目标检测干货 | 多级特征重复使用大幅度提升检测精度(文末附论文下载)
计算机视觉研究院专栏
作者:Edison_G
近年来,在利用深度卷积网络检测目标方面取得了显著进展。然而,很少有目标检测器实现高精度和低计算成本。

公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
一、简要
近年来,在利用深度卷积网络检测目标方面取得了显著进展。然而,很少有目标检测器实现高精度和低计算成本。今天分享的干货,就有研究者提出了一种新的轻量级框架,即多级特性重用检测器(MFRDet),它可以比两阶段的方法达到更好的精度。它还可以保持单阶段方法的高效率,而且不使用非常深的卷积神经网络。该框架适用于深度和浅层特征图中包含的信息的重复利用,具有较高的检测精度。
二、背景

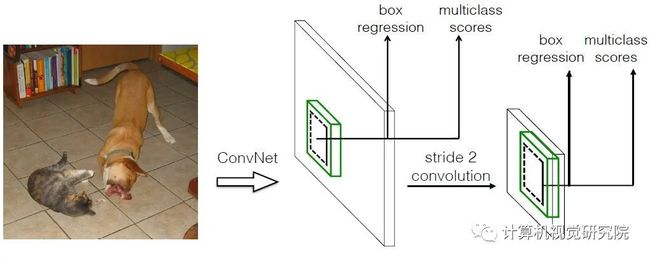
(a)仅使用单尺度特征进行预测,(b)整合来自高级和低级特征图的信息,(c)从不同尺度的特征图生成预测,(d)就是今天分享的多层特征重用模块可以获得不同尺度的特征图。
Shot learning
在深度学习领域,特别是目标检测领域,数据集的建设是至关重要的。进行了许多优秀和有价值的研究,改进了多元数据集的理论和实践。有研究者创建了一种有效的从Web学习方法来解决问题的数据集偏差,没有手动注释。这可能提供了一种帮助zero-shot学习的方法。zero-shot学习研究的主要问题是目标分类问题和目标检测问题。目前,在zero-shot学习中仍存在一些需要解决的问题,如domain shift problem, hubness problem和semantic gap问题。zero-shot学习通常将视觉特征嵌入其他模态空间,或将多个模型空间映射到一个共同的潜在空间,使用最近邻思想对看不见目标进行分类,这对目标检测器有很高的需求。
One-shot学习的目的是从一个或只有少数的训练图像中学习有关目标类别的信息。与zero-shot学习不同,One-shot学习依赖于先验知识,比如物体识别,它需要对形状和外观的先验知识。
三、新框架
SSD分析

SSD和Yolo一样都是采用一个CNN网络来进行检测,但是却采用了多尺度的特征图,其基本架构如下图所示。下面将SSD核心设计理念总结为以下三点:
 SSD基本框架
SSD基本框架
(1)采用多尺度特征图用于检测
所谓多尺度采用大小不同的特征图,CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小,这正如上图所示,一个比较大的特征图和一个比较小的特征图,它们都用来做检测。这样做的好处是比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标,如下图所示,8x8的特征图可以划分更多的单元,但是其每个单元的先验框尺度比较小。
 不同尺度的特征图
不同尺度的特征图
(2)采用卷积进行检测
与Yolo最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为 的特征图,只需要采用 这样比较小的卷积核得到检测值。
(3)设置先验框
在Yolo中,每个单元预测多个边界框,但是其都是相对这个单元本身(正方块),但是真实目标的形状是多变的,Yolo需要在训练过程中自适应目标的形状。而SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少训练难度。一般情况下,每个单元会设置多个先验框,其尺度和长宽比存在差异,如图5所示,可以看到每个单元使用了4个不同的先验框,图片中猫和狗分别采用最适合它们形状的先验框来进行训练,后面会详细讲解训练过程中的先验框匹配原则。
 SSD的先验框
SSD的先验框
SSD的检测值也与Yolo不太一样。对于每个单元的每个先验框,其都输出一套独立的检测值,对应一个边界框,主要分为两个部分。第一部分是各个类别的置信度或者评分,值得注意的是SSD将背景也当做了一个特殊的类别,如果检测目标共有 个类别,SSD其实需要预测 个置信度值,其中第一个置信度指的是不含目标或者属于背景的评分。后面当我们说 个类别置信度时,请记住里面包含背景那个特殊的类别,即真实的检测类别只有 个。在预测过程中,置信度最高的那个类别就是边界框所属的类别,特别地,当第一个置信度值最高时,表示边界框中并不包含目标。第二部分就是边界框的location,包含4个值 ,分别表示边界框的中心坐标以及宽高。但是真实预测值其实只是边界框相对于先验框的转换值(paper里面说是offset,但是觉得transformation更合适,参见R-CNN)。先验框位置用 表示,其对应边界框用 $表示,那么边界框的预测值 其实是 相对于 的转换值:
习惯上,我们称上面这个过程为边界框的编码(encode),预测时,你需要反向这个过程,即进行解码(decode),从预测值 中得到边界框的真实位置 :
然而,在SSD的Caffe源码实现中还有trick,那就是设置variance超参数来调整检测值,通过bool参数variance_encoded_in_target来控制两种模式,当其为True时,表示variance被包含在预测值中,就是上面那种情况。但是如果是False(大部分采用这种方式,训练更容易?),就需要手动设置超参数variance,用来对 的4个值进行放缩,此时边界框需要这样解码:
综上所述,对于一个大小 的特征图,共有 个单元,每个单元设置的先验框数目记为 ,那么每个单元共需要 个预测值,所有的单元共需要 个预测值,由于SSD采用卷积做检测,所以就需要 个卷积核完成这个特征图的检测过程。
新框架(MFRDet)

