复现 Mlp-Mixer(pytorch and keras)
文章目录
- 前言
- 一、mlp-mixer原理介绍
-
- 1.网络结构
- 2. MixerLayer
- 3.MLP-Mixer模型类型
- 二、网络实现
-
- 1.pytorch复现
- 2.keras 复现
- 总结
前言
mlp-mixer,Google又提出的一种基于感知机的网络。尽管CNN 已经在计算机视觉上取得很好的效果,最近提出来的基于Attention,以Vision Transformer 为首的神经网络已经 “杀疯” CV界,但是Google的大佬们认为CNN 和Attention 也不是必须的,于是就提出了mlp-mixer,在分类任务上也达到了很好的效果。但是网络的提出却早到了CNN之父LeCun的“教育”。因为网络的第一层(embedding时)却用到了卷积。

LeCun认为,这不过是 一个卷积核为1x1的卷积网络罢了。我在复现过程中,没有找到一个合适的数据集用该网络取得一个很好的效果。所以这里不附上训练的代码了。
| 项目 | 链接 |
|---|---|
| 论文 | 链接 |
博客中给出的就是网络结构的全部代码。
一、mlp-mixer原理介绍
1.网络结构
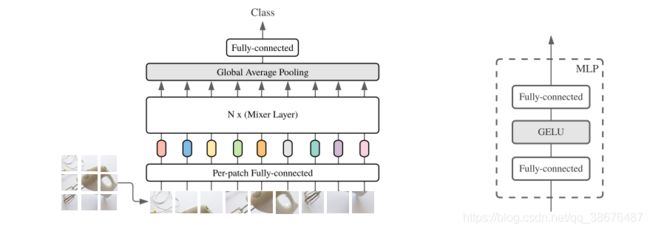
从上图我们可以看出,mlp-mixer 首先使用图片分成很多个小正方形的patch,每个patch的大小定义为patch_size。论文中实现这一步骤使用的是前面提到的卷积,卷积核的大小和步长均patch_size。至于卷积核的输出通道数,就是自己拍一拍脑袋就决定了,例如512 768 1024等。
网络不再使用传统的RELU激活函数,而是使用了GELU激活函数。
将图片分成小块后,在将它转换为一维结构。如图:

然后将每一个patch进行转换,如下图所示:
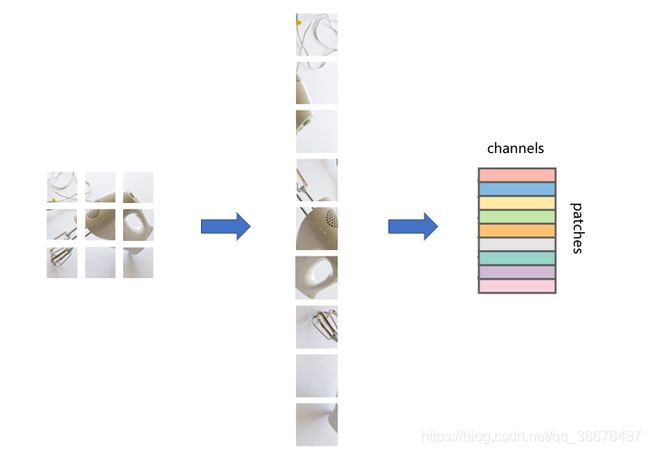
通过这样一种方式呢,就将一张图片转换为了一个大矩阵,就可以输入到MixerLayer 中进行计算啦。
2. MixerLayer
MixerLayer的结构如下图所示:

我们看一下论文里给出的公示:

MLP 是两个全连接层的感知机,W1,W2,对应token_mixer中两个全连接的权重,W3,W4则表示channel_mixer两个全连接的权重。σ表示GELU激活函数。那么公示就很简单了,输入X经过LN,再乘以W1,再经过激活函数后乘以W2,再加上X。第二个公式也是相同的计算过程。
大佬们都喜欢吧简单的问题复杂化吗?
将前面通过编码得到的矩阵经过Layer Norm 在将矩阵进行旋转(T 表示旋转)连接MLP1,MLP1 就是文章token_mixer 用来寻找像素与像素之间的关系,其中,MLP1中的权值共享。计算完之后,再将矩阵旋转回来,通过Layer Norm 后再接一个channel_mixer 用于寻找通道与通道之间的关系。其中MixerLayer 还启用了ResNet中的跨连结构,跨连结构的作用可以参考[优雅的复现ResNet50],看到这里,是不是感觉它跟卷积的原理很类似。
从上图可以看出MixerLayer的输入维度和输出维度相同,并且通过MLP的方式来寻找图片像素与像素,通道与通道的关系。
这就是MLP-MIXER的网络结构了,目前的了解,没有开源的pytorch或者TensorFlow 预训练的权重。官方给出的代码和权重是基于JAX的。
谁找到了权重 给我说一下 嘤嘤嘤~~~
3.MLP-Mixer模型类型

文章中给出的模型参数列表,Patch resolution 就是patch 的长宽。Hidden size 就是映射成前面提到的大矩阵的维度,Squence length 是计算后的结果。
以上图红色部分为例,输入图像大小为224*224,
然后分成的块大小为32*32.
