python 两点曲线_Python自学教程| 3万字详解每个重要知识点(内附视频)

本文目录:
- 什么是Python?
- Python的用途是什么?
- 如何安装Python?
- 为什么选择Python?
- R与Python
- 学习Python的最佳方法
- 什么是顶级Python IDE
- 哪个是最适合Python的IDE?
- 如何为Jupyter Notebook供电?
- Python Notebook(Jupyter)中的功能
- 注释
- 变数
- 经营者
- 算术运算符
- 赋值运算符
- 比较运算符
- 逻辑运算符
- 身份运算符
- 会员运营商
- 按位运算符
- 拉姆达
- 数组
- 班级
- 遗产
- 迭代器
- 范围
- 模组
- 日期
- JSON格式
- 正则表达式
- 画中画
- 尝试,除了
- 用户输入
- 字符串格式
- Python数据类型
- 流程控制声明
- 文件处理
- 用Python创建函数
- 通过使用Python作为计算器来学习简单命令
(配套视频见文末)
1.什么是Python?
Python是一种高级的,面向对象的编程语言。开发领域的大多数初学者都喜欢Python,因为它的简单性和多功能性使其成为最先学习的语言之一。它也得到了社区的大力支持,并与日俱增。
在这个面向初学者的Python教程中,我们将学习Python作为编程语言的基础知识,并了解如何开始使用它。我们将看到如何下载和安装Python以及如何使用流行的IDE开始编码。我们还将详细讨论jupyter功能。
2.Python的用途是什么?
当您使用浏览,每天在视频网站上观看视频或在收听自己喜欢的音乐时,请记住,他们所有人都使用Python来满足编程需求。Python在应用程序,平台和服务中有多种用途。让我们在这里谈论一些。
2.1-Web开发
大量的预构建Python库使Web开发变得更加简单。由于其简洁明了的语法,因此编写Python代码的时间更少。这有助于快速建立原型,从而加快商业产品的投资回报率。内置的测试框架有助于交付无错误的代码。大量支持良好的框架有助于在不影响解决方案性能的情况下加快实施速度。
2.2-物联网
为了简单起见,让我们将物联网视为“将嵌入式系统连接到互联网的物理对象”。它在涉及大数据,机器学习,数据分析,无线数据网络和网络物理系统的项目中起着至关重要的作用。物联网项目还涉及实时分析。
考虑到上述应用领域,编程语言应该是一个大胆的选择。这是Python选中所有复选框的地方。此外,Python还具有可伸缩性,可扩展性,可移植性和可嵌入性。这使得Python独立于系统,并使其可以容纳多台单板计算机,而与操作系统或体系结构无关。
而且,Python是管理和组织复杂数据的绝佳选择。对于大量数据的物联网系统而言,它特别有用。Python成为IoT应用程序理想编程语言的另一个原因是它与科学计算的紧密联系。
2.3-机器学习
机器学习为解决问题提供了一种全新的方法。由于以下原因,Python处于机器学习和数据科学的最前沿:
- 广泛的开源库支持
- 高效而精确的语法
- 易于与其他编程语言集成
- Python的入门点很低
- 可扩展到不同的操作系统和体系结构

3.如何安装Python?
如果您是Windows用户,并且已使用http://Anaconda.org上可用的Anaconda发行包安装了Python,则需要转到“ Download Anaconda ”,然后下载适用于Python 3.6的最新版本。
下载此文件后,这是一个非常简单明了的过程,并且将为您安装Python。下一步是启动IDE,以开始使用Python进行编码。
因此,一旦安装了Python,您就可以在Python安装的顶部拥有多个IDE或文本编辑器。
对于文本编辑器,可以使用Sublime或Notepad ++之类的东西。如果您喜欢使用集成开发环境,则可以使用Jupyter。此外,还有其他选项,例如Wingware,Komodo,Pycharm和Spyder。
Python中有多个可用的软件包。一些工具库是numpy,pandas,seaborn以进行可视化,并通过scipy进行计算和统计。其他是xlrb,openpyxl,matplotlib和io。
(配套视频见文末)
4.为什么选择Python?