如上面所述,有许多利用尝试观察和充分利用金字塔特征。图(b)显示了最常见的模式之一。这种类型经过了历史验证,大大提高了传统检测器的性能。但是这种设计需要多个特征合并过程,从而导致大量额外的计算。
今天分享的框架提出了一种轻量级、高效的多级特征重用(MFR)模块(如图(d)所示)。该模块能够充分利用不同尺度的特征图,集成了深、浅层的特征,提高了检测性能。特征重用模块可简要说明如下:

S的选择:
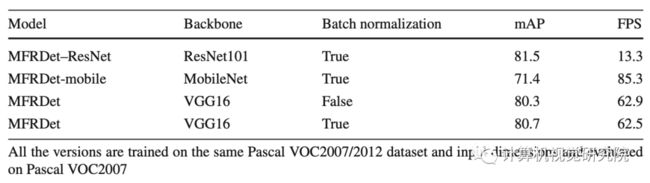
在初步设计它们时,需要考虑以下几个关键因素。首先,应该选择要重用的图层。在传统的SSD中,作者部署了conv4_3、fc7和另外四个SSD层进行预测。6个选定的特征地图的比例表包括38×38、19×19、10×10、5×5和1×1。在不同的SSD中,这些层是独立的,今天这个研究者不同意。研究者相信,小尺度特征图中存在的语义信息在尺度变换后的检测中仍然有效。选择了六个预测层和conv5_3层作为框架要重用的源层。从下表中,可以得出一个明确的结论,即重用conv3_3将降低检测精度。高分辨率特征图没有足够的高级语义信息,因此放弃了对其信息的重用。

Ti的转换策略:
在传统的SSD中,规模为38×38、语义信息很少的浅层conv4_3负责小目标识别。conv4_3层被设置为需要包含更深层语义信息的基本层。策略因特征图的标准而不同。首先,对每个源层应用Conv1×1来减小特征尺寸。然后,在Conv1×1层后,通过双线性插值,将尺度小于38×38的层(四个SSD_layers和fc7层)放入相同大小的38×38中。这样,所有的源特性都会转换为相同的大小。
Ψt的选择:
在转换策略Ti的过程完成后,创建了新的变换特征图。它们是conv4_3、conv5_3、fc7、conv8_2、conv9_2、conv10_2和conv11_2。有两种方法可以将新转换的特征映射合并在一起。通过实验验证,这两种方法都能得到良好的结果。从上表中,可以了解到连接似乎更适合我们的模型。
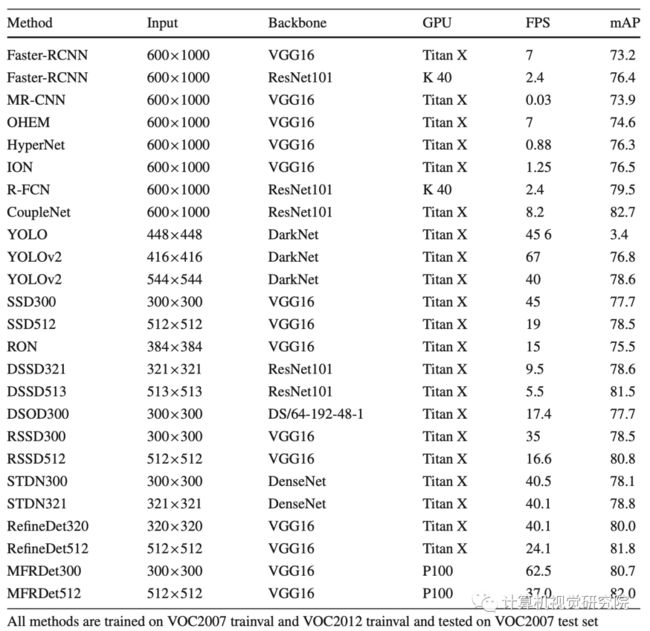
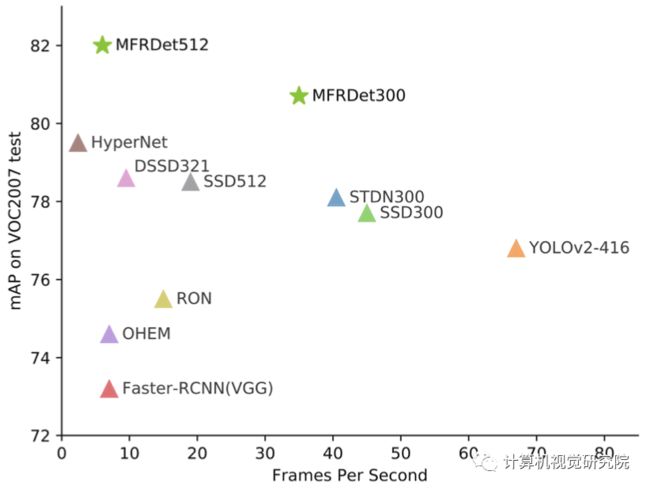
四、实验


在coco数据集上的检测可视化结果
© THE END
转载请联系本公众号获得授权
![]()
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
论文下载| 回复“MFR”获取论文下载