那么 (224*224)\(32*32)=7*7,Squence length 就为 49。Dc和Ds分别表示token_mixer和channel_mixer 中全连接层节点的个数。
这就是MLP-Mixer的全部过程了。
二、网络实现
1.pytorch复现
实现的难点在于,矩阵旋转,我们使用einops中的Rearrange实现矩阵旋转。还需要使用torchsummary 来查看网络结构。安装:
pip install einops
pip install torchsummary
首先我们来实现MLP 也就是FeedForward:
#定义多层感知机
class FeedForward(nn.Module):
def __init__(self,dim,hidden_dim,dropout=0.):
super().__init__()
self.net=nn.Sequential(
#由此可以看出 FeedForward 的输入和输出维度是一致的
nn.Linear(dim,hidden_dim),
#激活函数
nn.GELU(),
#防止过拟合
nn.Dropout(dropout),
#重复上述过程
nn.Linear(hidden_dim,dim),
nn.Dropout(dropout)
)
def forward(self,x):
x=self.net(x)
return x
#测试多层感知机
# mlp=FeedForward(10,20,0.4).to(device)
# summary(mlp,input_size=(10,))
实现过程很简单,就是全连接结构
接着我们来实现Mixer Block,里面包含了 token_mixer 和channel_mixer,还有矩阵转置。
#使用Rearrange 实现旋转
Rearrange('b n d -> b d n') #这里是[batch_size, num_patch, dim] -> [batch_size, dim, num_patch]
实现如下:
class MixerBlock(nn.Module):
def __init__(self,dim,num_patch,token_dim,channel_dim,dropout=0.):
super().__init__()
self.token_mixer=nn.Sequential(
nn.LayerNorm(dim),
Rearrange('b n d -> b d n'),
FeedForward(num_patch,token_dim,dropout),
Rearrange('b d n -> b n d')
)
self.channel_mixer=nn.Sequential(
nn.LayerNorm(dim),
FeedForward(dim,channel_dim,dropout)
)
def forward(self,x):
x=x+self.token_mixer(x)
x=x+self.channel_mixer(x)
return x
#测试mixerblock
# x=torch.randn(1,196,512)
# mixer_block=MixerBlock(512,196,32,32)
# x=mixer_block(x)
# print(x.shape)
更具上述定义好的网络零件,就可以实现我们最终的主网络mlp-mixer:
class MLPMixer(nn.Module):
def __init__(self,in_channels,dim,num_classes,patch_size,image_size,depth,token_dim,channel_dim,dropout=0.):
super().__init__()
assert image_size%patch_size==0
self.num_patches=(image_size//patch_size)**2
#embedding 操作,看见没用卷积来分成一小块一小块的
self.to_embedding=nn.Sequential( Conv2d(in_channels=in_channels,out_channels=dim,kernel_size=patch_size,stride=patch_size),
Rearrange('b c h w -> b (h w) c')
)
self.mixer_blocks=nn.ModuleList([])
for _ in range(depth):
self.mixer_blocks.append(MixerBlock(dim,self.num_patches,token_dim,channel_dim,dropout))
self.layer_normal=nn.LayerNorm(dim)
self.mlp_head=nn.Sequential(
nn.Linear(dim,num_classes)
)
def forward(self,x):
x=self.to_embedding(x)
for mixer_block in self.mixer_blocks:
x=mixer_block(x)
x=self.layer_normal(x)
x=x.mean(dim=1)
x=self.mlp_head(x)
return x
#测试Mlp-Mixer
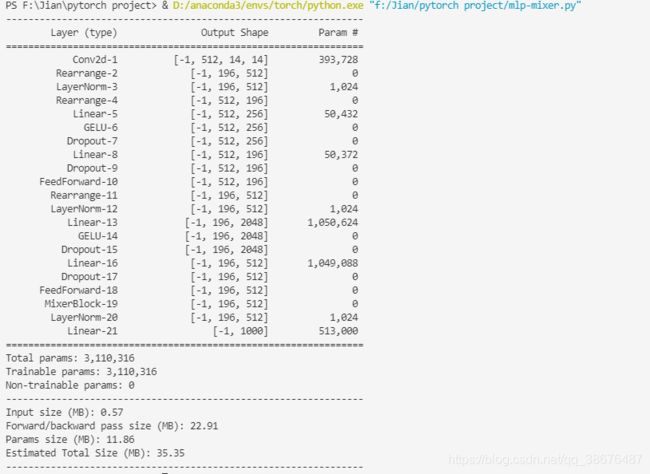
if __name__ == '__main__':
model = MLPMixer(in_channels=3, dim=512, num_classes=1000, patch_size=16, image_size=224, depth=1, token_dim=256,
channel_dim=2048).to(device)
summary(model,(3,224,224))