因为Python已成为支持数据科学和机器学习应用程序的首选编程语言。当然,Python有其优势。与其他编程语言相比,它是快速的,甚至R也是如此。
我们可以很容易地说Python是一个快速的编译器。由于它是一种基于Java的编程语言,因此您可以将其应用程序扩展到分析研究,分析建模和统计建模之外。您将能够使用Python创建Web应用程序,并将这些Web应用程序直接集成到后台的分析模型中。
Python也很容易与其他平台和其他编程语言集成。它具有通用的面向对象的编程体系结构,其中现有的IT开发人员,IT分析师和IT程序员发现很容易过渡到分析领域。
由于Python中的编码结构是面向对象的编程体系结构,因此它具有出色的文档支持。
使用Python的7个理由
- 可读且可维护的代码
- 多种编程范例
- 与主要平台和系统兼容
- 强大的标准库
- 开源框架和工具
- 简化软件开发
- 测试驱动开发

5.R vs Python?
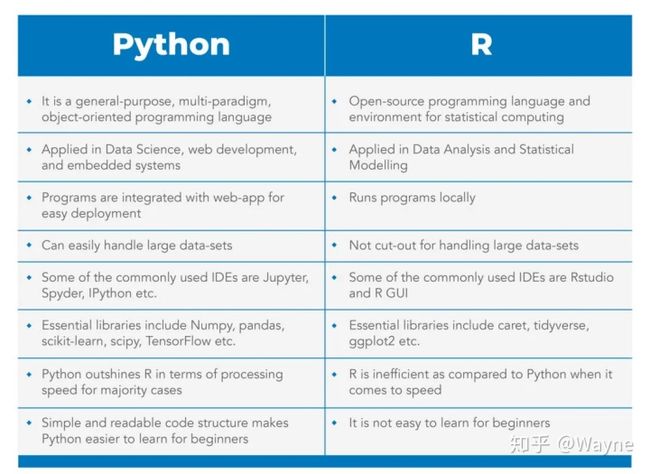
R是为统计分析应用开发的;另一方面; Python是作为通用编程语言开发的。对于使用大型数据集,解决机器学习问题并创建复杂的数据可视化的人来说,这两者都是必不可少的。
让我们看一下R和Python之间的区别。
开发Python是为了提供一种编写脚本的方法,以使每天遇到的一些例行任务自动化。但是,随着时间的流逝,Python已经发展并在许多其他领域变得非常有用,尤其是数据分析。
R是一种编程语言,同时也是用于图形和数据分析的开源软件。它具有可以在任何计算机系统上运行的优势,并且被数据挖掘者和统计人员用于对其数据进行表示和分析。
Python与R进行数据分析编程对于
数据科学家来说,决定使用Python还是R进行数据分析是一个普遍的挑战。尽管R是纯粹为统计人员开发的,使它能够将分析描述为可视化数据的特定优势,但Python凭借其通用特性和语法非常规则而脱颖而出。基于这些差异,有必要将两种语言进行比较,以确定哪种语言最适合它们。
Python程式设计语言
- – Python编程语言受到Modula-3,ABC和C语言的启发
- – Python专注于代码的可读性和生产力
- –由于其易于使用和简单的语法,因此更易于开发代码和调试
- –代码缩进会影响其含义
- –所有功能通常都以相同的样式编写
- – Python非常灵活,也可以用于Web脚本。
- –它具有相对渐进和较低的学习曲线,因为它注重简单性和可读性
- –适合开始编程的人
- –其Package索引称为PyPi。其带有库的Python软件仓库。尽管用户可以选择为Pypi做贡献。在实践中很难。
- – RPy2可在Python中用于运行R代码的库。用于从Python向R提供较低的级别。
- – 2014年,Dice Tech薪酬调查显示,经验丰富的专家的平均工资为$ 94139
- –主要用于需要将分析的数据与Web应用程序集成或将统计信息用于数据库生产时
- –尽管数据处理能力有所提高,但过去处理数据的能力仍然是一项挑战,这是由于其数据处理程序包尚处于初期阶段
- –您必须使用pandas和NumPy之类的工具才能将其用于数据分析
- –可用的IDE包括Spyder,IPython Notebook。
