Day4:应用层——FTP :文件传输协议、电子邮件(EMail)、DNS(Domain Name System)、P2P应用(一类应用)
加油!偷博人!
一、FTP文件传输协议

- 向远程主机上传输文件或从远程主机接收文件
- 客户/服务器模式
客户端:发起传输的一方
服务器:远程主机 - ftp: RFC 959
- ftp服务器:端口号为21
1.FTP: 控制连接与数据连接分开
FTP客户端与FTP服务器通过端21联系,并使用TCP为传输协议
客户端通过控制连接获得身份确认 (Client发起TCP控制连接,用户名、口令,明文传输)
客户端通过控制连接发送命令浏览远程目录 (list 、download 、upload)
收到一个文件传输命令时,服务器打开一个到客户端的数据连接 (居然Server主动建立第二个TCP数据连接)
一个文件传输完成后,服务器关闭连接

服务器打开第二个TCP数据连接用来传输另一个文件
控制连接: 带外( “out of band” )传送 (传输连接带内连接)
FTP服务器维护用户的状态信息:当前路径、用户帐户与控制连接对应
有状态
2.FTP命令、响应(ASCII码形式)
- 命令样例:
在控制连接上以ASCII文本方式传送
USER username
PASS password
LIST:请服务器返回远程主机当前目录的文件列表
RETR filename:从远程主机的当前目录检索文件(gets)
STOR filename:向远程主机的当前目录存放文件(puts)
返回码样例:
状态码和状态信息 (同HTTP)
331 Username OK, password required
125 data connection already open; transfer starting
425 Can’t open data connection
452 Error writing file
二、电子邮件(EMail)
-
3个主要组成部分:
用户代理 (相当于这个应用的代理)(像Browser是HTTP应用的代理,FTP客户端时FTP应用的代理)
(这个软件代理你去和服务器打交道)
邮件服务器
简单邮件传输协议:SMTP -
用户代理
又名 “邮件阅读器”
撰写、编辑和阅读邮件
如Outlook、Foxmail
输出和输入邮件保存在服务器上
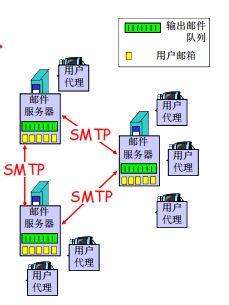
通过SMTP发邮件,用户代理发邮件给邮件服务器
通过SMTP邮件服务器互相发邮件
最后通过pop3文件存储协议,从邮件服务器(邮箱)拉取邮件(有人发的话)到用户代理
1.EMail: 邮件服务器
- 邮箱中管理和维护发送给用户的邮件
- 输出报文队列保持待发送邮件报文
- 邮件服务器之间的SMTP协议:发送email报文
客户:发送方邮件服务器
服务器:接收端邮件服务器
2.EMail: SMTP [RFC 2821]
- 使用TCP在客户端和服务器之间传送报文,端口号为25
- 直接传输:从发送方服务器到接收方服务器
- 传输的3个阶段
握手
传输报文
关闭 - 命令/响应交互
命令:ASCII文本
响应:状态码和状态信息 - 报文必须为7位ASCII码 (一个字节八bits,最高bit是0)
那如果超过7bitsASCII码,就不允许传输
3.Alice给Bob发送报文&&简单的SMTP交互


口水话看图说话:
红色单词的是命令后面跟了"命令参数",数字是状态码后面跟了状态码解释和一些说明。
这些都是明文写的东西,所以,,
伪造一个用户发邮件,也不难…
如果Bob的情敌,伪造Bob给Alice发一封分手信…
4.Try SMTP interaction for yourself:
telnet servername 25
see 220 reply from server
enter HELO, MAIL FROM, RCPT TO, DATA, QUIT commands
above lets you send email without using email client (reader)
我搜了一下这么用telnet发email
5.SMTP:总结
SMTP使用持久连接
SMTP要求报文(首部和主体)为7位ASCII编 码
SMTP服务器使用CRLF.CRLF决定报文的尾部
- 和HTTP比较:
HTTP:拉(pull)(客户端从服务器pull)
SMTP:推(push) (Server自己推给Client)
二者都是ASCII形式的命令/响应交互、状态码
HTTP:每个对象封装在各自的响应报文中
SMTP:多个对象包含在一个报文中
6.邮件报文格式

