卷积神经网络之-NiN网络(Network In Network)
更多内容请关注『机器视觉 CV』公众号
原文地址
简介
Network In Network 是发表于 2014 年 ICLR 的一篇 paper。当前被引了 3298 次。这篇文章采用较少参数就取得了 Alexnet 的效果,Alexnet 参数大小为 230M,而 Network In Network 仅为 29M,这篇 paper 主要两大亮点:mlpconv (multilayer perceptron,MLP,多层感知机)作为 "micro network"和 Global Average Pooling(全局平均池化)。论文地址:https://arxiv.org/abs/1312.4400
创新点
(1) mlpconv Layer
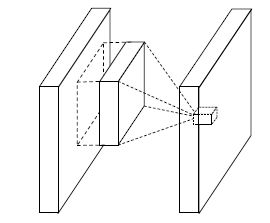
在介绍 mlpconv Layer 之前,我们先看看经典的 Linear Convolutional Layer(线性卷积层)是怎么进行操作的,
![]()
(i, j) 是特征图中像素的位置索引,x_ij 表示像素值,而 k 用于特征图通道的索引,W 是参数,经过 WX 计算以后经过一个 relu 激活进行特征的抽象表示。
下面就介绍 mlpconv Layer 结构
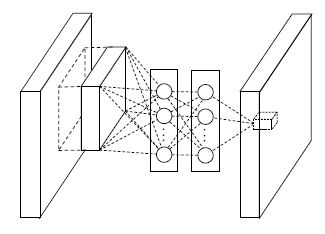
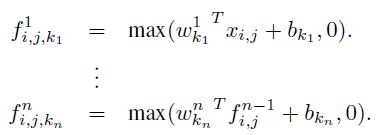
i, j 表示像素下标,xi,j 表示像素值,wk,n 表示第 n 层卷积卷积参数。 以上结构可以进行跨通道的信息融合。MLP 的参数也可以使用 BP 算法训练,与 CNN 高度整合;同时,1×1 卷积可以实现通道数的降维或者升维,11n,如果 n 小于之前通道数,则实现了降维,如果 n 大于之前通道数,则实现了升维。
(2) Global Average Pooling Layer
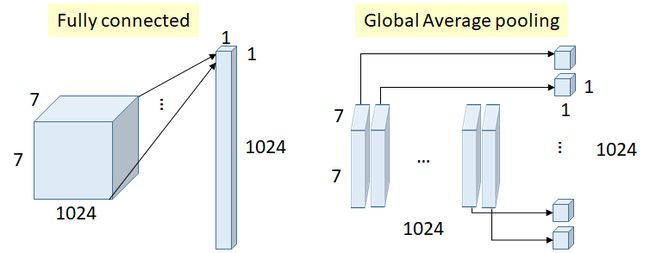
之前的卷积神经网络的最后会加一层全连接来进行分类,但是,全连接层具有非常大的参数量,导致模型非常容易过拟合。因此,全局平均池化的出现替代了全连接层。我们在最后一层 mlpconv 得到的特征图使用全局平均池化(也就是取每个特征图的平均值)进而将结果输入到 softmax 层中。
全局平均池化的优点
- 全局平均池化没有参数,可以避免过拟合产生。
- 全局平均池可以对空间信息进行汇总,因此对输入的空间转换具有更强的鲁棒性。
下图是全连接层和全局平均池化的一个对比图
整体网络架构

NiN 网络由三个 mlpconv 块组成,最后一个mlpconv 后使用全局平均池化。用 Pytorch 代码实现如下:假设输入是 32×32×3 (即 3 通道,32 高宽大小的图片)
import torch
import torch.nn as nn
class NiN(nn.Module):
def __init__(self, num_classes):
super(NiN, self).__init__()
self.num_classes = num_classes
self.classifier = nn.Sequential(
nn.Conv2d(3, 192, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.Conv2d(192, 160, kernel_size=1, stride=1, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(160, 96, kernel_size=1, stride=1, padding=0),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
nn.Dropout(0.5),
nn.Conv2d(96, 192, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=1, stride=1, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=1, stride=1, padding=0),
nn.ReLU(inplace=True),
nn.AvgPool2d(kernel_size=3, stride=2, padding=1),
nn.Dropout(0.5),
nn.Conv2d(192, 192, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=1, stride=1, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(192, 10, kernel_size=1, stride=1, padding=0),
nn.ReLU(inplace=True),
nn.AvgPool2d(kernel_size=8, stride=1, padding=0),
)
def forward(self, x):
x = self.classifier(x)
logits = x.view(x.size(0), self.num_classes)
probas = torch.softmax(logits, dim=1)
return logits, probas
结果分析
- CIFAR-10 测试数据集

NIN + Dropout 得到 10.41% 的错误率,加上数据增强(平移和水平翻转)错误率降到了 8.81%

以上曲线对比了有无 Dropout 机制前200 epoch 的错误率,实验结果表明,引入Dropout机制,可以降低测试集 20% 的错误率
在 CIFAR-10 测试数据集上对比了全连接层和全局平均池化的效果

- CIFAR-100

上面对比方法时提到了 maxout,这是是蒙特利尔大学信息与信息技术学院的几位大牛 2013 年在 ICML 上发表的一篇论文,有兴趣的可以看:https://arxiv.org/abs/1302.4389
- Street View House Numbers (SVHN) 街景门牌号码数据集

- MNIST

NiN + Dropout 效果在 MNIST 上效果比 maxout +Dropout 逊色了点
总结
Network In Network 通过创新的创建 MLP 卷积层,提高了网络的非线性表达同时降低了参数量,用全局均值池化代替全连接层,极大的降低了参数量。
参考:
- 有三AI【模型解读】network in network 中的 1*1 卷积,你懂了吗
- http://teleported.in/posts/network-in-network/
- https://openreview.net/forum?id=ylE6yojDR5yqX
- https://d2l.ai/chapter_convolutional-modern/nin.html 动手学深度学习
- https://github.com/jiecaoyu/pytorch-nin-cifar10