R编程- – S编程语言激发R。
- –强调用户友好的数据分析方法,图形模型和统计信息。
- –由于统计模型只用很少的几行编写,因此使用起来有点困难。
- –存在R样式表,尽管很少使用
- –表示或编写相同功能块的方法有很多。
- –使使用复杂的R公式变得容易。对于它的许多统计模型和检验。
- –在学习基础知识时,学习曲线开始就很陡。但是以后学习高级主题变得非常容易
- –对于专业程序员来说并不难。
- –全面的R存档网络(CRAN)。CRAN是R存储库软件包,很容易由用户提供。
- – R中的rpython包用于运行Python代码。调用Python方法或函数并获取数据。
- – 2014年,Dice Tech薪酬调查显示,经验丰富的专家的平均工资为$ 115 531
- –主要用于需要独立计算或独立服务器的分析。
- –用于初学者的关键任务时更容易。使用很少的代码行来编写统计方法。
- –非常适合处理大包装中的数据。可用的测试和公式的使用。
- – R不需要其他程序包即可进行基本分析。对于大型数据集,只需要像dplyr这样的软件包即可。
- –使用R studio IDE
Python –优点
- IPython Notebook促进并简化了Python和数据的使用。这是因为您可以与其他人共享笔记本而不必告诉他们安装任何东西。这减少了代码组织的开销,因此使人们可以专注于完成其他有用的工作。
- 鉴于它是一种通用语言,因此它既直观又简单。它使数据科学家的学习曲线平坦,从而使他能够提高自己的程序编写技能。Python还有一个内置的测试框架,可以鼓励改善测试范围,这反过来又保证了代码的可靠性和可重用性。
- 它是一种多用途的编程语言,它将具有不同背景的人们(统计学家和程序员)聚集在一起。
R –优点
- R提供清晰的数据可视化,使数据得到有效的设计和理解。ggvis,ggplot2,rChart和googleVis是其可视化软件包的示例。
- R具有活跃社区和理想软件包的广阔生态系统。该软件包可从Github,BioConductor和CRAN获得。
- 它是由统计学家为统计学家开发的。因此,他们可以通过R包和代码交流概念和想法。
两种语言各有优势,您可根据个人喜好选择一种可以解决您问题的语言。
6.学习Python的最佳方法?
易于学习是Python受欢迎的主要原因。它是一种简单且无类型的编程语言,因此易于学习。学习语言所需的时间取决于您要使用Python达到的水平。同样,学习曲线可以根据个人能力而变短或变长。
一个人需要6到8周的时间来学习Python的基础知识。这将包括学习语法,关键字,函数和类,数据类型,基本编码和异常处理
并非所有Python专业人士都需要高级Python技能。根据您的工作性质,您可以学习诸如数据库编程,套接字编程,多线程,同步技术等技能。
高度复杂的Python技能包括数据分析的概念,所需库的动手经验,图像处理等。每个专业技能都需要大约一周的时间才能掌握。
Python思维导图+学习路线图wx7dcc75bb5e655e9b.h5.xiaoe-tech.com
7.什么是最受欢迎的Python IDE?
有7个适用于Python的顶级IDE
- 斯派德
- 药香
- 托尼
- 原子
- 朱皮特
- 科莫多
- 翼件
8.哪个是最适合Python的IDE?