6.1报文格式:多媒体扩展
MIME:多媒体邮件扩展(multimedia mail extension), RFC 2045, 2056
在报文首部用额外的行申明MIME内容类型

口水话:base64编码,相当于把若干个不在ASCII码编码范围内的字节,转换成更长一点的,在
7.邮件访问协议

- SMTP: 传送到接收方的邮件服务器
- 邮件访问协议:从服务器访问邮件
- POP:邮局访问协议(Post Office Protocol)[RFC 1939]
用户身份确认 (代理<–>服务器) 并下载 - IMAP:Internet邮件访问协议(Internet Mail Access Protocol)[RFC 1730]
更多特性 (更复杂)
在服务器上处理存储的报文 - HTTP:Hotmail , Yahoo! Mail等
方便
- POP:邮局访问协议(Post Office Protocol)[RFC 1939]
7.1POP3协议

7.2POP3 (续) 与 IMAP

三、DNS(Domain Name System)
一个给其他应用所应用的应用。一个基础性的系统。互联网的核心功能(在互联网边缘)
- DNS的必要性
IP地址标识主机、路由器
但IP地址不好记忆,不便人类使用(没有意义)
人类一般倾向于使用一些有意义的字符串来标识Internet上的设备
例如:[email protected] (中科大郑老师的mail-box) 所在的邮件服务器www.ustc.edu.cn (中科大域名) 所在的web服务器
存在着“字符串”—IP地址的转换的必要性
人类用户提供要访问机器的“字符串”名称
由DNS负责转换成为二进制的网络地址
- DNS系统需要解决的问题 分成的域名命名和分布式的数据库
问题1:如何命名设备
用有意义的字符串:好记,便于人类用使用
解决一个平面命名的重名问题:层次化命名
问题2:如何完成名字到IP地址的转换
分布式的数据库维护和响应名字查询
问题3:如何维护:
增加或者删除一个域,需要在域名系统中做哪些工作
运行在UDP的53号端口,直接“一问一答”不用建立连接
1.DNS(Domain Name System)的历史
- ARPANET的名字解析解决方案
主机名:没有层次的一个字符串(一个平面)
存在着一个(集中)维护站:维护着一张 主机名-IP地址的映射文件:Hosts.txt
每台主机定时从维护站取文件 - ARPANET解决方案的问题
当网络中主机数量很大时
没有层次的主机名称很难分配
文件的管理、发布、查找都很麻烦
2.DNS(Domain Name System)总体思路和目标
- DNS的主要思路
分层的、基于域的命名机制
若干分布式的数据库完成名字到IP地址的转换
运行在UDP之上端口号为53的应用服务
核心的Internet功能,但以应用层协议实现
在网络边缘处理复杂性 - DNS主要目的:
实现主机名-IP地址的转换(name/IP translate) - 其它目的
主机别名到规范名字的转换:Host aliasing
邮件服务器别名到邮件服务器的正规名字的转换:Mail server aliasing
负载均衡:Load Distribution
3.1问题1:DNS名字空间(The DNS Name Space)
DNS域名结构
- 一个层面命名设备会有很多重名
- NDS采用层次树状结构的 命名方法
- Internet 根(所有域名缩成一个点)被划为几百个顶级域(top lever domains)(然后域名宇宙爆炸了)
- 通用的(generic)
.com; .edu ; .gov ; .int ; .mil ; .net ; .org
.firm ; .hsop ; .web ; .arts ; .rec ; - 国家的(countries)
.cn(China) ; .us(United States) ; .nl(New Zealand) ; .jp(Japan)
- 通用的(generic)
- 每个(子)域下面可划分为若干子域(subdomains)
- 树叶是主机
DNS: 根名字服务器(Internet 根)
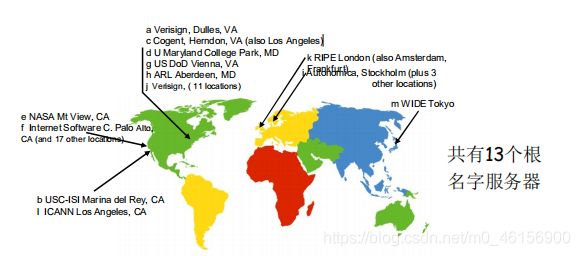
DNS名字空间(The DNS Name Space)

