清理逻辑,并调用schedule()重新开始一轮调度循环

即每次调度循环,都会完成g0 -> G -> g0的上下文切换。
schedule
schedule是调度循环的核心。由于P中的G分布在runnext、本地队列和全局队列中,则需要挨个判断是否有可执行的G,大体逻辑如下:
- 先到P上的runnext看一下是否有G,若有则直接返回
- runnext为空,则去本地队列中查找,找到了则直接返回
- 本地队列为空,则去阻塞的去全局队列、网路轮询器、以及其他P中查找,一直阻塞直到获取到一个可用的G为止
源码实现如下:
func schedule() {
_g_ := getg()
var gp *g
var inheritTime bool
...
if gp == nil {
// 每执行61次调度循环会看一下全局队列。为了保证公平,避免全局队列一直无法得到执行的情况,当全局运行队列中有待执行的G时,通过schedtick保证有一定几率会从全局的运行队列中查找对应的Goroutine;
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil {
// 先尝试从P的runnext和本地队列查找G
gp, inheritTime = runqget(_g_.m.p.ptr())
}
if gp == nil {
// 仍找不到,去全局队列中查找。还找不到,要去网络轮询器中查找是否有G等待运行;仍找不到,则尝试从其他P中窃取G来执行。
gp, inheritTime = findrunnable() // blocks until work is available
// 这个函数是阻塞的,执行到这里一定会获取到一个可执行的G
}
...
// 调用execute,继续调度循环
execute(gp, inheritTime)
}其中schedtick这里,每执行61次的调度循环,就需要去全局队列尝试获取一次。为什么要这样做呢?假设有十万个G源源不断的加入到P的本地队列中,那么全局队列中的G可能永远得不到执行被饿死,所以必须要在从本地队列获取之前有一个判断逻辑,定期从全局队列获取G以保证公平。
与此同时,调度器会将全局队列中的一半G都拿过来,放到当前P的本地队列中。这样做的目的是,如果下次调度循环到来的时候,就不必去加锁到全局队列中在获取一次G了,性能得到了很好的保障。
这里去其他P中查找可用G的逻辑也叫work stealing,即工作窃取。这里也是会使用随机算法,随机选择一个P,偷取该P中一半的G放入当前P的本地队列,然后取本地队列尾部的一个G拿来执行。
GMP模型
到这里相信大家已经了解了GMP的概念,我们最终来总结一下:
- G:goroutine,代表一个计算任务,由代码和上下文(如当前代码执行的位置、栈信息、状态等)组成
- M:machine,系统线程,想要在CPU上执行代码必须有线程,通过系统调用clone创建
- P:processor,虚拟处理器。M必须获得P才能执行P队列中的G代码,否则会陷入休眠
阻塞处理
以上只是假设G正常执行的情况。如果G存在阻塞等待(如channel、系统调用)等,那么需要将此时此刻的M与P上的G进行解绑,让M执行其他P上的G,从而最大化提升CPU利用率。以及从系统调用中陷入、恢复需要触发调度器调度的时机,这部分逻辑会在下一篇文章中做出讲解。
关注我们
欢迎对本系列文章感兴趣的读者订阅我们的公众号,关注博主下次不迷路~