Jupyter是Python最好的IDE,也是Python使用最广泛的IDE之一。让我们看看如何设置Jupyter Notebook。另外,让我们看看Jupyter Notebook的功能是什么。
9.如何为Jupyter Notebook供电
以下是启动Jupyter笔记本电脑的指导步骤:
- 打开Anaconda提示符。如果您通过Anaconda安装程序完成了安装,则可以使用该选项。
- 打开Anaconda命令提示符后,您将看到分配给您的默认路径。这是您使用的计算机的用户名。
- 将文件夹路径添加到您要在其中打开笔记本的默认路径(例如cd Desktop→cd Python)
- 设置路径后,使用命令jupyter notebook 添加Jupyter笔记本

5. 按回车。这将在本地主机(即系统)中打开笔记本
6. Anaconda提示中描述的路径现在将出现在jupyter笔记本主页上
7. 下一步是打开一个新的Python Notebook。这是您执行所有编码的环境。您可以将新笔记本(无标题)重命名为您想要的名称,然后单击“重命名”。

在本地使用Jupyter时,请保持anaconda提示符处于活动状态,这是您用来为Jupyter笔记本电脑加电的电源。如果关闭了anaconda提示符,则说明系统上不再运行python,并且内核已断开连接。
10.Python Notebook(Jupyter)中的功能


工具栏上有多个选项,即文件,编辑,视图,插入,单元格,内核,小部件和帮助。让我们一一看一下其中的一些特征和功能。
文件选项
保存和检查点– 设置检查点是一个有趣的概念。该文件会定期进行自动保存,通过设置检查点,您可以跳过一些自动保存到设置的检查点的操作。如果您在过去的几分钟或几小时内犯了一个错误,这将有所帮助。您始终可以还原到更稳定的检查点,然后从那里继续执行代码,而不是从头开始。
下载为– 有多种下载Jupyter Notebook的方式。首先是Classic Notebook,它是ipynb 扩展名。在被称为jupyter笔记本之前,它是一个Ipython笔记本。这就是为什么扩展名。
然后,您有了.py 扩展名。保存带有.py 扩展名的文件,您可以将其导入到其他IDE中以方便使用。 关闭并暂停–此命令关闭在此特定时间点运行的所有内核,并暂停所有进程。


编辑选项
它包括剪切单元格,复制单元格,粘贴,删除,拆分单元格,上移,下移等。
那么,什么是细胞?
单元格不过是您在窗口中出现的对话框中键入的代码。这是一个单元格,您可以在其中键入代码-运行时,每个单元格都会为您提供输出。
要运行这段特定的代码,您可以单击特定的选项,即运行单元格或快捷键是Shift + Enter 。
如果要浏览其他可用的快捷方式选项,可以在“ 键盘快捷方式”中的“ 帮助” 下获得。您可以剪切这些单元格,以后再粘贴。您可以合并,拆分等等。这些是简单的项目。
查看选项
您也可以切换标题,工具栏和行号。
插入选项
这些是基本的插入操作。您可以根据代码要求在上方或下方插入一个单元格。


单元选项
如果您单击全部运行,它将运行整个工作簿中存在的所有单元格。当您单击“ 全部运行”时,它将运行所选单元格上方的所有单元格。同样,如果您单击“ 在下方运行所有文件” ,它将运行所选单元格下面的所有单元格。
不同类型的单元格,即 代码,降价和原始转换文件。
我们将在代码文件中大量使用的一项令人兴奋的功能是Markdown文件。降价仅是将您在单元格中键入的内容转换为文本消息。
您转换为Markdown的单元格将不会运行或视为一行代码。当您运行此单元格时,它将被视为一个文本字段,并且输出也是文本。在此单元格上不执行任何计算。

帮助选项
在这里,您可以看到可用的常用库和软件包。
您可以单击这些选项,这将打开指南或参考书,您可以在其中查看所选软件包中可用的各种方法。
使用Jupyter时,您可以尝试其他各种选项。
11.注释
注释对于描述程序逻辑和各个模块的用途很有用。除编码人员外,其他人员也可以通过查看有意义的注释来理解代码。在测试程序时,注释可用于禁用部分代码,并从执行中排除。Python注释以#符号开头。注释可以是自己的,也可以在同一行中的代码之后开始注释。下面说明了这两种情况。
# comment in separate line
x = x * 5
x = x * 5 # multiply by 5; comment in same line
# this function is going to divide two variables
# the second value should not be zero
# if it is zero, error is thrown
def divide(first, second):提及多行注释没有其他方法。#可以添加到不同的行。当#放在引号内时,则它是字符串的一部分,而不是注释。例如,
str = "# hello world"12.变数
Python变量是保存数据的容器。这些分配给变量的数据值可以在以后的阶段进行更改。对变量的第一次值分配将创建变量。没有明确的变量声明。
numOfBoxes = 7
ownerName = "Karthik"
print("numOfBoxes= ", numOfBoxes)
print("ownerName= ", ownerName)上面示例中,创建了两个带有数字和字符串数据的变量。打印语句用于显示这些变量。变量名称遵循以下约定。
- 变量名称以字母或下划线字符开头
- 其余名称中允许使用字母数字和下划线
- 变量名称区分大小写
# valid names
numOfBoxes = 7