域名(Domain Name)
- 从本域往上,直到树根
中间使用“.”间隔不同的级别
例如:ustc.edu.cn
auto.ustc.edu.cn
www.auto. ustc.edu.cn
域的域名:可以用于表示一个域 (从树枝往上走)
主机的域名:一个域上的一个主机(从树叶往上走) - 域名的管理
一个域管理其下的子域
.jp 被划分为 ac.jp co.jp
.cn 被划分为 edu.cn com.cn
创建一个新的域,必须征得它所属域的同意 - 域与物理网络无关(同一个域的主机可以运行在不同网络上)
域的划分是逻辑的,而不是物理的- 域遵从组织界限,而不是物理网络
一个域的主机可以不在一个网络
一个网络的主机不一定在一个域
- 域遵从组织界限,而不是物理网络
3.2问题2:解析问题-名字服务器(Name Server)
- 一个名字服务器的问题
可靠性问题:单点故障
扩展性问题:通信容量
维护问题:远距离的集中式数据库 - 区域(zone)
- 区域的划分有区域管理者自己决定
- 将DNS名字空间划分为互不相交的区域,每个区域都是树的一部分
- 名字服务器:
每个区域都有一个名字服务器:维护着它所管辖区域的权威信息(authoritative record)
名字服务器允许被放置在区域之外,以保障可靠性
名字空间划分为若干区域:Zone
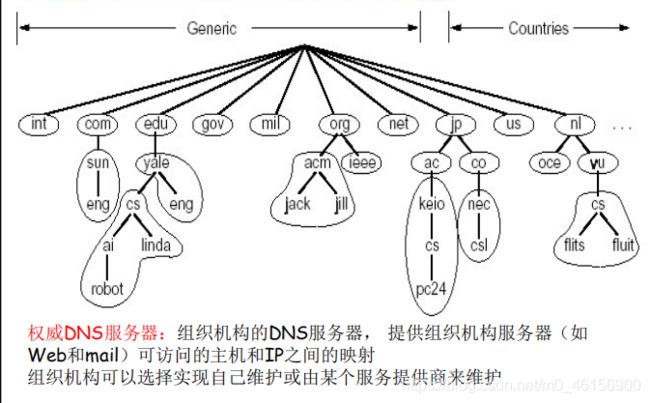
4.TLD服务器
顶级域(TLD)服务器:负责顶级域名(如com, org, net, edu和gov)和所有国家级的顶级域名(如cn, uk, fr, ca, jp )
Network solutions 公司维护com TLD服务器
Educause公司维护edu TLD服务器
5.区域名字服务器维护资源记录
- 资源记录(resource records)
作用:维护 域名-IP地址(其它)的映射关系
位置:Name Server的分布式数据库中 - RR格式: (domain_name, ttl, type,class,Value)
Domain_name: 域名
Ttl: time to live : 生存时间 (时间长,权威记录;时间短,缓存记录提高效率;到期后,删除,以备权威Server资源记录更新,为了一致性)
Class 类别 :对于Internet,值为IN。(也可以维护非Internet记录)
Value 值:可以是数字,域名或ASCII串。 (域名对应的ip地址)
Type 类别:资源记录的类型—见下页
DNS :保存资源记录(RR)的分布式数据库


A:Address
MX:Mail Box
资源记录(resource records)