depth=1,网络深度等于1 这样方便我们看整体结构,最后的运行结果:
2.keras 复现
keras的复现过程与pytorch类似,但有几个注意的地方,网络中使用的GELU 激活函数在tensorflow>=2.4才可以使用,conda 国内镜像很难安装tensorflow 2.4 以上的GPU 版本。如果要使用的话tensorflow2.4一下版本的话,自定义GELU激活函数如下:
def gelu(x):
cdf = 0.5 * (1.0 + tf.tanh(
(np.sqrt(2 / np.pi) * (x + 0.044715 * tf.pow(x, 3)))))
return x * cdf
在keras中使用类的方法定义自己的网络层时,需要重写 get_config 函数 不然模型无法保存。keras中借助Permute 层实现转置。
keras的完整实现如下:
from tensorflow import keras
import tensorflow as tf
import numpy as np
from keras import backend as K
from tensorflow.keras.layers import (
Add,
Dense,
Conv2D,
GlobalAveragePooling1D,
Flatten,
Layer,
LayerNormalization,
Permute,
Softmax,
Activation,
)
class MlpBlock(Layer):
def __init__(
self,
dim: int,
hidden_dim: int,
activation=None,
**kwargs
):
super(MlpBlock, self).__init__(**kwargs)
if activation is None:
activation = keras.activations.gelu
self.dim = dim
self.hidden_dim = dim
self.dense1 = Dense(hidden_dim)
self.activation = Activation(activation)
self.dense2 = Dense(dim)
def call(self, inputs):
x = inputs
x = self.dense1(x)
x = self.activation(x)
x = self.dense2(x)
return x
def compute_output_shape(self, input_signature):
return (input_signature[0], self.dim)
def get_config(self):
config = super(MlpBlock, self).get_config()
config.update({
'dim': self.dim,
'hidden_dim': self.hidden_dim
})
return config
class MixerBlock(Layer):
def __init__(
self,
num_patches: int,
channel_dim: int,
token_mixer_hidden_dim: int,
channel_mixer_hidden_dim: int = None,
activation=None,
**kwargs
):
super(MixerBlock, self).__init__(**kwargs)
self.num_patches = num_patches
self.channel_dim = channel_dim
self.token_mixer_hidden_dim = token_mixer_hidden_dim
self.channel_mixer_hidden_dim = channel_mixer_hidden_dim
self.activation = activation
if activation is None:
self.activation = keras.activations.gelu
if channel_mixer_hidden_dim is None:
channel_mixer_hidden_dim = token_mixer_hidden_dim
self.norm1 = LayerNormalization(axis=1)
self.permute1 = Permute((2, 1))
self.token_mixer = MlpBlock(num_patches, token_mixer_hidden_dim, name='token_mixer')
self.permute2 = Permute((2, 1))
self.norm2 = LayerNormalization(axis=1)
self.channel_mixer = MlpBlock(channel_dim, channel_mixer_hidden_dim, name='channel_mixer')
self.skip_connection1 = Add()
self.skip_connection2 = Add()
def call(self, inputs):
x = inputs
skip_x = x
x = self.norm1(x)
x = self.permute1(x)
x = self.token_mixer(x)
x = self.permute2(x)
x = self.skip_connection1([x, skip_x])
skip_x = x
x = self.norm2(x)
x = self.channel_mixer(x)
x = self.skip_connection2([x, skip_x]) # TODO need 2?