_num_of_boxes = 10 # this is a different variable than numOfBoxes
_NUM_OF_BOXES = 15 # a different variable as names are case sensitive
ownerName = "Karthik"
ownerName2 = "Charan" # different, valid variable
# invalid names
2ownerName = "David" # cannot start with number.
# Only letter or underscore in the beginning
owner-name = "Ram" # no hypen
owner name = "Krish" # no space allowed
# only alpha numeric and underscore在这里,我们列出了一些可能的变量名称和一些无效的名称。
在python中,您可以为多个变量分配多个值。同时将相同的值分配给多个变量。请看这个例子。
# different values assigned to many variables
length, width, depth = 5, 8, 7
print(length)
print(width)
print(depth)
# same value assigned to many variables
length = width = depth = 5
print(length)
print(width)
print(depth)13.经营者
运算符可帮助处理变量和值。例如,如果我们可以使用两个数字变量,则可以将它们相加或相减,相乘或相除。这些操作会更改值并给出新值。Python支持以下类别的运算符。
- 算术运算符
- 赋值运算符
- 比较运算符
- 逻辑运算符
- 身份运算符
- 会员经营者
- 按位运算符
14.算术运算符
使用算术运算符执行诸如加法,减法之类的数学运算。让我们通过它们。
a = 10
b = 6
print (a + b) # addition
print (a - b) # subtraction
print (a * b) # multiplication
print (a / b) # division
print (a % b) # modulus
print (a ** b) # exponentiation
print (a // b) # floor division所有操作都很容易理解。模运算返回除以两个数的余数(在我们的示例中,4是提示)。同样,底数除法是整数除法,它返回除法结果为整数(10 // 6 = 1)。
15.赋值运算符
可以使用赋值运算符将值或变量内容分配给另一个变量。右侧也可以是表达式(在下面的示例中为c赋值)。这里有一些例子。
a = 7 # assign value to a
b = a # assign value of a into b
c = a + b -2 # calculate an expression and place result into c
b += 2 # equivalent to b = b + 2
b -= 2 # equivalent to b = b - 2
b *= 2 # equivalent to b = b * 2
b /= 2 # equivalent to b = b / 2
b %= 2 # equivalent to b = b % 2
b //= 2 # equivalent to b = b // 2
b **= 2 # equivalent to b = b ** 2
b &= 2 # equivalent to b = b & 2
b |= 2 # equivalent to b = b | 2
b ^= 2 # equivalent to b = b ^ 2
b >>= 2 # equivalent to b = b >> 2
b <<= 2 # equivalent to b = b << 2
最后五个运算符将在下面的后面部分中说明。
16.比较运算符
比较两个值,结果是布尔值True或False。在if和loop语句中使用以进行决策。
a = 3
b = 7
print(a == b) # true if a and b are equal
print(a != b) # true if a and b are not equal
print(a > b) # true if a is greater than b
print(a < b) # true if a is less than b
print(a >= b) # true if a is greater than or equal to b
print(a <= b) # true if a is less than or equal to b让我们看一个实际比较的例子。在这里,我们检查a是否小于b。如果此条件为真,则执行一条语句。否则,执行其他语句。
a = 3
b = 7
if(a < b):
print("first number is less than second one");
else:
print("first number is greater than or equal to second one")17.逻辑运算符
可以使用逻辑运算符组合两个或多个比较操作。这些逻辑运算符返回布尔值。
a = 5
b = 8
# True if both conditions are true
print(a > 3 and a < 7)