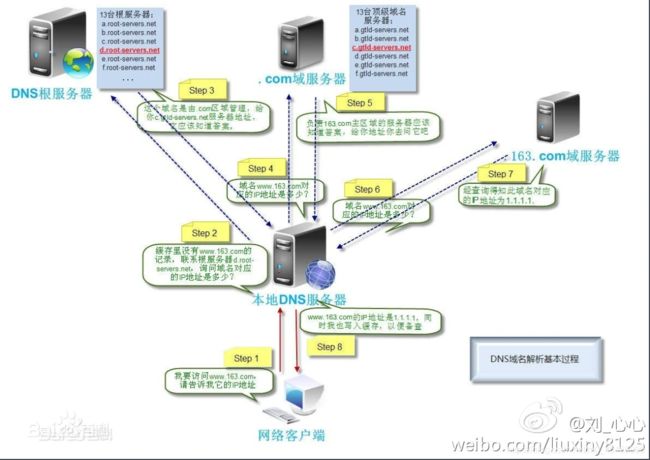
6.DNS大致工作过程
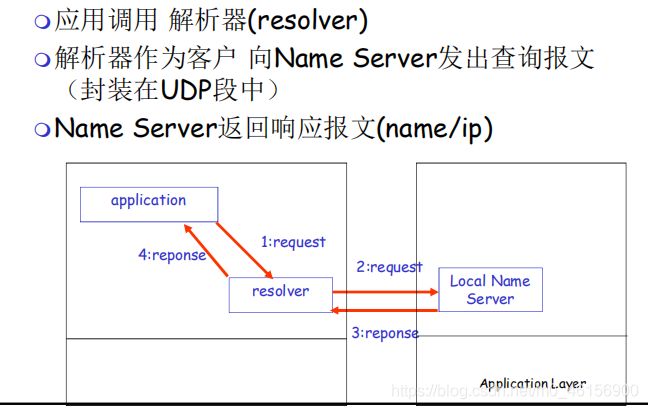
对于“2:request” 解析器如何知道Local Name Server 身处何方。
1.手工配
2.自动配
6.1本地名字服务器(Local Name Server)
- 并不严格属于层次结构
每个ISP (居民区的ISP、公司、大学)都有一个本地DNS服务器
也称为“默认名字服务器”
当一个主机发起一个DNS查询时,查询被送到其本地DNS服务器
起着代理的作用,将查询转发到层次结构中
6.2名字服务器(Name Server)
名字解析过程
- 目标名字在Local Name Server中
情况1:查询的名字在该区域内部
情况2:缓存(cashing) - 当与本地名字服务器不能解析名字时,联系根名字服务器顺着根-TLD 一直找到 权威名字服务器

6.3递归查询&&迭代查询
- 递归查询:
名字解析负担都放在当前联络的名字服务器上
问题:根服务器的负担太重
解决: 迭代查询(iterated queries)

- 迭代查询
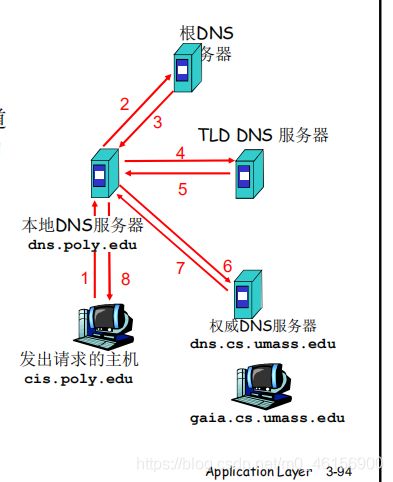
主机cis.poly.edu 想知道主机 gaia.cs.umass.edu的IP地址
根(及各级域名)服务器返回的不是查询结果,而是下一个NS的地址
最后由权威名字服务器给出解析结果
当前联络的服务器给出可以联系的服务器的名字
“我不知道这个名字,但可以向这个服务器请求”
百度百科的一张图片:
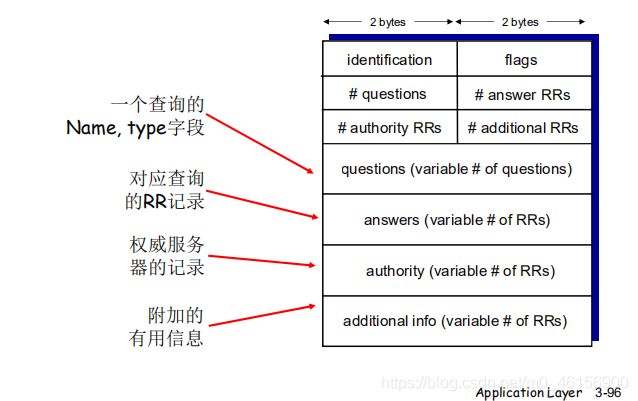
7.DNS协议、报文
DNS协议:查询和响应报文的报文格式相同