return x
def compute_output_shape(self, input_shape):
return input_shape
def get_config(self):
config = super(MixerBlock, self).get_config()
config.update({
'num_patches': self.num_patches,
'channel_dim': self.channel_dim,
'token_mixer_hidden_dim': self.token_mixer_hidden_dim,
'channel_mixer_hidden_dim': self.channel_mixer_hidden_dim,
'activation': self.activation,
})
return config
def MlpMixerModel(
input_shape: int,
num_classes: int,
num_blocks: int,
patch_size: int,
hidden_dim: int,
tokens_mlp_dim: int,
channels_mlp_dim: int = None,
use_softmax: bool = False,
):
height, width, _ = input_shape
if channels_mlp_dim is None:
channels_mlp_dim = tokens_mlp_dim
num_patches = (height*width)//(patch_size**2) # TODO verify how this behaves with same padding
inputs = keras.Input(input_shape)
x = inputs
x = Conv2D(hidden_dim,
kernel_size=patch_size,
strides=patch_size,
padding='same',
name='projector')(x)
x = keras.layers.Reshape([-1, hidden_dim])(x)
for _ in range(num_blocks):
x = MixerBlock(num_patches=num_patches,
channel_dim=hidden_dim,
token_mixer_hidden_dim=tokens_mlp_dim,
channel_mixer_hidden_dim=channels_mlp_dim)(x)
x = Flatten()(x) # TODO verify this global average pool is correct choice here
x = LayerNormalization(name='pre_head_layer_norm')(x)
x = Dense(num_classes, name='head')(x)
if use_softmax:
x = Softmax()(x)
return keras.Model(inputs, x)
- keras 配置训练代码:
训练过程参数可以自行调试:
#学习率调试,首先我们设置一个较小的学习率 查看loss的变化情况 使用Tensorboard记录下来
import tensorflow as tf
from keras_preprocessing.image import ImageDataGenerator
from tensorflow.python.keras.callbacks import ModelCheckpoint
from tensorflow.keras.callbacks import (EarlyStopping, ReduceLROnPlateau,
TensorBoard)
from tensorflow.keras.optimizers import Adam
def train():
log_dir = './log' #训练日志路劲
train_dataset_path=r"your_tarin_data_path" #分类训练数据集路径
test_dataset_path=r"your_test_data_path" #分类测试集路径
batch_size = 64
# 加载数据集
lr= 1e-3
epochs=20
num_classes=1000 #你的分类数
train_datagen = ImageDataGenerator( #数据集增强,这些参数查阅keras 官方文档 我前面的博客VGG 中 说明过也有介绍说
rescale=1 / 255.0,
rotation_range=20,
zoom_range=0.05,
width_shift_range=0.05,
height_shift_range=0.05,
shear_range=0.05,
horizontal_flip=True,
fill_mode="nearest",
)
train_generator = train_datagen.flow_from_directory(
directory=train_dataset_path,
target_size=(224, 224),
color_mode="rgb",
batch_size=batch_size,
class_mode="categorical",
shuffle=True,
seed=42
)
test_datagen = ImageDataGenerator(
rescale=1 / 255.0,)
valid_generator = test_datagen.flow_from_directory(
directory=test_dataset_path,
target_size=(224, 224),
color_mode="rgb",
batch_size=batch_size,
shuffle=True,
seed=42
)
#你的模型,模型参数自己调试
mlp_mixer_base = MlpMixerModel(input_shape=(224, 224, 3),
num_classes=num_classes,
num_blocks=2,
patch_size=16,
hidden_dim=64,
tokens_mlp_dim=32,
channels_mlp_dim=64,
use_softmax=True)
mlp_mixer_base.summary()
# training_weights='./weights' #这里是保存每次训练权重的 如果需要自己取消注释
# checkpoint_period = ModelCheckpoint(training_weights + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
# monitor='val_loss', save_weights_only=True, save_best_only=False, period=3)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=4, verbose=1) #学习率衰减
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1) # val_loss 不下降时 停止训练 防止过拟合
tensorboard = TensorBoard(log_dir=log_dir) #训练日志
optimizer=tf.keras.optimizers.Adam(learning_rate=lr)
mlp_mixer_base.compile(loss=tf.keras.losses.categorical_crossentropy, metrics='acc',optimizer=optimizer)
mlp_mixer_base.fit(train_generator,validation_data=valid_generator,
epochs=epochs,callbacks=[tensorboard, reduce_lr, early_stopping]
)
mlp_mixer_base.evaluate(valid_generator,verbose=1)
mlp_mixer_base.save('./mlp_mixer_base.h5')
if __name__ == '__main__':
train()
总结
代码复现过程,参考了论文地址给出的GitHub的链接,自己手撕代码的能力还是比较弱,不足之处就是没有使用数据集去训练它并达到一个不错的效果。后续如果有结果,会更新这篇博客,在训练模型时,调参过程是真的累,应该还是缺少理论知识的原因。后续会学习如何进行调参。
创作不易,点赞鼓励。
最后说一句,pytorch真香~~~~~~,前面的博客LeNet ,AlexNet和VGG已添加pytorch实现。