# True if one condition is true
print(a > 6 or b < 7)
# True if given condition is false (inverse of given condition)
print(not(a > 3))18.身份运算符
身份运算符比较两个对象是否相同。他们需要指向相同的位置。
a = ["hello", "world"]
b = ["hello", "world"]
c = a
# prints true as both are same element
print(a is c)
# prints false as they are two diffent values
# content may be same, but value locations are different
print(a is b)
# comparing the values gives true
print(a == b)
# not negates the comparison result
# if two variables are not same, then result is true
print(a is not c)
print(a is not b)19.会员经营者
检查给定列表中是否存在元素。
a = ["hello", "world"]
# checks if given element is present in the a list
print("world" in a)
# checks if given element is not present in the a list
print("world" not in a)20.按位运算符
在处理二进制数时,我们需要按位运算符来操作它们。二进制数是零和一,它们被称为位。
a = 1 # binary equivalent of 1 is 1
b = 2 # binary equivalent of 2 is 10
# In case of AND(&) operation, if both bits are 1, set result to one
# in our case, two corresponding bits are not 1
# so, corresponding result is 0
print(a & b)
# OR operation (|), gives 1 if either operands are 1
# The reult of 0 and 1 is 1, 1 and 0 is 1
# hence, a | b gives binary 11 or decimal equivalent of 3
print(a | b)
# XOR (^) returns 1 if only one of the operands is 1
# 1 ^ 1 = 0, 0 ^ 0 = 0, 1 ^ 0 = 1, 0 ^ 1 = 1
# considering a and b, they have only ones in each bit position
print(a ^ b)
# NOT operation negates the bit value
# NOT 0 = 1, NOT 1 = 0
# while negating b, all preceeding zeros are turned to one
# this leads to a negative number
print(~ b)
# zero fill left shift (<<)
# zeros are filled from right, bits are shifted to left
# left most bits fall off
# in this example, we shift the bits of b twice
# 10 (b) shifted twice is 1000 (which is decimal 8)
print(b << 2)
# signed right shift (>>)
# shift the bits to the right, copy leftmost bits to the right
# right most bits fall off
# when we shift b (10) once to the right, it becomes 1
print(b >> 1)21.拉姆达
前面我们看到了函数定义和函数调用。Lambda是匿名的小函数。Lambda的主体只能有一个表达式。Lambda可以接受任意数量的参数。
# a lambda function with the name growth is created
# it takes one argument and increase it by 2
growth = lambda givenLength : givenLength + 2
print(growth(25)) # prints 27
Let us take another example with many parameters:
# lambda with the name area is created
# two parameters are passed, who area is calculated
area = lambda length, breadth: length * breadth