8.提高性能:缓存(前面提到了)
一旦名字服务器学到了一个映射,就将该映射缓存起来
根服务器通常都在本地服务器中缓存着
使得根服务器不用经常被访问
目的:提高效率
可能存在的问题:如果情况变化,缓存结果和权威资源记录不一致
解决方案:TTL(默认2天)
9.问题3:维护问题:新增一个域
-
在上级域的名字服务器中增加两条记录,指向这个新增的子域的域名 和 域名服务器的ip地址
-
在新增子域的名字服务器上运行名字服务器,负责本域的名字解析: 名字->IP地址
-
例子:在com域中建立一个“Network Utopia”(网络乌托邦)
到注册登记机构注册域名networkutopia.com
需要向该机构提供权威DNS服务器(基本的、和辅助的)的名字和IP地址
登记机构在com TLD服务器中插入两条RR记录: (networkutopia.com,dns1.networkutopia.com, NS)
(dns1.networkutopia.com, 212.212.212.1, A) -
在networkutopia.com的权威服务器中确保有
用于Web服务器的www.networkuptopia.com的类型为A的记录
用于邮件服务器mail.networkutopia.com的类型为MX的记录
10.攻击DNS(总的说来,DNS比较健壮)
DDoS 攻击
- 对根服务器进行流量轰炸
攻击:发送大量ping
没有成功
原因1:根目录服务器配置了流量过滤器,防火墙
原因2:Local DNS 服务器缓存了TLD服务器的IP地址, 因此无需查询根服务器 - 向TLD服务器流量轰炸攻击
发送大量查询
可能更危险
效果一般,大部分DNS缓存了TLD
重定向攻击
- 中间人攻击
截获查询,伪造回答,从而攻击某个(DNS回答指定的IP)站点 - DNS中毒
发送伪造的应答给DNS服务器,希望它能够缓存这个虚假的结果 - 技术上较困难:分布式截获和伪造利用DNS基础设施进行DDoS
- 伪造某个IP进行查询, 攻击这个目标IP
- 查询放大,响应报文比查询报文大
- 效果有限
四、P2P应用
纯P2P架构
- 没有(或极少)一直运行的服务器
任意端系统都可以直接通信
利用peer的服务能力
Peer节点间歇上网,每次IP地址都有可能变化
例子:
文件分发 (BitTorrent)
流媒体(KanKan)
VoIP (Skype) (互联网语言电话)
1.文件分发: C/S vs P2P**
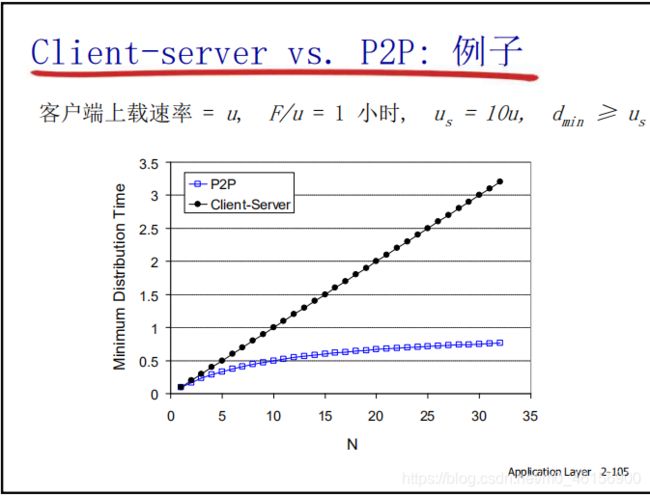
问题: 从一台服务器分发文件(大小F)到N个peer需要多少时间?
Peer节点上下载能力是有限的资源

- 文件分发时间: C/S模式

- 当用户较少,文件传输时长取决于用户的下载能力。当用户相当大,取决于服务器的上载时间。
- 文件分发时间: P2P模式

2.P2P文件分发: BitTorrent (BT种子)
文件被分为一个个块256KB
网络中的这些peers发送接收文件块,相互服务
每个peer都有一个 bit_map(位图)(每个bit映射0/1来代表每个块的未拥有/拥有文件块的情况)
然后peer节点泛洪,就知道每个peer的文件拥有情况