print(area(4, 7)) # prints 28当嵌套在另一个函数中时,lambda很有用。函数成为创建函数的模板。
# the growth lambda we wrote earlier
def growth(n):
return lambda a : a + n
# create a function that would increase by 2
strechTwo = growth(2)
# create a function that would increase by 3
strechThree = growth(3)
print(strechTwo(7))
print(strechThree(7))在上面的示例中,使用相同的函数增长,我们生成了不同的函数strechTwo和strechThree。这可以通过在growth函数中声明的lambda函数来实现。通过运行此代码,我们得到输出9和10。
22.数组
数组用于在变量中存储值列表。这是创建数组的语法。方括号用于定义列表。
fruits = ["mango", "apple", "grapes"]
print (fruits)数组允许我们使用索引访问数组元素。索引从零开始,从零开始。
fruits = ["mango", "apple", "grapes"]
firstFruit = fruits[0]
print (firstFruit)与访问元素类似,我们可以使用索引来修改元素。
fruits = ["mango", "apple", "grapes"]
fruits[0] = "melon"
print (fruits)可以使用len()方法知道数组中元素的数量。
fruits = ["mango", "apple", "grapes"]
print (len(fruits)) # prints 3for语句用于遍历数组元素。我们可以在循环内处理单个元素。
fruits = ["mango", "apple", "grapes"]
for fruit in fruits:
print(fruit)append()方法将新元素添加到数组的末尾。
fruits = ["mango", "apple", "grapes"]
fruits.append("guava")
print(fruits) 有两种方法可用于从数组中删除元素。pop()方法获取数组索引,并删除特定位置的元素(请记住元素是从零开始的)。remove()接受元素的值并将其删除。让我们看看这两种方法的作用。
fruits = ["mango", "apple", "grapes"]
fruits.pop(1)
print(fruits)
fruits.remove("grapes")
print(fruits)23.班级
对象是具有属性和方法的实体。这些对象可以通过声明类来创建。类是对象的蓝图。在此示例中,我们看到如何定义一个类,如何在该类之外创建对象以及访问该对象的属性。
# create a class with "class" keyword
class Fruit:
# a property, "name" is created
# the property is assigned with the value "mango"
name="mango"
# let us create an object, "oneFruit" using the above class
oneFruit = Fruit()
# the property of the object "oneFruit" is accessed like this
print(oneFruit.name)所有类都有一个内置函数__init __()
从该类创建新对象时将调用此函数。创建对象时会自动调用此函数。我们可以在该函数中编写有用的初始化代码,以便在对象实例化时设置变量。
# create a class with "class" keyword
class Fruit:
# define the init function
def __init__(self, name, color):
self.name = name
self.color = color
# let us create an object, "oneFruit" using the above class
# values are passed to the class
oneFruit = Fruit("mango", "yellow")
# the property of the object "oneFruit" is accessed like this
print(oneFruit.name)
print(oneFruit.color)在上面的示例中,我们使用了参数“ self”。在init函数中定义了三个参数,但是我们在类调用中仅传递了两个参数。自参数会自动传递给类的方法。名称“ self”不是固定的,可以使用任何名称。它必须是第一个参数。
除了内置方法之外,该类还可以具有其他用户定义的方法。让我们在类内部创建一个makeJuice()方法。
# create a class with "class" keyword
class Fruit:
# define the init function
def __init__(self, name, color):
self.name = name
self.color = color
def makeJuice(self):
print("Made " + self.name + " juice. It will be in " +
self.color + " color.")