peer和peer节点,在应用层逻辑连接,相连互通,相互协作,构成overlay(覆盖网)。
新的Peer加入torrent:
- 一开始没有块,bit_map全0(白手起家,困难重重),但是将会通过其他节点处累积文件块
- 向跟踪服务器注册,获得peer节点列表,和部分peer节点构成邻居关系 (“连接”)
当白手起家随机请求了4块之后,(bit_map中4个bits置1),于是优先请求稀缺的文件block,有助于整体的文件共享,有助于缓解拥有稀缺资源的peer下线之后请求不到稀缺资源的情况
集体的利益和个人利益这么捆绑?
“一报还一报,得道多助,失道寡助,人人为我我为人人”
一开始 ”白手起家“ 很难拿稀缺的块,因为,别人干嘛一来就给你稀缺的块? 这不符合一报还一报。
- 当peer下载时,该peer可以同时向其他节点提供上载服务
- Peer可能会变换用于交换块的peer节点
- 扰动churn: peer节点可能会上线或者下线
- 一旦一个peer拥有整个文件,它会(自私的)离开或者保留(利他主义)在torrent中 (成为一个BT种子)
- 成为种子,不选择离开,选择继续服务,就攒人品,可更多更快更好的下载其他peer的资源
再Summarize一下:
2.1BitTorrent: 请求,发送文件块
请求块:
- 在任何给定时间,不同peer节点拥有一个文件块的子集
周期性的,Alice节点向邻居询问他们拥有哪些块的信息
Alice向peer节点请求它希望的块,稀缺的块
发送块:一报还一报tit-for-tat
- Alice向4个peer发送块,这些块向它自己提供最大带宽的服务
其他peer被Alice阻塞 (将不会从Alice处获得服务)
每10秒重新评估一次:前4位 - 每个30秒:随机选择其他peer节点,向这个节点发送块
“优化疏通” 这个节点
新选择的节点可以加入这个top 4
2.2BitTorrent: tit-for-tat
(1) Alice “优化疏通” Bob
(2) Alice 变成了Bob的前4位提供者; Bob答谢Alice
(3) Bob 变成了Alice的前4提供者

3.P2P文件共享
- 例子
Alice在其笔记本电脑上运行P2P客户端程序
间歇性地连接到Internet,每次从其ISP得到新的IP地址
请求“双截棍.MP3”
应用程序显示其他有“双截棍.MP3” 拷贝的对等方
Alice选择其中一个对等方,如Bob.
文件从Bob’s PC传送到Alice的笔记本上:HTTP
当Alice下载时,其他用户也可以从Alice处下载
Alice的对等方既是一个Web客户端,也是一个瞬时Web服务器
所有的对等方都是服务器 = 可扩展性好!
- 两大问题:
如何定位所需资源
如何处理对等方的加入与离开 - 可能的方案
集中
分散
半分散
4.P2P:集中式目录
最初的“Napster”设计
- 当对等方连接时,它告知中心服务器: IP地址 内容
- Alice查询 “双截棍.MP3” 3) Alice从Bob处请求文件

P2P:集中式目录中存在的问题
单点故障 (目录服务器挂了的话)
性能瓶颈
侵犯版权
(文件传输是分散的,而定位内容则是高度集中的)
5.查询洪泛:Gnutella (完全分布式)
泛洪,一问十,十问百(你有没有学习资料啊,口口相问,很快遍及全网overlay)。
然后出现一个问题,要是真没有,就一直问下去吗?“你有学习资料吗有吗有吗?”
于是有 “治洪”…


Participate in Gnutella
 对等方离开,就和所有邻居“say goodbye”
对等方离开,就和所有邻居“say goodbye”
6.利用不匀称性:KaZaA (半分布式)
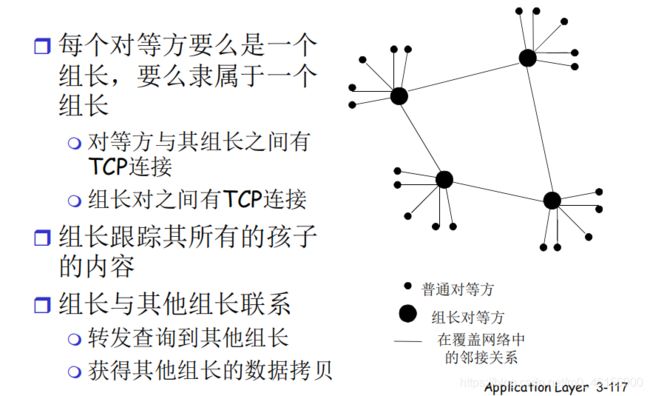 在组内是集中式,在组长间是分布式。
在组内是集中式,在组长间是分布式。
下面再看看具体咋找资源

散列标识(哈希值) 是下载资源的唯一标识,用哈希值来下载文件。
用户在检索的时候,匹配的是 “描述符”

以上所说的都是非结构化的P2P应用。下面是结构化的P2P应用(下面了解一下)

本篇结束