# let us create an object, "oneFruit" using the above class
# values are passed to the class
oneFruit = Fruit("mango", "yellow")
# invode object's method
oneFruit.makeJuice()
The property of the object can be modified like this:
oneFruit.color = "red"24.遗产
继承是一个概念,其中我们扩展类的功能以创建新的类。这样做有很多好处。首先是重用现有代码。现有类具有可以重用的通用代码。该类称为父类或基类。我们创建一个子类,该子类将从父类接收定义。让我们考虑一个父类,车辆。它具有适合描述任何车辆的特性和方法。
lass Vehicle:
def __init__(self, make, color):
self.make = make
self.color = color
def display(self):
print("make= " + self.make + " color= " + self.color)
v = Vehicle("2015", "green")
v.display()Vehicle属性中定义了两个属性,make和color。让我们从Vehicle类扩展一个子类Car。
class Vehicle:
def __init__(self, make, color):
self.make = make
self.color = color
def display(self):
print("make= " + self.make + " color= " + self.color)
# v = Vehicle("2015", "green")
# v.display()
class Car(Vehicle):
def __init__(self, make, color, numOfSeats):
super().__init__(make, color)
self.numOfSeats = numOfSeats
def display(self):
super().display()
print("number of seats= " + str(self.numOfSeats))
def wipeWindshield(self):
print("turned on wiper")
newCar = Car("2019", "orange", 5)
newCar.display()
newCar.wipeWindshield()在此代码中有许多要注意的地方。第12行定义了一个类Car。这是一个扩展的载具(在括号中提到)。第13行是Car的构造函数。接受三个参数。第14行调用父类Vehicle类的构造函数。两个参数传递给父级的构造函数。第15行初始化一个对象属性numOfSeats。此属性属于Car,并且在Vehicle类中不存在。第17行重新定义方法display()。在方法的代码中,将调用父方法,并且那里的代码可以表达Car对象的功能。第21行定义了一个属于Car类的方法。第24至26行创建一个Car对象,处理Car属性并调用各种方法。
2020Python高薪实战学习大合集wx7dcc75bb5e655e9b.h5.xiaoe-tech.com
25.迭代器
迭代器是值的容器,我们可以使用它遍历所有值。在Python中,迭代器是实现__iter __()和__next __()的对象。列表,元组,字典和集合是可迭代的,并实现了迭代器协议。这些容器具有用于遍历值的iter()方法。这是一个例子。
fruitTuple = ("mango", "apple", "grapes")
fruitIter = iter(fruitTuple)
print(next(fruitIter))
print(next(fruitIter))
print(next(fruitIter))
A string can be iterated using iter() method.
fruitStr = "mango"
fruitIter = iter(fruitStr)
print(next(fruitIter))
print(next(fruitIter))
print(next(fruitIter))
print(next(fruitIter))
print(next(fruitIter))
print(next(fruitIter)) # last call throws error请注意,前五个next()调用将打印“ mango”的每个字符。最后的next()引发错误,指示迭代已停止。可迭代对象可以使用for in循环进行迭代。
fruitTuple = ("mango", "apple", "grapes")
fruitIter = iter(fruitTuple)
for fruit in fruitTuple:
print(fruit)我们可以创建自己的迭代器类。我们需要实现__iter __()和__next __()方法。还记得我们在类定义中看到的__init __()吗?迭代器的方法和协议类似于该类的init。让我们考虑一个创建迭代器的示例。迭代器是从1、2开始的斐波那契数列。
class Fibonacci:
def __iter__(self):
# define first two numbers
self.first = 1
self.second = 2
return self
def __next__(self):
curr = self.first + self.second # find new number
self.first = self.second # shift the previous two numbers
self.second = curr
return curr
fibo = Fibonacci ()
fiboIter = iter(fibo)
print(next(fiboIter))
print(next(fiboIter))
print(next(fiboIter))
print(next(fiboIter))
print(next(fiboIter))当第15行iter(fibo)被调用时,内部会调用__iter __()。调用next(iter)时,将调用__next __()方法来查找系列中的下一个元素。该迭代器永无休止,因为没有终止控件。为了防止无休止的系列,我们可以添加StopIteration语句。在__next__中,我们可以添加条件并使用StopIteration。
class Fibonacci:
def __iter__(self):
# define first two numbers
self.first = 1
self.second = 2
return self
def __next__(self):
curr = self.first + self.second # find new number
if (curr <= 50):
self.first = self.second # shift the previous two numbers
self.second = curr
return curr
else:
raise StopIteration
fibo = Fibonacci ()
fiboIter = iter(fibo)
for f in fiboIter:
print(f)在此示例中,我们检查斐波那契数列是否已达到50。任何大于或等于50的值都会产生错误。那将停止for循环。
由于字数限制,无法全部展示,完整版原文及视频点击下方阅读
Python自学教程| 3万字详解每个重要知识点(内附视频)mp.weixin.qq.com